Amazon Web Services ブログ
Amazon OpenSearch Serverless のコレクショングループでマルチテナントワークロードのコストを最適化
本記事は 2026 年 2 月 26 日 に公開された「Amazon OpenSearch Serverless introduces collection groups to optimize cost for multi-tenant workloads」を翻訳したものです。
本日、Amazon OpenSearch Serverless のコレクショングループ機能の一般提供を開始しました。テナントごとの暗号化による安全なテナント境界を維持しながら、マルチテナントワークロードのコンピューティングコストを削減できます。コスト効率とアプリケーションに必要な分離・セキュリティレベルを柔軟に調整できます。
Amazon OpenSearch Serverless は Amazon OpenSearch Service のサーバーレスデプロイオプションで、検索や分析ワークロードを大規模に実行する際のインフラストラクチャ管理が不要になります。使用パターンが変化しても、リソースを自動的にプロビジョニング・スケーリングし、高速なデータ取り込みとミリ秒単位のレスポンスタイムを実現します。マルチテナント環境を管理する組織にとって、テナントのデータを暗号化して保護するデータ分離 (多くの場合、独自の暗号化キーを使用) はコンプライアンス要件です。
従来、OpenSearch Serverless は物理的な分離で高いセキュリティを確保していました。各 AWS Key Management Service キー (KMS キー) には、完全な物理的データ分離を維持するための専用 OpenSearch Compute Units (OCU) が必要でした。このアーキテクチャは高い保護を提供する一方、大規模なマルチテナントデプロイでは課題がありました。共有暗号化キーを使用する複数テナントの場合、OCU リソースは効率的にプールされ、経済性は良好です。しかし、データ分離のために独自の KMS キーを必要とする小規模テナントを多数管理する場合、コストが高くなるという課題がありました。一意のキーごとに専用 OCU リソースが必要なため、個々のテナントが OCU 容量のごく一部しか使用しない場合、インフラストラクチャコストが過大になる可能性がありました。特に、顧客に Bring Your Own Key (BYOK) 機能を提供したいサービスプロバイダーに影響し、持続不可能なコストを負担するか、サービス提供を制限するかの選択を迫られていました。
OpenSearch Serverless は、コスト管理のための最大 OCU 設定による柔軟なキャパシティ管理を提供してきました。ほとんどのワークロードでは、需要に応じてキャパシティがスケールアップ・ダウンするため、使用した分だけ支払えば済みます。しかし、一部のワークロードパターンでは、最初から一定のベースラインコンピューティングを確保しておく方が適しています。突発的なトラフィックスパイク、高速データ取り込みパイプライン、負荷テストなどのシナリオでは、キャパシティを事前に割り当てておくことで、最初のリクエストから他のリクエストと同じ応答性で処理できます。同様に、マルチテナントアーキテクチャや時間的制約のあるオペレーションでは、コレクションがアクティブになった瞬間から予測可能で一貫したパフォーマンスが求められます。
コレクショングループによる柔軟な制御
