AWS News Blog
Launch – AWS Glue Now Generally Available
Today we’re excited to announce the general availability of AWS Glue. Glue is a fully managed, serverless, and cloud-optimized extract, transform and load (ETL) service. Glue is different from other ETL services and platforms in a few very important ways.
First, Glue is “serverless” – you don’t need to provision or manage any resources and you only pay for resources when Glue is actively running. Second, Glue provides crawlers that can automatically detect and infer schemas from many data sources, data types, and across various types of partitions. It stores these generated schemas in a centralized Data Catalog for editing, versioning, querying, and analysis. Third, Glue can automatically generate ETL scripts (in Python!) to translate your data from your source formats to your target formats. Finally, Glue allows you to create development endpoints that allow your developers to use their favorite toolchains to construct their ETL scripts. Ok, let’s dive deep with an example.
In my job as a Developer Evangelist I spend a lot of time traveling and I thought it would be cool to play with some flight data. The Bureau of Transportations Statistics is kind enough to share all of this data for anyone to use here. We can easily download this data and put it in an Amazon Simple Storage Service (Amazon S3) bucket. This data will be the basis of our work today.
Crawlers
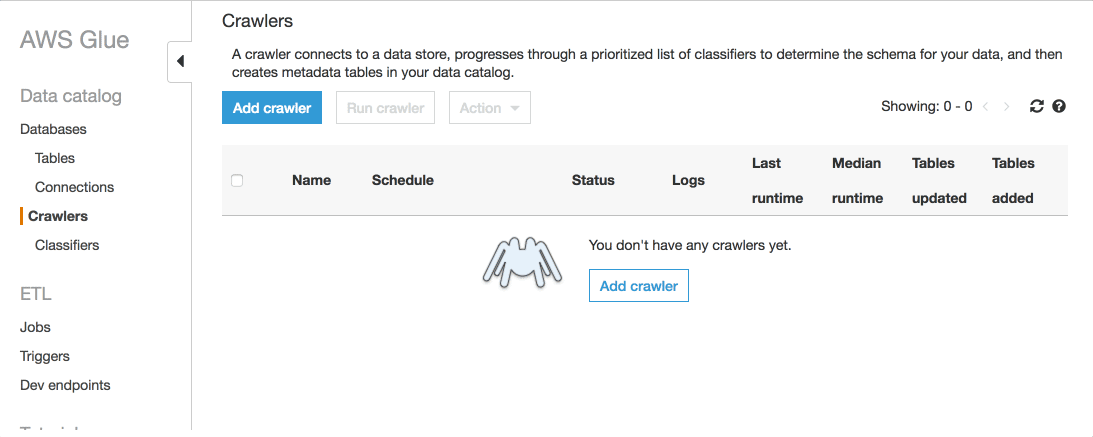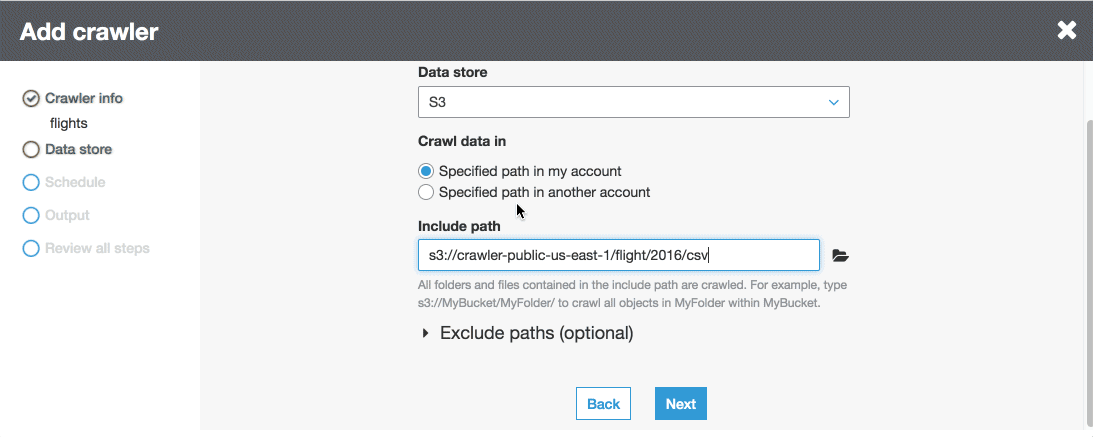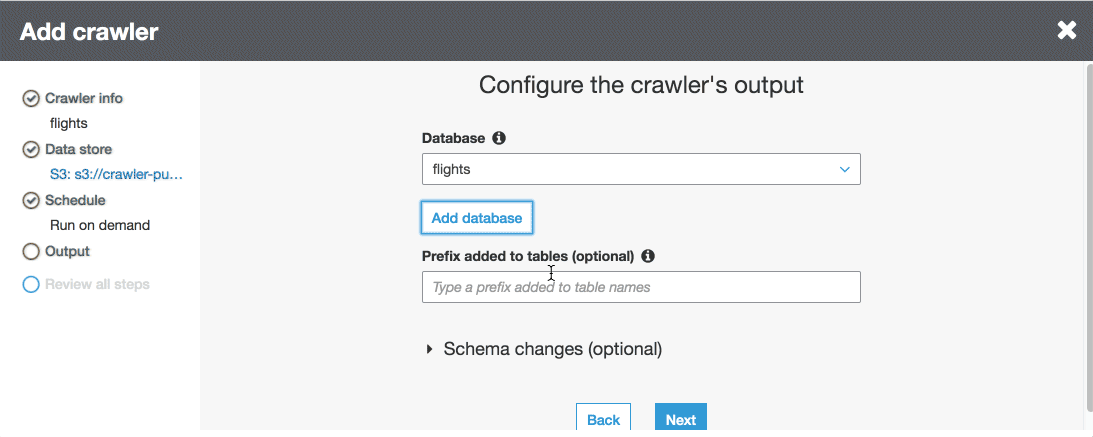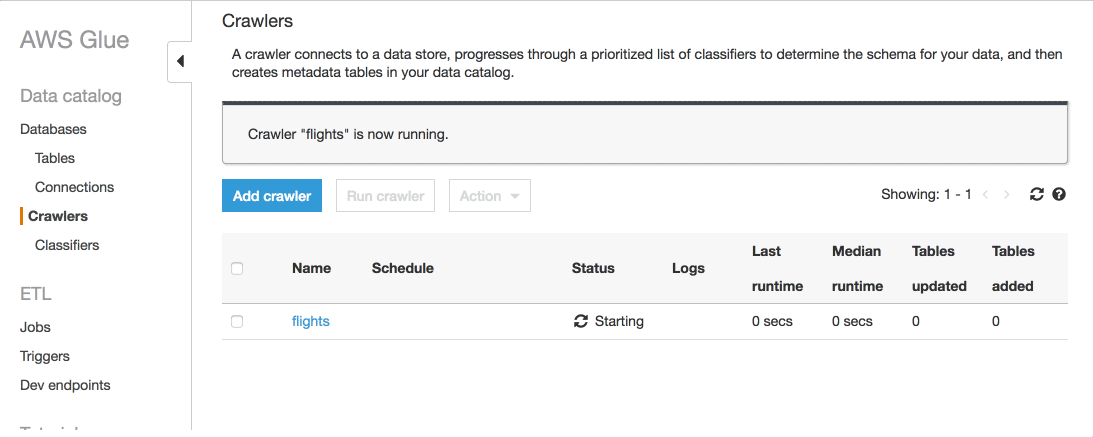
First, we need to create a Crawler for our flights data from S3. We’ll select Crawlers in the Glue console and follow the on screen prompts from there. I’ll specify s3://crawler-public-us-east-1/flight/2016/csv/ as my first datasource (we can add more later if needed). Next, we’ll create a database called flights and give our tables a prefix of flights as well.
