Blog AWS Indonesia
Pemrosesan dokumen secara cerdas dengan Amazon Textract, Amazon Bedrock, dan LangChain
Di era informasi saat ini, volume data yang sangat besar yang terdapat dalam berbagai dokumen menimbulkan tantangan dan peluang bisnis. Metode pemrosesan dokumen tradisional seringkali kurang efisien dan akurat, meninggalkan ruang untuk inovasi, efisiensi biaya, dan optimisasi. Pemrosesan dokumen telah mengalami kemajuan signifikan dengan munculnya Intelligent Document Processing (IDP). Dengan IDP, bisnis dapat mengubah data tidak terstruktur dari berbagai jenis dokumen menjadi informasi terstruktur yang bernilai, secara signifikan meningkatkan efisiensi dan mengurangi kerja manual. Namun, potensinya tidak berhenti di situ. Dengan mengintegrasikan kecerdasan buatan generatif (Generative AI) ke dalam proses ini, kita dapat lebih meningkatkan kemampuan IDP. Generative AI tidak hanya membantu kemampuan tambahan dalam pemrosesan dokumen, tetapi juga memperkenalkan adaptabilitas dinamis terhadap pola data yang berubah. Posting ini akan membawa Anda memahami sinergi antara IDP dan generative AI, bagaimana keduanya mewakili teknologi terdepan berikutnya dalam pemrosesan dokumen.
Kami membahas IDP secara rinci dalam seri postingan tentang Intelligent Document Processing dengan Layanan Kecerdasan Buatan dari AWS (Bagian 1 dan Bagian 2). Dalam posting ini, kami membahas bagaimana memperluas arsitektur IDP yang baru atau yang sudah ada dengan Large Language Model (LLM). Lebih khusus, kami membahas bagaimana kita dapat mengintegrasikan Amazon Textract dengan LangChain sebagai dokumen loader dan Amazon Bedrock untuk mengekstrak data dari dokumen dan menggunakan kemampuan Generative AI dalam berbagai fase IDP.
Amazon Textract adalah layanan machine learning (ML) yang secara otomatis mengekstrak teks, tulisan tangan, dan data dari dokumen yang discan. Amazon Bedrock adalah layanan managed service yang menawarkan pilihan foundation model (FM) melalui API yang mudah digunakan.
Gambaran umum solusi
Diagram berikut adalah referensi arsitektur high level yang menjelaskan bagaimana Anda dapat lebih meningkatkan alur kerja IDP dengan foundation model (FM). Anda dapat menggunakan LLM dalam satu atau semua fase IDP tergantung pada kasus penggunaan dan hasil yang diinginkan.
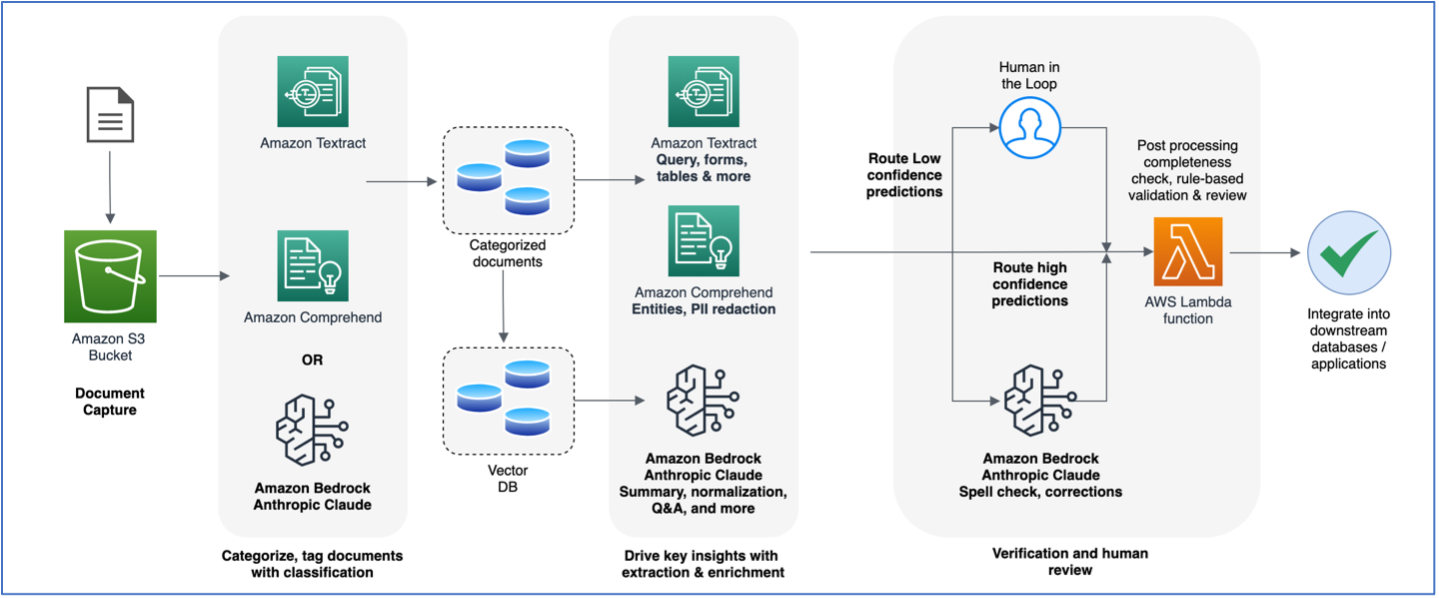
Pada arsitektur ini, LLM digunakan untuk melakukan task yang spesifik didalam workflow IDP
- Klasifikasi dokumen – Selain menggunakan Amazon Comprehend, Anda dapat menggunakan LLM untuk mengklasifikasikan dokumen dengan menggunakan “few-shot prompting.” Few-shot prompting melibatkan pemberian prompt pada language model yang berbeda untuk beberapa tipe kelas dan dari semua tipe yang memungkinkan, lalu meminta model untuk mengklasifikasikan potongan teks yang diberikan dari dokumen menggunakan salah satu tipe tersebut.
