Artificial Intelligence
Amazon Comprehend document classifier adds layout support for higher accuracy
The ability to effectively handle and process enormous amounts of documents has become essential for enterprises in the modern world. Due to the continuous influx of information that all enterprises deal with, manually classifying documents is no longer a viable option. Document classification models can automate the procedure and help organizations save time and resources. Traditional categorization techniques, such as manual processing and keyword-based searches, become less efficient and more time-consuming as the volume of documents increases. This inefficiency causes lower productivity and higher operating expenses. Additionally, it can prevent crucial information from being accessible when needed, which could lead to a poor customer experience and impact decision-making. At AWS re:Invent 2022, Amazon Comprehend, a natural language processing (NLP) service that uses machine learning (ML) to discover insights from text, launched support for native document types. This new feature gave you the ability to classify documents in native formats (PDF, TIFF, JPG, PNG, DOCX) using Amazon Comprehend.
Today, we are excited to announce that Amazon Comprehend now supports custom classification model training with documents like PDF, Word, and image formats. You can now train bespoke document classification models on native documents that support layout in addition to text, increasing the accuracy of the results.
In this post, we provide an overview of how you can get started with training an Amazon Comprehend custom document classification model.
Overview
The capacity to understand the relative placements of objects within a defined space is referred to as layout awareness. In this case, it aids the model in understanding how headers, subheadings, tables, and graphics relate to one another inside a document. The model can more effectively categorize a document based on its content when it’s aware of the structure and layout of the text.
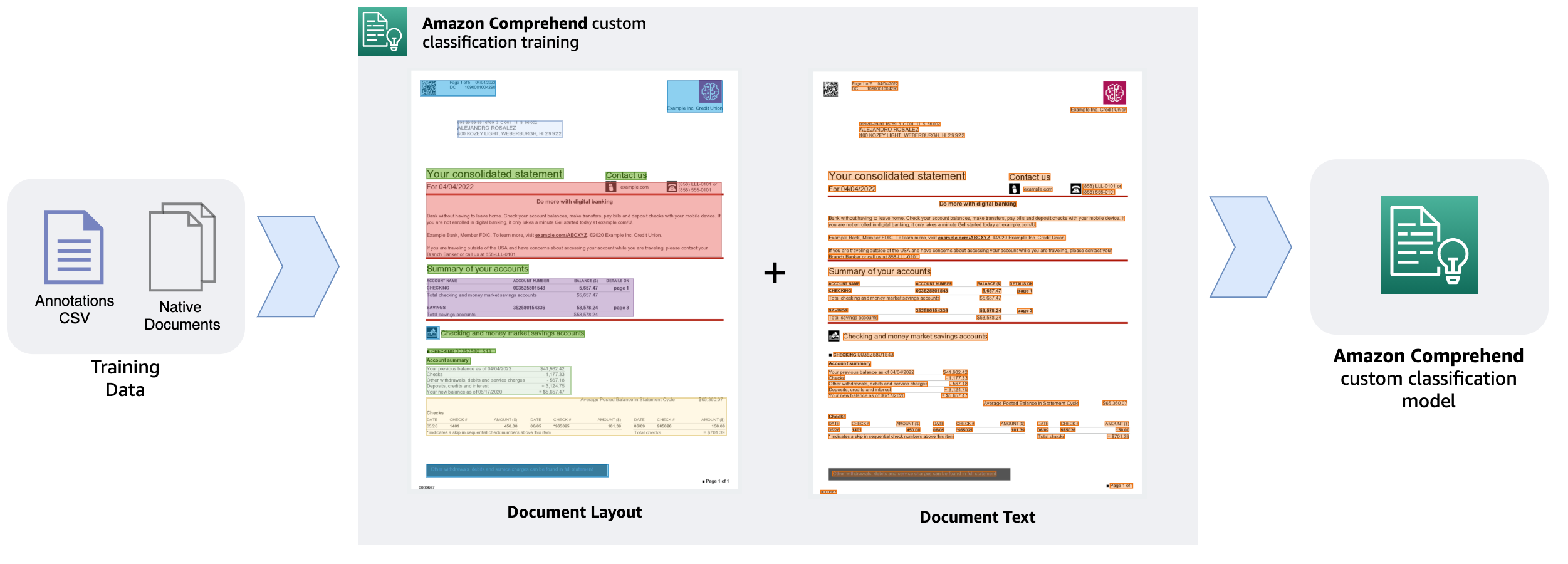
In this post, we walk through the data preparation steps involved, demonstrate the model training process, and discuss the benefits of using the new custom document classification model in Amazon Comprehend. As a best practice, you should consider the following points before you begin training the custom document classification model.
