8 Septembre 2021 : Amazon Elasticsearch Service a été renommé en Amazon OpenSearch Service. Voir les détails.
Les documents nous permettent d’enregistrer des informations de tout type. Ce sont des outils de communication, collaboration et traçabilité utilisés dans tous les secteurs de l’industrie, y compris la finance, la santé, le domaine juridique, l’immobilier, etc. Les millions de dossiers de demande de prêts ou les dizaine de millions de formulaires d’impôts qui sont traités chaque année sont autant d’exemple de documents. Néanmoins, ces documents capturent la donnée de manière non-structurée et donc beaucoup d’informations y restent bloquées. Il faut généralement des traitements longs, coûteux et complexes pour permettre la recherche, la découverte et l’automatisation des processus métier ou de confirmité intégrant des documents.
Dans ce post, nous allons illustrer comment utiliser Amazon Textract pour extraire automatiquement du texte et des données à partir de documents scannées sans avoir besoin de compétences en Machine Learning (ML). AWS se charge de construire, entrainer et déployer des modèles ML avancés dans un environnement disponible et scalable, que vous allez consommer au travers d’une API simple et facile à utiliser.
Vous trouverez ci-dessous les cas d’utilisation couverts dans ce post :
- Détection de texte
- Détection multi-colonnes et ordre de lecture
- Traitement du langage naturel et classification des documents
- Traitement du langage naturel pour des documents médicaux
- Traduction de documents
- Recherche et découverte de contenu
- Extraction et traitement de formulaires
- Contrôle de conformité
- Extraction et traitement de tables
- Traitement de documents PDF
Amazon Textract
Avant de commencer, introduisions les principales fonctionnalités du service. Amazon Textract va au-delà d’un simple outil d’OCR (“Optical Character Recognition”), il permet également d’identifier le contenu des champs dans les formulaires et l’information présente dans des tableaux. Avec Amazon Textract vous allez donc pouvoir « lire » instantanément n’importe quel type de document et extraire avec précision son texte et ses données sans travaux manuels ou sans code complexe à implémenter et déployer.
Les images suivantes montrent un exemple d’extraction du texte, formulaire et tableau d’un document utilisant Amazon Textract depuis la console AWS Management Console.
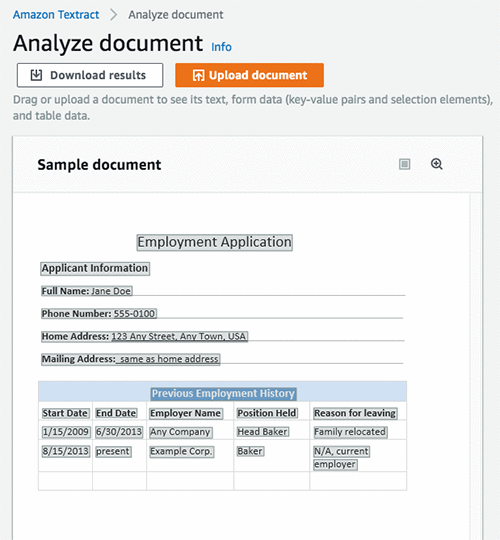
L’image suivante montre les lignes extraites sous format texte.
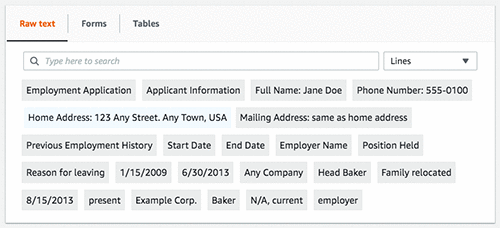
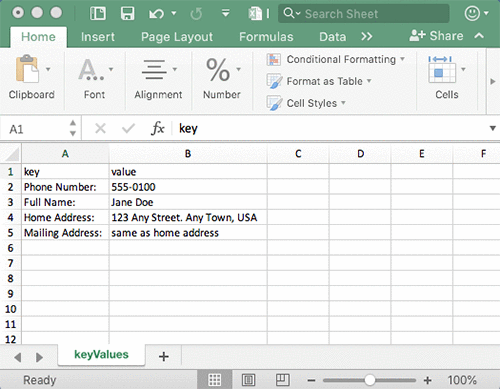
L’image suivante montre les champs extraits de la partie formulaire du document et leurs valeurs correspondantes.
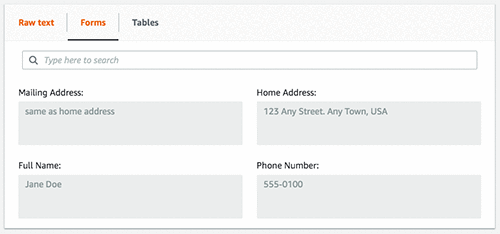
L’image suivante montre le tableau extrait, ses cellules et leur texte.