The Crawler will go over our dataset, detect partitions through various folders – in this case months of the year, detect the schema, and build a table. We could add additonal data sources and jobs into our crawler or create separate crawlers that push data into the same database but for now let’s look at the autogenerated schema.

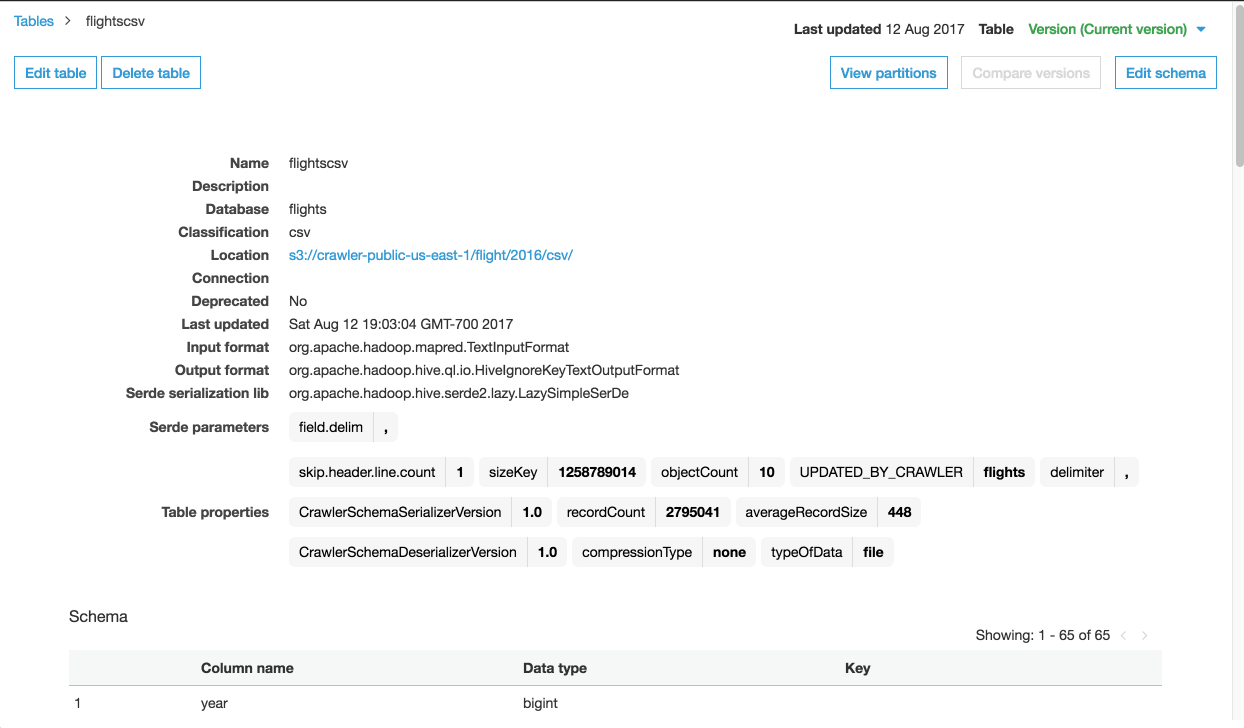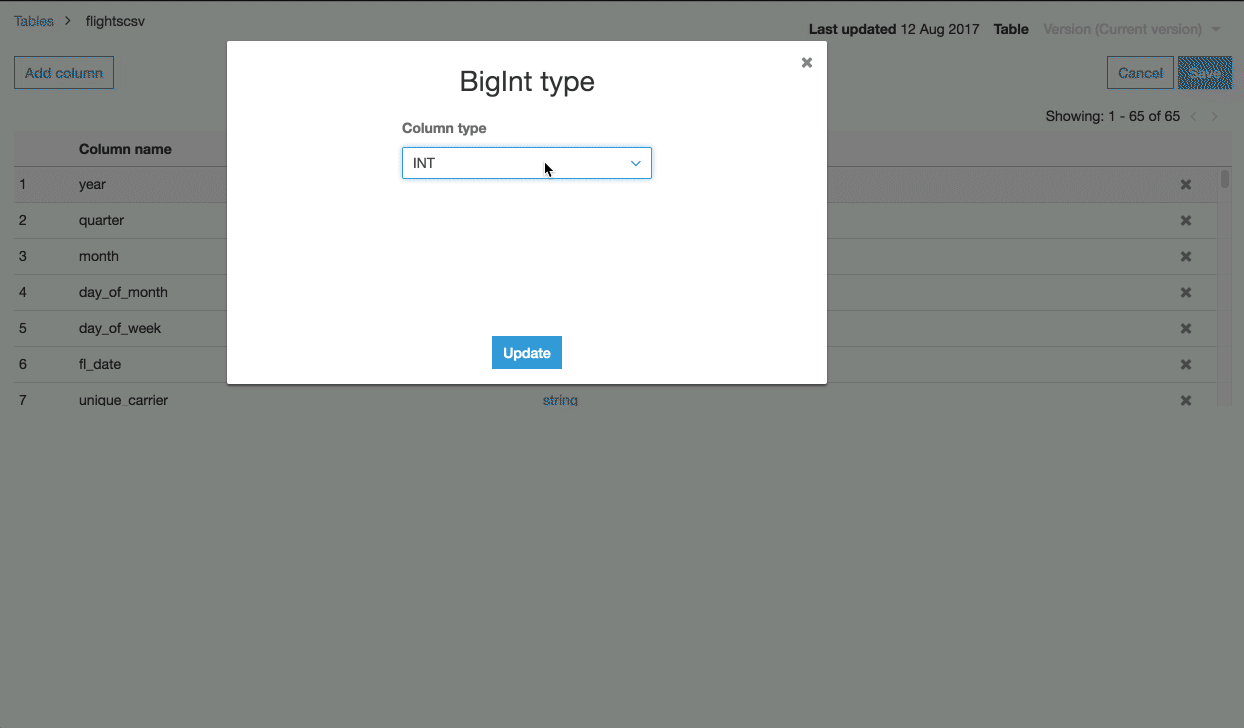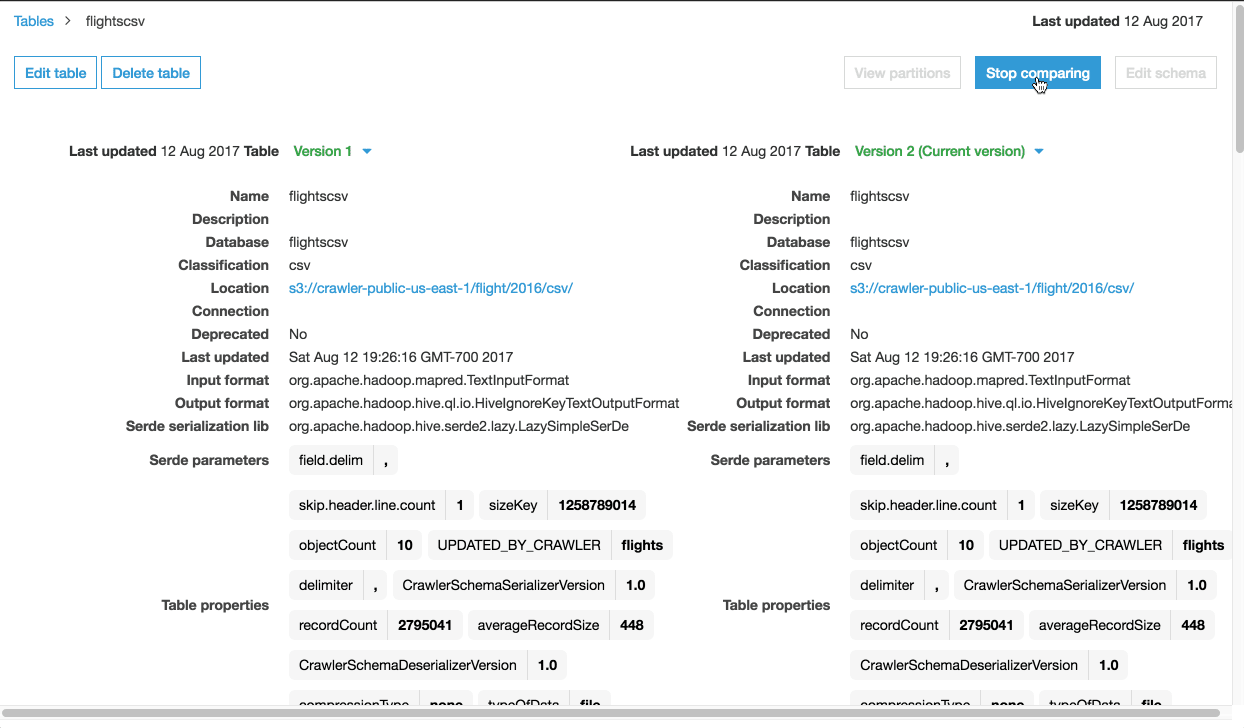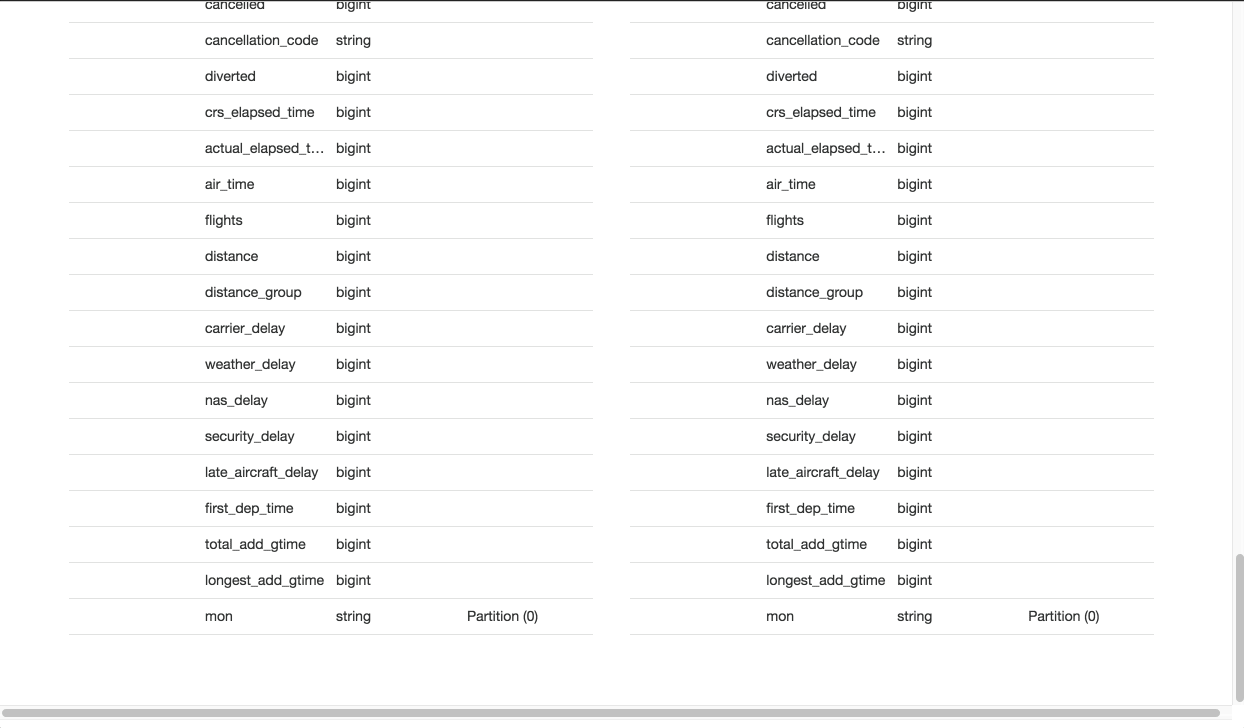
I’m going to make a quick schema change to year, moving it from BIGINT to INT. Then I can compare the two versions of the schema if needed.
