- Machine Learning
- Amazon SageMaker AI
- MLOps d’Amazon SageMaker AI
Amazon SageMaker pour MLOps
Fournir rapidement des modèles ML de production très performants à l'échelle
Pourquoi choisir les MLOps d’Amazon SageMaker ?
Fonctionnement
Les avantages des MLOps de SageMaker
-
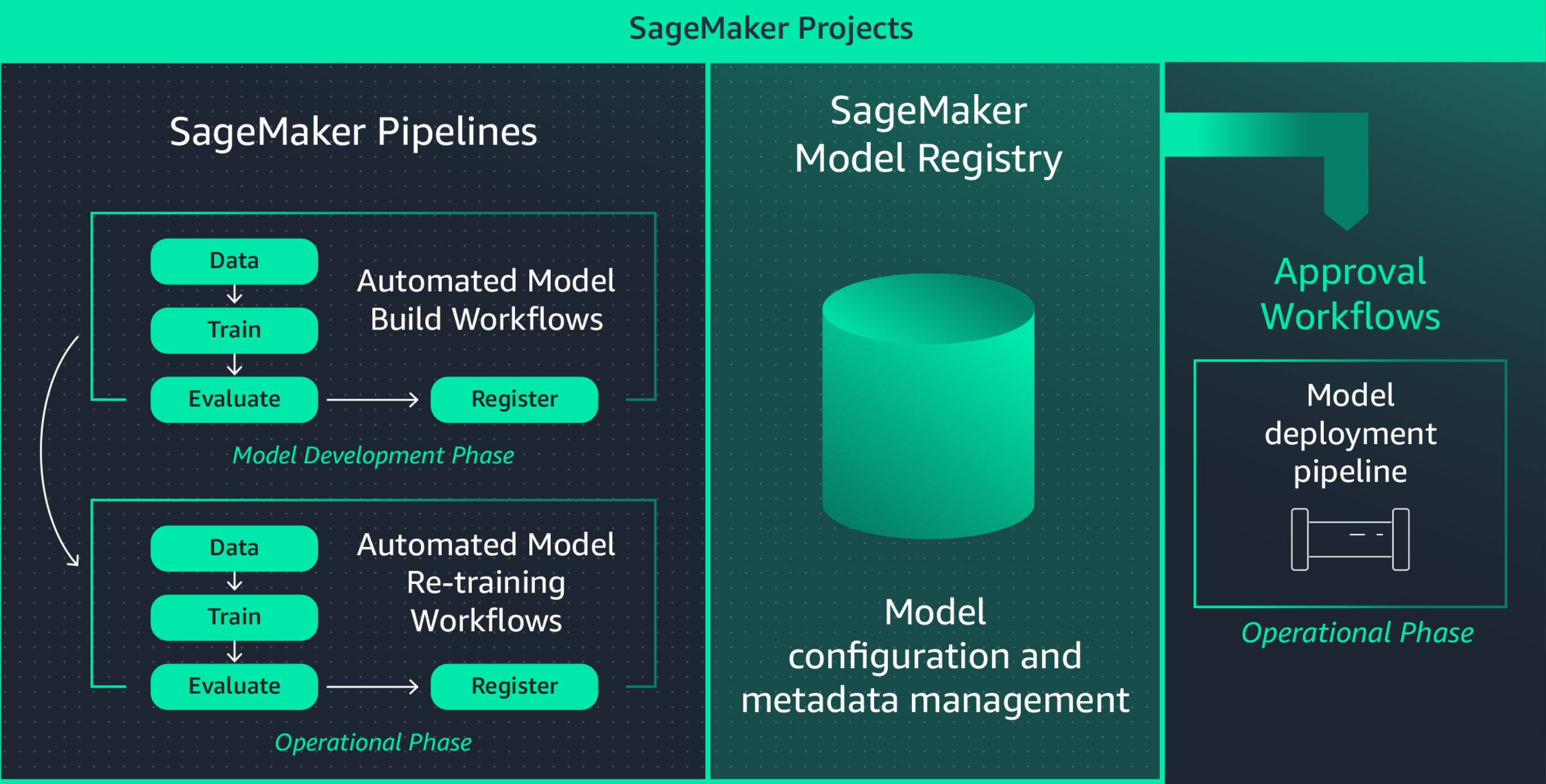
Créer des flux d’entraînement reproductibles pour accélérer le développement de modèles
-
Cataloguez les artefacts ML de manière centralisée pour la reproductibilité et la gouvernance des modèles
-
Intégrer les flux de travail ML aux pipelines CI/CD pour une production plus rapide
-
Contrôler en permanence les données et les modèles en production pour en maintenir la qualité
Accélérer le développement de modèles
Fournir des environnements normalisés pour la science des données
La standardisation des environnements de développement ML augmente la productivité des experts en mégadonnées et, en fin de compte, le rythme de l'innovation en facilitant le lancement de nouveaux projets, la rotation de ces experts entre les projets et la mise en œuvre des meilleures pratiques ML. Les projets Amazon SageMaker propose des modèles permettant de fournir rapidement des environnements standardisés pour les experts en données, avec des outils et des bibliothèques à jour et bien testés, des dépôts de contrôle des sources, du code standard et des pipelines CI/CD.