コレクショングループにより、セキュリティ境界とリソース割り当てを柔軟に制御できます。画一的なアプローチではなく、セキュリティ要件とコスト要件に合わせてアーキテクチャを調整できます。仕組みは次のとおりです。
- ニーズに合ったセキュリティ境界の定義: コレクショングループは、関連するコレクションの論理的なセキュリティ構成です。各コレクショングループは、他のコレクショングループとメモリ、CPU、ディスクが物理的に分離されており、異なるセキュリティ構成間の強固なセキュリティ境界を確保します。
- 暗号化キー間でのリソース共有: KMS キーの共有・個別使用に関係なく、コレクションをコレクショングループに割り当てられます。異なる暗号化キーを持つコレクションが同じセキュリティ境界内で OCU リソースを共有できるようになり、各テナントの完全な暗号化保護と論理的分離を維持しながら、コストを大幅に削減できます。
- 柔軟なネットワークアクセスでのデプロイ: コレクショングループは異なるネットワークアクセスタイプのコレクションをサポートし、パブリックエンドポイントと VPC エンドポイントのコレクションを同じグループ内に組み合わせられます。セキュリティと接続要件に合わせながら、グループ内の全コレクションで共有リソース管理のメリットを享受できます。
- コストとパフォーマンスの制御: 最大 OCU で支出を制限し、最小 OCU でベースラインパフォーマンスを保証します。二重制御により各コレクショングループのリソース範囲が明確になり、予期しないコスト増加を防ぎつつ一貫したパフォーマンスを確保できます。
- インサイトによる最適化: コレクショングループ全体のリソース消費、相対的な使用パターン、レイテンシーを示す詳細な CloudWatch メトリクスにアクセスできます。インサイトを活用して、割り当ての適正化、最適化の機会の特定、実際のワークロード動作に基づくパフォーマンスチューニングが可能です。
コレクショングループにより、最小・最大 OCU 設定の両方でリソース割り当てを完全に制御できます。
最大 OCU: コスト制御
リソースの上限を設定して、コレクショングループごとの過剰なスケーリングを防ぎ、コストを制御します。予期しないトラフィックスパイク時でも予算を超えないようにできます。コレクショングループのキャパシティ制限はアカウントレベルの制限とは独立して動作します。アカウントレベルの最大 OCU 設定はコレクショングループに関連付けられていないコレクションにのみ適用され、コレクショングループの最大 OCU 設定はそのグループ内のコレクションに適用されます。(全コレクショングループの最大 OCU の合計 + アカウントレベルの最大 OCU 設定) がアカウントの Service Quota で許可された最大 OCU 以下である必要があります。アカウントレベルとコレクショングループレベルの分離により、異なるセキュリティコンテキスト間できめ細かなコスト制御が可能です。
最小 OCU: パフォーマンス保証
コレクショングループに常に割り当てるベースラインコンピューティングリソースを定義し、一貫したパフォーマンスとリソースの可用性を確保します。OCU はコレクショングループ専用に予約され、次のメリットがあります。
- コールドスタートなしの即時利用: コレクションはスケーリング遅延なしで即座に利用できます。リソースは常にウォーム状態で準備されており、トラフィック到着時の遅延がありません。
