AWS Big Data Blog
Introducing AWS Glue 3.0 with optimized Apache Spark 3.1 runtime for faster data integration
May 2022: This post was reviewed for accuracy.
In August 2020, we announced the availability of AWS Glue 2.0. AWS Glue 2.0 reduced job startup times by 10x, enabling customers to realize an average of 45% cost savings on their extract, transform, and load (ETL) jobs. The fast start time allows customers to easily adopt AWS Glue for batching, micro-batching, and streaming use cases. In the last year, AWS Glue has evolved from an ETL service to a serverless data integration service, offering all the required capabilities needed to build, operate and scale a modern data platform. The following are some of the use cases you can accomplish with AWS Glue:
- Move data to and from a broad variety of data sources and software as a service (SaaS) applications using AWS Glue custom connectors
- Populate a central AWS Glue Data Catalog using AWS Glue crawlers, which are capable of inferring the schema, detecting data drift, and keeping the metadata up to date easily and quickly
- Build and share reusable data pipelines running on AWS Glue workflows using custom blueprints
- Process data in near-real time using event-driven workflows and AWS Glue streaming.
- Visually clean and prepare data for analysis using AWS Glue DataBrew
- Visually author AWS Glue ETL jobs in AWS Glue Studio to simplify how you build, maintain and monitor data pipelines.
Today, we are pleased to announce AWS Glue version 3.0. AWS Glue 3.0 introduces a performance-optimized Apache Spark 3.1 runtime for batch and stream processing. The new engine speeds up data ingestion, processing and integration allowing you to hydrate your data lake and extract insights from data quicker.
AWS Glue version 3.0 highlights
Performance-optimized Spark runtime based on open-source Apache Spark 3.1.1 and enhanced with innovative optimizations developed by the AWS Glue and Amazon EMR teams. These optimizations accelerate data integration and query processing with advanced techniques, such as SIMD based vectorized readers developed in native language (C++), in-memory columnar formats for processing, optimized shuffles, partition coalescing, and Spark’s adaptive query execution. The AWS Glue 3.0 runtime is built with upgraded JDBC drivers for all AWS Glue native sources, including MySQL, Microsoft SQL Server, Oracle, PostgreSQL, and MongoDB, to enable simpler, faster, and secure integration with new versions of database engines.
Faster read and write access with the AWS Glue 3.0 runtime to Amazon Simple Storage Service (Amazon S3) using vectorized readers with Glue Dynamic Frames, and Amazon S3 optimized output committers. These optimizations improve Spark application performance for popular customer workloads reading row-based formats such as CSV and writing to columnar formats such as Apache Parquet.
Faster and efficient partition pruning with the AWS Glue 3.0 runtime when analyzing large, highly partitioned tables managed AWS Glue Data Catalog. For highly partitioned datasets, partition pruning can significantly reduce the cost of catalog partition listing and query planning by filtering out unnecessary partitions using partition indexes.
Fine-grained access control with the AWS Glue 3.0 runtime for your batch jobs using AWS Lake Formation. You can now access your data at the database, table, column, row, and cell-level using resource names and Lake Formation tag attributes (available in preview).
ACID transactions offered with the AWS Glue 3.0 runtime for Lake Formation Governed Tables and query acceleration with automatic file compaction on your data lake (available in preview).
Improved user experience for monitoring, debugging, and tuning Spark applications. Spark 3.1.1 enables an improved Spark UI experience that includes new Spark executor memory metrics and Spark Structured Streaming metrics that are useful for AWS Glue streaming jobs.
With AWS Glue 3.0, you continue to benefit from reduced startup latency, which improves overall job execution times and makes job and pipeline development more interactive. AWS Glue 3.0 Spark jobs are billed per second, with a 1-minute minimum, similar to AWS Glue 2.0.
Getting started with AWS Glue 3.0
You can start using AWS Glue 3.0 via AWS Glue Studio, the AWS Glue console, the latest AWS SDK, and the AWS Command Line Interface (AWS CLI).
To start using AWS Glue 3.0 in AWS Glue Studio, choose the version Glue 3.0 – Supports spark 3.1, Scala 2, Python 3.

