AWS Storage Blog
5 Ways to reduce data storage costs using Amazon S3 Storage Lens
If you have an increasing number of Amazon S3 buckets, spread across tens or even hundreds of accounts, you might be in search of a tool that makes it easier to manage your growing storage footprint and improve cost efficiencies. S3 Storage Lens is an analytics feature built-in to the S3 console to help you gain organization-wide visibility into your object storage usage and activity trends, and to identify cost savings opportunities. S3 Storage Lens is available for all S3 accounts, free of charge. You can also upgrade to advanced metrics to receive additional metrics, insights, and an extended data retention period.
After reading this post, you should walk away with a basic understanding of how to use S3 Storage Lens to identify typical cost savings opportunities, and how to take action to implement changes to realize those cost savings.
1. Identify large buckets that you aren’t aware of
The first step to managing your storage costs is to gain a detailed understanding of your usage by bucket. With S3 Storage Lens, you can access a centralized view of all buckets in your account. You can even configure an AWS Organization level dashboard to see all buckets in all your accounts. Using S3 Storage Lens makes it easy to get visibility into all of your buckets, which can reveal unexpected findings such as buckets with more objects than you expected.
One way to spot these buckets is to scroll down to the top buckets section of the overview tab of your S3 Storage Lens dashboard to see a ranking of your largest buckets. The dashboard arranges the buckets by the Total storage metric for a selected date, as shown in the following screenshot:
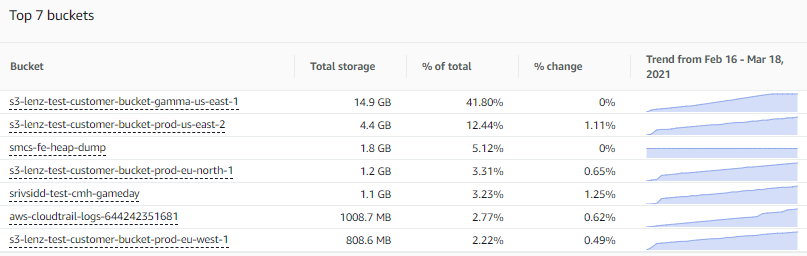
You can adjust the number of buckets displayed (up to 25), toggle the sort order to show the smallest buckets, and adjust the metric to rank by any of the other 29+ metrics. This view also shows a percentage change from prior day or week, in addition to a sparkline to visualize your 14-day trend (or 30-day trend if you have upgraded to advanced tier).
From there, you can proceed to the Buckets tab of the dashboard for more detailed insights on your buckets. For example, in the following chart you can see how one bucket has grown substantially more than others, from 10 GB to 15 GB in just 30 days:

Once you find a bucket with more data growth than other buckets, you can drill down on that bucket in S3 Storage Lens to gather more insights, such as the average object size, or the largest prefixes. Finally, you can navigate into the bucket within the Amazon S3 console to understand the associated workload and identify internal owners of the bucket based on the account number. Then you could find out from the bucket owners whether this growth is expected, or if it is unexpected growth that you can now place under proper monitoring and control.
2. Find and eliminate incomplete multipart upload bytes
The multipart upload feature is useful if you have very large objects (>100 MB), enabling you to upload a single object as a set of parts, which provides improved throughput and quicker recovery from network issues. However, in cases where you do not complete your multipart upload process, incomplete parts remain in your bucket (in an unusable state) and incur storage costs until you choose to complete the upload process, or take specific action to remove them.
With S3 Storage Lens, you can identify the amount of incomplete multipart upload bytes in your account, or across your entire AWS Organization. You can find this metric (as a percentage of total bytes) under the Cost efficiency tab, within the snapshot section at the top of the overview tab, as shown here:

You can also select incomplete multipart upload bytes as a metric in any other chart in the S3 Storage Lens dashboard. By doing so, you can further assess the impact of incomplete multipart upload bytes on your storage. For instance, you can assess their contribution to overall growth trends, or identify specific buckets that are accumulating these incomplete multipart upload bytes.
From there, you can take action by creating a lifecycle policy to expire incomplete multipart upload bytes from the bucket after a specified number of days.
