AWS for SAP
SAP Data Services and SAP LT Server for near real-time replication to AWS data lakes
Introduction
This blog contains instructions on how to set up a solution for replicating data from SAP applications, such as SAP S/4HANA or SAP Business Suite, to Amazon Simple Storage Service (Amazon S3) using SAP Landscape Transformation (LT) Replication Server and SAP Data Services (DS). SAP Landscape Transformation Replication Server is an ideal solution for organizations that need near real-time replication.
Many enterprise customers have deployed data lakes to optimize manufacturing outcomes, track business performance and accelerate product lifecycle management. The initial process of loading involves bringing data from several commercial off-the-shelf (COTS) applications and non-COTS applications. There are several approaches to extracting SAP data, as outlined in out earlier blog – Building data lakes with SAP on AWS.
Tens of thousands of data lakes are already deployed on AWS. Customers are benefiting from storing their data in Amazon S3 and analyzing that data with the broadest set of analytics and machine learning services to increase their pace of innovation. AWS offers the broadest and most complete portfolio of native ingest and data transfer services, plus more partner ecosystem integrations with S3.
SAP Data Services is one of the popular ETL engines, delivering a single enterprise-class solution for data integration, data quality, data profiling, and text data processing. It enables you to integrate, transform, improve, and deliver trusted data to critical business processes. When combined with SAP LT server, it can enable near real-time data replication to AWS data lake solutions. This gives customers the choice of either batch or near-real-time processing for analytic services. SAP Data Services comes prepackaged with multiple out of the box connectors for SAP and other applications/databases.
Prerequisites
The instructions are intended for SAP ETL or technology consultants who have some experience with the configuration of SAP Basis, SAP Data services, SAP LT, Amazon S3, and AWS Identity and Access Management (IAM). The core solution components for extraction, transformation and loading are as follows:
SAP DMIS 2011 SP3 or later
SAP Landscape Transformation Replication Server 2.0 or later
SAP data services 4.2 SP1 or higher
Solution Overview

The Operational data provisioning (ODP ) framework supports extraction and replication scenarios for various target SAP applications, known as subscribers. The subscribers retrieve the data from the delta queue for further processing.
Data gets replicated as soon as a subscriber requests the data from a data source through an ODP context. An Operational Data queue is used to maintain the different queues of data between publishers and subscribers. To know in depth about ODP and ODQ, please refer to the documentation from SAP.
SAP LT replication server can act as a provider to the ODP context. The detailed steps are below.
AWS
- Set up your AWS Account
- Create an S3 Bucket and a folder within the bucket (e.g. “Product”)
- Create an IAM role to provide full access for this S3 bucket
- Create an IAM user with programmatic access and attach the IAM role to the user
- Download the access key and secret key information for the user. This is used to apply these credentials in SAP Data Service
SAP LT
- Login to SAP. Please ensure that you have SLT admin access.
- Go to transaction LTRC
- Select Create Configuration Icon
- Enter a Configuration Name and Description as indicated below.
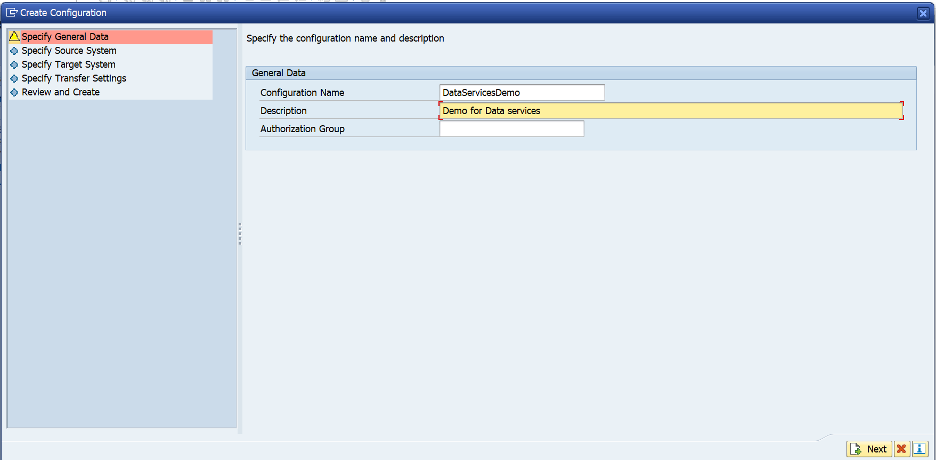
- Select RFC Connection. In the Destination Box, choose None.