- Ringkasan – Anda juga dapat menggunakan LLM untuk merangkum dokumen yang lebih besar guna memberikan ringkasan yang tepat dalam fase ekstraksi IDP. Sebagai contoh, sistem analisis keuangan mungkin melibatkan analisis ratusan halaman dokumen pendapatan perusahaan. Anda dapat menggunakan language model untuk merangkum aspek-aspek kunci dari pendapatan tersebut, sehingga memungkinkan para analis untuk membuat keputusan bisnis.
- Standarisasi dan Pertanyaan & Jawaban dalam Konteks – Selain mengekstrak informasi yang tepat dari dokumen menggunakan fungsi Amazon Textract Analyze Document, Anda dapat menggunakan LLM untuk mengekstrak informasi yang mungkin tidak dapat diambil dengan jelas dari dokumen. Sebagai contoh, rangkuman surat pernyataan pasien mungkin mencantumkan tanggal masuk rumah sakit dan tanggal keluar pasien, tetapi mungkin tidak secara eksplisit menyebutkan jumlah total hari pasien berada di rumah sakit. Anda dapat menggunakan LLM untuk menghitung jumlah total hari pasien dirawat di rumah sakit, berdasarkan dua tanggal yang diekstrak oleh Amazon Textract. Nilai ini kemudian dapat diberi alias yang dikenal dengan format key-value yang dinormalisasi, yang membuat konsumsi dan post-processing lebih mudah dipahami.
- Pembuatan Template dan Normalisasi – Pipeline IDP seringkali menghasilkan output yang harus sesuai dengan skema deterministik tertentu. Hal ini dilakukan agar output yang dihasilkan menggunakan workflow IDP dapat digunakan dalam sistem lainnya, misalnya dalam database relasional. Manfaat lain dari menentukan skema deterministik adalah untuk mencapai normalisasi key sehingga kita memiliki seperangkat key yang dikenal untuk diproses dalam post-processing logic. Sebagai contoh, kita mungkin ingin menentukan “DOB” sebagai key yang dinormalisasi untuk “tanggal lahir”, “tanggal ulang tahun,” “tanggal kelahiran”, dan sebagainya, karena dokumen dapat datang dengan variasi apapun dari ini. Kami menggunakan LLM untuk melakukan pembuatan template dan ekstraksi key-value yang dinormalisasi pada dokumen apa pun.
- Pemeriksaan Ejaan (Spellcheck) dan Koreksi – Meskipun Amazon Textract dapat mengekstrak nilai-nilai yang tepat dari dokumen yang discan (dicetak atau ditulis tangan), Anda dapat menggunakan language model untuk mengidentifikasi apakah terdapat kesalahan pengejaan dan kesalahan tata bahasa dalam data yang diekstrak. Hal ini penting dalam situasi di mana data dapat diekstrak dari dokumen berkualitas buruk atau ditulis tangan dan digunakan untuk menghasilkan materi marketing, laporan cepat, dan sebagainya. Selain melalui manusia yang secara manual mereview ekstraksi dengan skor rendah dari Amazon Textract, Anda dapat menggunakan LLM untuk memperkuat proses review dengan memberikan rekomendasi perbaikan kepada pemeriksa manusia, sehingga mempercepat proses review.
Pada bagian berikut, kita akan membahas secara mendalam bagaimana Amazon Textract diintegrasikan ke dalam workflow generative AI menggunakan LangChain untuk memproses dokumen untuk setiap task tertentu ini. Blok kode yang disediakan di sini telah dipotong untuk kejelasan. Silakan lihat repositori GitHub kami untuk Python notebooks yang lebih detil.
Dokumen loader dengan Amazon Textract LangChain
Ekstraksi teks dari dokumen adalah aspek yang sangat penting dalam pemrosesan dokumen dengan LLM. Anda dapat menggunakan Amazon Textract untuk mengekstrak teks mentah yang tidak terstruktur dari dokumen dan mempertahankan objek semi-terstruktur atau terstruktur yang asli seperti pasangan key-value dan tabel yang ada dalam dokumen. Contohnya seperti dokumen klaim kesehatan dan asuransi atau hipotek terdiri dari formulir yang kompleks dan mengandung banyak informasi dalam berbagai format terstruktur, semi-terstruktur, dan tidak terstruktur. Ekstraksi dokumen adalah langkah penting di sini karena LLM mendapatkan manfaat dari konten yang masif untuk menghasilkan respon yang lebih akurat dan relevan, yang sebaliknya dapat memengaruhi kualitas output LLM.
LangChain adalah framework open-source untuk integrasi dengan LLM. Secara umum, LLM sangat fleksibel, tetapi mungkin mengalami kesulitan dalam task-task tertentu yang berdomain khusus dimana diperlukan konteks yang lebih dalam dan respons yang sesuai. LangChain memberikan developer skenario untuk membangun agen yang dapat memecah task yang kompleks menjadi task-task kecil. Task-task kecil ini kemudian dapat memperkenalkan konteks dan memori ke dalam LLM dengan menghubungkan dan mengaitkan (chaining) prompt LLM.
