AWS News Blog
S3 Select and Glacier Select – Retrieving Subsets of Objects

|
Update July 25, 2024 — Use Amazon Athena, S3 Object Lambda, or client-side filtering to optimize querying your data in Amazon S3. Learn more.
Amazon Simple Storage Service (Amazon S3) stores data for millions of applications used by market leaders in every industry. Many of these customers also use Amazon Glacier for secure, durable, and extremely low-cost archival storage. With S3, I can store as many objects as I want and individual objects can be as large as 5 terabytes. Data in object storage have traditionally been accessed as a whole entities, meaning when you ask for a 5 gigabyte object you get all 5 gigabytes. It’s the nature of object storage. Today we’re challenging that paradigm by announcing two new capabilities for S3 and Glacier that allow you to use simple SQL expressions to pull out only the bytes you need from those objects. This fundamentally enhances virtually every application that accesses objects in S3 or Glacier.
S3 Select
S3 Select,
launching in preview
now generally available, enables applications to retrieve only a subset of data from an object by using simple SQL expressions. By using S3 Select to retrieve only the data needed by your application, you can achieve drastic performance increases – in many cases you can get as much as a 400% improvement.
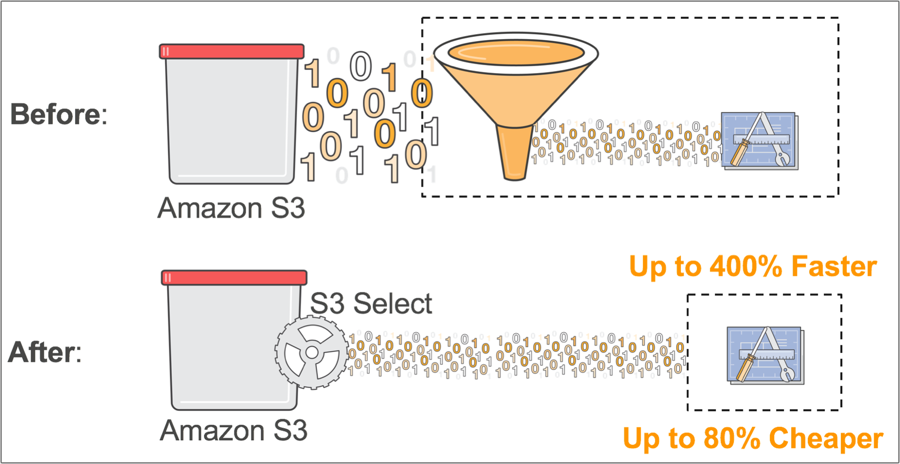
As an example, let’s imagine you’re a developer at a large retailer and you need to analyze the weekly sales data from a single store, but the data for all 200 stores is saved in a new GZIP-ed CSV every day. Without S3 Select, you would need to download, decompress and process the entire CSV to get the data you needed. With S3 Select, you can use a simple SQL expression to return only the data from the store you’re interested in, instead of retrieving the entire object. This means you’re dealing with an order of magnitude less data which improves the performance of your underlying applications.
Let’s look at a quick Python example, which shows how to retrieve the first column from an object containing data in CSV format.
import boto3
s3 = boto3.client('s3')
r = s3.select_object_content(
Bucket='jbarr-us-west-2',
Key='sample-data/airportCodes.csv',
ExpressionType='SQL',
Expression="select * from s3object s where s.\"Country (Name)\" like '%United States%'",
InputSerialization = {'CSV': {"FileHeaderInfo": "Use"}},
OutputSerialization = {'CSV': {}},
)
for event in r['Payload']:
if 'Records' in event:
records = event['Records']['Payload'].decode('utf-8')
print(records)
elif 'Stats' in event:
statsDetails = event['Stats']['Details']
print("Stats details bytesScanned: ")
print(statsDetails['BytesScanned'])
print("Stats details bytesProcessed: ")
print(statsDetails['BytesProcessed'])Pretty cool!
We expect customers to use S3 Select to accelerate all sorts of applications. For example, this partial data retrieval ability is especially useful for serverless applications built with AWS Lambda. When we modified the Serverless MapReduce reference architecture to retrieve only the data needed using S3 Select we saw a 2X improvement in performance and an 80% reduction in cost.
Query pushdown using S3 Select is now supported with Spark, Hive and Presto in Amazon EMR. You can use this feature to push down the computational work of filtering large data sets for processing from the EMR cluster to Amazon S3, which can improve performance and reduce the amount of data transferred between Amazon EMR and Amazon S3.
Things To Know
Amazon Athena, Amazon Redshift, and Amazon EMR as well as partners like Cloudera, DataBricks, and Hortonworks will all support S3 Select.
Glacier Select
Some companies in highly regulated industries like Financial Services, Healthcare, and others, write data directly to Amazon Glacier to satisfy compliance needs like SEC Rule 17a-4 or HIPAA. Many S3 users have lifecycle policies designed to save on storage costs by moving their data into Glacier when they no longer need to access it on a regular basis. Most legacy archival solutions, like on premise tape libraries, have highly restricted data retrieval throughput and are unsuitable for rapid analytics or processing. If you want to make use of data stored on one of those tapes you might have to wait for weeks to get useful results. In contrast, cold data stored in Glacier can now be easily queried within minutes.
This unlocks a lot of exciting new business value for your archived data. Glacier Select allows you to to perform filtering directly against a Glacier object using standard SQL statements.
Glacier Select works just like any other retrieval job except it has an additional set of parameters you can pass in initiate job request. SelectParameters
Here a quick example:
import boto3
glacier = boto3.client("glacier")
jobParameters = {
"Type": "select", "ArchiveId": "ID",
"Tier": "Expedited",
"SelectParameters": {
"InputSerialization": {"csv": {}},
"ExpressionType": "SQL",
"Expression": "SELECT * FROM archive WHERE _5='498960'",
"OutputSerialization": {
"csv": {}
}
},
"OutputLocation": {
"S3": {"BucketName": "glacier-select-output", "Prefix": "1"}
}
}
glacier.initiate_job(vaultName="reInventSecrets", jobParameters=jobParameters)
Things To Know
Glacier Select is generally available in all commercial regions that have Glacier.
Glacier is priced in 3 dimensions.
- GB of Data Scanned
- GB of Data Returned
- Select Requests
Pricing for each dimension is determined by the speed at which you want your results returned: expedited (1-5 minutes), standard (3-5 hours), and bulk (5-12 hours).
I hope you’re able to get started enhancing your applications or building new ones with these capabilities.
– Randall