(Please note that if your SLT system is separate from your ECC system, enter the RFC destination of the source system).

- Click next. In the target, Select RFC destination and choose NONE as indicated below
- Choose the Scenario for RFC communication as ODP Replication Scenario.
- Choose any 4 character Alias (Please note that this will be used in the ODP context in data services later).
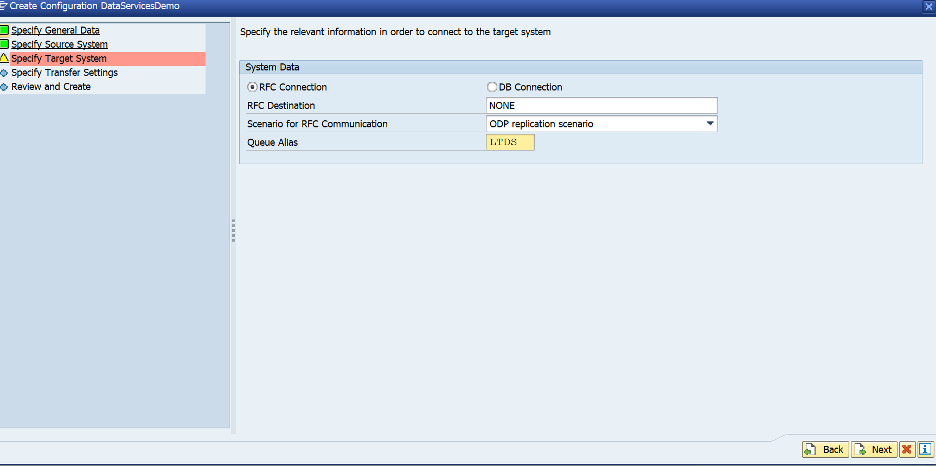
Choose next
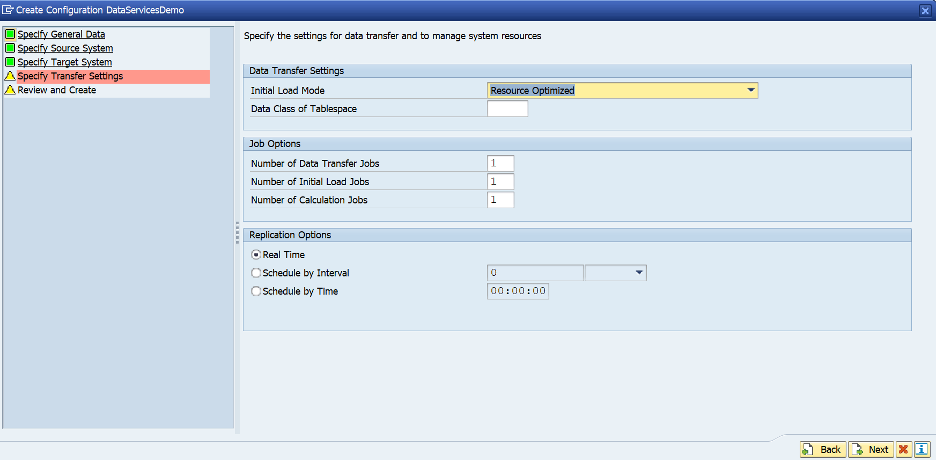
Review and Select Create
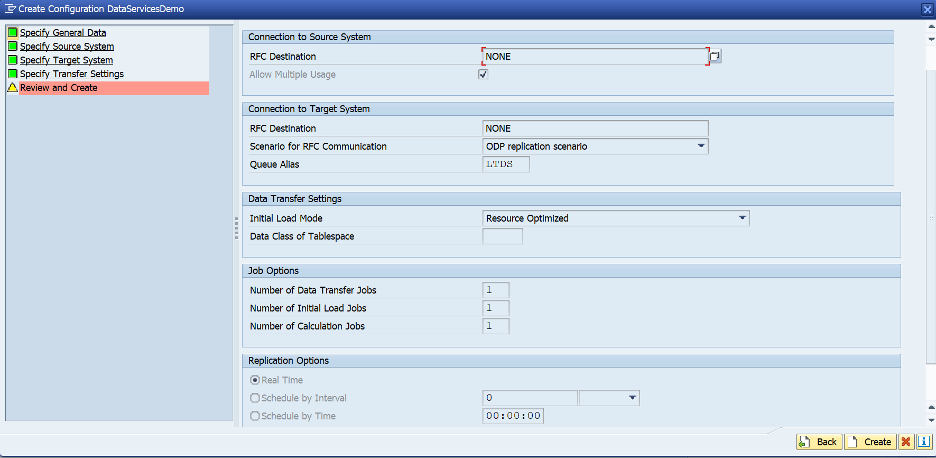
The queue should be active. Click on the configuration name to review settings.
