AWS Storage Blog
Category: Intermediate (200)

Unlocking data residency use cases with Amazon S3 in AWS Local Zones
Organizations running workloads in metros and geographies far from major cloud infrastructure need scalable, fully managed object storage, but regulations or business requirements mandate that data stays within specific national or metropolitan boundaries. This is particularly true for financial services, healthcare, and public sector, where compliance frameworks not only dictate where primary data resides but […]

How Vanderbilt University scales digital archive discovery with Amazon S3 Metadata
Managing massive digital collections is hard. When you’re preserving decades of historical content and adding new materials daily, making that content discoverable matters more than the storage itself. Vanderbilt University Library discovered this firsthand while managing their extensive digital archives, including the renowned Vanderbilt Television News Archive (VTNA). Amazon S3 Metadata accelerates data discovery by […]
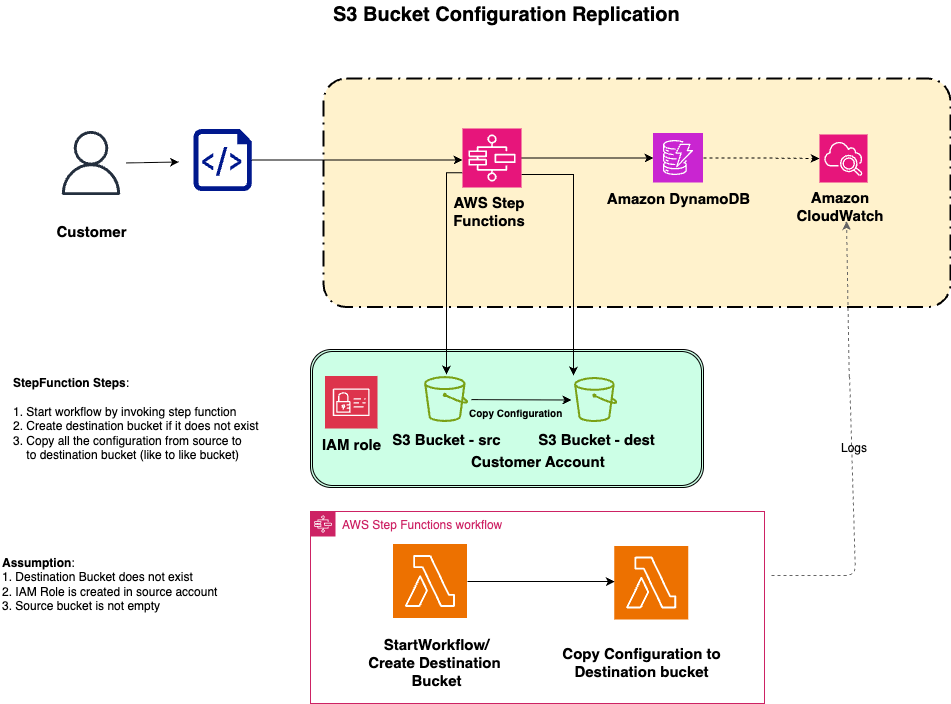
Replicate Amazon S3 bucket configurations across AWS Regions with AWS Step Functions
Many organizations operate thousands of Amazon S3 buckets in a single AWS Region, each with its own configuration accumulated over the years. Some were created manually in the AWS Management Console and others by scripts that are no longer actively maintained, provisioned by different business units with their own policies, lifecycle rules, encryption, and tags. […]

Query Amazon S3 access logs instantly with CloudWatch and S3 Tables
Knowing who accessed your data, when, and how is the foundation for security investigations, compliance audits, cost attribution, and performance troubleshooting. Detailed access logs capture every request: who made it, which resource was accessed, and what response was returned. In practice, though, they arrive as semi-structured records spread across different locations. Turning them into actionable […]

Gain workload-specific storage insights with Amazon S3 Storage Lens groups
As industries generate and store growing volumes of data, gaining meaningful insights into storage usage becomes increasingly complex. You need to understand your data growth patterns and drivers while optimizing storage investments across different business units and workloads. However, obtaining the necessary visibility by data categories, departments, or applications remains operationally difficult, limiting the ability […]

Migrating SAS grid to the cloud: How Amazon FSx for Lustre Intelligent-Tiering delivers low cost, high performance, storage
For nearly two decades, organizations across healthcare, drug discovery, and financial services have relied on SAS Grid to power their most critical analytics workloads. SAS Grid (formally known as SAS Grid Manager) is an enterprise software platform developed by SAS Institute that distributes and manages large-scale analytical workloads across a cluster of servers. It acts […]

How Tavily reduced AI search caching costs by 95% with Amazon S3 Express One Zone
Tavily is an AI infrastructure company building the web access layer for agents and large language models (LLMs). The company provides developer-friendly APIs that enable real-time, structured retrieval from the web. Their mission is to make information instantly accessible for intelligent systems, and they’re trusted by thousands of leading research, commercial AI teams, and enterprises […]

Bridge legacy and modern applications with Amazon S3 Access Points for Amazon FSx
Organizations rely on file storage accessed from traditional, file-based, applications while simultaneously wanting to build modern, cloud-native applications and services that access the same underlying data. Consequently, many cloud-native apps are built to work with Amazon S3. Amazon Web Services (AWS) recently introduced a new capability, S3 Access Points for Amazon FSx which solves challenges […]
Optimize agent tool selection using Amazon S3 Vectors and Amazon Bedrock Knowledge Bases
State-of-the-art AI agents rely on external tools to perform actions on their behalf. A tool is a function with a clear description, defined inputs, and outputs that extend the capabilities of a large language model (LLM). As toolkits expand, selecting the right tool for each task requires effective mechanisms, among which semantic search enables agents […]
Improve application resiliency with larger and faster Amazon EBS gp3 volumes
Maintaining resiliency and operational clarity while keeping costs low is one of the key things our customers have to balance for their high-performance applications. As customers experience natural growth in capacity and performance needs, at some point they may hit the limits of the existing solutions and have to rethink their architecture. They can do […]