Le résultant de l’exécution peut être téléchargé en cliquant sur Download results. Plusieurs formats sont supportés, y compris JSON, .txt et CSV pour les formulaires et les tables.
En plus du contenu extrait, Amazon Textact fournit des informations supplémentaires telles que les indices de confiance et la position des éléments détectés (ie “Bounded boxes”). Ces informations vous permettent de contrôler la façon dont vous utilisez le contenu et de l’intégrer facilement à d’autres applications.
Amazon Textract fournit des API synchrones et asynchrones pour extraire et analyser le texte de documents. L’API synchrone peut être utilisée pour des documents d’une seule page et des traitements à faible latence, comme l’analyse d’un document en temps réel pris en photo avec un smartphone. L’API asynchrone peut être utilisée pour des documents multipages comme un document PDF ayant des milliers des pages. Pour plus d’informations, veuillez consulter la documentation de référence : API Amazon Textract Reference.
Textract appliqués aux différents cas d’usage
Nous allons maintenant écrire du code permettant l’invocation de l’’API d’Amazon Textract en utilisant AWS SDK et allons mettre en évidence les éléments clefs qui permettent de rendre nos applications plus intelligentes avec ce service. On utilise JSON Parser Library pour réaliser certains traitements des cas d’utilisation ci-dessous.
1. Détection de texte
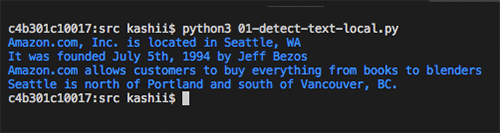
Commençons par un exemple simple de détection de texte. Utilisons l’image ci-dessous comme document. Comment vous pouvez voir, l’image n’est pas de bonne qualité, toutefois, Amazon Textract va réussir à détecter son texte correctement.

L’exemple de code ci-dessous montre comment, avec quelques lignes de code, envoyer une image à Amazon Textract et obtenir une réponse au format JSON. Une fois le texte extrait, on peut parcourir cette réponse et en afficher son résultat.
# Amazon Textract client
textract = boto3.client('textract')
# Call Amazon Textract
response = textract.detect_document_text(
Document={
'S3Object': {
'Bucket': s3BucketName,
'Name': documentName
}
})
#print(response)
# Print detected text
for item in response["Blocks"]:
if item["BlockType"] == "LINE":
print ('\033[94m' + item["Text"] + '\033[0m')
Voici ci-dessous la réponse au format JSON reçue d’Amazon Textract, avec les blocs contenant le texte détecté dans le document :
{
"Blocks": [
{
"Geometry": {
"BoundingBox": {
"Width": 1.0,
"Top": 0.0,
"Left": 0.0,
"Height": 1.0
},
"Polygon": [
{
"Y": 0.0,
"X": 0.0
},
{
"Y": 0.0,
"X": 1.0
},
{
"Y": 1.0,
"X": 1.0
},
{
"Y": 1.0,
"X": 0.0
}
]
},
"Relationships": [
{
"Type": "CHILD",
"Ids": [
"2602b0a6-20e3-4e6e-9e46-3be57fd0844b",
"82aedd57-187f-43dd-9eb1-4f312ca30042",
"52be1777-53f7-42f6-a7cf-6d09bdc15a30",
"7ca7caa6-00ef-4cda-b1aa-5571dfed1a7c"
]
}
],
"BlockType": "PAGE",
"Id": "8136b2dc-37c1-4300-a9da-6ed8b276ea97"
}.....
],
"DocumentMetadata": {
"Pages": 1
}
}
L’image suivante montre le résultat de l’exécution du code. Elle indique le texte détecté.
2. Détection multi-colonnes et ordre de lecture
Les solutions traditionnelles d’OCR lisent de gauche à droite, ne détectent pas de colonnes dans un document et par conséquent, l’ordre de lecture du document résultant est incorrect. En plus de détecter du texte, Amazon Textract fournit des informations supplémentaires sur la géométrie des éléments dans les documents qui peuvent être utilisées pour détecter plusieurs colonnes et afficher le texte de manière adéquate.
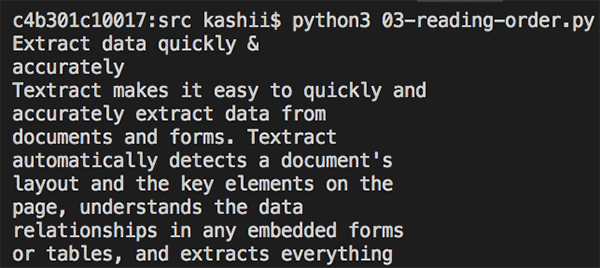
L’image suivante est un document ayant deux colonnes. Comme dans l’exemple précédent, l’image n’est pas de bonne qualité, toutefois, Amazon Textract permet de détecter son texte.

