Guidance for Monitoring Amazon EKS Workloads Using Amazon Managed Services for Prometheus & Grafana
Overview
This Guidance demonstrates how you can configure the AWS Observability Accelerator to collect and visualize metrics, logs, and traces on Amazon Elastic Kubernetes Service (Amazon EKS) clusters. Use it with the AWS Observability Accelerator for Terraform infrastructure as code models to rapidly deploy and operate observability for your AWS environments.
How it works
Optional
This architecture diagram demonstrates an Amazon Elastic Kubernetes Service (Amazon EKS) cluster provisioned through an Amazon EKS Blueprint for Terraform.
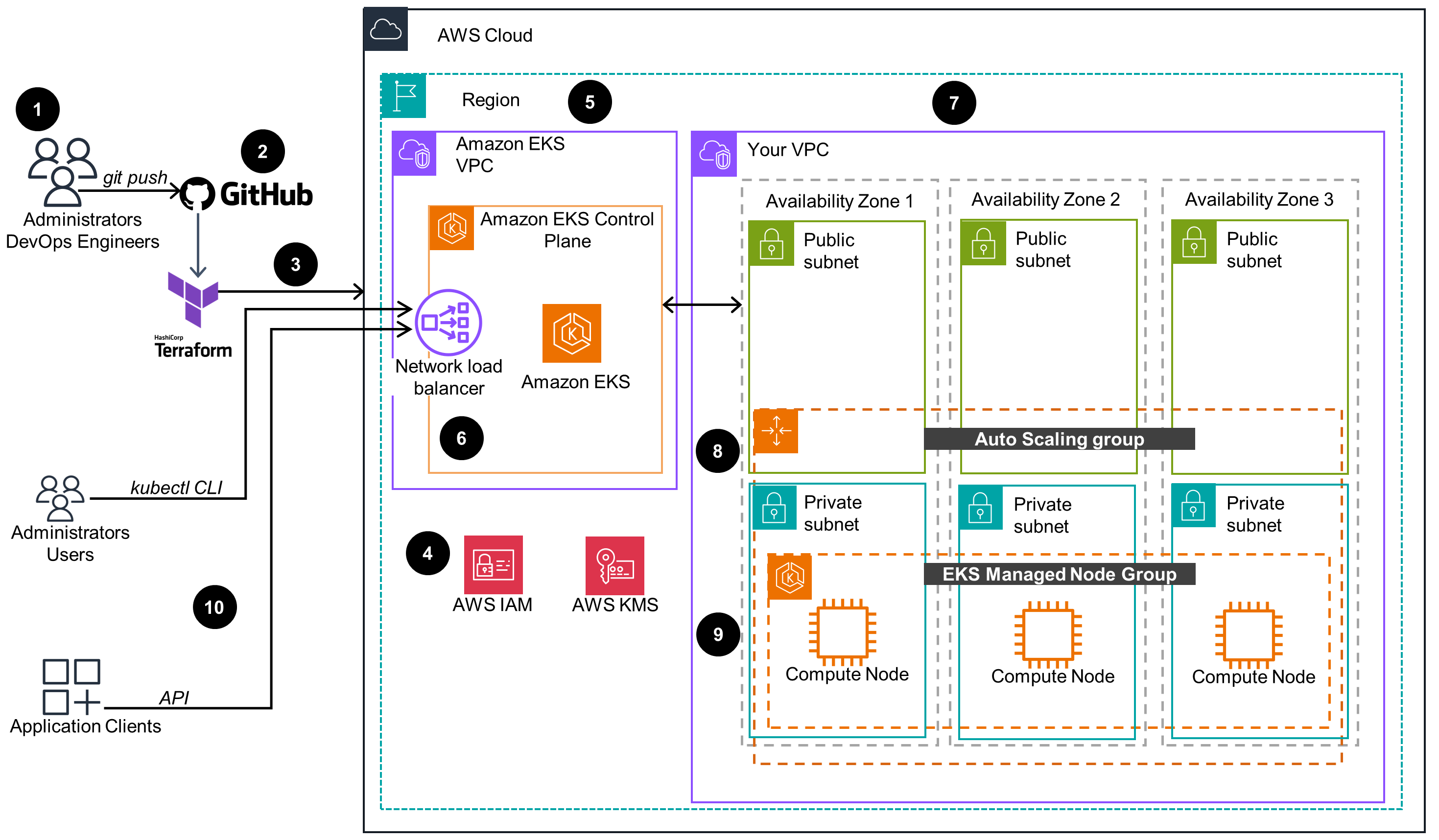
Main Architecture
This architecture demonstrates the deployment of AWS Observability Accelerator on an Amazon Elastic Kubernetes Service (Amazon EKS) cluster.