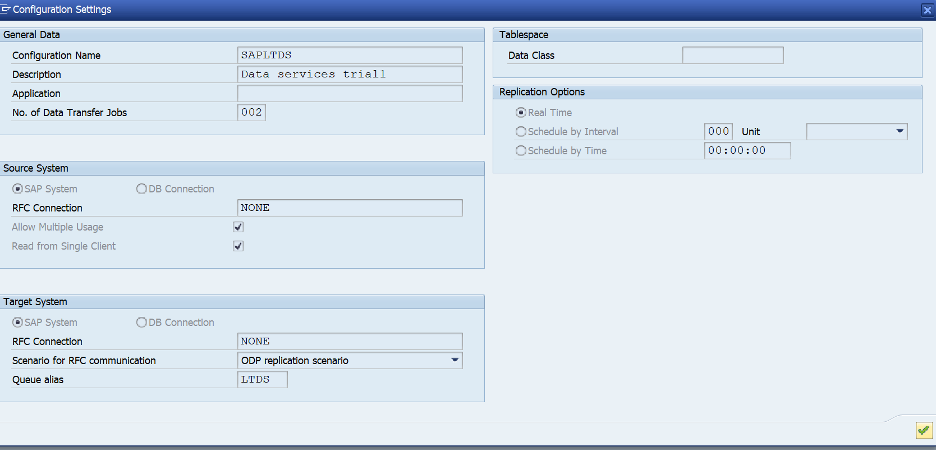
Please note that every dictionary table in SAP source system can be queried using SLT context.
SAP Data Services
Source Creation
Open SAP Data Services Designer.
- Right-click on your SAP Data Services project name in Project Explorer.
- Select New > Datastore.
- Fill in Datastore Name. For example, NPL.
- In the Datastore type field, select SAP Applications.
- In the Application server name box, provide the instance name of the SAP SLT application server,
- Specify the access credentials. Please create a separate user in SAP LT server for Data services if possible.
- Open the Advanced button.
In ODP Context, enter SLT~ALIAS, where ALIAS is the queue alias that you specified during SLT configuration.
Click OK.
The new datastore appears in the Datastore tab in the local object library in Designer
Target Data Store
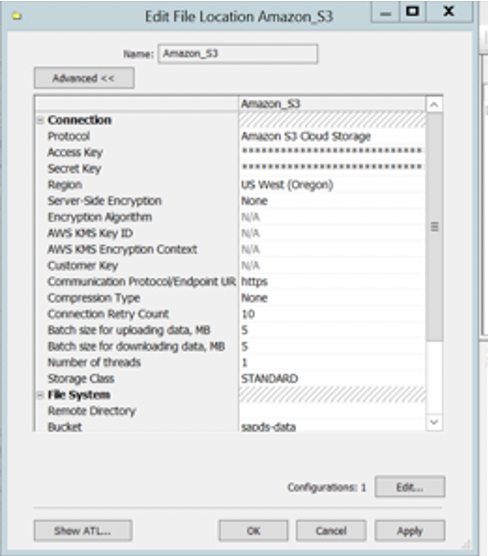
Configure a File Location object to point to the S3 Bucket
- Select File Formats
- Select File Locations and Right click to create new file location.