Now that we know how to correctly parse this data let’s go ahead and do some transforms.
ETL Jobs
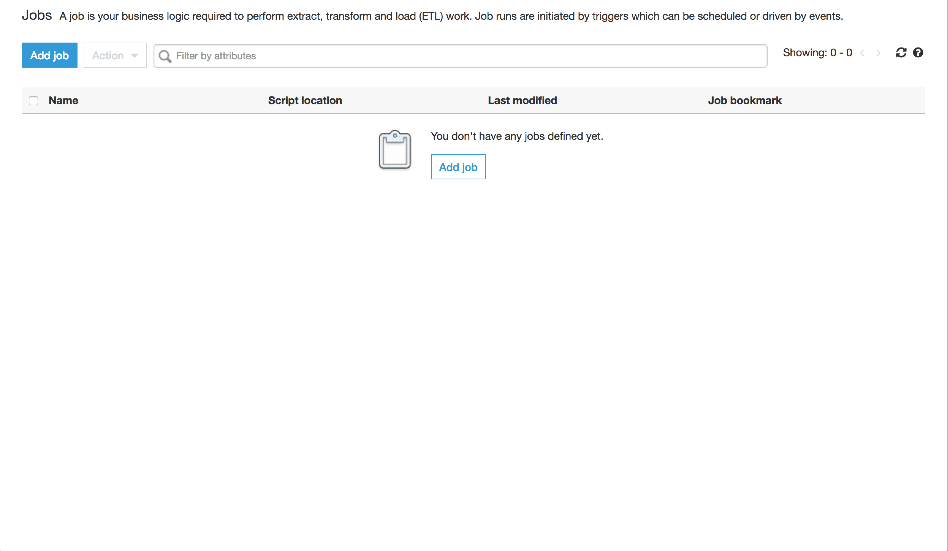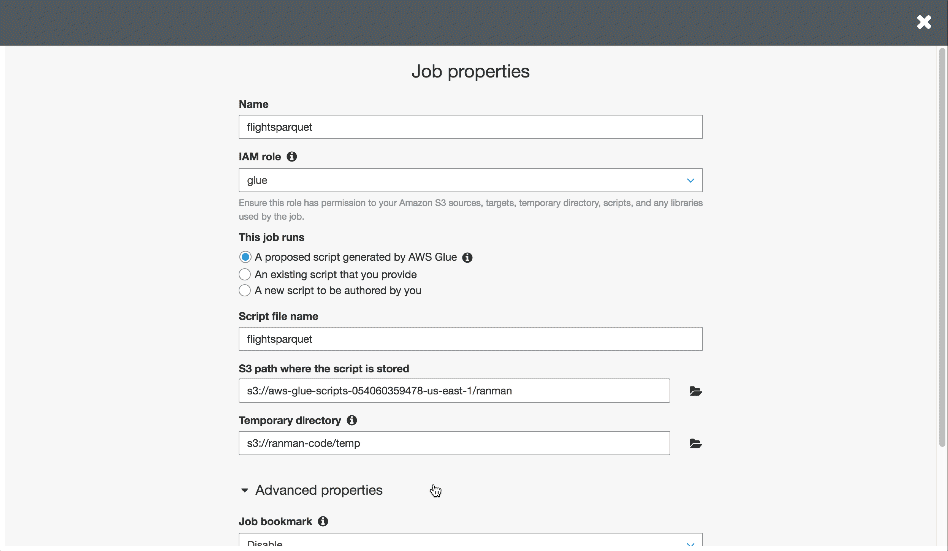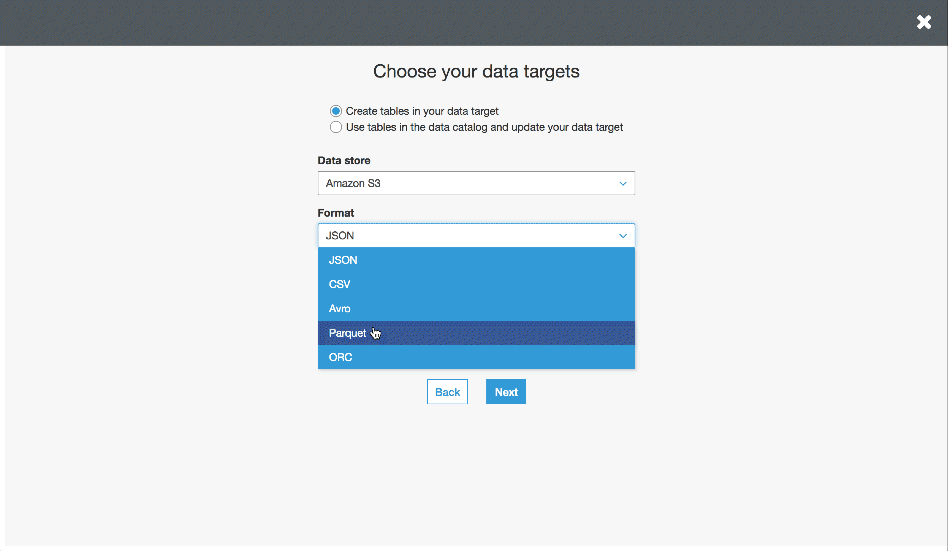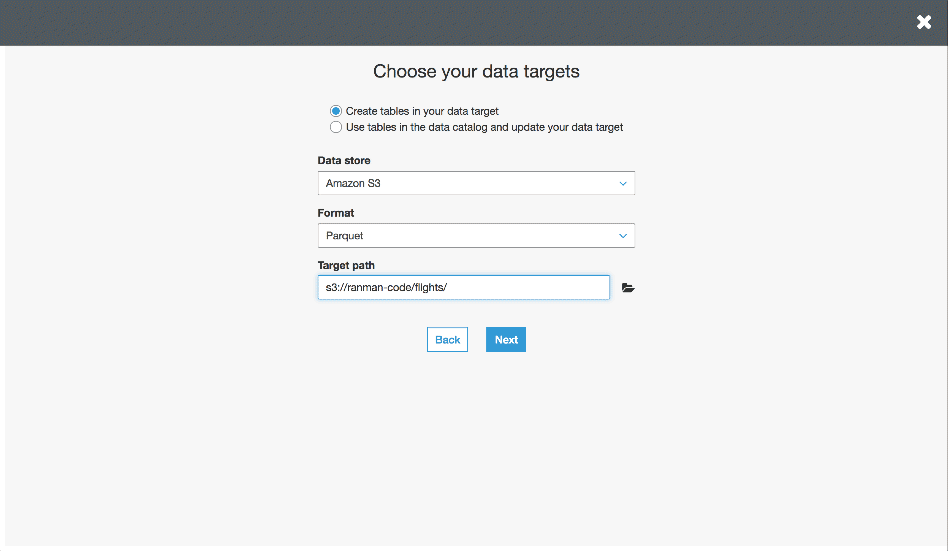
Now we’ll navigate to the Jobs subconsole and click Add Job. Will follow the prompts from there giving our job a name, selecting a datasource, and an S3 location for temporary files. Next we add our target by specifying “Create tables in your data target” and we’ll specify an S3 location in Parquet format as our target.
After clicking next, we’re at screen showing our various mappings proposed by Glue. Now we can make manual column adjustments as needed – in this case we’re just going to use the X button to remove a few columns that we don’t need.

This brings us to my favorite part. This is what I absolutely love about Glue.

Glue generated a PySpark script to transform our data based on the information we’ve given it so far. On the left hand side we can see a diagram documenting the flow of the ETL job. On the top right we see a series of buttons that we can use to add annotated data sources and targets, transforms, spigots, and other features. This is the interface I get if I click on transform.