- キャパシティの保証: 低アクティビティ期間中や他のコレクショングループとの競合時でもリソースが常に利用可能で、低トラフィック時でも予測可能なパフォーマンスを確保します。
- 予測可能なコスト: 最小 OCU は継続的に課金され、予測可能な請求と引き換えに予約キャパシティを提供します。保証されたパフォーマンスと引き換えにコストの確実性が得られます。予約ベースラインはオートスケーリングの基盤となり、需要の増加に応じて最大制限までキャパシティを拡張します。
最小・最大 OCU の組み合わせにより、要件に基づいてコスト最適化とパフォーマンス保証を柔軟に調整できます。
コレクショングループによるマルチテナントのコスト経済性
マルチテナントアーキテクチャのコスト管理では、分離、パフォーマンス、効率のバランスが常に求められ、いずれかを犠牲にすることが多くありました。コレクショングループは、セキュリティ境界を犠牲にすることなくコレクション間で共有キャパシティを実現し、従来の前提を覆します。コレクショングループの有無による違いを以下に示します。
コレクショングループ導入前: データ分離のためにそれぞれ独自の KMS キーを必要とする 10 テナントの顧客を考えます。テナントのほとんどは控えめなデータ要件で、通常 10〜100 GB、大半はその範囲の小さい方です。実際のキャパシティニーズに関係なく、各テナントの暗号化キーに専用リソースを管理することで、大規模な運用の複雑さとコストの課題が生じていました。
コレクショングループ導入後: 同じ顧客が、類似のセキュリティ要件を持つテナントをコレクショングループにまとめ、コレクション間で OCU リソースを共有できます。OCU キャパシティのごく一部しか必要としないテナントに専用リソースを割り当てる必要がなくなり、小規模テナントが多いワークロードではコストを最大 90% 削減できます。
最小 OCU 設定の場合: プレミアムテナントは最小 OCU を設定したコレクショングループに配置してパフォーマンスを保証し、スタンダードテナントはより低い最小しきい値のコレクショングループでコスト効率を高められます。
次の表は、コレクショングループの有無で異なるテナント構成におけるインフラストラクチャコストを比較し、さまざまなデータサイズとクエリ負荷でのコスト削減効果を示しています。
|
一意の KMS キーを持つテナント数 |
データサイズとクエリパラメータ |
完全なデータ分離のコスト (コレクショングループなし) |
コレクショングループ使用時のコスト |
補足 |
| 10 |
データサイズ: 60 GB 以下 クエリ: ベース OCU (冗長コレクションの場合 1) を超えるコンピューティングが不要 |
$3,500 | $350 | コストを 10 分の 1 に削減。 |
| 10 |
データサイズ: 60 GB 以下 クエリ: ピーク時にベース OCU (冗長コレクションの場合 1) を超えるコンピューティングが必要 (例: コレクショングループなしではテナントあたり追加 5 OCU、コレクショングループでは共有インフラのメリットにより全テナントで 40 OCU)。 |
$3,500 + ピーク時のテナントごとのスケールアウト ($8,650) | $350 + ピーク時のスケールアウト ($6,912) | 追加のクエリ負荷がかかるとシステムがスケールアップし、追加 OCU がデプロイされます。負荷が減少するとシステムはベース OCU にスケールインします。 |
| 10 | テナントごとのサンプルデータサイズ (GB): [3, 5, 7, 8, 10, 15, 18, 25, 28, 150]