LangChain memiliki dokumen loader yang dapat memuat dan mengubah data dari dokumen. Anda dapat menggunakannya untuk mengorganisir dokumen ke dalam format yang diinginkan yang dapat diproses oleh LLM. AmazonTextractPDFLoader adalah tipe dokumen loader yang merupakan jenis loader layanan yang menyediakan cara cepat untuk mengotomatisasi pemrosesan dokumen dengan menggunakan Amazon Textract bersama dengan LangChain. Untuk informasi lebih lanjut mengenai AmazonTextractPDFLoader, lihat dokumentasi LangChain. Untuk menggunakan dokumen loader Amazon Textract, Anda memulainya dengan mengimpor dari library LangChain:
Anda dapat mengambil dokumen dari sebuah HTTPS URL endpoint dan juga dokumen yang dihosting di dalam bucket Amazon Simple Storage Service (Amazon S3) melalui Amazon S3 object URL (juga disebut path style access):
Anda juga dapat menyimpan dokumen di Amazon S3 dan merujuknya menggunakan pola URL s3://, seperti yang dijelaskan dalam mengakses bucket melalui S3://, dan meneruskan path S3 ini ke PDF Amazon Textract loader:
Sebuah dokumen multipage akan berisi beberapa halaman teks, yang kemudian dapat diakses melalui objek dokumen, yang merupakan daftar halaman. Kode berikut melakukan perulangan melalui halaman-halaman dalam objek dokumen dan mencetak teks dokumen, yang dapat diakses melalui atribut page_content:
Klasifikasi Dokumen
Amazon Comprehend dan LLM dapat digunakan secara efektif untuk klasifikasi dokumen. Amazon Comprehend adalah layanan natural language processing (NLP) yang menggunakan ML untuk mengekstrak informasi dari teks. Amazon Comprehend juga mendukung pelatihan model klasifikasi kustom dengan pemahaman layout pada dokumen seperti PDF, Word, dan format gambar. Untuk informasi lebih lanjut tentang penggunaan pengklasifikasian dokumen Amazon Comprehend, lihat artikel “Amazon Comprehend document classifier adds layout support for higher accuracy”.
Ketika digabungkan dengan LLM, klasifikasi dokumen menjadi lebih baik untuk mengelola volume dokumen yang besar. LLM membantu dalam klasifikasi dokumen karena ia dapat menganalisis teks, pola, dan elemen kontekstual dalam dokumen menggunakan NLP. Anda juga dapat menyesuaikannya untuk kelas dokumen tertentu. Ketika jenis dokumen baru diperkenalkan dalam alur kerja IDP dan memerlukan klasifikasi, LLM dapat memproses teks dan mengategorikan dokumen tersebut berdasarkan serangkaian kelas. Berikut adalah contoh kode yang menggunakan dokumen loader LangChain yang didukung oleh Amazon Textract untuk mengekstrak teks dari dokumen dan menggunakannya untuk mengklasifikasikan dokumen. Kami menggunakan model Anthropic Claude v2 melalui Amazon Bedrock untuk melakukan klasifikasi.
Pada contoh berikut, kami pertama-tama mengekstrak teks dari laporan pemulangan pasien dan menggunakan LLM untuk mengklasifikasinya dengan memberikan daftar tiga jenis dokumen yang berbeda—RINGKASAN_PENGELUARAN, BUKTI, dan RESEP. Screenshot berikut menunjukkan laporan kami.

Kami menggunakan kode berikut:
Kode di atas menghasilkan output berikut:
The provided document is a DISCHARGE_SUMMARY
Ringkasan Dokumen
Ringkasan melibatkan penyusutan teks atau dokumen yang diberikan ke dalam versi yang lebih pendek sambil mempertahankan informasi utama. Teknik ini bermanfaat untuk pengambilan informasi yang efisien, yang memungkinkan pengguna dengan cepat memahami poin-poin utama dari dokumen tanpa harus membaca seluruh kontennya. Meskipun Amazon Textract tidak secara langsung melakukan ringkasan teks, ia memberikan kemampuan dasar untuk mengekstrak seluruh teks dari dokumen. Teks yang diekstrak ini berfungsi sebagai masukan untuk model LLM kami dalam menjalankan tugas ringkasan teks.
Dengan menggunakan laporan pemulangan sampel yang sama, kami menggunakan AmazonTextractPDFLoader untuk mengekstrak teks dari dokumen ini. Seperti sebelumnya, kami menggunakan model Claude v2 melalui Amazon Bedrock dan menginisiasinya dengan prompt yang berisi instruksi tentang apa yang harus dilakukan dengan teks (dalam kasus ini, ringkasan). Terakhir, kami menjalankan rangkaian LLM dengan memberikan teks yang diekstrak dari dokumen loader. Ini menjalankan inferensi pada LLM dengan prompt yang berisi instruksi untuk merangkum, dan teks dokumen yang ditandai sebagai Document. Lihat kode berikut:
Kode tersebut menghasilkan ringkasan laporan pemulangan pasien:
Contoh sebelumnya menggunakan dokumen satu halaman untuk melakukan ringkasan. Namun, kemungkinan Anda akan berurusan dengan dokumen yang berisi beberapa halaman yang perlu diringkas. Cara umum untuk melakukan ringkasan pada beberapa halaman adalah dengan pertama-tama menghasilkan ringkasan pada potongan teks yang lebih kecil dan kemudian menggabungkan ringkasan yang lebih kecil untuk mendapatkan ringkasan akhir dari dokumen. Perlu diingat bahwa metode ini memerlukan beberapa panggilan ke LLM. Logika ini dapat dibuat dengan mudah; namun, LangChain menyediakan built-in summarize bawaan yang dapat merangkum teks besar (dari dokumen multipage). Proses ringkasan dapat terjadi baik melalui map_reduce atau dengan opsi stuff, yang tersedia sebagai opsi untuk mengelola multi-call ke LLM. Pada contoh berikut, kami menggunakan map_reduce untuk merangkum dokumen multipage. Gambar berikut menjelaskan alur kerja kami.