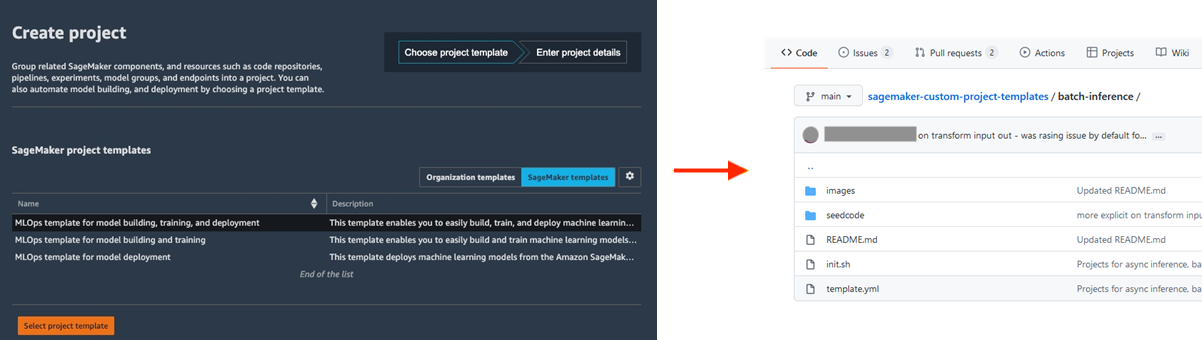
Collaborer à l’aide de MLflow pendant l’expérimentation du ML
La création de modèles ML est un processus itératif qui implique la formation de centaines de modèles afin de trouver le meilleur algorithme, la meilleure architecture et les meilleurs paramètres pour une précision de modèle optimale. MLflow vous permet de suivre les entrées et les sorties au cours de ces itérations de formation, améliorant ainsi la répétabilité des essais et favorisant la collaboration entre les data scientists. Grâce aux fonctionnalités MLflow entièrement gérées, vous pouvez créer des serveurs de suivi MLflow pour chaque équipe, ce qui facilite une collaboration efficace lors des expérimentations ML.
Amazon SageMaker avec MLflow gère le cycle de vie de bout en bout du machine learning, en rationalisant la formation efficace des modèles, le suivi des expériences et la reproductibilité dans différents cadres et environnements. Il offre une interface unique qui permet de visualiser les travaux d’entraînement en cours, de partager des expériences avec des collègues et d’enregistrer des modèles directement à partir d’une expérience.
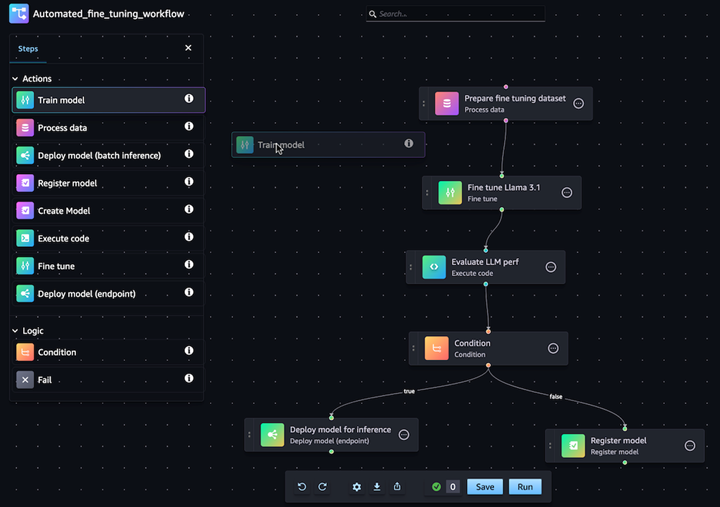
Automatiser les flux de travail de personnalisation des modèles d’IA générative
Avec Amazon SageMaker Pipelines, vous pouvez automatiser le flux de travail ML de bout en bout pour le traitement des données, l’entraînement de modèle, la mise au point, l’évaluation et le déploiement. Créez votre propre modèle ou personnalisez un modèle de fondation à partir de SageMaker Jumpstart en quelques clics dans l’éditeur visuel de Pipelines. Vous pouvez configurer les Pipelines SageMaker pour qu’ils s’exécutent automatiquement, à intervalles réguliers ou lorsque certains événements sont déclenchés (par exemple, de nouvelles données d’entraînement dans S3)
Déployer et gérer facilement les modèles en production
Reproduire rapidement vos modèles pour le dépannage
Souvent, vous devez reproduire des modèles en production pour dépanner le comportement du modèle et déterminer la cause racine. Pour vous aider, Amazon SageMaker enregistre chaque étape de votre flux de travail, créant une piste d'audit des artefacts du modèle, tels que les données d'entraînement, les paramètres de configuration, les paramètres du modèle et les gradients d'apprentissage. Grâce au suivi de la traçabilité, vous pouvez recréer des modèles pour déboguer les problèmes potentiels.
