AWS News Blog
New – Cross-Region Replication for Amazon S3
We launched Amazon S3 nine years ago as of last week!
Since that time we have added dozens of features, expanded across the globe, and reduced the prices for storage and bandwidth multiple times. You, our customers, have trusted us with your mission-critical data and have used S3 in thousands of interesting and unique ways. Your creativity and your feedback (keep it coming) have given us the insights that we need to have in order to ensure that S3 continues to meet your requirements for object storage.
While the name space for buckets is global, S3 (like most of the other AWS services) runs in each AWS region (see the AWS Global Infrastructure page for more information). This model gives you full control over the location of your data; you can choose an appropriate location based on local regulatory requirements, a desire to have the data close to your principal customers to reduce latency, or for other reasons.
Many of you have told us that you need to keep copies of your critical data in locations that are hundreds of miles apart. This is often a consequence of having to comply with stringent regulatory requirements for the storage of sensitive financial and personal data.
Cross-Region Replication
In order to make it easier for you to make copies of your S3 objects in a second AWS region, we are launching Cross-Region Replication today. You can use this feature to meet all of the needs that I described above including geographically diverse replication and adjacency to important customers.
Once enabled, every object uploaded to a particular S3 bucket is automatically replicated to a designated destination bucket located in a different AWS region.
You can enable and start using this feature in a couple of minutes! It it built on top of S3’s existing versioning facility; the console will help you to turn it on if necessary:
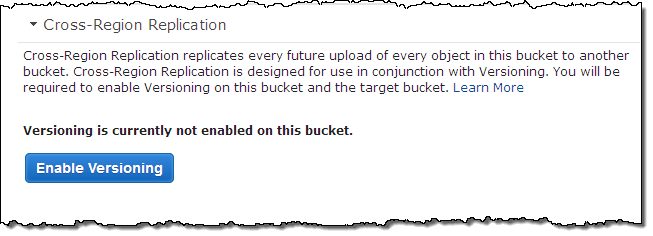
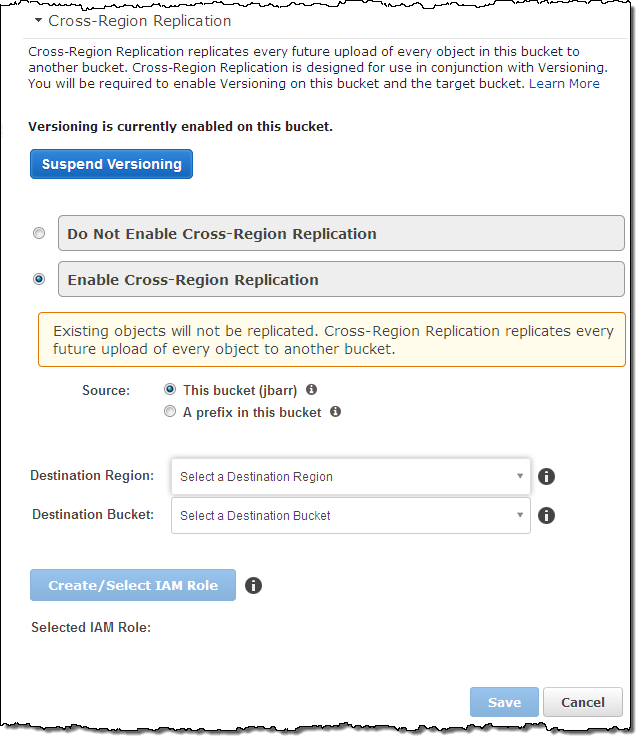
With versioning enabled, the rest is easy. You simply choose the destination region and bucket (and optionally restrict replication to a subset of the objects in the bucket using a prefix), set up an IAM role, and you are done.