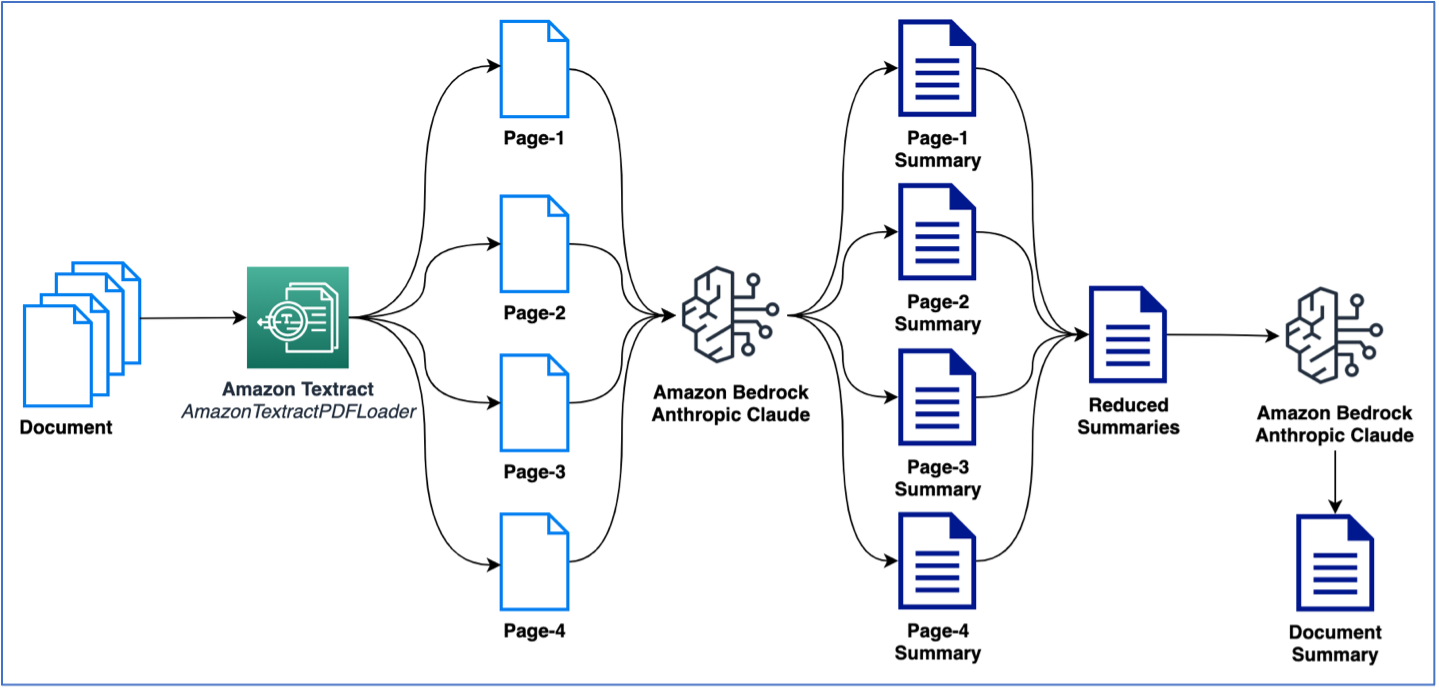
Mari kita mulai dengan mengekstrak dokumen dan melihat total jumlah token per halaman serta jumlah total halaman:
Selanjutnya, kami menggunakan LangChain’s built-in load_summarize_chain untuk merangkum seluruh dokumen:
Standarisasi dan Pertanyaan & Jawaban (Q&A)
Pada bagian ini, kita akan membahas task-task pemrosesan berkaitan dengan standarisasi dan Pertanyaan & Jawaban (Q&A).
Standarisasi
Standarisasi output adalah task untuk menghasilkan teks di mana LLM digunakan untuk memberikan pemformatan yang konsisten pada teks output. Task ini sangat berguna untuk otomatisasi ekstraksi entitas kunci yang memerlukan output yang selaras dengan format yang diinginkan. Sebagai contoh, kita dapat mengikuti praktik terbaik dalam prompt engineering untuk mensetting LLM agar memformat tanggal ke dalam format MM/DD/YYYY, yang mungkin kompatibel dengan kolom DATE dalam database. Blok kode berikut menunjukkan contoh bagaimana hal ini dilakukan menggunakan LLM dan prompt engineering. Tidak hanya kita standarisasi format output untuk nilai-nilai tanggal, kami juga memberikan prompt kepada model untuk menghasilkan output akhir dalam format JSON sehingga dapat dengan mudah dikonsumsi dalam aplikasi akhir kami. Kami menggunakan LangChain Expression Language (LCEL) untuk menggabungkan dua aksi. Aksi pertama meminta LLM untuk menghasilkan output format JSON hanya dari tanggal-tanggal dalam dokumen. Aksi kedua mengambil output JSON dan menstandarisasi format tanggal. Perlu diingat bahwa dua langkah ini juga dapat dilakukan dalam satu langkah dengan prompt engineering yang tepat, seperti yang akan kita lihat dalam normalisasi dan pembuatan template.