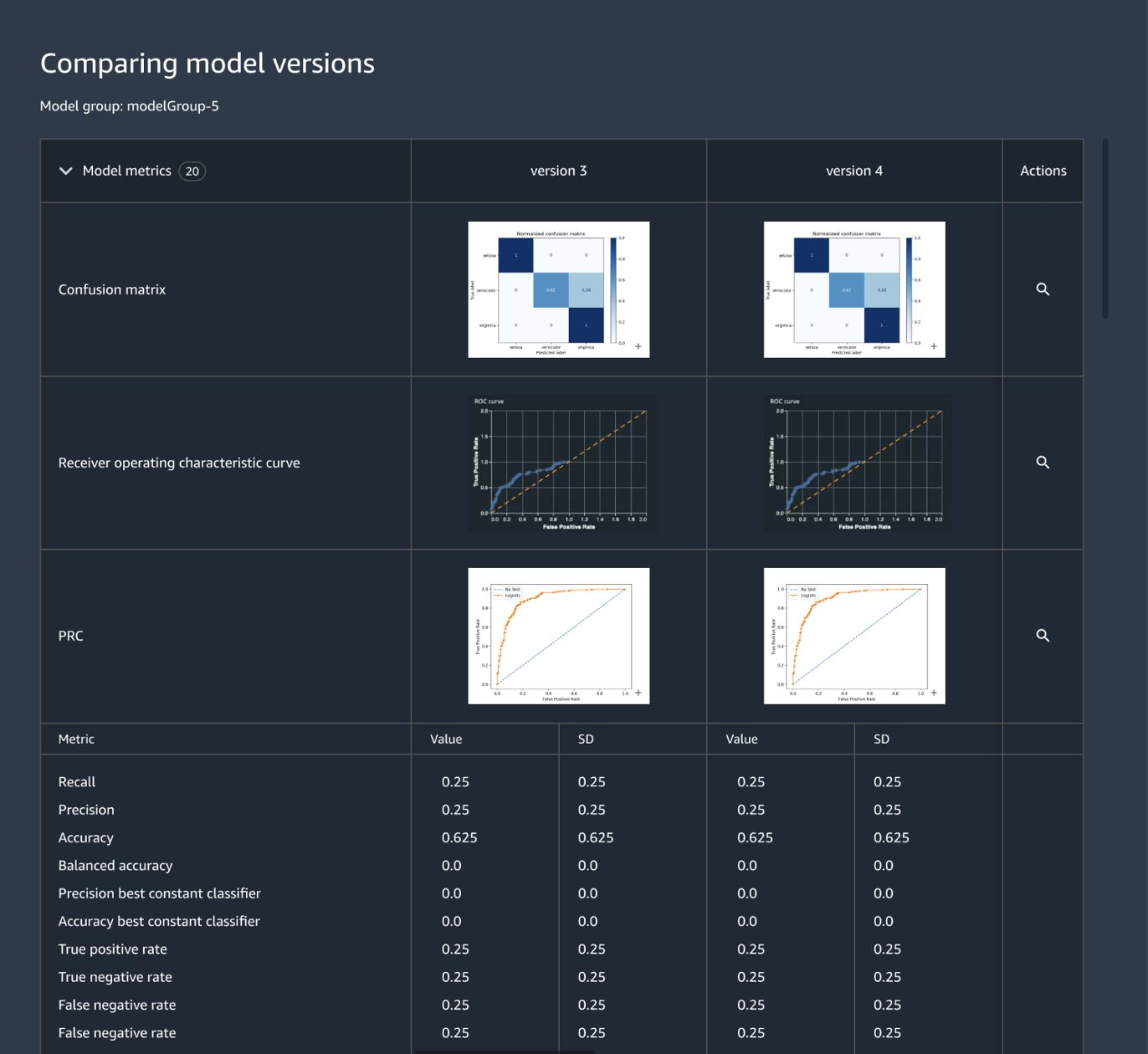
Suivre et gérer les versions de modèles de façon centralisée
La construction d'une application ML implique le développement de modèles, de pipelines de données, de pipelines d'entraînement et de tests de validation. Grâce à Amazon SageMaker Model Registry, vous pouvez suivre les versions des modèles, leurs métadonnées, telles que le regroupement des cas d'utilisation, et les bases des mesures de performance des modèles dans un référentiel central où il est facile de choisir le bon modèle à déployer en fonction des exigences de votre entreprise. En outre, SageMaker Model Registry enregistre automatiquement les flux d'approbation à des fins d'audit et de conformité.