Evaluate your document classification needs
Identify the various types of documents they you may need to classify, along with the different classes or categories to support your use case. Determine the suitable classification structure or taxonomy after evaluating the amount and types of documents that need to be categorized. Document types may vary from PDF, Word, images, and so on. Ensure you have authorized access to a diverse set of labeled documents either via a document management system or other storage mechanisms.
Prepare your data
Ensure that the document files you intend to use for model training aren’t encrypted or locked—for example, make sure that your PDF files aren’t encrypted and locked with a password. You must decrypt such files before you can use them for training purposes. Label a sample of your documents with the appropriate categories or labels (classes). Determine whether single-label classification (multi-class mode) or multi-label classification is appropriate for your use case. Multi-class mode associates only a single class with each document, whereas multi-label mode associates one or more class with a document.
Consider model evaluation
Use the labeled dataset to train the model so it can learn to classify new documents accurately and evaluate how the newly trained model version performs by understanding the model metrics. To understand the metrics provided by Amazon Comprehend post-model training, refer to Custom classifier metrics. After the training process is complete, you can begin classifying documents asynchronously or in real time. We walk through how to train a custom classification model in the following sections.
Prepare the training data
Before we train our custom classification model, we need to prepare the training data. Training data is comprised of a set of labeled documents, which can be pre-identified documents from a document repository that you already have access to. For our example, we trained a custom classification model with a few different document types that are typically found in a health insurance claim adjudication process: patient discharge summary, invoices, receipts, and so on. We also need to prepare an annotations file in CSV format. Following is an example of an annotations file CSV data required for the training:
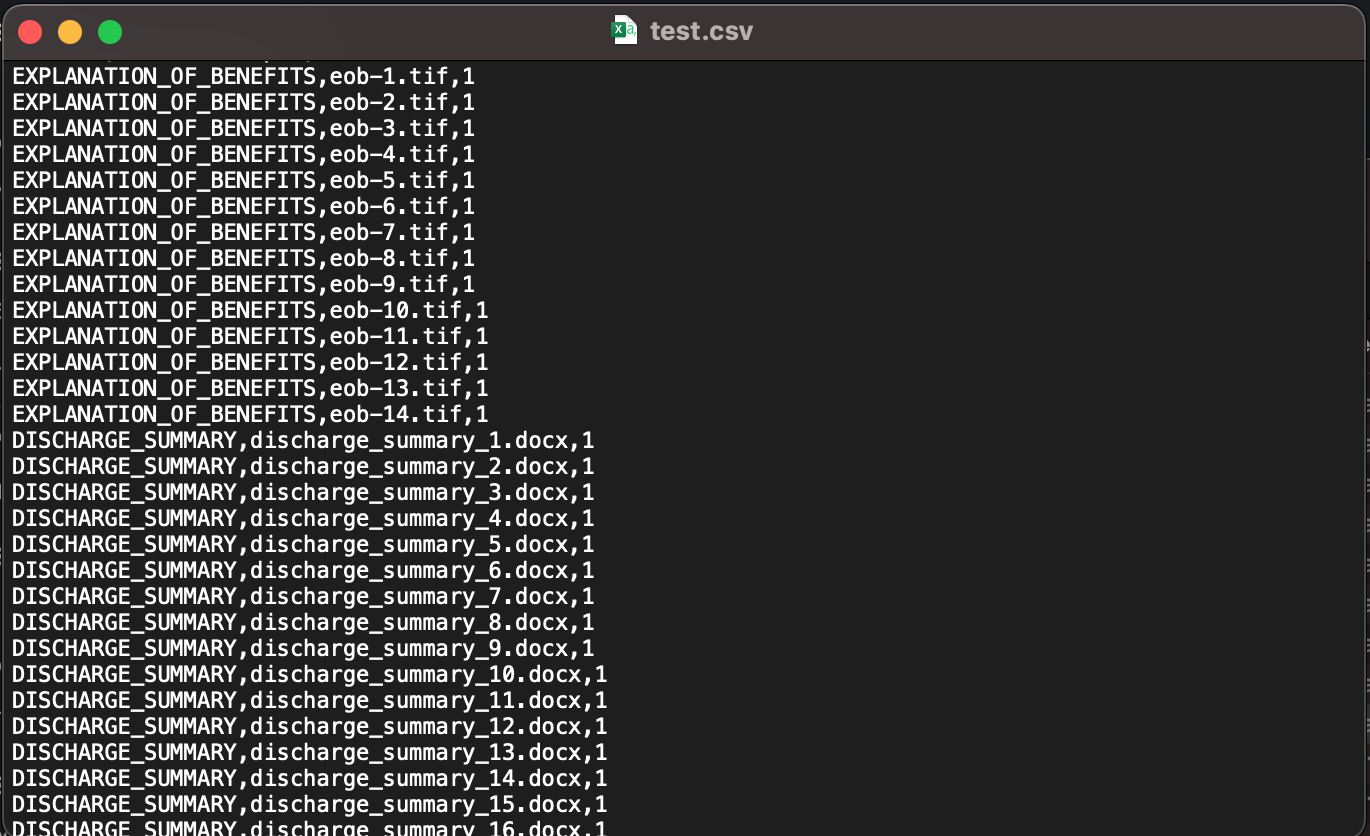
The annotations CSV file must contain three columns. The first column contains the desired class (label) for the document, the second column is the document name (file name), and the last column is the page number of the document that you want to include in the training dataset. Because the training process supports native multi-page PDF and DOCX files, you must specify the page number in case the document is a multi-page document. If you want to include all pages of a multi-page document in the training dataset, you must specify each page as a separate line in the CSV annotations file. For example, in the preceding annotations file, invoice-1.pdf is a two-page document, and we want to include both pages in the classification dataset. Because files like PDF, PNG, and TIFF are image formats, the page number (third column) value must always be 1. If your dataset contains multi-frame (multi-page) TIF files, you must split them into separate TIF files in order to use them in the training process.
We prepared an annotations file called test.csv with the appropriate data to train a custom classification model. For each sample document, the CSV file contains the class that document belongs to, the location of the document in Amazon Simple Storage Service (Amazon S3), such as path/to/prefix/document.pdf, and the page number (if applicable). Because most of our documents are either single-page DOCX, PDF files, or TIF, JPG, or PNG files, the page number assigned is 1. Because our annotations CSV and sample documents are all under the same Amazon S3 prefix, we don’t need to explicitly specify the prefix in the second column. We also prepare at least 10 document samples or more for each class, and we used a mix of JPG, PNG, DOCX, PDF, and TIF files for training the model. Note that it’s usually recommended to have a diverse set of sample documents for model training to avoid overfitting of the model, which impacts its ability to recognize new documents. It’s also recommended that the number of samples per class is balanced, although it’s not required to have an exact same number of samples per class. Next, we upload the test.csv annotations file and all the documents into Amazon S3. The following image shows part of our annotations CSV file.
Train a custom classification model
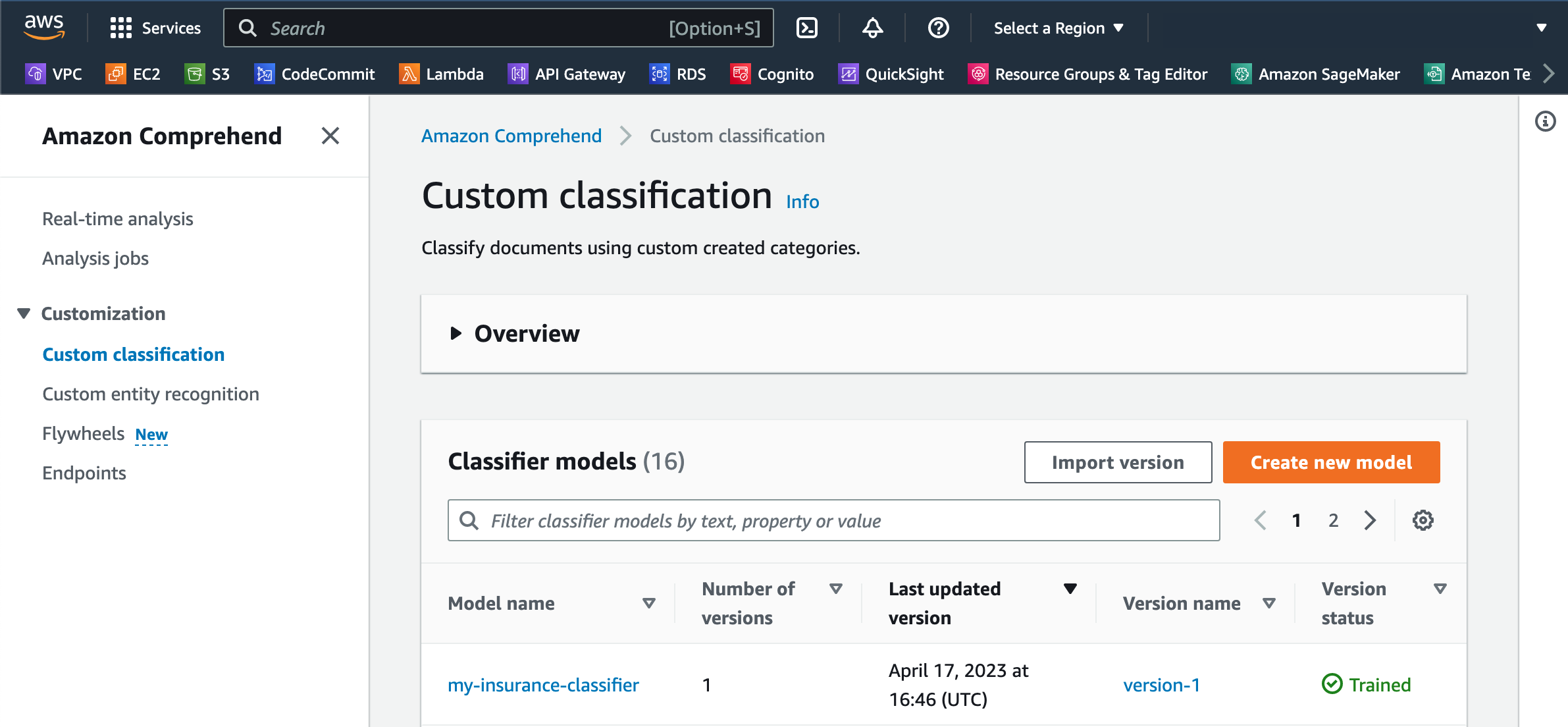
Now that we have the annotations file and all our sample documents ready, we set up a custom classification model and train it. Before you begin setting up custom classification model training, make sure that the annotations CSV and sample documents exist in an Amazon S3 location.
- On the Amazon Comprehend console, choose Custom classification in the navigation pane.
- Choose Create new model.

- For Model name, enter a unique name.
- For Version name, enter a unique version name.

- For Training model type, select Native documents.
This tells Amazon Comprehend that you intend to use native document types to train the model instead of serialized text.
- For Classifier mode, select Using single-label mode.
This mode tells the classifier that we intend to classify documents into a single class. If you need to train a model with multi-label mode, meaning a document may belong to one or more than one class, you must set up the annotations file appropriately by specifying the classes of the document separated by a special character in the annotations CSV file. In that case, you would select the Using multi-label mode option.
- For Annotation location on S3, enter the path of the annotations CSV file.
- For Training data location on S3, enter the Amazon S3 location where your documents reside.
- Leave all other options as default in this section.

- In the Output data section, specify an Amazon S3 location for your output.
This is optional, but it’s a good practice to provide an output location because Amazon Comprehend will generate the post-model training evaluation metrics in this location. This data is useful to evaluate model performance, iterate, and improve the accuracy of your model.
- In the IAM role section, choose an appropriate AWS Identity and Access Management (IAM) role that allows Amazon Comprehend to access the Amazon S3 location and write and read from it.
- Choose Create to initiate the model training.

The model may take several minutes to train, depending on the number of classes and the dataset size. You can review the training status on the Custom classification page. The training process will display a Submitted status right after the training process starts and will change to Training status when the training process begins. After your model is trained, the Version status will change to Trained. If Amazon Comprehend finds inconsistencies in your training data, the status will show In error along with an alert that shows the appropriate error message so that you can take corrective action and restart the training process with the corrected data.
In this post, we demonstrated the steps to train a custom classifier model using the Amazon Comprehend console. You can also use the AWS SDK in any language (for example, Boto3 for Python) or the AWS Command Line Interface (AWS CLI) to initiate a custom classification model training. With either the SDK or AWS CLI, you can use the CreateDocumentClassifier API to initiate the model training, and subsequently use the DescribeDocumentClassifier API to check the status of the model.
After the model is trained, you can perform either real-time analysis or asynchronous (batch) analysis jobs on new documents. To perform real-time classification on documents, you must deploy an Amazon Comprehend real-time endpoint with the trained custom classification model. Real-time endpoints are best suited for use cases that require low-latency, real-time inference results, whereas for classifying a large set of documents, an asynchronous analysis job is more appropriate. To learn how you can perform asynchronous inference on new documents using a trained classification model, refer to Introducing one-step classification and entity recognition with Amazon Comprehend for intelligent document processing.
Benefits of the layout-aware custom classification model
The new classifier model offers a number of improvements. It’s not only easier to train the new model, but you can also train a new model with just a few samples for each class. Additionally, you no longer have to extract serialized plain text out of scanned or digital documents such as images or PDFs to prepare the training dataset. The following are some additional noteworthy improvements that you can expect from the new classification model:
- Improved accuracy – The model now takes into account the layout and structure of documents, which leads to a better understanding of the structure and content of the documents. This helps distinguish between documents with similar text but different layouts or structures, resulting in increased classification accuracy.
- Robustness – The model now handles variations in document structure and formatting. This makes it better suited for classifying documents from different sources with varying layouts or formatting styles, which is a common challenge in real-world document classification tasks. It’s compatible with several document types natively, making it versatile and applicable to different industries and use cases.
- Reduced manual intervention – Higher accuracy leads to less manual intervention in the classification process. This can save time and resources, and increase operational efficiency in your document processing workload.
Conclusion
The new Amazon Comprehend document classification model, which incorporates layout awareness, is a game-changer for businesses dealing with large volumes of documents. By understanding the structure and layout of documents, this model offers improved classification accuracy and efficiency. Implementing a robust and accurate document classification solution using a layout-aware model can help your business save time, reduce operational costs, and enhance decision-making processes.
As a next step, we encourage you to try the new Amazon Comprehend custom classification model via the Amazon Comprehend console. We also recommend revisiting our custom classification model improvement announcements from last year and visit the GitHub repository for code samples.
About the authors
 Anjan Biswas is a Senior AI Services Solutions Architect with a focus on AI/ML and Data Analytics. Anjan is part of the world-wide AI services team and works with customers to help them understand and develop solutions to business problems with AI and ML. Anjan has over 14 years of experience working with global supply chain, manufacturing, and retail organizations, and is actively helping customers get started and scale on AWS AI services.
Anjan Biswas is a Senior AI Services Solutions Architect with a focus on AI/ML and Data Analytics. Anjan is part of the world-wide AI services team and works with customers to help them understand and develop solutions to business problems with AI and ML. Anjan has over 14 years of experience working with global supply chain, manufacturing, and retail organizations, and is actively helping customers get started and scale on AWS AI services.
 Godwin Sahayaraj Vincent is an Enterprise Solutions Architect at AWS who is passionate about Machine Learning and providing guidance to customers to design, deploy and manage their AWS workloads and architectures. In his spare time, he loves to play cricket with his friends and tennis with his three kids.
Godwin Sahayaraj Vincent is an Enterprise Solutions Architect at AWS who is passionate about Machine Learning and providing guidance to customers to design, deploy and manage their AWS workloads and architectures. In his spare time, he loves to play cricket with his friends and tennis with his three kids.
 Wrick Talukdar is a Senior Architect with the Amazon Comprehend Service team. He works with AWS customers to help them adopt machine learning on a large scale. Outside of work, he enjoys reading and photography.
Wrick Talukdar is a Senior Architect with the Amazon Comprehend Service team. He works with AWS customers to help them adopt machine learning on a large scale. Outside of work, he enjoys reading and photography.