L’exemple de code suivant montre comment traiter un document avec Amazon Texttract et utiliser les informations de géométrie pour afficher le texte correctement (dans l’ordre de lecture).
import boto3
# Document
s3BucketName = "ki-textract-demo-docs"
documentName = "two-column-image.jpg"
# Amazon Textract client
textract = boto3.client('textract')
# Call Amazon Textract
response = textract.detect_document_text(
Document={
'S3Object': {
'Bucket': s3BucketName,
'Name': documentName
}
})
#print(response)
# Detect columns and print lines
columns = []
lines = []
for item in response["Blocks"]:
if item["BlockType"] == "LINE":
column_found=False
for index, column in enumerate(columns):
bbox_left = item["Geometry"]["BoundingBox"]["Left"]
bbox_right = item["Geometry"]["BoundingBox"]["Left"] + item["Geometry"]["BoundingBox"]["Width"]
bbox_centre = item["Geometry"]["BoundingBox"]["Left"] + item["Geometry"]["BoundingBox"]["Width"]/2
column_centre = column['left'] + column['right']/2
if (bbox_centre > column['left'] and bbox_centre < column['right']) or (column_centre > bbox_left and column_centre < bbox_right):
#Bbox appears inside the column
lines.append([index, item["Text"]])
column_found=True
break
if not column_found:
columns.append({'left':item["Geometry"]["BoundingBox"]["Left"], 'right':item["Geometry"]["BoundingBox"]["Left"] + item["Geometry"]["BoundingBox"]["Width"]})
lines.append([len(columns)-1, item["Text"]])
lines.sort(key=lambda x: x[0])
for line in lines:
print (line[1])
L’image suivante montre le résultat de l’exécution du code. Elle montre le texte détecté affiché dans l’ordre de lecture.
3. Traitement du langage naturel et classification des document
Les emails, les tickets de support, les avis émis sur des produits, les données sur les réseaux sociaux et même les messages publicitaires présentent des informations exploitables qui peuvent être mises au service de votre entreprise. Beaucoup d’informations sont présentes dans des images ou documents scannés. Une fois le texte extrait des documents, vous pouvez utiliser Amazon Comprehend pour analyser le sentiment, extraire les entités, les mots-clés, la syntaxe et les sujets du texte. Vous pouvez également entrainer Amazon Comprehend pour créer des entités personnalisées basées sur votre domaine d’activité. Ces informations peuvent être utilisées pour classer des documents, automatiser des processus métiers et faire des contrôles de conformité.
L’exemple de code ci-dessous montre comment utiliser Amazon Textract pour extraire le texte d’un document et puis utiliser Amazon Comprehend pour analyser les sentiments et extraire les entités du texte.
import boto3
# Document
s3BucketName = "ki-textract-demo-docs"
documentName = "simple-document-image.jpg"
# Amazon Textract client
textract = boto3.client('textract')
# Call Amazon Textract
response = textract.detect_document_text(
Document={
'S3Object': {
'Bucket': s3BucketName,
'Name': documentName
}
})
#print(response)
# Print text
print("\nText\n========")
text = ""
for item in response["Blocks"]:
if item["BlockType"] == "LINE":
print ('\033[94m' + item["Text"] + '\033[0m')
text = text + " " + item["Text"]
# Amazon Comprehend client
comprehend = boto3.client('comprehend')
# Detect sentiment
sentiment = comprehend.detect_sentiment(LanguageCode="en", Text=text)
print ("\nSentiment\n========\n{}".format(sentiment.get('Sentiment')))
# Detect entities
entities = comprehend.detect_entities(LanguageCode="en", Text=text)
print("\nEntities\n========")
for entity in entities["Entities"]:
print ("{}\t=>\t{}".format(entity["Type"], entity["Text"]))
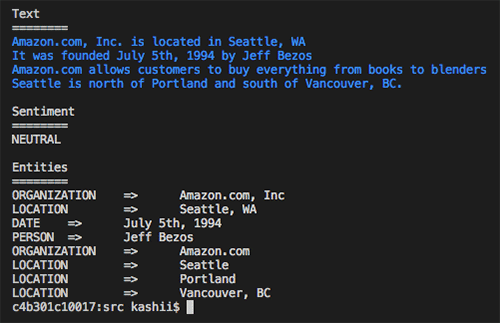
L’image suivante montre le résultat de l’exécution du code. Le code affiche le texte extrait, l’analyse du sentiment et les entités extraites. Vous pouvez voir que le sentiment est “Neutral”, “Amazon” a été classé comme “organization”, “Seattle, WA” comme “location” et “July 5th, 1994” comme “date”.