from langchain.document_loaders import AmazonTextractPDFLoader
from langchain.llms import Bedrock
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
loader = AmazonTextractPDFLoader("./samples/discharge-summary.png")
document = loader.load()
bedrock_llm = Bedrock(client=bedrock, model_id="anthropic.claude-v2")
template1 = """
Given a full document, answer the question and format the output in the format specified. Skip any preamble text and just generate the JSON.
<format>
{{
"key_name":"key_value"
}}
</format>
<document>{doc_text}</document>
<question>{question}</question>"""
template2 = """
Given a JSON document, format the dates in the value fields precisely in the provided format. Skip any preamble text and just generate the JSON.
<format>DD/MM/YYYY</format>
<json_document>{json_doc}</json_document>
"""
prompt1 = PromptTemplate(template=template1, input_variables=["doc_text", "question"])
llm_chain = LLMChain(prompt=prompt1, llm=bedrock_llm, verbose=True)
prompt2 = PromptTemplate(template=template2, input_variables=["json_doc"])
llm_chain2 = LLMChain(prompt=prompt2, llm=bedrock_llm, verbose=True)
chain = (
llm_chain
| {'json_doc': lambda x: x['text'] }
| llm_chain2
)
std_op = chain.invoke({ "doc_text": document[0].page_content,
"question": "Can you give me the patient admitted and discharge dates?"})
print(std_op['text'])
{
"admit_date":"07/09/2020",
"discharge_date":"08/09/2020"
}Hasil contoh kode sebelumnya adalah struktur JSON dengan tanggal 07/09/2020 dan 08/09/2020, yang dalam format DD/MM/YYYY dan merupakan tanggal masuk dan pemulangan pasien dari rumah sakit, sesuai dengan laporan ringkasan pemulangan.
Q&A dengan Retrieval Augmented Generation
LLM dikenal mampu menyimpan informasi faktual, sering disebut sebagai pengetahuan dunia atau pandangan dunia mereka. Ketika disesuaikan dengan baik, mereka dapat menghasilkan hasil terkini. Namun, ada batasan pada sejauh mana LLM dapat mengakses dan memanipulasi pengetahuan ini dengan efektif. Akibatnya, dalam task yang sangat bergantung pada pengetahuan tertentu, kinerja mereka mungkin tidak optimal untuk beberapa kasus. Misalnya, dalam skenario Q&A, sangat penting bagi model untuk mematuhi dengan ketat konteks yang disediakan dalam dokumen tanpa hanya bergantung pada pengetahuan dunia. Melanggar ini dapat mengakibatkan perwakilan yang salah, ketidakakuratan, atau bahkan tanggapan yang salah. Metode yang paling umum digunakan untuk mengatasi masalah ini dikenal sebagai Retrieval Augmented Generation (RAG). Pendekatan ini memadukan kekuatan model pengambilan dan language model, meningkatkan ketepatan dan kualitas respons yang dihasilkan.
LLM juga dapat membatasi token karena batasan memori dan batasan hardware yang mereka jalankan. Untuk mengatasi masalah ini, teknik seperti chunking digunakan untuk membagi dokumen besar menjadi bagian yang lebih kecil sehingga sesuai dengan batasan token LLM. Di sisi lain, embeddings digunakan dalam pemrosesan bahasa alami (NLP) terutama untuk menangkap makna kata-kata semantik dan hubungannya dengan kata-kata lain dalam ruang berdimensi tinggi. Embedding mengubah kata-kata menjadi vektor, memungkinkan model untuk mengolah dan memahami data teks dengan efisien. Dengan memahami nuansa semantik antara kata-kata dan frasa, embedding memungkinkan LLM untuk menghasilkan output yang koheren dan sesuai dengan konteks. Perhatikan istilah kunci berikut:
- Chunking – Proses ini memecah sejumlah besar teks dari dokumen menjadi potongan teks yang lebih kecil dan bermakna.
- Embedding – Ini adalah transformasi vektor berdimensi tetap dari setiap potongan teks yang menyimpan informasi semantik dari potongan tersebut. Embedding ini kemudian dimuat ke dalam vektor database.
- Vektor database – Ini adalah database dari embedding kata-kata atau vektor yang mewakili konteks kata-kata. Ia bertindak sebagai sumber pengetahuan yang membantu tugas-tugas pemrosesan dokumen dalam alur kerja NLP. Manfaat dari vektor database di sini adalah bahwa ia hanya memberikan konteks yang diperlukan kepada LLM selama pembuatan teks, seperti yang kami jelaskan dalam bagian berikut.
RAG menggunakan kemampuan embedding untuk memahami dan mengambil segmen dokumen yang relevan selama pengambilan. Dengan demikian, RAG dapat bekerja dalam batasan token LLM, memastikan informasi yang paling relevan dipilih, menghasilkan output yang lebih akurat dan sesuai konteks.