クエリ: データサイズに対する最小 OCU で一定レベルまでクエリを処理し、負荷に応じてスケールアウト。 |
サンプルデータサイズの場合、最小 OCU 要件は [2, 2, 2, 2, 2, 2, 2, 2, 2, 8] = 26 OCU [$4,492] + ピーク時のテナントごとのスケールアウト | 最小コストは全テナントのデータを保持するために必要な OCU 数 (OCU あたり 120 GB × 2) + ピーク時のスケールアウトで決まります。サンプルデータサイズの場合、8 OCU [$1,382] + ピーク時のテナントごとのスケールアウト | 追加のクエリ負荷がかかるとシステムがスケールアップし、追加 OCU がデプロイされます。負荷が減少するとシステムはデータを保持するために必要な最小 OCU 数にスケールインします。 |
注: 上記の計算は冗長性が有効なコレクションを前提としています。非冗長モードの場合、上記の計算の半分になります。
コレクショングループの使用開始
コレクショングループと最小 OCU 設定は、OpenSearch Serverless が提供されている全 AWS リージョンで追加料金なしで利用できます。コレクショングループを作成し、新しいコレクションをグループに直接追加して管理を強化できます。既存のコレクションはコレクショングループとは独立して変更なく動作し続けますが、新しいコレクションでコレクショングループをすぐに使い始められます。
現在、新しく作成したコレクションのみコレクショングループに関連付けることができ、グループ内の全コレクションは同じタイプ (検索、時系列、またはベクトル検索) である必要があります。既存のコレクションは現在のキャパシティ管理設定で独立して動作し続け、1 つのコレクショングループ内に異なるコレクションタイプを混在させることはできません。AWS マネジメントコンソール、AWS CLI、AWS CloudFormation、または AWS CDK でコレクショングループを作成できます。次のセクションでは、OpenSearch Service コンソールでの作成方法を説明します。
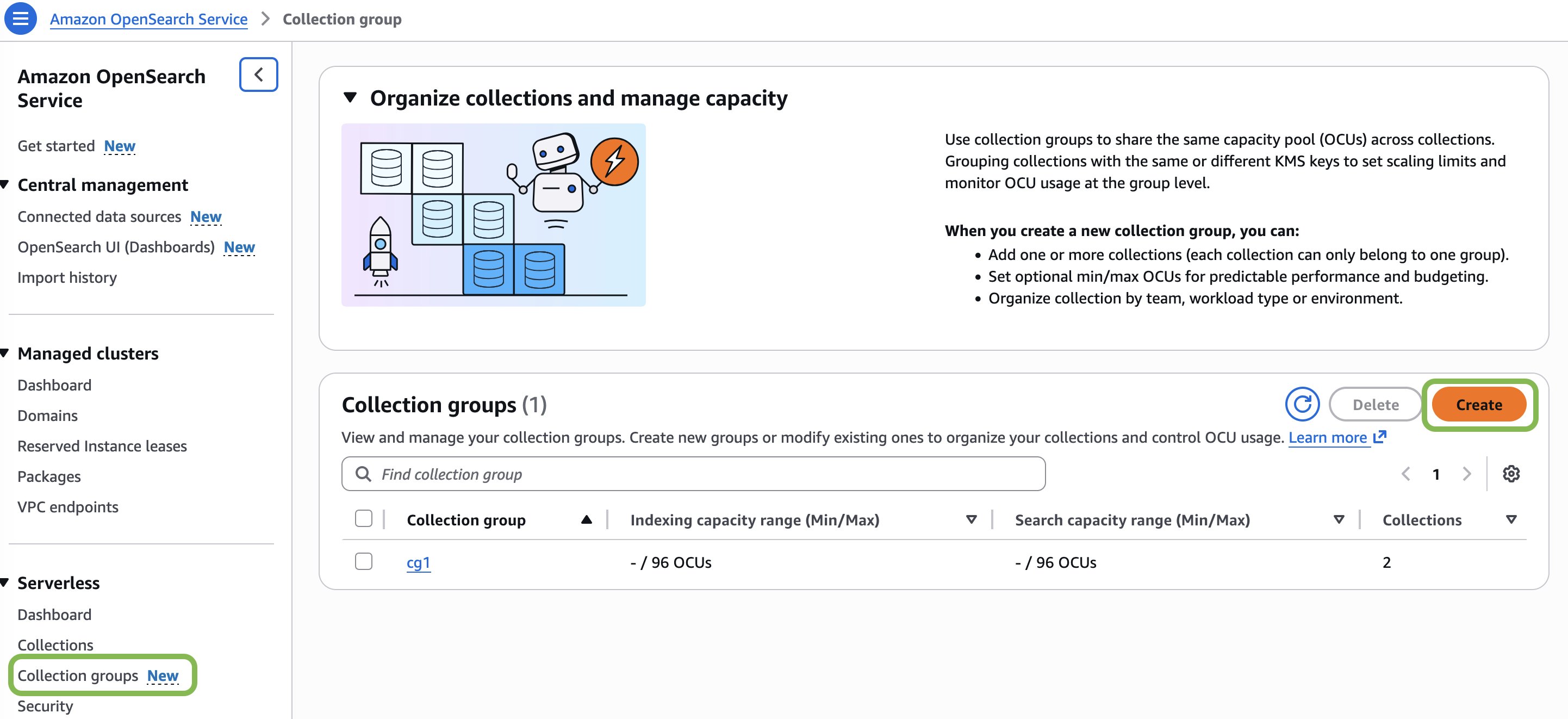
最初のコレクショングループを作成するには:
- OpenSearch Service コンソールを開きます。
- 左のナビゲーションペインで Serverless を選択し、Collection groups を選択します。
- Create collection groups を選択します。
- collection groups name にコレクショングループの名前を入力します。名前は 3〜32 文字で、小文字で始まり、小文字、数字、ハイフンのみ使用できます。
- (オプション) Description にコレクショングループの説明を入力します。
- Capacity management セクションで OCU 制限を設定します。
- Maximum indexing capacity – グループ内のコレクションがスケールアップできるインデキシング OCU の最大数。
- Maximum search capacity – グループ内のコレクションがスケールアップできる検索 OCU の最大数。
- Minimum indexing capacity – 一貫したパフォーマンスを維持するためのインデキシング OCU の最小数。