4. Traitement du langage naturel pour des documents médicaux
Pour améliorer la condition des patients et accélérer la recherche médicale, il est indispensable de comprendre et analyser les données et les relations qui sont stockées dans des documents tels que les ordonnances, les notes d’admission et les historiques des patients.
Dans l’exemple suivant, on utilise Amazon Textract pour extraire le texte d’un document médical. Puis on utilise Amazon Comprehend Medical pour extraire des entités de santé comme des états médicaux, des médicaments, des dosages et des informations des santés protégées (protected health information, PHI).

L’exemple de code ci-dessous montre comment les entités de santé sont extraites.
import boto3
# Document
s3BucketName = "ki-textract-demo-docs"
documentName = "medical-notes.png"
# Amazon Textract client
textract = boto3.client('textract')
# Call Amazon Textract
response = textract.detect_document_text(
Document={
'S3Object': {
'Bucket': s3BucketName,
'Name': documentName
}
})
#print(response)
# Print text
print("\nText\n========")
text = ""
for item in response["Blocks"]:
if item["BlockType"] == "LINE":
print ('\033[94m' + item["Text"] + '\033[0m')
text = text + " " + item["Text"]
# Amazon Comprehend client
comprehend = boto3.client('comprehendmedical')
# Detect medical entities
entities = comprehend.detect_entities(Text=text)
print("\nMidical Entities\n========")
for entity in entities["Entities"]:
print("- {}".format(entity["Text"]))
print (" Type: {}".format(entity["Type"]))
print (" Category: {}".format(entity["Category"]))
if(entity["Traits"]):
print(" Traits:")
for trait in entity["Traits"]:
print (" - {}".format(trait["Name"]))
print("\n")
L’image suivante montre le résultat de l’exécution du code. Le code affiche les entités extraites et classées par types. “40yo” a été classé comme “age” dans la catégorie “Protected Health Information”. Des autres informations sur la condition médicale, les médicaments et l’anatomie ont été détecté comme troubles du sommeil “sleeping trouble”, éruption cutanée “rash”, turbinectomie inférieure “inferior turbinates”.
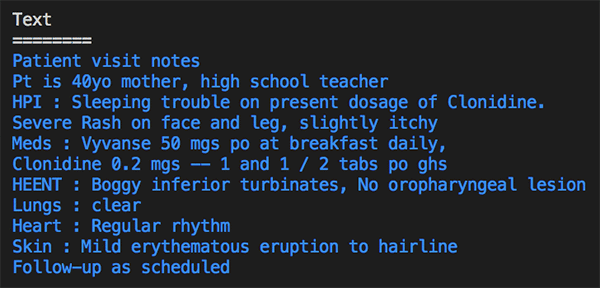
Medical Entities
========
- 40yo
Type: AGE
Category: PROTECTED_HEALTH_INFORMATION
- Sleeping trouble
Type: DX_NAME
Category: MEDICAL_CONDITION
Traits:
- SYMPTOM
- Clonidine
Type: GENERIC_NAME
Category: MEDICATION
- Rash
Type: DX_NAME
Category: MEDICAL_CONDITION
Traits:
- SYMPTOM
- face
Type: SYSTEM_ORGAN_SITE
Category: ANATOMY
- leg
Type: SYSTEM_ORGAN_SITE
Category: ANATOMY
- Vyvanse
Type: BRAND_NAME
Category: MEDICATION
- Clonidine
Type: GENERIC_NAME
Category: MEDICATION
- HEENT
Type: SYSTEM_ORGAN_SITE
Category: ANATOMY
- Boggy inferior turbinates
Type: DX_NAME
Category: MEDICAL_CONDITION
Traits:
- SIGN
- inferior
Type: DIRECTION
Category: ANATOMY
- turbinates
Type: SYSTEM_ORGAN_SITE
Category: ANATOMY
- oropharyngeal lesion
Type: DX_NAME
Category: MEDICAL_CONDITION
Traits:
- SIGN
- NEGATION
- Lungs
Type: SYSTEM_ORGAN_SITE
Category: ANATOMY
- clear Heart
Type: DX_NAME
Category: MEDICAL_CONDITION
Traits:
- SIGN
- Heart
Type: SYSTEM_ORGAN_SITE
Category: ANATOMY
- Regular rhythm
Type: DX_NAME
Category: MEDICAL_CONDITION
Traits:
- SIGN
- Skin
Type: SYSTEM_ORGAN_SITE
Category: ANATOMY
- erythematous eruption
Type: DX_NAME
Category: MEDICAL_CONDITION
Traits:
- SIGN
- hairline
Type: SYSTEM_ORGAN_SITE
Category: ANATOMY
5. Traduction de documents
De nombreuses organisations proposent du contenu dans plusieurs langues à destination d’utilisateurs partout dans le monde. Dans certains cas, il est nécessaire de traduire un grand nombre de documents. Vous pouvez utiliser Amazon Textract et Amazon Translate pour extraire du texte des documents, puis le traduire dans une autre langue.