Diagram berikut menggambarkan integrasi teknik-teknik ini untuk merancang input ke LLM, meningkatkan pemahaman kontekstual mereka dan memungkinkan tanggapan dalam konteks yang lebih relevan. Salah satu pendekatan melibatkan pencarian kesamaan, dengan menggunakan vektor database dan chunking. Vektor database menyimpan embedding yang mewakili informasi semantik, dan chunking membagi teks menjadi bagian-bagian yang dapat dikelola. Dengan konteks dari pencarian kesamaan ini, LLM dapat menjalankan tugas seperti menjawab pertanyaan dan operasi berdomain khusus seperti klasifikasi dan pengayaan.
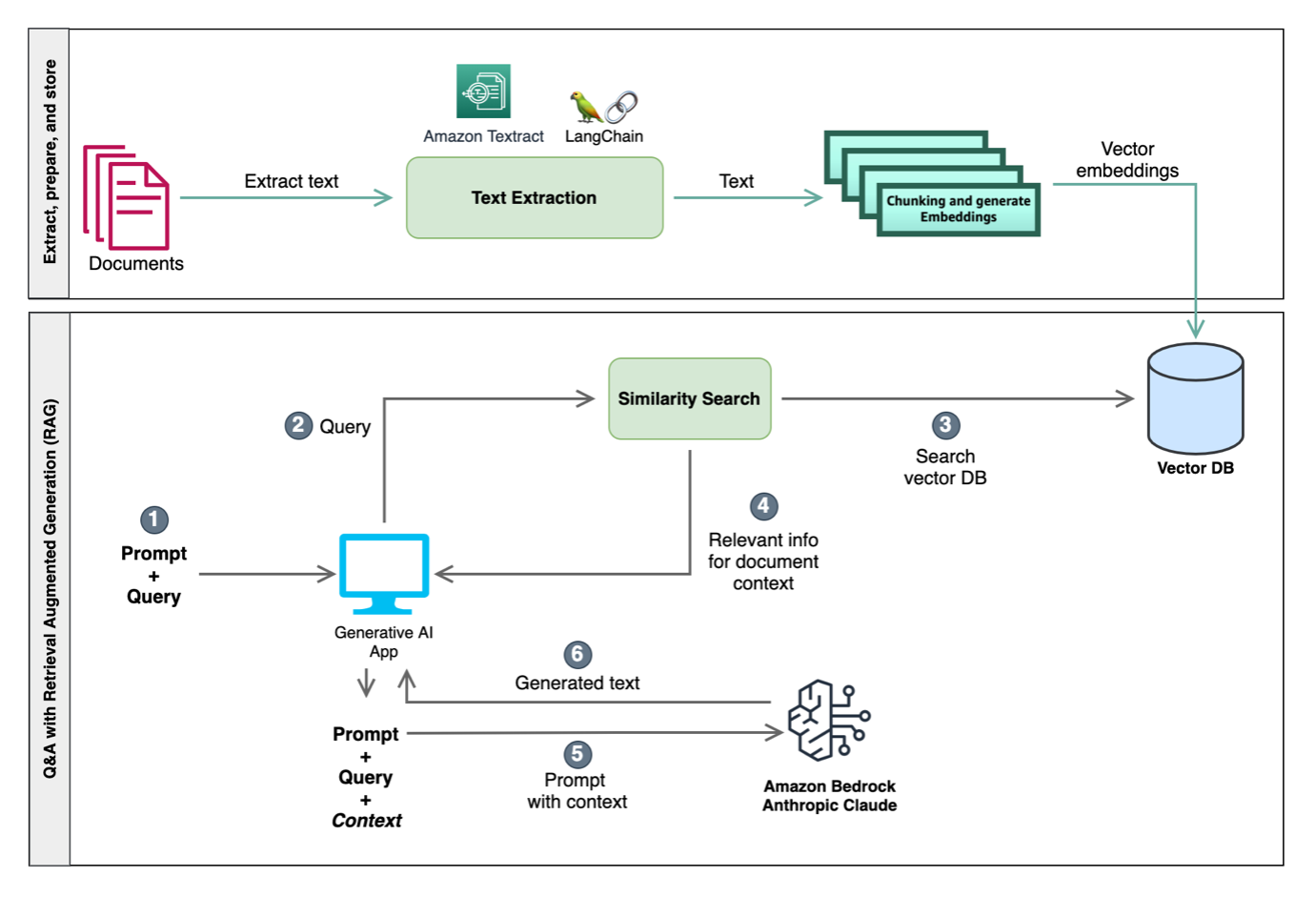
Untuk posting ini, kami menggunakan pendekatan berbasis RAG untuk menjalankan Pertanyaan & Jawaban (Q&A) dalam konteks dengan dokumen. Pada contoh kode berikut, kami mengekstrak teks dari dokumen dan kemudian membagi dokumen menjadi potongan-potongan teks yang lebih kecil. Penggunaan chunking diperlukan karena kami mungkin memiliki dokumen multipage yang besar dan LLM kami memiliki batasan token. Potongan-potongan ini kemudian dimuat ke dalam vektor database untuk menjalankan pencarian kesamaan dalam langkah-langkah selanjutnya. Pada contoh berikut, kami menggunakan model Amazon Titan Embed Text v1, yang melakukan vektor embedding dari potongan-potongan dokumen:
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import BedrockEmbeddings
from langchain.vectorstores import FAISS
from langchain.document_loaders import AmazonTextractPDFLoader
from langchain.chains import RetrievalQA
loader = AmazonTextractPDFLoader("amazon_10k.pdf")
document = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=400,
separators=["\n\n", "\n", ".", "!", "?", ",", " ", ""],
chunk_overlap=0)
texts = text_splitter.split_documents(document)
embeddings = BedrockEmbeddings(client=bedrock,
model_id="amazon.titan-embed-text-v1")
db = FAISS.from_documents(documents=texts,
embedding=embeddings)
retriever = db.as_retriever(search_type='mmr', search_kwargs={"k": 3})
template = """
Answer the question as truthfully as possible strictly using only the provided text, and if the answer is not contained within the text, say "I don't know". Skip any preamble text and reasoning and give just the answer.