3. Increase use of S3 storage classes
One of the clearest paths to storage cost savings is through optimizing your storage costs based on frequency of access and performance needs via S3 storage classes. As of today, Amazon S3 offers seven different storage classes to support a wide range of access frequency at corresponding rates. These include:
- S3 Standard for general-purpose storage of frequently accessed data
- S3 Intelligent-Tiering for data with unknown or changing access patterns
- S3 Standard-Infrequent Access (S3 Standard-IA) and S3 One Zone-Infrequent Access (S3 One Zone-IA) for long-lived, but less frequently accessed data
- Amazon S3 Glacier (S3 Glacier) and Amazon S3 Glacier Deep Archive (S3 Glacier Deep Archive) for long-term archive and digital preservation
If you are unsure of how you are currently using S3 storage classes, S3 Storage Lens provides a simple way to find out. From the overview tab, just scroll down to the Storage class distribution chart, as shown here:

If you see that all, or nearly all, of your storage bytes are attached to the S3 Standard storage class, it means that you’re not making use of the full array of S3 storage classes. If this is the case, you could likely benefit from one of two cost optimization design pattern. First, you can have cost optimization automated for you by electing to use the S3 Intelligent-Tiering storage class, which is ideal for unknown or changing access patterns. Second, you can configure S3 Lifecycle policies to reduce your storage costs by transitioning your data to more cost-effective storage classes as the access frequency slows over time. Check out the S3 pricing page for more details on exact savings, and note additional costs for transitions and S3 Glacier per object overhead.
You can then continue your analysis in S3 Storage Lens to explore storage class usage at greater depths, drilling down to see storage class distributions for specific Regions or buckets (or prefixes if you have upgraded to advanced tier). It’s fairly common to have a subset of buckets that are not optimally configured to make use of storage classes, and S3 Storage Lens is an effective tool to screen for these buckets before moving on to take further action.
4. Reduce the number of noncurrent versions retained
You can use Amazon S3 Versioning to retain multiple variants of the same object, which you can use to quickly recover data if it is accidentally deleted or overwritten. Versioning can also have a cost implication if you accumulate a large number of previous versions and do not put in place the necessary lifecycle policies to manage them.
To identify if you have an issue with accumulation of noncurrent versions, you can open S3 Storage Lens and navigate to the Cost efficiency tab under the snapshot section of the overview tab. Here, there is a metric for % noncurrent version bytes that represents the proportion of your total bytes (in scope of the dashboard) that are attributed to noncurrent versions, for the selected date, as shown here:

As a rule of thumb, if your % noncurrent version bytes is greater than 10% or more of your storage at the account level, it could be an indicator that you’re storing too many versions. You can also look at this metric under the top buckets section, to identify specific buckets that are accumulating a large number of noncurrent versions, as shown here:
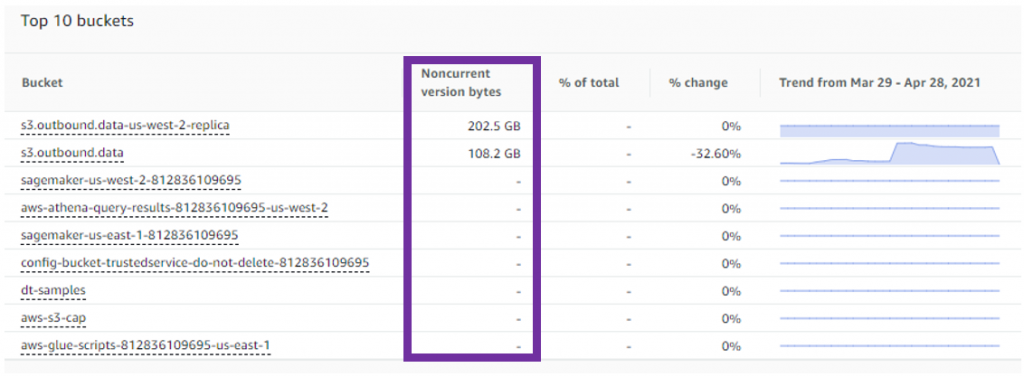
Once you have determined the buckets that require further attention, you can navigate to the bucket within the S3 console and enable a lifecycle policy to expire a noncurrent version after a specified number of days. Alternatively, you can configure noncurrent versions to transition to S3 Glacier to reduce costs while retaining the data.