L’exemple du code ci-dessous montre comment traduire un document en allemand.
import boto3
# Document
s3BucketName = "ki-textract-demo-docs"
documentName = "simple-document-image.jpg"
# Amazon Textract client
textract = boto3.client('textract')# Call Amazon Textract
response = textract.detect_document_text(
Document={
'S3Object': {
'Bucket': s3BucketName,
'Name': documentName
}
})
#print(response)
# Amazon Translate client
translate = boto3.client('translate')
print ('')
for item in response["Blocks"]:
if item["BlockType"] == "LINE":print ('\033[94m' + item["Text"] + '\033[0m')
result = translate.translate_text(Text=item["Text"], SourceLanguageCode="en", TargetLanguageCode="de")
print ('\033[92m' + result.get('TranslatedText') + '\033[0m')
print ('')
L’image suivante montre le résultat de l’exécution du code. Le code affiche le texte extrait et sa traduction en allemand ligne par ligne.

6. Indexation & Recherche
Vous pouvez créer un outil de recherche rapide pour des millions des documents. Le processus consiste à en extraire des données structurées, créer des index intelligents et utiliser Amazon Elasticsearch Service (Amazon ES) pour l’indexation et la recherche. Une banque ou un organisme financier peut utiliser Amazon Textract pour indexer des millions de dossiers de demande de prêt en quelques heures récupérant leurs textes, ses mots-clés et les stocker dans Amazon ES. Cela permettrait de créer un outil de recherche avancé, l’utilisateur final pourrait, par exemple, rechercher un dossier dont le nom du demandeur est John Doa, ou des contrats dont le taux d’intérêt est de 2 %.
L’exemple de code suivant montre comment extraire du texte, le sauvegarder dans Amazon ES et faire une recherche utilisant Kibana. Vous pouvez également créer votre propre interface utilisateur utilisant les APIs d’Amazon ES. Plus loin dans ce post, vous allez apprendre à extraire des données des tableaux et formulaires, de la même manière que pour le texte utilisé dans l’exemple, ces données structurées peuvent être indexées afin de créer un outil de recherche intelligent.
import boto3
from elasticsearch import Elasticsearch, RequestsHttpConnection
from requests_aws4auth import AWS4Auth
def indexDocument(bucketName, objectName, text):
# Update host with endpoint of your Elasticsearch cluster
#host = "search--xxxxxxxxxxxxxx.us-east-1.es.amazonaws.com
host = "searchxxxxxxxxxxxxxxxx.us-east-1.es.amazonaws.com"
region = 'us-east-1'
if(text):
service = 'es'
ss = boto3.Session()
credentials = ss.get_credentials()
region = ss.region_name
awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token)
es = Elasticsearch(
hosts = [{'host': host, 'port': 443}],
http_auth = awsauth,
use_ssl = True,
verify_certs = True,
connection_class = RequestsHttpConnection
)
document = {
"name": "{}".format(objectName),
"bucket" : "{}".format(bucketName),
"content" : text
}
es.index(index="textract", doc_type="document", id=objectName, body=document)
print("Indexed document: {}".format(objectName))
# Document
s3BucketName = "ki-textract-demo-docs"
documentName = "simple-document-image.jpg"
# Amazon Textract client
textract = boto3.client('textract')
# Call Amazon Textract
response = textract.detect_document_text(
Document={
'S3Object': {
'Bucket': s3BucketName,
'Name': documentName
}
})
#print(response)
# Print detected text
text = ""
for item in response["Blocks"]:
if item["BlockType"] == "LINE":
print ('\033[94m' + item["Text"] + '\033[0m')
text += item["Text"]
indexDocument(s3BucketName, documentName, text)
# You can view index documents in Kibana Dashboard
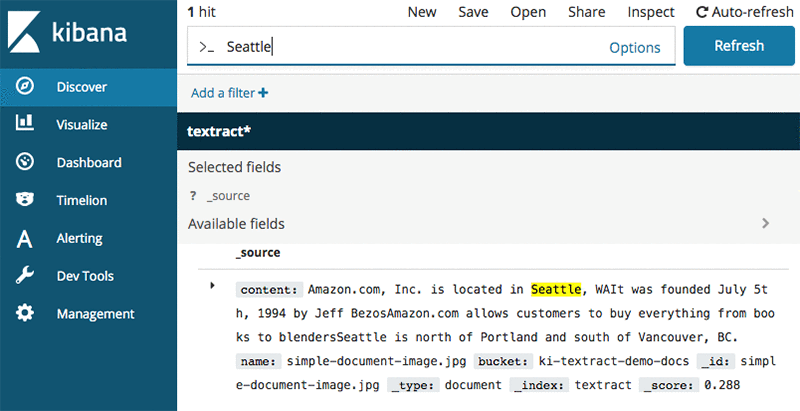
L’image suivante montre le résultat d’une recherche faite avec Kibana après l’exécution le code.