<text>{context}</text>
<question>{question}</question>
<answer>"""
# define the prompt template
qa_prompt = PromptTemplate(template=template, input_variables=["context","question"])
chain_type_kwargs = { "prompt": qa_prompt, "verbose": False } # change verbose to True if you need to see what's happening
bedrock_llm = Bedrock(client=bedrock, model_id="anthropic.claude-v2")
qa = RetrievalQA.from_chain_type(
llm=bedrock_llm,
chain_type="stuff",
retriever=retriever,
chain_type_kwargs=chain_type_kwargs,
verbose=False # change verbose to True if you need to see what's happening
)
question="Who is the administrator for this plan?"
result = qa.run(question)
print(result.strip())Kode tersebut menciptakan konteks yang relevan bagi LLM dengan menggunakan potongan-potongan teks yang dikembalikan oleh pencarian kesamaan dari vektor database. Pada contoh ini, kami menggunakan open-source FAISS vector store sebagai contoh vektor database untuk menyimpan vektor embedding dari setiap potongan teks. Kemudian, kami menentukan vektor database sebagai LangChain retriever, yang diteruskan ke dalam rangkaian (chain) RetrievalQA. Ini secara internal menjalankan permintaan pencarian kesamaan pada vektor database yang mengembalikan n potongan teks teratas (dengan n=3 dalam contoh kami) yang relevan dengan pertanyaan. Akhirnya, LLM chain dijalankan dengan konteks yang relevan (kelompok potongan teks yang relevan) dan pertanyaan yang perlu dijawab oleh LLM. Untuk panduan langkah demi langkah tentang Q&A dengan RAG, lihat Python notebook di GitHub.
Sebagai alternatif FAISS, Anda juga dapat menggunakan kemampuan vektor database Amazon OpenSearch Service, Amazon Relational Database Service (Amazon RDS) untuk PostgreSQL dengan ekstensi pgvector sebagai vektor database, atau open-source Chroma Database.
Q&A dengan tabular data
Data dalam bentuk tabel pada dokumen bisa menjadi tantangan bagi LLM untuk diproses karena kompleksitas strukturalnya. Amazon Textract dapat digabungkan dengan LLM karena memungkinkan ekstraksi tabel dari dokumen dalam format bertingkat dengan elemen seperti halaman, tabel, dan sel. Menjalankan Pertanyaan & Jawaban (Q&A) dengan data berbentuk tabel membutuhkan proses dengan beberapa langkah, dan bisa dicapai melalui self-querying. Berikut adalah gambaran umum langkah-langkahnya:
- Ekstrak tabel dari dokumen menggunakan Amazon Textract. Dengan Amazon Textract, struktur berbentuk tabel (baris, kolom, header) dapat diekstrak dari dokumen.
- Simpan data tabel ke dalam vektor database bersama dengan informasi metadata, seperti nama-nama header dan deskripsi dari masing-masing header.
- Gunakan prompt untuk membuat kueri terstruktur, menggunakan LLM, untuk mendapatkan data dari tabel.
- Gunakan kueri untuk mengekstrak data tabel yang relevan dari vektor database.
Sebagai contoh, pada laporan rekening bank, dengan menggunakan prompt “Manakah transaksi dengan lebih dari $1000 dalam deposit,” LLM akan menyelesaikan langkah-langkah berikut:
- Membuat kueri, seperti “Query: transaksi”, “filter: lebih besar dari (Deposit$)”.
- Mengonversi kueri menjadi kueri terstruktur.
- Mengaplikasikan kueri terstruktur ke vektor database di mana data tabel kita disimpan.
Untuk panduan langkah demi langkah dengan contoh kode untuk Q&A dengan data berbentuk tabel, lihat Python notebook di GitHub.
Templating dan normalisasi
Pada bagian ini, kita akan melihat bagaimana menggunakan teknik prompt engineering dan mekanisme built-in LangChain untuk menghasilkan output dengan ekstraksi dari dokumen pada skema yang ditentukan. Kami juga akan melakukan beberapa standarisasi pada data yang diekstraksi, dengan menggunakan teknik yang telah dibahas sebelumnya. Kita akan memulai dengan mendefinisikan sebuah template untuk output yang diinginkan. Ini akan berfungsi sebagai skema dan mencakup detail tentang setiap entitas yang ingin kita ekstraksi dari teks dokumen.
