AWS Storage Blog
Category: Advanced (300)

Manage storage consumption at scale using quotas on Amazon FSx for NetApp ONTAP
Learn how to configure ONTAP tree quotas on Amazon FSx for NetApp ONTAP to enforce per-workload capacity boundaries within a shared volume. This post walks through creating qtrees, defining quota policy rules with hard limits, soft limits, and thresholds, activating enforcement, and monitoring consumption using native quota reports and EMS events.

Zero-downtime Amazon S3 Versioning: Architectural patterns for mission-critical workloads
Organizations delivering content on a global scale rely on distributed edge networks to cache and serve billions of requests daily. These architectures depend on highly aggressive Time-To-Live (TTL) configurations to maximize performance and minimize origin load. On a cache miss, the network falls through to the origin to retrieve the requested content. At this scale, […]
Integrating Amazon FSx for NetApp ONTAP and Amazon FSx for Windows File Server using Microsoft Entra Domain Services
Organizations are increasingly adopting cloud-based identity solutions to reduce infrastructure overhead and improve their security posture. For customers running file workloads on AWS, both Amazon FSx for NetApp ONTAP and Amazon FSx for Windows File Server require joining a Microsoft Active Directory domain to serve SMB file shares and support Windows-based authentication. When customers have […]
Simplify workforce data access with AWS Transfer Family web apps and Terraform
Enterprises increasingly need direct access to data stored in Amazon Simple Storage Service (Amazon S3) for analytics, reporting, collaboration, and decision-making. Enabling this access for non-technical users can be challenging: training staff on the AWS Management Console, building custom portals, or adopting third-party tools each carry trade-offs in cost, complexity, or security posture. And as […]
Achieving sub-10ms latency and 94% cost savings with Diskless Kafka using AutoMQ and Amazon FSx for NetApp ONTAP
As more organizations adopt Diskless Kafka—a cloud-based messaging queue that builds entirely on object storage like Amazon Simple Storage Service (Amazon S3)—they gain significant cost and operational advantages. But for latency-sensitive workloads, this architecture faces a key question: how to keep millisecond-level write latency while preserving the cost benefits of S3? This is the core […]
Secure shared storage with CIFS share-level access controls on Amazon FSx for NetApp ONTAP
Learn how to use CIFS share-level access controls with qtrees on Amazon FSx for NetApp ONTAP to enforce per-team access boundaries within a shared volume, preventing unauthorized share access and simplifying access management through Active Directory group membership.
Building persistent memory for multi-agent AI systems with Amazon S3 Vectors
The most capable multi-agent AI systems share a common trait: they give agents the right context at the right time. When agents lack access to shared history, including what other agents discovered, what tasks are already complete, and what decisions were made in previous sessions, they might duplicate work, contradict each other, and burn through […]

Orchestrate automated response for Amazon GuardDuty Malware Protection for AWS Backup at scale
Many organizations maintain a backup strategy built on the assumption that the backups themselves are clean. Ransomware can sit dormant in your environment for weeks, spreading across production systems while nightly backup jobs preserve it alongside your data. By the time the threat is identified, those backups are no longer recovery points; they are artifacts […]
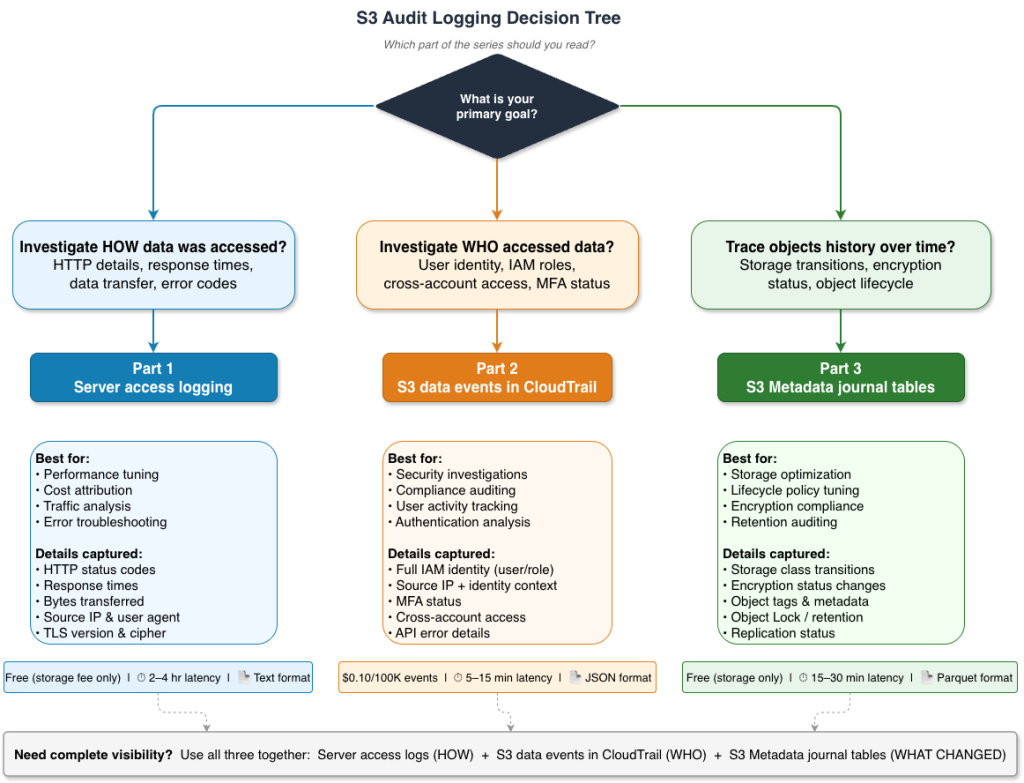
Amazon S3 audit logging, Part 3: Analyzing S3 Metadata journal tables for object lifecycle tracking
This is Part 3 of our three-part series on Amazon S3 audit logging. In Part 1, we covered server access logs for HTTP-level requests and performance analysis. In Part 2, we covered S3 data events in AWS CloudTrail for identity-focused security investigations. As data volumes grow and storage costs become a significant line item, organizations […]
Amazon S3 audit logging, Part 2: Centralized logging and analysis of S3 data events in AWS CloudTrail for security and compliance
This is Part 2 of our three-part series on Amazon S3 audit logging, focusing on identity-driven security investigations. In Part 1, we covered S3 server access logs for HTTP-level performance analysis and cost attribution. When a security incident occurs—an unauthorized download, a bulk deletion, or suspicious access from an unfamiliar location—the first question is always, […]