Amazon Web Services ブログ
Amazon RDS PostgreSQL レプリケーションのベストプラクティス
Amazon RDS for PostgreSQL では、読み込み負荷を取り除き、災害復旧 (DR) リソースを作成するために、ソース PostgreSQL インスタンスのレプリカを簡単に設定することができます。リードレプリカは、ソースと同じリージョン、または異なるリージョン内に設定できます。
RDS PostgreSQL リードレプリカインスタンスを使用すると、読み込みワークロードをレプリカインスタンスにオフロードすると同時に、書き込みアクティビティのためにソースインスタンスのコンピューティングリソースも確保します。ただし、レプリケーション遅延を避けるには、リードレプリカを正しく設定し、適切なパラメータ値を設定する必要があります。
概要
この記事では、リードレプリカを正しく設定するためのベストプラクティスをいくつかご紹介します。リージョン内、クロスリージョン、および論理レプリケーションなどのさまざまな RDS PostgreSQL レプリケーションオプションの長所と短所を取り上げ、適切なパラメータ値と、監視するメトリクスを推奨します。以下のステップでは、レプリケーション遅延を最小限に抑えながら、DR 戦略、読み込みワークロード、および健全なソースインスタンスを最適化する方法を説明します。
一般的な推奨事項
全体的なベストプラクティスとして、リードレプリカで実行するリードクエリが、ソースインスタンスとしてデータの最新バージョンを使用することを確認してください。データバージョンは、Amazon CloudWatch メトリクスでレプリケーション遅延を調べることによって確認できます。レプリケーション遅延を最小限に抑えることによって、古いデータに基づいたクエリ出力と、インスタンスの健全性に対するリスクの両方を避けることができます。
リージョン内のレプリケーション
RDS PostgreSQL は、ソースインスタンスと同じ AWS リージョン内でリードレプリカを作成するために Postgres ネイティブストリーミングレプリケーションを使用します。ソースインスタンスでのデータの変更は、ストリーミングレプリケーションを使ってリードレプリカにストリームされます。このプロセスが何らかの理由で遅れると、レプリケーション遅延が発生します。以下の図は、RDS PostgreSQL が同じリージョン内のソースとレプリカの間でレプリケーションを実行する方法を示しています。
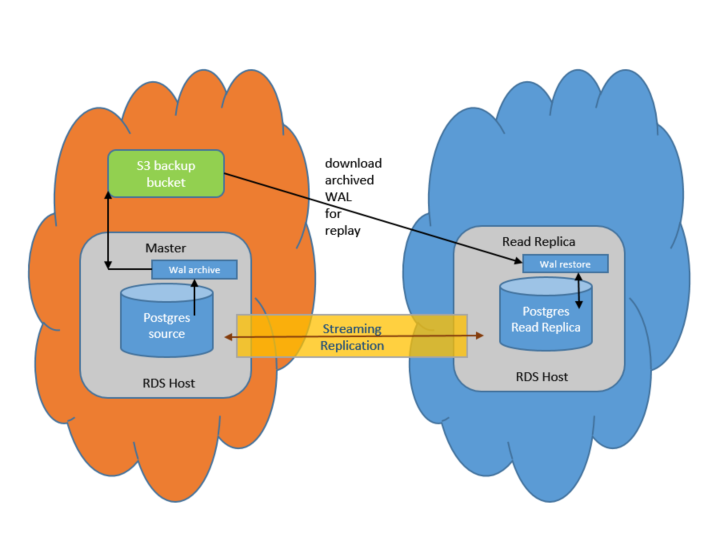
この後のセクションでは、同じリージョン内でホストされている RDS PostgreSQL インスタンスを最適にレプリケートするために Postgres インスタンスを調整する方法について説明します。
適切な wal_keep_segments の値
Postgres では、wal_keep_segments パラメータで pg_wal ディレクトリに保存される WAL ログファイルセグメントの最大数を指定します。Postgres は、このパラメータを超える WAL セグメントを Amazon S3 バケットにアーカイブします。
リードレプリカが pg_wal ロケーションで WAL セグメントを見つけられない場合、リードレプリカは S3 バケットからセグメントをダウンロードし、復元して適用します。一般に、アーカイブからの復元の実行はストリーミングレプリケーションよりも遅いため、インスタンス上に保存する WAL セグメントが多いほど、レプリケーションも速くなります。
ストリーミングレプリケーションの停止後は、データベースログに Streaming replication has stopped というエラーが表示されます。ストリーミングレプリケーションの停止時間が長くなると、データベースログに Streaming replication has been terminated というメッセージが表示されることがあります。
