AWS Storage Blog
Tag: Amazon Simple Storage Service (Amazon S3)

How Vanderbilt University scales digital archive discovery with Amazon S3 Metadata
Managing massive digital collections is hard. When you’re preserving decades of historical content and adding new materials daily, making that content discoverable matters more than the storage itself. Vanderbilt University Library discovered this firsthand while managing their extensive digital archives, including the renowned Vanderbilt Television News Archive (VTNA). Amazon S3 Metadata accelerates data discovery by […]

Zero-downtime Amazon S3 Versioning: Architectural patterns for mission-critical workloads
Organizations delivering content on a global scale rely on distributed edge networks to cache and serve billions of requests daily. These architectures depend on highly aggressive Time-To-Live (TTL) configurations to maximize performance and minimize origin load. On a cache miss, the network falls through to the origin to retrieve the requested content. At this scale, […]
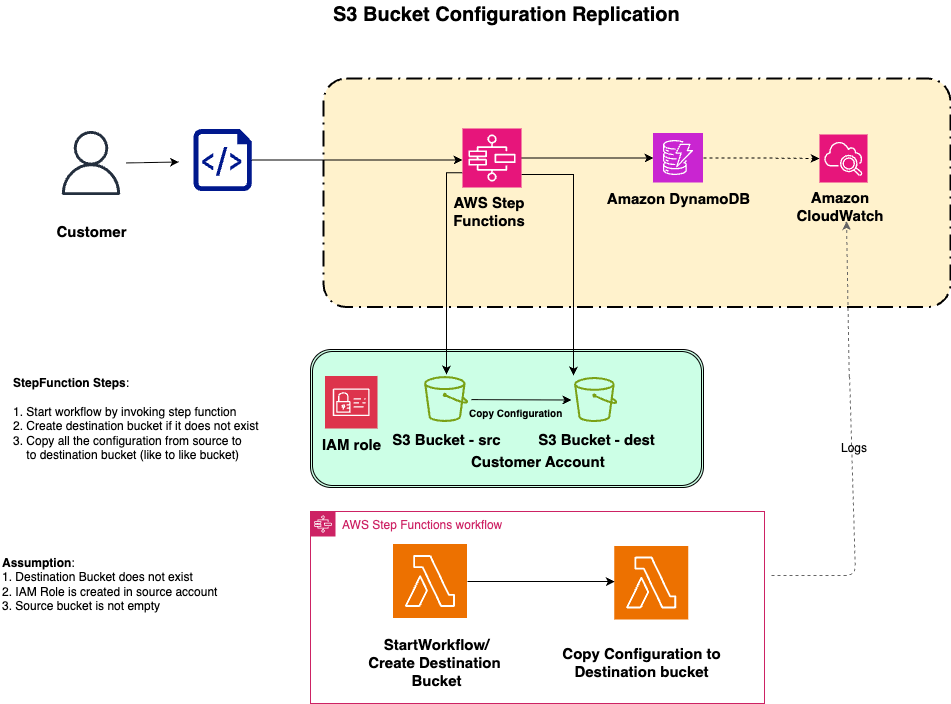
Replicate Amazon S3 bucket configurations across AWS Regions with AWS Step Functions
Many organizations operate thousands of Amazon S3 buckets in a single AWS Region, each with its own configuration accumulated over the years. Some were created manually in the AWS Management Console and others by scripts that are no longer actively maintained, provisioned by different business units with their own policies, lifecycle rules, encryption, and tags. […]

Query Amazon S3 access logs instantly with CloudWatch and S3 Tables
Knowing who accessed your data, when, and how is the foundation for security investigations, compliance audits, cost attribution, and performance troubleshooting. Detailed access logs capture every request: who made it, which resource was accessed, and what response was returned. In practice, though, they arrive as semi-structured records spread across different locations. Turning them into actionable […]