5. Uncover buckets that have gone cold
If you have buckets that have gone cold, meaning that the storage in those buckets is no longer accessed (or rarely accessed), it’s often an indicator that the related workload is no longer in use. If you have enabled S3 Storage Lens advanced metrics, you have access to activity metrics to understand how hot (or cold) your buckets are. There are metrics like GET requests and download bytes that indicate how often your buckets are accessed each day. You can trend this data over several months (extended data retention is available with advanced tier) to understand the consistency of the access pattern and to spot buckets that are no longer being accessed at all. The % retrieval rate metric, computed as Download bytes / Total storage, is a useful metric to understand the proportion of storage in a bucket that is accessed daily. Keep in mind that the download bytes are duplicated in cases where the same object is downloaded multiple times during the day.
One of the more interesting visualizations in S3 Storage Lens is the bubble analysis chart on the bucket tab of the dashboard. Here you can select % retrieval rate as one of the metrics, enabling you to plot your buckets on multiple dimensions using any three metrics to represent the x-axis, y-axis, and size of the bubble, as shown here:
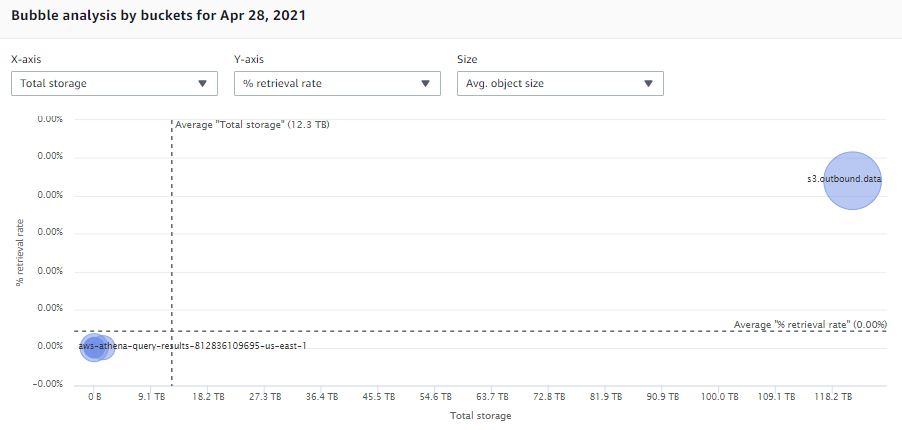
If you select Total storage, % retrieval rate, and Avg. object size, and then focus in on any buckets with a retrieval rate of zero (or near zero) and a larger relative storage size, you can find buckets that have gone cold and where the storage cost is likely large enough to warrant taking action. From here, you can identify the bucket owners in your organization to confirm the purpose of the workload and find out if the storage is still needed. If it’s unneeded, you can remediate costs by configuring lifecycle expiration policies, or archiving the data in Amazon S3 Glacier. And to avoid the problem of cold buckets going forward, you can apply one of the recommended design patterns previously mentioned in this post, to automatically transition your data using S3 Lifecycle policies or enable auto-archiving with S3 Intelligent-Tiering.
Conclusion
This blog post highlights 5 ways to increase your cost efficiency using insights from S3 Storage Lens, and the techniques described here can result in immediate cost savings. Often we find customers can save 20% or more through techniques like these. Furthermore, ongoing use of S3 Storage Lens can provide the necessary visibility to maintain or further extend these cost efficiencies as your storage increases over time.
In addition to these 5 ideas, there are numerous other ways to apply insights from S3 Storage Lens to drive greater cost efficiencies in your storage, or to implement data protection best practices – so please stay tuned for future posts. You can also reach out to your account team, or Amazon S3 Support, for more assistance on how to use S3 Storage Lens.
Thanks for reading this blog post on a few ways you can use Amazon S3 Storage Lens to reduce your storage costs. If you have any comments or questions, please leave them in the comments section.