- Choose Protocol as Amazon Cloud Storage and enter the access key and secret key credentials saved earlier.
- Enter the region and bucket name as indicated in the screenshot below.
- Save the credentials and test to ensure connectivity works
Creating Import for your SAP Data service flow
Following steps import ODP objects from the source datastore for the initial and delta loads and make them available in SAP Data Services to process the data to Amazon S3.
- From your SAP Data Services designer application, expand the source datastore for replication load and double click on the ODP object.
- Select the External Metadata option in the upper portion of the right panel. The list of nodes with available tables and ODP objects appears
- Click on the ODP objects node to retrieve the list of available ODP objects. The list might take a long time to display.
- Click on the Search button. In the dialog screen, select External data in the look in menu and ODP object in the object type menu.
- In the Search dialog, select the search criteria to filter the list of source ODP object(s)
- Select the ODP object to import from the list (example SNWD_PD).
- Right-click and select the Import option.
- Enter the Name of Consumer with desired value, enter the Name of Project which is your Data Service project name from earlier steps
- Select Changed-data capture (CDC) option in Extraction mode. Click Import to import the ODP object into Data Services.
- Validate the ODP object in object library of your data store.
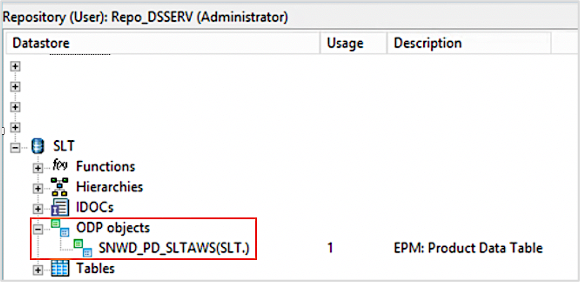
Note: For more information, see Importing ODP source metadata section in SAP Data Services documentation.
Creating Data Flow and Batch job
- Open the SAP Data Services Designer application and access the data flow section.
- Right click and create a new data flow with a desired name for your project.
- Click Finish
- Right click on the project to create new batch job.
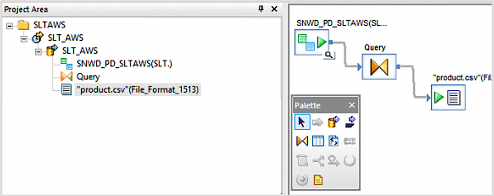
- Drag and drop the dataflow on the canvas.
- Double click on the data flow drag the ODP object on to the data flow workspace
- Double click on the ODP object and select initial load to No
- Drag a query object from the transforms tab to the data flow workspace and connect it to the ODP object.
- Double click on query object from the canvas and right click in the schema out section to select Create File Format option.

- Go to data file section file format editor, input the Amazon S3 bucket in the location section created during target data source configuration.
- Enter the folder name of your Amazon S3 bucket as the directory name
- Provide a desired name for your file in the File names(s) section and save the configuration.
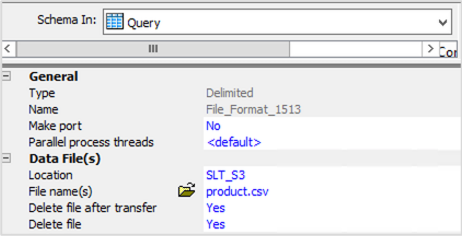
- Validate the new file format and drag the file format to data flow workspace and save your changes.
For CDC operations, you might want a date time stamp embedded into the file name. SAP documentation for this step is available here
Execute your data flow
Right click on the job name and execute your data flow. The initial set of records will be loaded to your S3 bucket.
Add more records to ODP object. For this session, we are running transaction SEPM_PD to add more records to ODP object SNWD_PD.
Rerun the job, to load the deltas.

Note: The jobs can be scheduled in the background for large tables
Conclusion
Landing the SAP data in S3 is the first step in unlocking the value potential of this data. AWS provides many services to manage, enrich, and analyze the data residing in S3. Data changes can be captured and consolidated in Parquet format using AWS DMS and AWS Glue.
Customers like Zalando are taking this farther, and moving the SAP data into Amazon Redshift using HANA federation to gain economies of scale for their analytical data while keeping their core business KPIs within SAP.