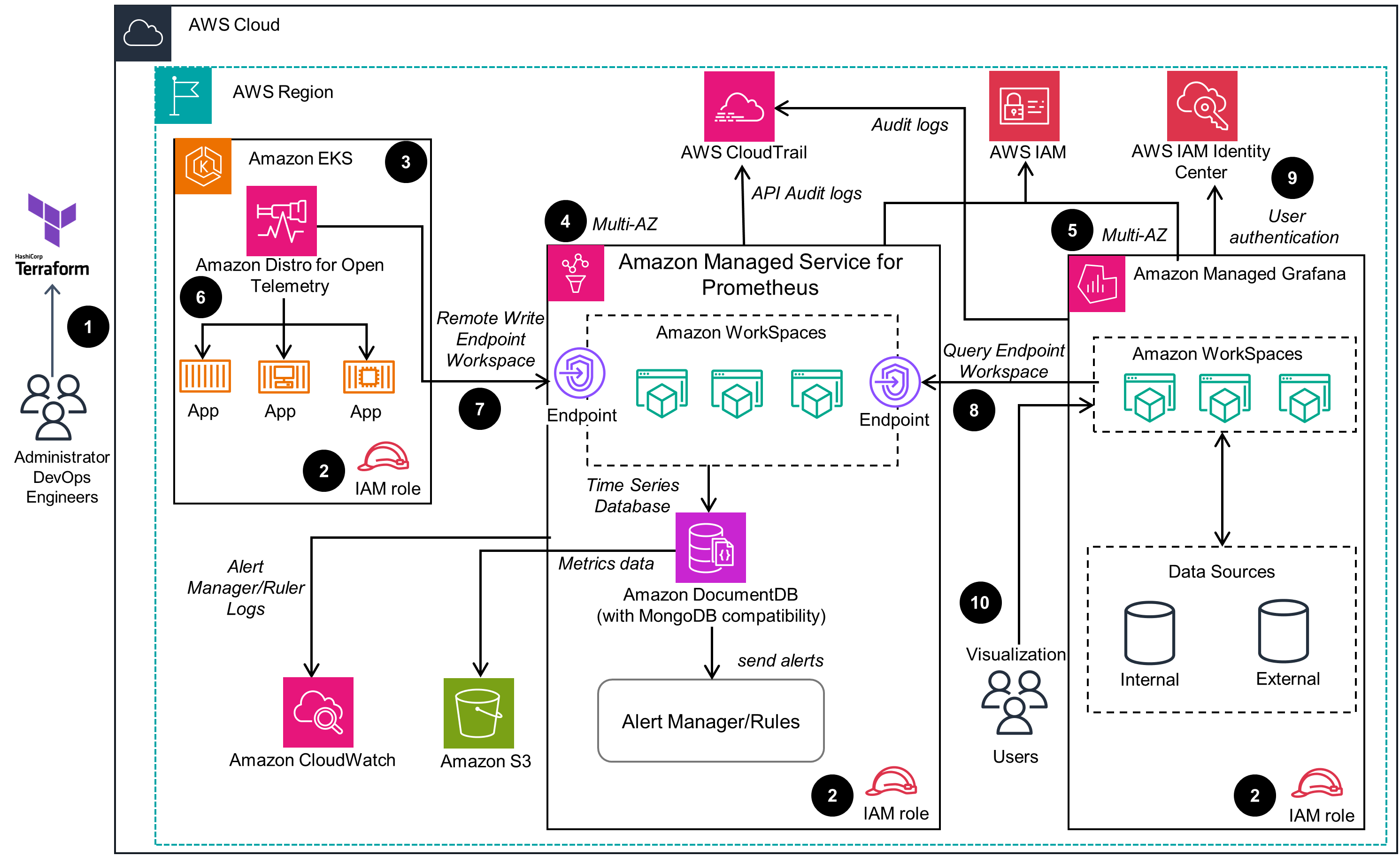
Well-Architected Pillars
The architecture diagram above is an example of a Solution created with Well-Architected best practices in mind. To be fully Well-Architected, you should follow as many Well-Architected best practices as possible.
Related Content
Disclaimer
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages