AWS News Blog
Amazon Redshift Spectrum – Exabyte-Scale In-Place Queries of S3 Data

|
Now that we can launch cloud-based compute and storage resources with a couple of clicks, the challenge is to use these resources to go from raw data to actionable results as quickly and efficiently as possible.
Amazon Redshift allows AWS customers to build petabyte-scale data warehouses that unify data from a variety of internal and external sources. Because Redshift is optimized for complex queries (often involving multiple joins) across large tables, it can handle large volumes of retail, inventory, and financial data without breaking a sweat. Once the data is loaded, our customers can make use of a plethora of enterprise reporting and business intelligence tools provided by the Redshift Partners.
One of the most challenging aspects of running a data warehouse involves loading data that is continuously changing and/or arriving at a rapid pace. In order to provide great query performance, loading data into a data warehouse includes compression, normalization, and optimization steps. While these steps can be automated and scaled, the loading process introduces overhead and complexity, and also gets in the way of those all-important actionable results.
Data formats present another interesting challenge. Some applications will process the data in its original form, outside of the data warehouse. Others will issue queries to the data warehouse. This model leads to storage inefficiencies because the data must be stored twice, and can also mean that results from one form of processing may not align with those from another due to delays introduced by the loading process.
Amazon Redshift Spectrum
In order to allow you to process your data as-is, where-is, while taking advantage of the power and flexibility of Amazon Redshift, we are launching Amazon Redshift Spectrum. You can use Spectrum to run complex queries on data stored in Amazon Simple Storage Service (Amazon S3), with no need for loading or other data prep.
You simply create a data source and issue your queries to your Redshift cluster as usual. Behind the scenes, Spectrum scales to thousands of instances on a per-query basis, ensuring that you get fast, consistent performance even as your data set grows up to an beyond an exabyte! Being able to query data stored in S3 means that you can scale your compute and your storage independently, with the full power of the Redshift query model and all of the reporting and business intelligence tools at your disposal. Your queries can reference any combination of data stored in Redshift tables and in S3.
When you issue a query, Redshift rips it apart and generates a query plan that minimizes the amount of S3 data that will be read, taking advantage of both column-oriented formats and data that is partitioned by date or another key. Then Redshift requests Spectrum workers from a large, shared pool and directs them to project, filter, and aggregate the S3 data. The final processing is performed within the Redshift cluster and the results are returned to you.
Because Spectrum operates on data that is stored in S3, you can process the data using other AWS services such as Amazon EMR and Amazon Athena. You can also implement hybrid models where frequently queried data is kept in Redshift local storage and the rest is S3, or where dimension tables are in Redshift along with the recent portions of the fact tables, with older data in S3. In order to drive even higher levels of concurrency, you can point multiple Redshift clusters at the same stored data.
Spectrum supports open, common data types including CSV/TSV, Parquet, and RCFile. Files can be compressed using GZip or Snappy, with other data types and compression methods in the works.
Spectrum in Action
In order to get some first-hand experience with Spectrum I loaded up a sample data set and ran some queries!
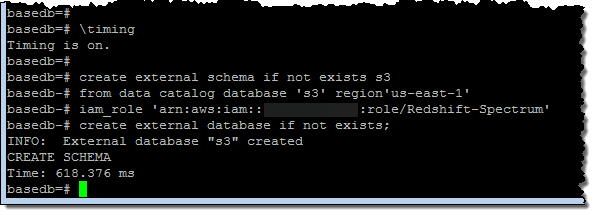
I started by creating an external schema and database:
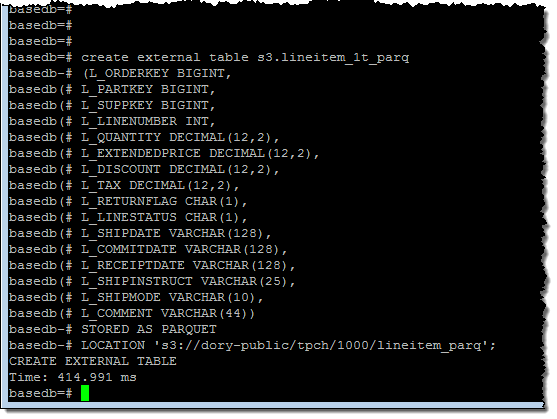
Then I created an external table within the database:
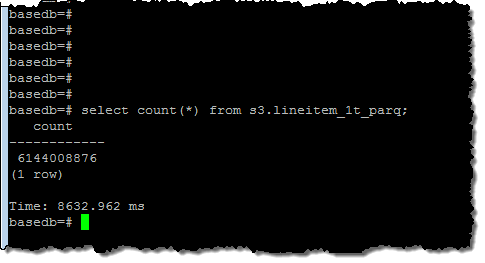
I ran a simple query to get a feel for the size of the data set (6.1 billion rows):
And then I ran a query that processed all of the rows:
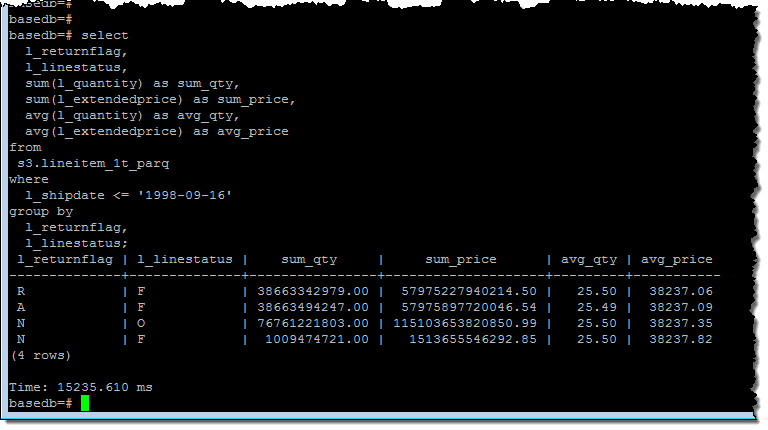
As you can see, Spectrum was able to churn through all 6 billion rows in about 15 seconds. I checked my cluster’s performance metrics and it looked like I had enough CPU power to run many such queries simultaneously:
Available Now
Amazon Redshift Spectrum is available now and you can start using it today!
Spectrum pricing is based on the amount of data pulled from S3 during query processing and is charged at the rate of $5 per terabyte (you can save money by compressing your data and/or storing it in column-oriented form). You pay the usual charges to run your Redshift cluster and to store your data in S3, but there are no Spectrum charges when you are not running queries.
— Jeff;
PS – Several people have asked about the relationship between Spectrum and Athena, and the applicability of both tools to different workloads. Fortunately, the newly updated Redshift FAQ addresses this question; see When should I use Amazon Athena vs. Redshift Spectrum? for more info.