AWS Storage Blog
Shutterstock transforms IT and saves 60% on storage costs with Amazon S3
Shutterstock, founded in 2003, is a leading global creative platform for transformative brands and media companies. Working with a community of over 2 million contributors, our catalog has grown to more than 405 million images and over 25 million videos. Headquartered in New York City, we serve a global customer base spread across 150 countries and cater our platform to 21 unique languages. To add to this scale, our catalog increases by approximately 200,000 images each day.
One of the challenges of a fast-growing library of content like ours is ensuring that ample storage is available well ahead of demand. Maintaining our own storage infrastructure for over a decade has given us valuable insight into the logistics of on-premises hardware maintenance, expansion, and refreshes.
In this blog, written from the perspective of the Shutterstock Cloud Storage Services Team, we explore the AWS cloud journey our team embarked on in 2015 and the discoveries along the way. Join us as we examine how we shifted our primary focus from hardware to software and how Amazon Simple Storage Service (Amazon S3) assisted with this transformation.
Data Center to cloud via Strangler Fig Pattern
In early 2015, our storage was based on an open-source object store and a collection of high disk capacity servers. Our analytics leading up to 2014 forecasted exponential growth ahead. Drivers of this growth, such as the availability of an increasingly more capable selection of media gear (including cameras, drones, and even phones), created an exciting wave of new content the world had never seen. We certainly had a conundrum on our hands. How could we support the ever-increasing stream of content headed our way? Great forward-thinking in 2015 by our engineers resulted in the internal creation of the first generation of a storage proxy that would be able to support a multitude of backend storage solutions (both on-premises and in AWS) without requiring our internal users and services to change their access patterns. This approach is often referred to as the Strangler Fig Pattern and is a key way to ensure minimal disruption while introducing new systems.
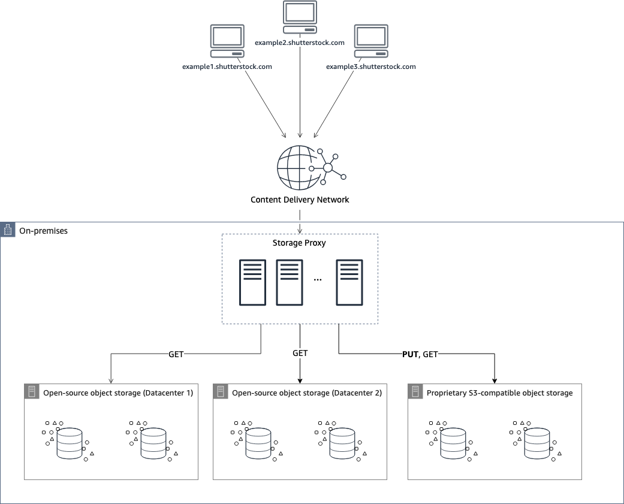
Figure 1: 2015 Shutterstock data center to cloud via Strangler Fig Pattern example
By 2017, our on-premises open-source powered object storage solution held over 4 PB of data on more than 5,000 drives with four copies of every object in two geographically dispersed data centers. This capacity was augmented with the purchase of a proprietary on-premises S3-compatible object storage system. We began serving traffic from both systems via our storage proxy with PUT operations initially going to both systems, and eventually only to the newer system. GET operations would happen sequentially allowing us to favor one system over the other as objects migrated over time. The flexibility of the storage proxy configuration allowed us to pursue new ideas around how storage calls should behave.
The Strangler Fig/storage proxy pattern worked out very well for us and enabled our object storage transformation. However, as with any architectural pattern, there are positives and negatives to the approach. The positive is a seamless integration with no change needed for users/applications accessing your storage. The ability to map different calls to different systems is key to the popularity of this approach. Likewise, we were able to achieve minimal disruption by implementing changes gradually. All of this, however, comes at a price. Provisioning and maintaining a fleet of KVM or Amazon EC2 hosts can be time and resource-consuming. Additionally, a proxy likely indicates byte proxying is involved. This can be an expensive middleman operation as every byte streamed must make it through the storage proxy before arriving at its destination. Byte chunking in the proxy must be configured to optimize throughput and avoid dragging down performance. Building a seamless bridge between infrastructure iterations is the prize.
By early 2018 much of the hardware our open source solution ran on was reaching end of life. Luckily our storage proxy allowed us to seamlessly phase it out as more and more objects were copied to the later proprietary on-premises system, which was now fronting the majority of requests. At this point, we felt we had a good grasp on the sort of work that would be involved in scaling on-premises solutions from ~8 PB to ~15 PB by 2020 as our projections indicated we needed to achieve. Such an endeavor would require us to increase our focus on hardware. This sort of expansion required additional rack space, hardware refreshes, and continued contract negotiations with multiple vendors, all of which needed to be lined up a year in advance. We had already experienced owning the full solution with our open-source system and utilizing a vendor to manage on-premises hardware with our proprietary object storage system. Both required a laser focus on hardware. We began to wonder, are we focused on our core business if we continue down this path? Soon, Shutterstock collectively decided to migrate to the cloud. AWS is a clear cloud leader. We were also already able to support Amazon S3, AWS’ object storage service built to retrieve any amount of data from anywhere.

Figure 2: Shutterstock AWS architecture diagram
By late 2018, the proxy itself moved from on premise KVM to Amazon EC2. Also, we made another configuration change to our storage proxy that allowed us to point our services to both our on-premises object storage as well as to S3. We began to use Amazon S3 for all new PUT operations and many GET operations. Migration tasks started copying data from on-premises storage to AWS and once more, our storage proxy eased the transition. Even more exciting – the best was still ahead.