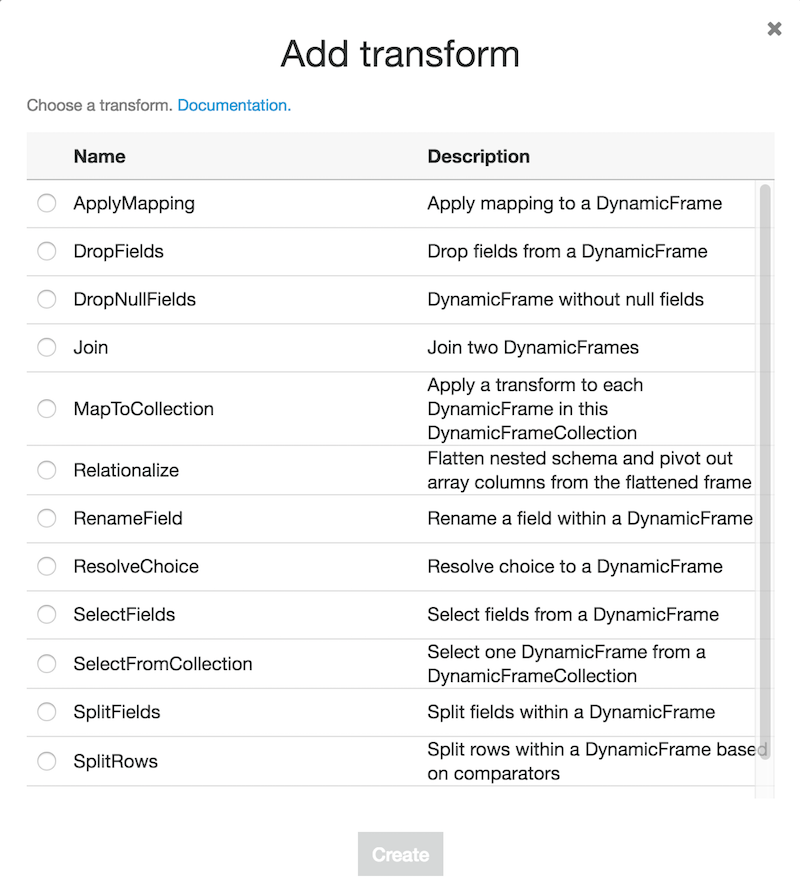
If we add any of these transforms or additional data sources, Glue will update the diagram on the left giving us a useful visualization of the flow of our data. We can also just write our own code into the console and have it run. We can add triggers to this job that fire on completion of another job, a schedule, or on demand. That way if we add more flight data we can reload this same data back into S3 in the format we need.
I could spend all day writing about the power and versatility of the jobs console but Glue still has more features I want to cover. So, while I might love the script editing console, I know many people prefer their own development environments, tools, and IDEs. Let’s figure out how we can use those with Glue.
Development Endpoints and Notebooks
A Development Endpoint is an environment used to develop and test our Glue scripts. If we navigate to “Dev endpoints” in the Glue console we can click “Add endpoint” in the top right to get started. Next we’ll select a VPC, a security group that references itself and then we wait for it to provision.
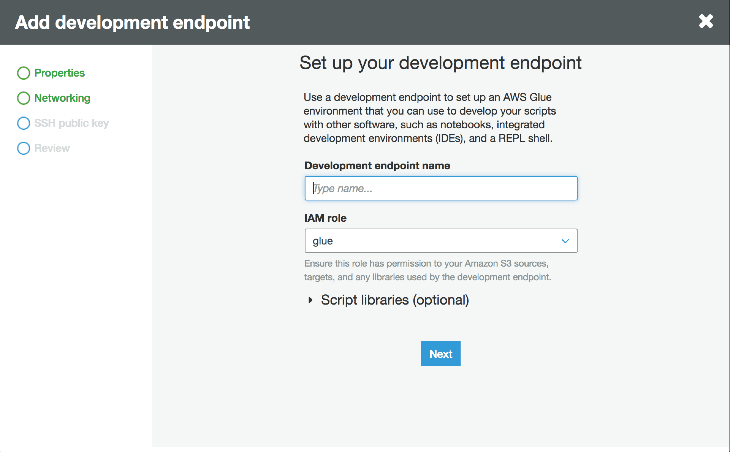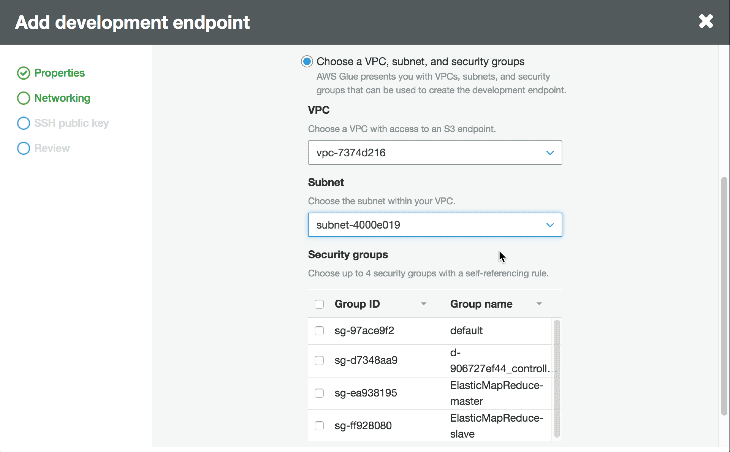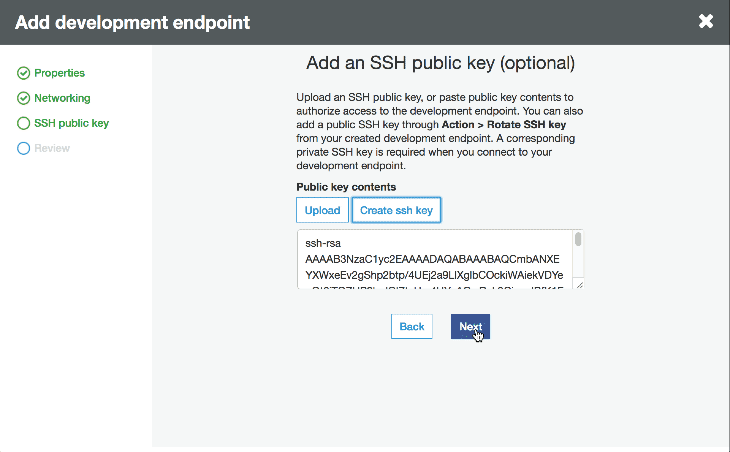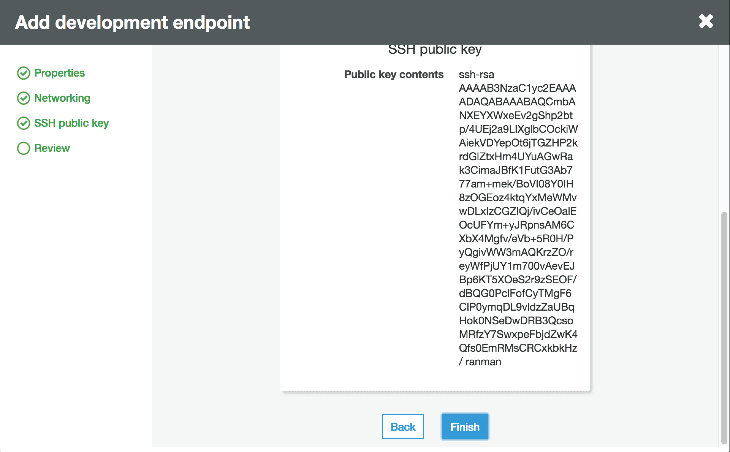
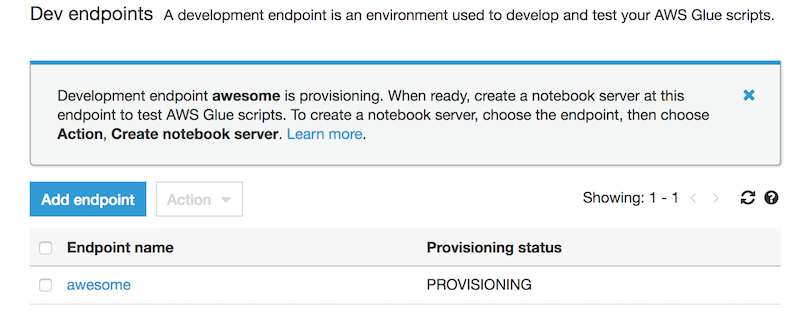