デフォルトで、RDS PostgreSQL は wal_keep_segments を 32 に設定します。このパラメータの値は、RDS パラメータグループを使用して変更できます。このパラメータは動的で、その値を変更してもインスタンスを再起動する必要はありません。
たとえば、以下の Postgres ログファイルメッセージは、RDS がアーカイブされた WAL ファイルを再生することによってリードレプリカを復元していることを示しています。
2018-11-07 21:01:16 UTC::@:[23180]:LOG: restored log file "000000010000001A000000D3“ from archive
RDS がレプリカで十分な数のアーカイブされた WAL ファイルを再生したら、リードレプリカはストリーミングを再開します。この時点で、RDS はログファイルに以下のような行を書き込みます。
2018-11-07 21:41:36 UTC::@:[24714]:LOG: started streaming WAL from primary at 1B/B6000000 on timeline 1
ベストプラクティスとして、pg_wal ディレクトリにおける WAL ログファイルセグメントの最大数を超えないようにしてください。これは、S3 バケットからセグメントを復元するプロセスの減速につながります。この値を調整するには、ソースインスタンスの書き込みアクティビティに戻ります。
新しいレプリカインスタンスを立ち上げる前に、wal_keep_segments の値を変更します。このパラメータの値は、ストリーミングレプリケーションの開始時に WAL ファイルがアーカイブされることを避けるために、十分高く設定してください。たとえば、wal_keep_segments を 500 に設定すると、ソースインスタンスで 500 前後の WAL ファイルを維持できます。
PostgreSQL 10 以下のバージョンでは、各 WAL ファイルのサイズが 16 MB になります。WAL セグメントによって使用される容量は、割り当てられたインスタンスストレージに反映されます。
ソースインスタンスでの過剰な書き込みアクティビティを避ける
ソースインスタンスでは、書き込みアクティビティの一環として、WAL がまずトランザクションを記録してから、これらの変更をストレージブロックに書き込みます。ソースインスタンスでの書き込みアクティビティが多いと、多数の WAL ファイルが急増する可能性があります。WAL ファイルの増加と、リードレプリカでのこれらのファイルの再生は、全体的なレプリケーションパフォーマンスを減速させます。
WAL ファイルの作成率を追跡するには、CloudWatch メトリクスの TransactionLogsGeneration メトリックを確認します。このパラメータは、1 秒ごとに生成されたトランザクションログのサイズを示します。以下の図は、ソースでの高い書き込みアクティビティレベルがどのようにレプリケーション遅延に影響するかを示しています。
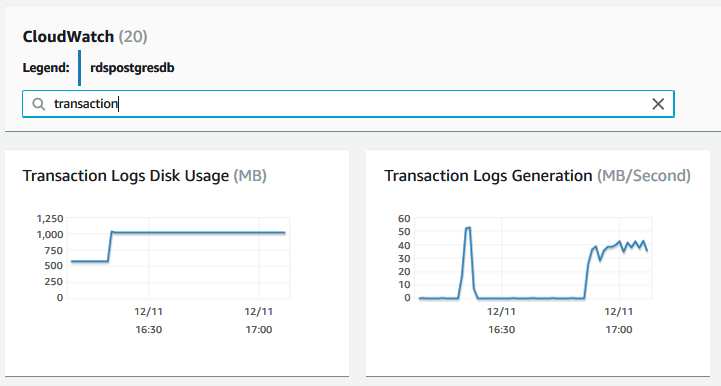
TransactionLogsDiskUsage、TransactionLogsGeneration、WriteIOPS、WriteThroughput、および WriteLatency の各メトリックは、ソースインスタンスが 16:20 および 17:00 に過剰な書き込みの影響を受けていたことを示しています。これは、同時にリードレプリカでのレプリケーション遅延を 11 分に増加させています。
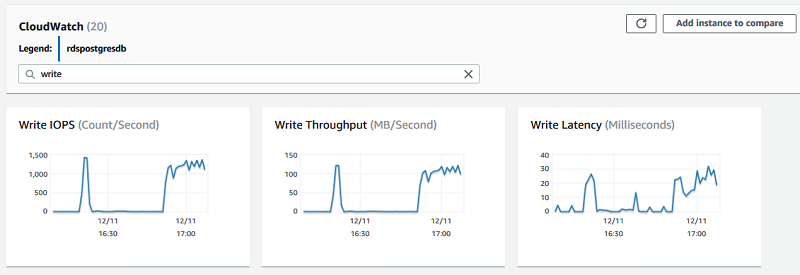

この状況を避けるには、ソースインスタンスでの書き込みアクティビティを制御し、分配します。多数の書き込みアクティビティを一度に行う代わりに、それらを小さなタスクバンドルに分割して、複数のトランザクション全体に均等に分配します。ソースインスタンスでの過剰な書き込みを絶えず警戒するため、Write Latency および Write IOPS などのメトリクスで CloudWatch アラートを使用します。wal_compression を ON に設定して WAL の量を減らし、徐々にレプリケーション遅延を減らします。