Gain workload-specific storage insights with Amazon S3 Storage Lens groups
As industries generate and store growing volumes of data, gaining meaningful insights into storage usage becomes increasingly complex. You need to understand your data growth patterns and drivers while optimizing storage investments across different business units and workloads. However, obtaining the necessary visibility by data categories, departments, or applications remains operationally difficult, limiting the ability […]
Building persistent memory for multi-agent AI systems with Amazon S3 Vectors
The most capable multi-agent AI systems share a common trait: they give agents the right context at the right time. When agents lack access to shared history, including what other agents discovered, what tasks are already complete, and what decisions were made in previous sessions, they might duplicate work, contradict each other, and burn through […]
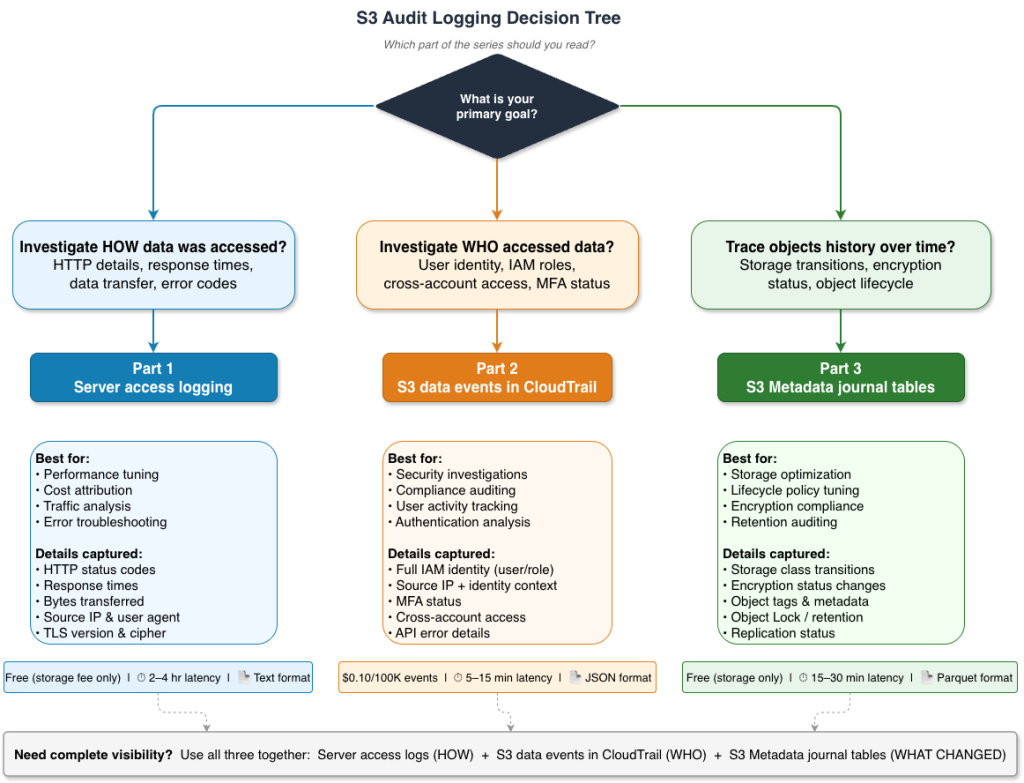
Amazon S3 audit logging, Part 3: Analyzing S3 Metadata journal tables for object lifecycle tracking
This is Part 3 of our three-part series on Amazon S3 audit logging. In Part 1, we covered server access logs for HTTP-level requests and performance analysis. In Part 2, we covered S3 data events in AWS CloudTrail for identity-focused security investigations. As data volumes grow and storage costs become a significant line item, organizations […]
Amazon S3 audit logging, Part 2: Centralized logging and analysis of S3 data events in AWS CloudTrail for security and compliance
This is Part 2 of our three-part series on Amazon S3 audit logging, focusing on identity-driven security investigations. In Part 1, we covered S3 server access logs for HTTP-level performance analysis and cost attribution. When a security incident occurs—an unauthorized download, a bulk deletion, or suspicious access from an unfamiliar location—the first question is always, […]
Amazon S3 audit logging, Part 1: Analyzing server access logs with Amazon Athena for performance insights
Organizations storing sensitive data must maintain complete visibility into how it’s accessed, by whom, and what changes occur over time. Regulatory frameworks demand detailed audit trails, security teams need rapid answers during investigations, and finance teams require granular cost attribution. Yet as data grows from terabytes to petabytes, the scale that makes centralized storage attractive […]
Scalable cross-cloud data migration to Amazon S3 with distributed rclone
Migrating petabytes of data across cloud providers is one of the most operationally demanding tasks an organization can take on. At this scale, simple transfer approaches break down. Teams lose track of what has been copied and what has failed. Transfers stall and require constant manual intervention to restart. In some cases, teams need to […]