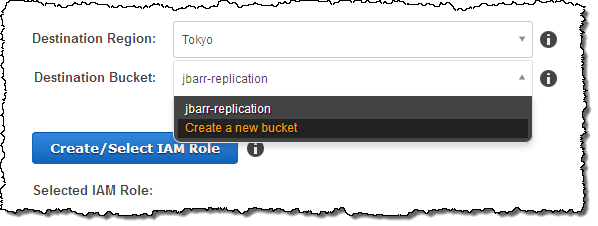
You can choose an existing bucket or you can create a new one as part of this step:
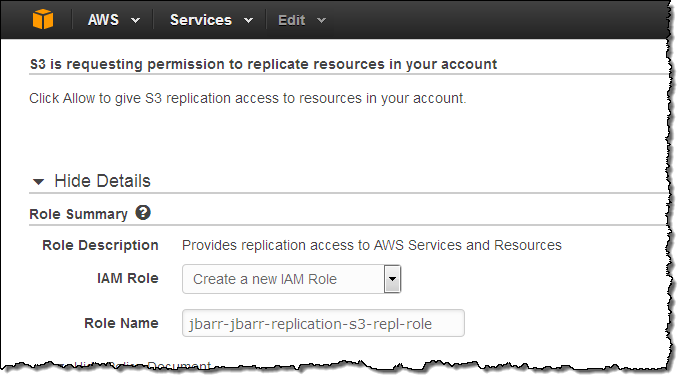
You will also need to set up an IAM role so that S3 can list and retrieve objects from the source bucket and to initiate replication operations on the destination bucket. Because you have the opportunity to control the policy document, you can easily implement advanced scenarios such as replication between buckets owned by separate AWS accounts. The console will help you to set up the proper IAM role by supplying a default policy:
Once I had the replication all set up, I inspected the destination bucket. As expected, it was empty (replication works on newly created objects):
![]()
I uploaded a picture, and selected Reduced Redundancy Storage (RRS) and Server Side Encryption (SSE) using the AWS S3 master key:
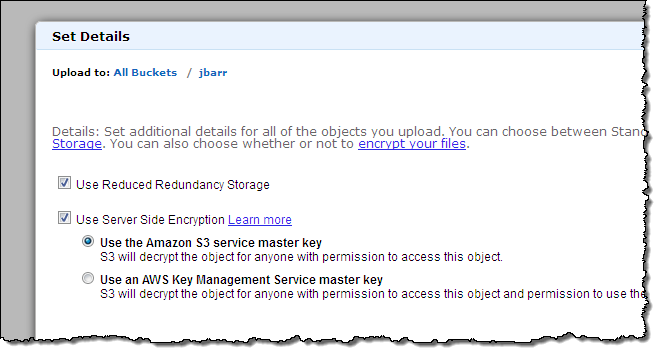
I refreshed my view of the destination bucket a couple of times (I’m impatient) and the object was there, as expected. I verified that the replica also used RRS and SSE:
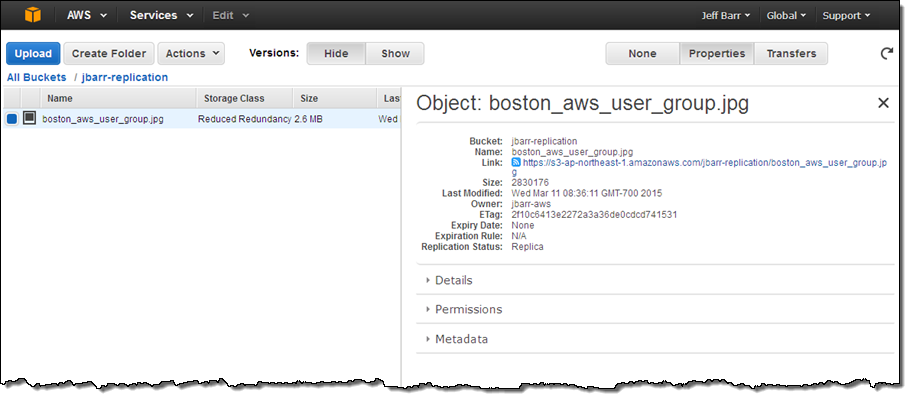
The replication process also copies any metadata and ACLs (Access Control Lists) associated with the object.
You can also enable and manage this feature through the S3 API.
A Few Details

“Based on the results of our testing, the S3 cross-region replication feature will enable FINRA to transfer large amounts of data in a far more automated, timely and cost effective manner. Making use of the new feature to help meet resiliency, compliance or DR data requirements is a no brainer.”
Peter Boyle, Senior Director
FINRA
Here are a few things to keep in mind as you start to think about how to make use of Cross-Region Replication in your own operating environment.
Versioning – As I mentioned earlier, you must first enable S3 versioning for the source and destination buckets.
Lifecycle Rules – You can choose to use Lifecyle Rules on the destination bucket to manage older versions by deleting them or migrating them to Amazon Glacier.
Determining Replication Status – You (or your code) can use the HEAD operation on a source object to determine its replication status. You can also (as you saw above) view this status in the Console.
Region-to-Region – Replication always takes place between a pair of AWS regions. You cannot use this feature to replicate content to two buckets that are in the same region.
New Objects – Because this feature watches the source bucket for changes, it replicates new objects and changes to existing objects. If you need to replicate existing objects, a solution built around the S3 COPY operation can be used to bring the destination bucket up to date.
To learn more, read about Cross-Region Replication in the S3 Developer Guide.
Available Now
This feature is available now and you can start using it today. In addition to the additional data storage charges for the data in the destination bucket, you will also pay the usual AWS price for data transfer between regions. For more information, please consult the S3 Pricing page.
— Jeff;