7. Extraction et Traitement de formulaires
Amazon Textract permet d’extraire des données nécessaires pour traiter des formulaires automatiquement sans intervention humaine. Une banque pourrait ainsi créer un outil pour lire des dossiers de demande de prêt en format PDF. L’information extraite du document peut être utilisée pour initialiser la vérification des références et du crédit automatiquement afin que les clients puissent obtenir une réponse rapide pour leur demande sans devoir attendre plusieurs jours une vérification manuelle.
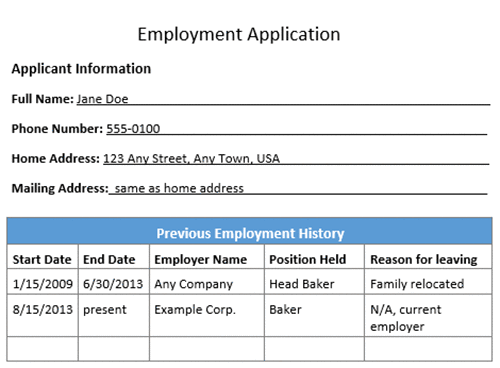
L’image suivante est un modèle de recherche d’emploi ayant un formulaire et un tableau.
L’exemple de code ci-dessous montre comment extraire le formulaire et traiter les différents champs.
import boto3
from trp import Document
# Document
s3BucketName = "ki-textract-demo-docs"
documentName = "employmentapp.png"
# Amazon Textract client
textract = boto3.client('textract')
# Call Amazon Textract
response = textract.analyze_document(
Document={
'S3Object': {
'Bucket': s3BucketName,
'Name': documentName
}
},
FeatureTypes=["FORMS"])
#print(response)
doc = Document(response)
for page in doc.pages:
# Print fields
print("Fields:")
for field in page.form.fields:
print("Key: {}, Value: {}".format(field.key, field.value))
# Get field by key
print("\nGet Field by Key:")
key = "Phone Number:"
field = page.form.getFieldByKey(key)
if(field):
print("Key: {}, Value: {}".format(field.key, field.value))
# Search fields by key
print("\nSearch Fields:")
key = "address"
fields = page.form.searchFieldsByKey(key)
for field in fields:
print("Key: {}, Value: {}".format(field.key, field.value))
L’image suivante montre le résultat de l’exécution du code. Le code détecte et affiche le formulaire du document.
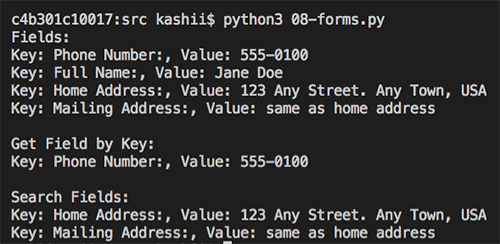
8. Controle de conformité
Amazon Textract identifiant les données et les champs des formulaires automatiquement vous aide à sécuriser votre informatique. Par exemple, une assurance peut utiliser Amazon Textract pour créer un processus qui va automatiquement identifier et masquer des données personnelles (personally identifiable information PII) avant d’archiver un formulaire de réclamation. Amazon Textract reconnaît les champs contenant des informations sensibles.
L’exemple de code suivant montre comment extraire le formulaire du modèle de demande d’emploie et masquer les adresses.
import boto3
from trp import Document
from PIL import Image, ImageDraw
# Document
s3BucketName = "ki-textract-demo-docs"
documentName = "employmentapp.png"
# Amazon Textract client
textract = boto3.client('textract')
# Call Amazon Textract
response = textract.analyze_document(
Document={
'S3Object': {
'Bucket': s3BucketName,
'Name': documentName
}
},
FeatureTypes=["FORMS"])
#print(response)
doc = Document(response)
# Redact document
img = Image.open(documentName)
width, height = img.size
if(doc.pages):
page = doc.pages[0]
for field in page.form.fields:
if(field.key and field.value and "address" in field.key.text.lower()):
#if(field.key and field.value):
print("Redacting => Key: {}, Value: {}".format(field.key.text, field.value.text))
x1 = field.value.geometry.boundingBox.left*width
y1 = field.value.geometry.boundingBox.top*height-2
x2 = x1 + (field.value.geometry.boundingBox.width*width)+5
y2 = y1 + (field.value.geometry.boundingBox.height*height)+2
draw = ImageDraw.Draw(img)
draw.rectangle([x1, y1, x2, y2], fill="Black")
img.save("redacted-{}".format(documentName))
L’image suivante montre le résultat de l’exécution du code. Le code extrait les données du formulaire et masque dans l’image les champs correspondant aux adresses.