Perlu diperhatikan bahwa untuk setiap entitas, kita menggunakan deskripsi untuk menjelaskan apa entitas itu, sehingga membantu LLM dalam mengekstrak nilai dari teks dokumen. Pada contoh kode berikut, kami menggunakan template ini untuk membuat prompt untuk LLM bersama dengan teks yang diekstrak dari dokumen menggunakan AmazonTextractPDFLoader, dan selanjutnya melakukan inferensi dengan model:
Seperti yang Anda lihat, bagian {keys} dari prompt adalah key dari template kita, dan {details} juga adalah key dan juga deskripsinya. Dalam kasus ini, kita tidak memberikan prompt secara eksplisit kepada model dengan format output selain menspesifikasikan dalam instruksi untuk menghasilkan output dalam format JSON. Ini karena output teks dari LLM adalah teks yang bersifat non-deterministik, kita ingin menspesifikasikan format secara eksplisit sebagai bagian dari instruksi dalam prompt. Untuk mengatasi ini, kita dapat menggunakan modul LangChain structured output parser untuk memanfaatkan prompt engineering otomatis yang membantu mengonversi template kita menjadi format prompt instruksi. Kita menggunakan template yang telah didefinisikan sebelumnya untuk menghasilkan prompt instruksi format sebagai berikut:
Variabel format_instructions sekarang memiliki format prompt instruksi:
Kemudian kita menggunakan variabel ini dalam prompt awal sebagai instruksi kepada LLM sehingga LLM mengekstrak dan memformat output sesuai skema yang diinginkan dengan melakukan sedikit modifikasi pada prompt kita sebelumnya:
Sejauh ini, kita baru saja mengekstrak data dari dokumen dalam skema yang diinginkan. Namun, kita masih perlu melakukan beberapa standardisasi. Misalnya, kita ingin tanggal masuk dan tanggal pemulangan pasien diekstrak dalam format DD/MM/YYYY. Dalam kasus ini, kita menambahkan atribut description dengan instruksi format:
Silakan merujuk pada Python notebook di GitHub untuk penjelasan langkah-demi-langkah yang lebih detil.
Spellcheck dan koreksi
LLM telah menunjukkan kemampuan luar biasa dalam memahami dan menghasilkan teks yang mirip dengan bahasa manusia. Salah satu aplikasi LLM yang kurang dibahas namun sangat berguna adalah potensi mereka dalam pemeriksaan tata bahasa (spellcheck) dan koreksi kalimat dalam dokumen. Berbeda dengan pemeriksa tata bahasa tradisional yang bergantung pada seperangkat aturan yang telah ditentukan, LLM menggunakan pola yang mereka identifikasi dari teks dengan jumlah data besar untuk menentukan apa yang dianggap sebagai bahasa yang benar atau lancar. Ini berarti mereka dapat mendeteksi nuansa, konteks, dan penekanan yang mungkin terlewatkan oleh sistem berbasis aturan (rule-based).
Bayangkan teks yang diekstrak dari ringkasan pemulangan pasien yang berbunyi “Patient Jon Doe, who was admittd with sever pnemonia, has shown significant improvemnt and can be safely discharged. Followups are scheduled for nex week.” Pemeriksa tata bahasa tradisional mungkin mengenali “admittd,” “pneumonia,” “improvement,” dan “nex” sebagai kesalahan. Namun, konteks dari kesalahan ini bisa mengarah pada kesalahan lebih lanjut atau saran yang bersifat generik. Sebaliknya, LLM, yang dilengkapi dengan pelatihan yang luas, mungkin akan menyarankan: “Patient John Doe, who was admitted with severe pneumonia, has shown significant improvement and can be safely discharged. Follow-ups are scheduled for next week.”
Berikut ini adalah contoh dokumen dengan tulisan tangan yang buruk dengan teks yang sama seperti yang dijelaskan sebelumnya.

Kita mengekstrak dokumen dengan menggunakan Amazon Textract document loader dan kemudian memberikan instruksi kepada LLM, melalui prompt engineering, untuk memperbaiki teks yang diekstrak guna memperbaiki kesalahan ejaan dan/atau tata bahasa:
Output dari kode sebelumnya menunjukkan teks asli yang diekstrak oleh document loader diikuti oleh teks yang diperbaiki yang dihasilkan oleh LLM:
Perlu diingat bahwa sebagus apa pun kemampuan LLM, penting untuk output mereka sebagai sekadar saran. Meskipun mereka dapat menangkap penekanan bahasa dengan sangat baik, tetapi itu tidak menjamin. Beberapa saran mungkin mengubah makna atau nada asli teks. Oleh karena itu, penting bagi para reviewer manusia untuk menggunakan koreksi yang dihasilkan oleh LLM sebagai panduan, bukan sebagai keputusan mutlak. Kolaborasi intuisi manusia dengan kemampuan LLM menjanjikan masa depan di mana komunikasi tertulis kita bukan hanya bebas dari kesalahan, tetapi juga lebih kaya dan berwarna.
Kesimpulan
Generative AI mengubah cara bagaimana Anda memproses dokumen dengan IDP untuk mendapatkan wawasan. Dalam post Enhancing AWS intelligent document processing with generative AI, kita membahas berbagai tahap dalam pipeline dan bagaimana pelanggan AWS, Ricoh, meningkatkan pipeline IDP mereka dengan LLM. Dalam posting ini, kita membahas berbagai mekanisme dalam meningkatkan workflow IDP dengan LLM melalui Amazon Bedrock, Amazon Textract, dan framework LangChain yang populer. Anda dapat mulai menggunakan Amazon Textract document loader baru dengan LangChain hari ini dengan menggunakan notebooks yang tersedia di repositori GitHub kami. Untuk informasi lebih lanjut bagaimana menggunakan generative AI di AWS, lihat Announcing New Tools for Building with Generative AI on AWS.
Artikel ini diterjemahkan dari artikel asli dengan judul “Intelligent document processing with Amazon Textract, Amazon Bedrock, and LangChain” yang ditulis oleh Sonali Sahu, Anjan Biswas, dan Chinmayee Rane.