To migrate your existing AWS Glue jobs from AWS Glue 0.9, 1.0, and 2.0 to AWS Glue 3.0, see Migrating AWS Glue jobs to AWS Glue version 3.0.
Performance of AWS Glue 3.0
AWS Glue 3.0 speeds up your Spark applications in addition to offering reduced startup latencies. The following benchmark shows the performance improvements between AWS Glue 3.0 and AWS Glue 2.0 for a popular customer workload to convert large datasets from CSV to Apache Parquet format. The comparison uses the largest store_sales table in the TPC-DS benchmark dataset (3 TB). All Spark jobs run on warm 60 G.2X workers. All values in store_sales table are numeric. We compare performance with schema enforcement, casting values into numeric data type and without schema enforcement, casting them to string type. Enforcing schema to numeric types allows for compact in-memory representations and faster deserialization. No schema enforcement allows for flexibility with string types.
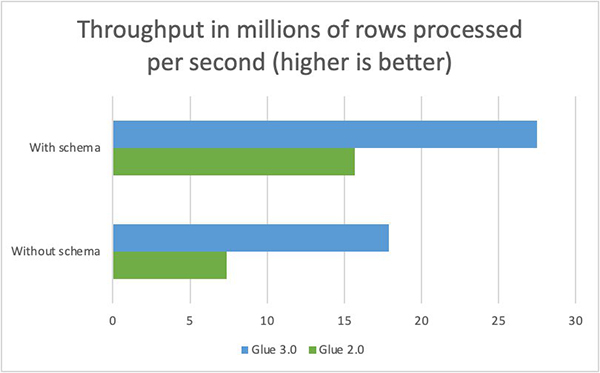
AWS Glue 3.0 speeds up performance by as much as 2.4 times compared to AWS Glue 2.0 with the use of vectorized readers, which are implemented in C++. It also uses micro-parallel SIMD CPU instructions for faster data parsing, tokenization and indexing. Additionally, it reads data into in-memory columnar formats based on Apache Arrow for improved memory bandwidth utilization and direct conversion to columnar storage format such as Apache Parquet.
Conclusion
In this post, we introduced a faster, more efficient AWS Glue engine based on Apache Spark 3.1 that includes innovative features to enable your jobs to run faster and reduce costs. With only minor changes to your job configurations and scripts, you can start using AWS Glue 3.0 today. To learn more about new features, library versions, and dependencies in AWS Glue 3.0, see Migrating AWS Glue jobs to AWS Glue version 3.0.
About the Authors
 Noritaka Sekiyama is a Senior Big Data Architect on the AWS Glue team. He is passionate about architecting fast-growing data platforms, diving deep into distributed big data softwares like Apache Spark, building reusable software artifacts for data lakes, and sharing the knowledge in AWS Big Data blog posts.
Noritaka Sekiyama is a Senior Big Data Architect on the AWS Glue team. He is passionate about architecting fast-growing data platforms, diving deep into distributed big data softwares like Apache Spark, building reusable software artifacts for data lakes, and sharing the knowledge in AWS Big Data blog posts.
 Neil Gupta is a Software Development Engineer on the AWS Glue team. He enjoys tackling big data problems and learning more about distributed systems.
Neil Gupta is a Software Development Engineer on the AWS Glue team. He enjoys tackling big data problems and learning more about distributed systems.
 XiaoRun Yu is a Software Development Engineer on the AWS Glue team.
XiaoRun Yu is a Software Development Engineer on the AWS Glue team.
 Rajendra Gujja is a Software Development Engineer on the AWS Glue team. He is passionate about distributed computing and everything and anything about the data.
Rajendra Gujja is a Software Development Engineer on the AWS Glue team. He is passionate about distributed computing and everything and anything about the data.
 Mohit Saxena is a Software Engineering Manager on the AWS Glue team. His team works on distributed systems for efficiently managing data lakes on AWS and optimizes Apache Spark for performance and reliability.
Mohit Saxena is a Software Engineering Manager on the AWS Glue team. His team works on distributed systems for efficiently managing data lakes on AWS and optimizes Apache Spark for performance and reliability.
 Kinshuk Pahare is a Principal Product Manager on the AWS Glue team.
Kinshuk Pahare is a Principal Product Manager on the AWS Glue team.