ソースインスタンステーブルの排他ロックを避ける
ソースインスタンスでは、DROP TABLE、TRUNCATE、REINDEX、CLUSTER、VACUUM FULL、および REFRESH MATERIALIZED VIEW (CONCURRENTLY なし) などのコマンドを実行するたびに、Postgres が Access Exclusive ロックを処理します。
ACCESS EXCLUSIVE は、最も排他的なロックモードです (他のすべてのロックモードと競合します)。このロックは、ロックの持続期間中、その他すべてのトランザクションからのテーブルへのアクセスを阻止します。一般に、テーブルはトランザクションが終了するまでロックされたままになります。このロックアクティビティは WAL に記録され、リードレプリカによって再生および保持されます。テーブルが ACCESS EXCLUSIVE ロックされている時間が長ければ長いほど、レプリケーション遅延も長くなります。
このような状況を避けるため、AWS では pg_locks および pg_stat_activity カタログテーブルを定期的にクエリして、この状況を監視することをお勧めしています。たとえば、以下のクエリは Postgres 9.6 以降の Postgres インスタンスにおけるロックを監視します。
リードレプリカでのパラメータ設定
レプリカインスタンスでパラメータをいくつか設定することによって、全体的なレプリケーションに影響を与えることもできます。パラメータ hot_standby_feedback は、レプリカインスタンスで現在実行されているクエリについて、レプリカインスタンスがソースインスタンスにフィードバックを送信するかどうかを指定します。
このパラメータを有効にすることで、ソースでの以下のエラーメッセージをキュレートし、関連するテーブルでの VACUUM を延期します (リードレプリカでリードクエリが完了した場合を除く)。
ERROR: canceling statement due to conflict with recovery
Detail: User query might have needed to see row versions that must be removed
この方法では、hot_standby_feedback が有効化されたレプリカインスタンスは長時間実行される SQL に対応できるものの、ソースインスタンスのテーブルを増大させる場合があります。レプリカインスタンスで長時間実行されるクエリを監視しなければ、ソースインスタンスでストレージ不足、およびトランザクション ID 周回などの深刻な問題に直面する可能性があります。
あるいは、レプリカインスタンスで max_standby_archive_delay または max_standby_streaming_delay といったパラメータを有効化して、長時間実行されるリードクエリを完了できるようにすることも可能です。これらのパラメータはどちらも、レプリカでリードクエリが実行されている間にソースデータが変更されると、レプリカでの WAL 再生を一時停止します。-1 の値は、リードクエリが完了するまで WAL 再生を待機させます。ただし、この一時停止は、レプリケーション遅延を無限に増加させ、WAL が蓄積することからストレージの消費率が高くなる原因になります。
これら 3 つのパラメータのいずれかを変更するときは、ソースインスタンスを健全に保ち、レプリケーション遅延を管理可能な範囲に維持するためにも、レプリカインスタンスで長時間実行されるリードクエリに注意してください。
以下の SQL クエリも役に立つかもしれません。このクエリは、5 分を超えて実行されている読み込みトランザクションを中止します。
リードレプリカインスタンス設定