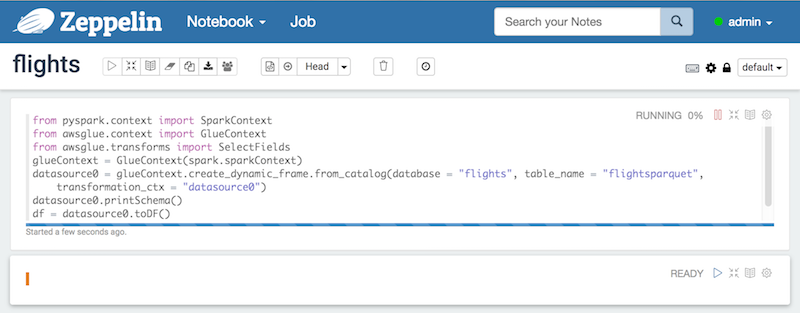
Once it’s provisioned we can create an Apache Zeppelin notebook server by going to actions and clicking create notebook server. We give our instance an IAM role and make sure it has permissions to talk to our data sources. Then we can either SSH into the server or connect to the notebook to interactively develop our script.
Pricing and Documentation
You can see detailed pricing information here. Glue crawlers, ETL jobs, and development endpoints are all billed in Data Processing Unit Hours (DPU) (billed by minute). Each DPU-Hour costs $0.44 in us-east-1. A single DPU provides 4vCPU and 16GB of memory.
We’ve only covered about half of the features that Glue has so I want to encourage everyone who made it this far into the post to go read the documentation and service FAQs. Glue also has a rich and powerful API that allows you to do anything console can do and more.
We’re also releasing two new projects today. The aws-glue-libs provide a set of utilities for connecting, and talking with Glue. The aws-glue-samples repo contains a set of example jobs.
I hope you find that using Glue reduces the time it takes to start doing things with your data. Look for another post from me on AWS Glue soon because I can’t stop playing with this new service.
– Randall