Définir l’infrastructure ML par un code
L'orchestration de l'infrastructure par le biais de fichiers de configuration déclaratifs, communément appelée infrastructure en tant que code (infrastructure-as-code), est une approche populaire pour provisionner l'infrastructure ML et mettre en œuvre l'architecture de la solution exactement comme spécifié par les pipelines CI/CD ou les outils de déploiement. Grâce aux projets Amazon SageMaker, vous pouvez écrire une infrastructure en tant que code à l’aide de fichiers modèles préétablis.
Automatiser les flux d’intégration et de déploiement (CI/CD)
Les flux de développement du ML doivent s'intégrer aux flux d'intégration et de déploiement afin de fournir rapidement de nouveaux modèles pour les applications de production. Amazon SageMaker Projects apporte les pratiques CI/CD à ML, telles que le maintien de la parité entre les environnements de développement et de production, le contrôle des sources et des versions, les tests A/B et l'automatisation de bout en bout. Ainsi, vous mettez un modèle en production dès qu'il est approuvé et gagnez en efficacité.
En outre, Amazon SageMaker offre des garanties intégrées pour vous aider à maintenir la disponibilité des points de terminaison et à minimiser les risques de déploiement. Pour vous aider à identifier automatiquement les problèmes à un stade précoce et à prendre des mesures correctives avant qu’ils n’aient un impact significatif sur la production, SageMaker se charge de mettre en place et d’orchestrer les meilleures pratiques de déploiement telles que les déploiements bleu/vert pour maximiser la disponibilité et leur intégration aux mécanismes de mise à jour des points de terminaison, tels que les mécanismes de restauration automatique.
Réentraîner continuellement les modèles pour maintenir la qualité des prédictions
Une fois qu'un modèle est en production, vous devez surveiller ses performances en configurant des alertes afin qu'un expert des données d'astreinte puisse résoudre le problème et déclencher une nouvelle formation. Amazon SageMaker Model Monitor vous aide à maintenir la qualité en détectant la dérive du modèle et du concept en temps réel et en vous envoyant des alertes pour que vous puissiez prendre des mesures immédiates. SageMaker Model Monitor surveille en permanence les caractéristiques de performance des modèles, telle que la précision, qui mesure le nombre de prédictions correctes par rapport au nombre total de prédictions, afin que vous puissiez remédier aux anomalies. SageMaker Model Monitor est intégré à SageMaker Clarify pour améliorer la visibilité des biais potentiels.
Optimiser le déploiement du modèle en termes de performances et de coûts
Amazon SageMaker permet de déployer facilement des modèles ML pour l'inférence à haute performance et à faible coût pour tous les cas d'utilisation. Il offre une large sélection d’options d’infrastructure et de déploiement de modèles ML pour répondre à tous vos besoins d’inférence ML.

Ressources relatives aux MLOps de SageMaker Studio
Nouveautés
Lancement d’expériences Amazon SageMaker Autopilot à partir d’Amazon SageMaker Pipelines pour automatiser facilement les flux de travail MLOps
30/11/2022
Amazon SageMaker Pipelines prend désormais en charge le test des flux de travail de machine learning dans votre environnement local
17/08/2022
Amazon SageMaker Pipelines prend désormais en charge le partage d’entités de type pipelines entre les comptes
09/08/2022
L’orchestrateur de charges de travail MLOps prend désormais en charge l’explicabilité des modèles et la surveillance de biais de modèles d’Amazon SageMaker
02/02/2022
Amazon SageMaker Pipelines prend désormais en charge le contrôle de la simultanéité
21/01/2022