AWS Storage Blog
Category: Amazon Simple Storage Service (S3)

Achieving sub-10ms latency and 94% cost savings with Diskless Kafka using AutoMQ and Amazon FSx for NetApp ONTAP
As more organizations adopt Diskless Kafka—a cloud-based messaging queue that builds entirely on object storage like Amazon Simple Storage Service (Amazon S3)—they gain significant cost and operational advantages. But for latency-sensitive workloads, this architecture faces a key question: how to keep millisecond-level write latency while preserving the cost benefits of S3? This is the core […]
Building persistent memory for multi-agent AI systems with Amazon S3 Vectors
The most capable multi-agent AI systems share a common trait: they give agents the right context at the right time. When agents lack access to shared history, including what other agents discovered, what tasks are already complete, and what decisions were made in previous sessions, they might duplicate work, contradict each other, and burn through […]
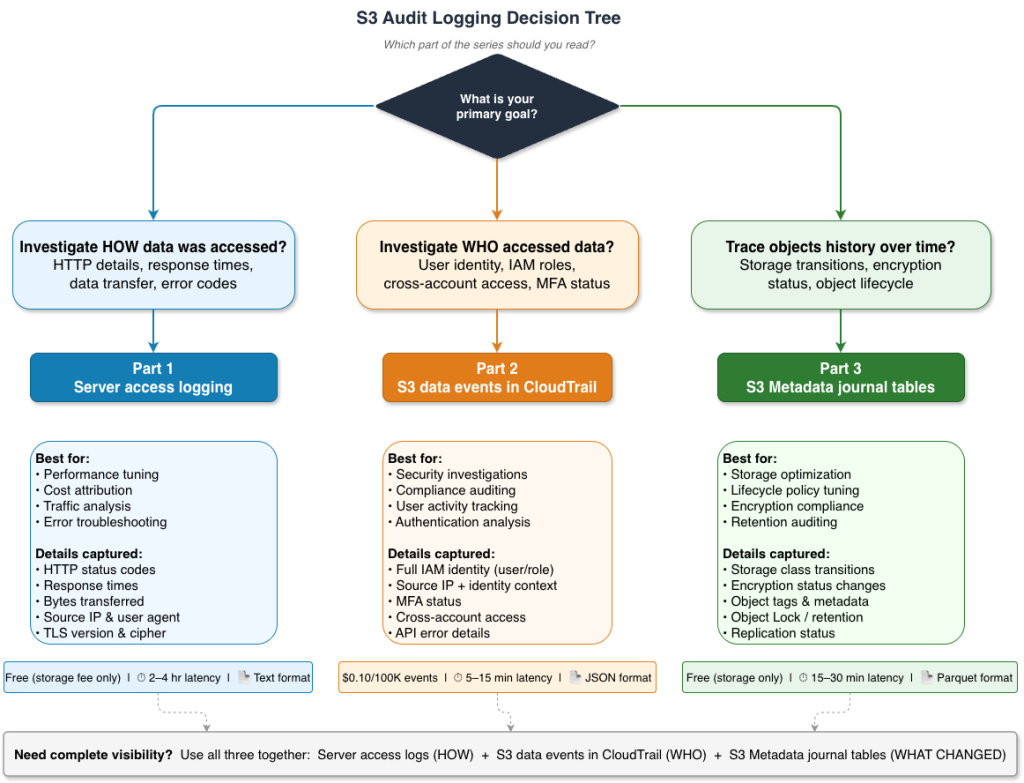
Amazon S3 audit logging, Part 3: Analyzing S3 Metadata journal tables for object lifecycle tracking
This is Part 3 of our three-part series on Amazon S3 audit logging. In Part 1, we covered server access logs for HTTP-level requests and performance analysis. In Part 2, we covered S3 data events in AWS CloudTrail for identity-focused security investigations. As data volumes grow and storage costs become a significant line item, organizations […]
Amazon S3 audit logging, Part 2: Centralized logging and analysis of S3 data events in AWS CloudTrail for security and compliance
This is Part 2 of our three-part series on Amazon S3 audit logging, focusing on identity-driven security investigations. In Part 1, we covered S3 server access logs for HTTP-level performance analysis and cost attribution. When a security incident occurs—an unauthorized download, a bulk deletion, or suspicious access from an unfamiliar location—the first question is always, […]
Amazon S3 audit logging, Part 1: Analyzing server access logs with Amazon Athena for performance insights
Organizations storing sensitive data must maintain complete visibility into how it’s accessed, by whom, and what changes occur over time. Regulatory frameworks demand detailed audit trails, security teams need rapid answers during investigations, and finance teams require granular cost attribution. Yet as data grows from terabytes to petabytes, the scale that makes centralized storage attractive […]

Data discovery: How to find out what’s on your Amazon FSx for NetApp ONTAP volumes
Enterprise storage administrators manage hundreds of terabytes, and sometimes petabytes, of file data spanning business units, applications, and users. As that storage grows, so does the challenge of understanding what is actually stored in it. Administrators are asked to make capacity decisions, identify archive candidates, track storage costs, and support compliance reviews — but with […]

Scalable cross-cloud data migration to Amazon S3 with distributed rclone
Migrating petabytes of data across cloud providers is one of the most operationally demanding tasks an organization can take on. At this scale, simple transfer approaches break down. Teams lose track of what has been copied and what has failed. Transfers stall and require constant manual intervention to restart. In some cases, teams need to […]

Implement single-exchange tokens for short-lived Amazon S3 presigned URLs with Terraform
Organizations across industries use signed URLs to grant temporary, credential-less access to private resources such as receipts, medical or financial records, legal files, or confidential reports. However, signed URLs can be reused by anyone until they expire, creating security risks if a URL is shared or inadvertently disclosed. This risk can be mitigated by vending […]

Enabling natural language access to structured data using Amazon S3 Tables and Amazon Bedrock Knowledge Bases
Organizations generate massive volumes of structured data from customer transactions, operational metrics, product catalogs, and compliance records. This data contains insights that can help businesses make better and timely decisions. Financial advisors need to review client transaction histories, retail analysts track inventory trends, and healthcare administrators monitor patient outcomes. Yet accessing these insights creates a […]

Migrate to Amazon S3 account regional namespaces
Since its launch in 2006, Amazon S3 has used a global namespace where bucket names must be unique across all AWS accounts and AWS Regions. This design has served customers well at scale, but organizations managing multiple accounts and environments often encounter naming collisions. When a bucket is deleted, its name returns to the global […]