Optimize and re:Invest
Starting in 2019, all our storage requests were being served from Amazon S3. The storage proxy, now in its second generation and built with code portability in mind, continued mapping requests as needed but no longer had to keep track of multiple storage systems. The greatest initially observed gain was that reduced maintenance of S3 allowed us to regain 20% – 50% of our team sprint time for other tasks. We reinvested this time into optimizing other areas of our architecture. One of these was improving our object access pattern analysis. Upon first using S3, we quickly discovered that based on our access patterns it was most cost-efficient for us to use Amazon S3 Standard-Infrequent Access (S3 Standard-IA) for our larger objects. The Amazon S3 Intelligent-Tiering storage class had just launched in late 2018 and piqued our interest as well, but at the time it did not offer much benefit in our specific case. For now, we continued to PUT original size objects utilizing S3 Standard-IA and derivatives utilizing S3 Standard. This resulted in a predictable data retrieval cost along with reduced storage utilization cost.
As our content footprint increased to roughly 16 PB by late 2021, significant changes were announced for the S3 Intelligent-Tiering storage class. A new Archive Instant Access tier offered additional savings of up to 68% with no impact on performance. This would allow us to have collections of objects, which may be infrequently accessed, to reach the Archive Instant Access tier and move to the Frequent Access tier in the event of the topic warming up.
S3 Intelligent-Tiering works by monitoring objects in your bucket and automatically tiering those objects down to more cost-efficient storage classes when objects have not been accessed over defined periods of time. The introduction of the Archive Instant Access tier of S3 Intelligent-Tiering meant that we could take advantage of objects being moved from the Frequent Access tier to the Infrequent Access tier after 30 days, and then from the Infrequent Access tier to the Archive Instant Access tier after an additional 60 days of no access, all while these objects were still accessible with milliseconds latency access.

Figure 3: Bucket lifecycle policy
Given these improvements, we began to migrate our existing objects to S3 Intelligent-Tiering at the beginning of 2022. This was easily accomplished on entire buckets using an S3 lifecycle policy. After applying the below lifecycle to each bucket, S3 would officially transition our objects to the S3 Intelligent Tiering storage class at the next midnight UTC, allowing us to effectively migrate 16 PB of storage to S3 Intelligent-Tiering within 24 hours.
All new objects were placed directly into the S3 Intelligent-Tiering storage class using the ‘StorageClass’ parameter in our PUT call. In Python, the PUT call may look something like this:
response = client.put_object(
Bucket='string',
Key='string',
StorageClass='INTELLIGENT_TIERING',
)This avoids any transition costs that could have been incurred if the policy above had to transition the class of all newly PUT objects after they were written. With the two methods combined, we were able to ensure proper object storage class settings over the life of the bucket. Monitoring of AWS Cost Explorer for S3 Intelligent-Tiering transition costs can highlight misconfigured PUT operations. Additionally, we use AWS Cost Explorer to visualize, understand, and manage our AWS costs and usage over time.
The savings we realized from using S3 Intelligent-Tiering, up to 60% in some buckets, allowed us to further reinvest in our storage infrastructureand replicate our storage environment to a second AWS Region. The timing aligned well with a recent feature release for Amazon S3 Batch Replication for existing objects that would allow us to turn on S3 Cross-Region Replication (CRR) for both existing and newly uploaded objects. Single Region S3 is already designed for awesome 99.999999999% (11 9s) durability and 99.9% availability when utilizing the S3 Intelligent-Tiering class. This is achieved by storing the data in three Availability Zones in a single Region. By enabling CRR we are able to keep 6 copies across geographically dispersed sets of data centers to ensure our contributors’ work is offered the best protection against major incidents. For instance, this can provide availability in the event of a regional outage. Furthermore, by employing S3 Intelligent-Tiering in our second Region, we keep the cost to a minimum when the data is not being accessed. Essentially it allows us to have a ‘sleeping’ disaster recovery site that can ‘awaken’ at any time.
The process of copying large amounts of data to get started with CRR was made simple by S3 Batch Replication and allowed us to copy 16 PB of data to a second Region in mere weeks. Given we were looking to move both our objects to S3 Intelligent-Tiering and migrate them to a second Region, we chose to do these tasks in quick succession. First, we transitioned the objects to S3 Intelligent-Tiering so that we could take advantage of the lack of data retrieval fees for our replication step. Immediately after this transition was complete, we kicked off our S3 Batch Replication job to the second Region. The S3 Batch Replication step counts as access for the S3 Intelligent-Tiering objects and resets the access timeline used for tiering the objects down to colder storage tiers. By initiating the Batch Replication job as soon as the objects were transitioned to S3 Intelligent-Tiering, our objects’ last access dates were still at or near 0 days, allowing us to reduce potential cost fluctuations and achieve the fastest possible schedule for tiering down the objects.
Conclusion
In a short time span, we experienced multiple major improvements, which increased performance and reduced the cost of Amazon S3. This did not require a major invasive refresh on our side as it would have if we had stayed on premises. Our increased access utilization of our buckets is being outpaced by performance improvements on S3 as well, due to S3’s continuous innovation. To our delight, many of our recent acquisitions use Amazon S3 as well, making for optimal integration with existing architectures and leading to some productive business transformation conversations with our new colleagues. Also, it has driven a shift in team focus from storage resource planning to true innovation. In hindsight, observing our gradual storage evolution, we believe this to be an impressive solution, and we look forward to the improvements ahead.
In this post, we discussed our journey from the data center to AWS and the opportunities this presented to us. We observed our scale-up from 4 PB to 16 PB (16 PB content, 40 PB+ overall) and how our partnership with the Amazon S3 team has supported our growth. We hope our story gives you inspiration in your own cloud journey.
Thanks for reading this blog! Leave any thoughts you have in the comments section below.