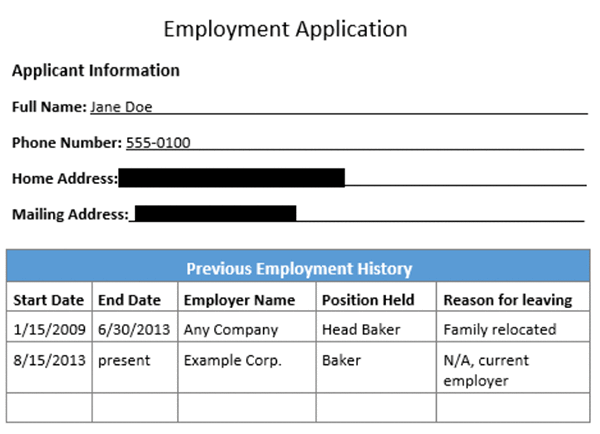
9. Extraction et traitement des tableaux
Amazon Textract permet de détecter des tableaux et ses éléments. Une entreprise peut ainsi extraire les montants d’un rapport de dépenses et appliquer des règles, par exemple, toute dépense de plus de 1000$ nécessite une validation supplémentaire.
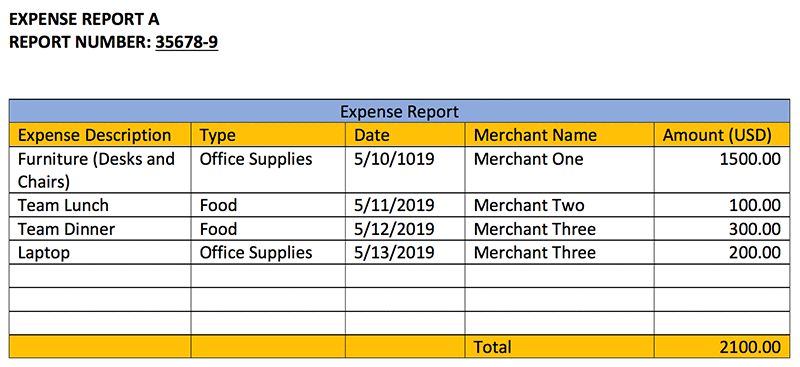
L’exemple de code suivant nous montre comment extraire le tableau du rapport de dépense ci-dessus et afficher les cellules du tableau en mettant un warning si un montant dépasse 1000$.
import boto3
from trp import Document
# Document
s3BucketName = "ki-textract-demo-docs"
documentName = "expense.png"
# Amazon Textract client
textract = boto3.client('textract')
# Call Amazon Textract
response = textract.analyze_document(
Document={
'S3Object': {
'Bucket': s3BucketName,
'Name': documentName
}
},
FeatureTypes=["TABLES"])
#print(response)
doc = Document(response)
def isFloat(input):
try:
float(input)
except ValueError:
return False
return True
warning = ""
for page in doc.pages:
# Print tables
for table in page.tables:
for r, row in enumerate(table.rows):
itemName = ""
for c, cell in enumerate(row.cells):
print("Table[{}][{}] = {}".format(r, c, cell.text))
if(c == 0):
itemName = cell.text
elif(c == 4 and isFloat(cell.text)):
value = float(cell.text)
if(value > 1000):
warning += "{} is greater than $1000.".format(itemName)
if(warning):
print("\nReview needed:\n====================\n" + warning)
L’image suivante montre le résultat de l’exécution du code. Le code affiche les cellules du tableau et son texte.
Table[0][0] = Expense Description
Table[0][1] = Type
Table[0][2] = Date
Table[0][3] = Merchant Name
Table[0][4] = Amount (USD)
Table[1][0] = Furniture (Desks and Chairs)
Table[1][1] = Office Supplies
Table[1][2] = 5/10/1019
Table[1][3] = Merchant One
Table[1][4] = 1500.00
Table[2][0] = Team Lunch
Table[2][1] = Food
Table[2][2] = 5/11/2019
Table[2][3] = Merchant Two
Table[2][4] = 100.00
Table[3][0] = Team Dinner
Table[3][1] = Food
Table[3][2] = 5/12/2019
Table[3][3] = Merchant Three
Table[3][4] = 300.00
Table[4][0] = Laptop
Table[4][1] = Office Supplies
Table[4][2] = 5/13/2019
Table[4][3] = Merchant Three
Table[4][4] = 200.00
Table[5][0] =
Table[5][1] =
Table[5][2] =
Table[5][3] =
Table[5][4] =
Table[6][0] =
Table[6][1] =
Table[6][2] =
Table[6][3] =
Table[6][4] =
Table[7][0] =
Table[7][1] =
Table[7][2] =
Table[7][3] =
Table[7][4] =
Table[8][0] =
Table[8][1] =
Table[8][2] =
Table[8][3] = Total
Table[8][4] = 2100.00
Review needed: ====================
Furniture (Desks and Chairs) is greater than $1000
10. Traitement des documents PDF (async API operations)
Dans les exemples précédents, nous avons analysé des images avec les fonctions synchrones de l’API. Maintenant, vous allez voir comment traiter des fichiers PDF en masse en utilisant des fonctions asynchrones de l’API.