- Minimum search capacity – 一貫したパフォーマンスを維持するための検索 OCU の最小数。
- (オプション) Tags セクションで、コレクショングループの整理と識別に役立つタグを追加します。
- Create collection groups を選択します。
コレクションをコレクショングループに割り当てるには
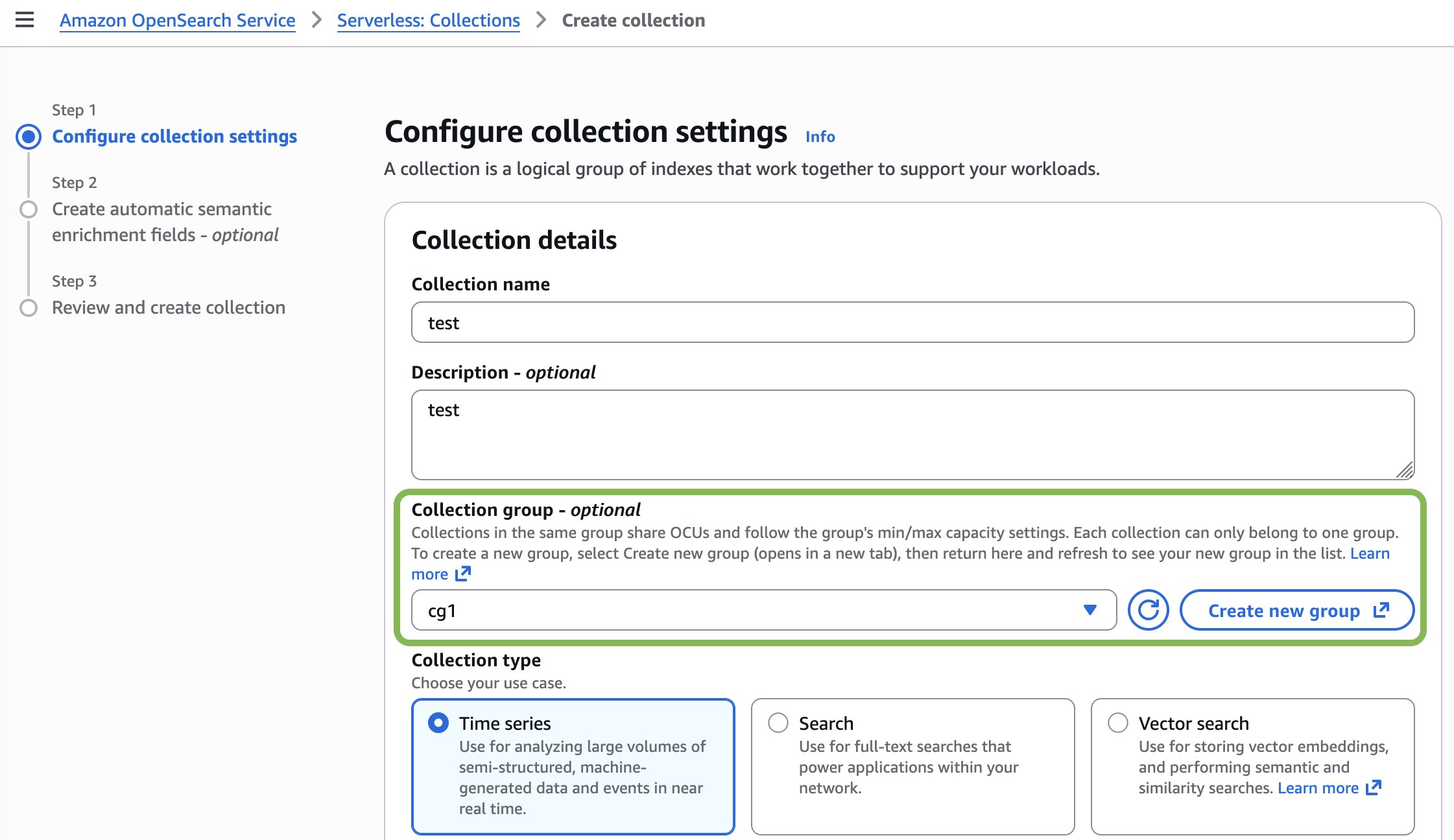
- Amazon OpenSearch Service コンソールを開きます。
- 左のナビゲーションペインで Serverless を選択し、Collections を選択します。
- Create collection を選択します。
- Collection name にコレクションの名前を入力します。名前は 3〜28 文字で、小文字で始まり、小文字、数字、ハイフンのみ使用できます。
- (オプション) Description にコレクションの説明を入力します。
- Collection groups セクションで、コレクションを割り当てるコレクショングループを選択します。コレクションは一度に 1 つのコレクショングループにのみ所属できます。
(オプション) Create a new group を選択して新しいグループを作成することもできます。コレクショングループの作成が完了したら、ステップ 1 に戻って新しいコレクションの作成を開始します。 - ワークフローを続行してコレクションを作成します。
コレクショングループの管理
コレクショングループを作成したら、アーキテクチャの進化に合わせて設定を更新できます。Amazon OpenSearch Serverless のドキュメントに、AWS マネジメントコンソール、CLI、CloudFormation でのコレクショングループの編集・削除、OCU 制限の更新、グループ設定の変更に関するステップバイステップのガイダンスがあります。
まとめ
OpenSearch Serverless のコレクショングループは、セキュリティ要件と運用効率を両立する柔軟なデプロイモードを提供し、マルチテナントデプロイのアーキテクチャを変革します。コレクショングループで論理的なセキュリティ境界を定義し、同じ KMS キーを共有するか異なる KMS キーを使用するかに関係なく、コレクション間で OCU リソースを共有できます。
コレクショングループの柔軟性は、従来マルチテナントデプロイを困難にしていたコスト課題に直接対応します。コレクショングループ内にコレクションを統合することで、暗号化とテナント分離を維持しながらインフラストラクチャコストを削減できます。各コレクショングループに最小・最大 OCU の両方を設定することで、コールドスタートとキャパシティ保証の課題を解決します。最小 OCU により、コレクションは高速取り込み、突発的なトラフィックスパイク、負荷テストをパフォーマンス低下なく処理するための準備済みコンピューティングリソースを維持します。最大 OCU はコストの予測可能性と支出制御を提供します。最小・最大の二重設定により、コールドスタートの不確実性とコスト超過のリスクの両方を排除するリソース範囲が明確になります。
コレクショングループと最小 OCU 設定の詳細については、Amazon OpenSearch Serverless のドキュメントをご覧ください。
著者について
この記事は Kiro が翻訳を担当し、Solutions Architect の 榎本 貴之 がレビューしました。