不適切なレプリカインスタンス設定も、レプリケーションパフォーマンスに影響を及ぼします。同じレベル、またはレベルが高いインスタンスクラスとストレージタイプのレプリカをソースインスタンスとして使用してください。レプリカはソースインスタンスと同じ書き込みアクティビティを再生しなくてはならないため、レベルが低いインスタンスクラスのレプリカの使用は、リードレプリカでの高遅延と レプリケーション遅延の増加を引き起こす場合があります。
リードレプリカは、ソースインスタンスの書き込みワークロードと同様のワークロードの他、追加のリードクエリも処理します。リードレプリカは、少なくとも同じレベル、またはそれより高レベルのインスタンスクラスを使用しているほうがよく、ソースとレプリカインスタンスのストレージタイプも一致させるようにします。一致していないストレージ設定は、レプリケーション遅延を増加させます。
クロスリージョンのレプリケーション
RDS PostgreSQL は、クロスリージョンレプリケーションもサポートします。クロスリージョンリードレプリカは、リードクエリのスケーリングに加えて、災害復旧と AWS リージョン間におけるデータベース移行に対するソリューションも提供します。
クロスリージョンレプリケーションは、wal_keep_segments に基づいて WAL を保持する代わりに、ソースインスタンスの物理的なレプリケーションスロットを使用します。CloudWatch メトリック OldestReplicationSlotLag は、MB 単位の WAL サイズでのレプリケーション遅延を示します。メトリック TransactionLogsDiskUsage は、WAL ファイルによって使用されたストレージサイズを示します。レプリケーションスロットは WAL を保持するため、クロスリージョンレプリケーション遅延がソースインスタンスでの WAL の蓄積の原因となり、最終的にはストレージ不足などの深刻な問題を引き起こします。
ベストプラクティスとして、ソースインスタンスでの IOPS パフォーマンスも監視するようにしてください。つまり、ソースインスタンスの IOPS が不足すると、長い読み込み遅延が WAL ファイルの読み込みを遅らせ、クロスリージョンレプリケーション遅延が増加する原因になります。クロスリージョンレプリケーションでは地理的な距離が長くなることから、WAL の保持によるソースインスタンスでのストレージの大量消費を避けるためにクロスリージョンレプリケーション遅延を注意深く監視することをお勧めします。
論理レプリケーション
Postgres バージョン 9.4 以降では、RDS PostgreSQL インスタンスで論理レプリケーションスロットをセットアップして、データベースの変更をストリームすることができます。AWS Database Migration Service (AWS DMS) は、論理レプリケーションの最も一般的なユースケースを提供します。
論理レプリケーションは、レプリケーション先を無視する論理スロットを使用します。レプリケーションが一時停止される、または WAL が消費されないと、ソースインスタンスストレージはすぐに満杯になります。この状況を避けるには、以下の設定を確認するようにしてください。
- パラメータ
rds.logical_replicationを設定する: このパラメータが DMS ソースとしての RDS PostgreSQL インスタンスの使用を有効化する場合は、DMS タスクを監視します。DMS タスクが一時停止もしくはドロップされる場合、または change-data-capture が有効化されていない場合は、このパラメータを無効にしてください。 - レプリケーションスロットを監視する: 上記のパラメータを有効化する場合、消費されていない WAL ファイルがソースで蓄積され続けます。ベストプラクティスとして、レプリケーションスロットを注意深く監視し、アクティブではないものを停止してください。以下は、それを行うために重要なスロットメンテナンスクエリの一部です。
- a.非アクティブなレプリケーションスロットを見つける:
SELECT slot_name FROM pg_replication_slots WHERE active='f'; - b.非アクティブなレプリケーションスロットをドロップする:
SELECT pg_drop_replication_slot('slot_name'); - c.上記 2 つのコマンドを以下のように組み合わせる:
SELECT pg_drop_replication_slot('slot_name') from pg_replication_slots where active = 'f';
- a.非アクティブなレプリケーションスロットを見つける:
バージョン 10.4 からは、RDS PostgreSQL がパブリケーションおよびサブスクリプションモデルに基づいたネイティブ論理レプリケーションをサポートします。すべてのデータベースと共にインスタンス全体をレプリケートする従来の物理レプリケーションとは異なり、論理レプリケーションはテーブルまたはデータベースレベルの変更などのサブセットのレプリケーションを可能にするため、Postgres の異なるメジャーバージョンをレプリケート、または複数のデータベースを 1 つに統合することができます。
論理レプリケーションには特定の制限があることに留意してください。以下に関する問題が生じる可能性があります。
- スキーマの変更: ベストプラクティスとして、スキーマの変更は、サブスクライバーがコミットした後で、パブリッシャーがコミットするようにします。
- シーケンスデータ: 論理レプリケーションは、シリアル列または ID 列のシーケンスデータをレプリケートしますが、サブスクライバーデータベースへの切り替えまたはフェイルオーバーが行われた場合は、シーケンスを最新の値に更新する必要があります。
- ラージオブジェクトの切り捨て: TRUNCATE の回避策には DELETE が可能です。意図しない TRUNCATE 操作を避けるため、テーブルから TRUNCATE 権限を取り消すことができます。
- パーティションテーブル: 論理レプリケーションは、パーティションテーブルを通常のテーブルとして扱います。パーティション化されたテーブルは、1 対 1 でレプリケートしてください。
- 外部テーブル: 論理レプリケーションは外部テーブルをレプリケートしません。
まとめ
この記事では、リードレプリカを設定する上でのベストプラクティスを推奨しました。リージョン内、クロスリージョン、および論理レプリケーション操作を含めたさまざまな RDS PostgreSQL レプリケーションオプションの長所と短所も説明しました。
RDS はレプリケーションの設定と管理を円滑化しますが、この記事で説明したベストプラクティスは、レプリケーション遅延を最小限に抑えるためにも、依然として重要です。これらのベストプラクティスは、DR 戦略、読み込みワークロード、および健全なソースインスタンスの最適化にも役立ちます。RDS Postgres リードレプリカの制限事項、モニタリング、およびトラブルシューティングの詳細については、「PostgreSQL リードレプリカの使用」を参照してください。
いつものように、AWS では皆さんのフィードバックをお待ちしています。コメントまたはご質問については、以下から送信してください。
著者について
 Vivek Singh は、RDS/Aurora PostgreSQL エンジンを専門とする AWS のデータベーススペシャリストテクニカルアカウントマネージャーです。Vivek はエンタープライズカスタマーと連携して、PostgreSQL の運用パフォーマンスに関する技術的なサポートを提供し、データベースのベストプラクティスを提供しています。
Vivek Singh は、RDS/Aurora PostgreSQL エンジンを専門とする AWS のデータベーススペシャリストテクニカルアカウントマネージャーです。Vivek はエンタープライズカスタマーと連携して、PostgreSQL の運用パフォーマンスに関する技術的なサポートを提供し、データベースのベストプラクティスを提供しています。