On utilise StartDocumentTextDetection ou StartDocumentAnalysis pour initialiser un travail (job) Amazon Textract. Quand le travail est finit, Amazon Textract publie le résultat de la requête, y compris son status, sur Amazon SNS. On utilise GetDocumentTextDetection ou GetDocumentAnalysis pour récupérer les résultant d’Amazon Textract.
L’exemple de code suivant montre comment initier un travail (Job), récupérer son statut et traiter son résultat. Cliquer ici pour télécharger le document pdf utilisé dans l’exemple. Pour plus d’informations, veuillez regarder Calling Amazon Textract Asynchronous Operations.
import boto3
import time
def startJob(s3BucketName, objectName):
response = None
client = boto3.client('textract')
response = client.start_document_text_detection(
DocumentLocation={
'S3Object': {
'Bucket': s3BucketName,
'Name': objectName
}
})
return response["JobId"]
def isJobComplete(jobId):
# For production use cases, use SNS based notification
# Details at: https://docs.aws.amazon.com/textract/latest/dg/api-async.html
time.sleep(5)
client = boto3.client('textract')
response = client.get_document_text_detection(JobId=jobId)
status = response["JobStatus"]
print("Job status: {}".format(status))
while(status == "IN_PROGRESS"):
time.sleep(5)
response = client.get_document_text_detection(JobId=jobId)
status = response["JobStatus"]
print("Job status: {}".format(status))
return status
def getJobResults(jobId):
pages = []
client = boto3.client('textract')
response = client.get_document_text_detection(JobId=jobId)
pages.append(response)
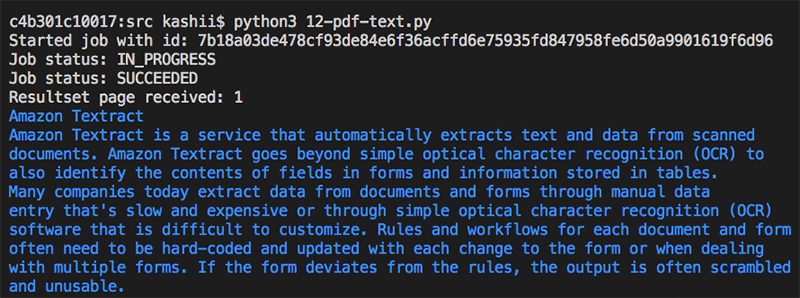
print("Resultset page recieved: {}".format(len(pages)))
nextToken = None
if('NextToken' in response):
nextToken = response['NextToken']
while(nextToken):
response = client.get_document_text_detection(JobId=jobId, NextToken=nextToken)
pages.append(response)
print("Resultset page recieved: {}".format(len(pages)))
nextToken = None
if('NextToken' in response):
nextToken = response['NextToken']
return pages
# Document
s3BucketName = "ki-textract-demo-docs"
documentName = "Amazon-Textract-Pdf.pdf"
jobId = startJob(s3BucketName, documentName)
print("Started job with id: {}".format(jobId))
if(isJobComplete(jobId)):
response = getJobResults(jobId)
#print(response)
# Print detected textfor resultPage in response:
for item in resultPage["Blocks"]:
if item["BlockType"] == "LINE":
print ('\033[94m' + item["Text"] + '\033[0m')
L’image suivante montre le statut du travail lors de l’appel de l’API.
Conclusion
Dans ce post, nous avons montré comment utiliser Amazon Textract pour extraire du texte et des données des documents scannés automatiquement sans avoir de compétences particulières en machine learning (ML). On a couvert des cas d’utilisation dans différents domaines tels que la finance, la santé, ou les ressources humaines, mais il existe des nombreuses opportunités et industries où Textract peut être utilisé afin de récupérer des informations stockées dans des documents non-structurés.
Pour en savoir plus sur Amazon Textract, veuillez consulter les liens suivants: traitement de documents single-page and multi-page, travaillant avec block objects, et exemples de code.
Post original de Kashif Imran et traduit de l’anglais par Felix Guglielmi Miguel, Solutions Architect accompagnant ses clients français dans leur adoption du Cloud AWS, LinkedIn.
Source