Amazon Web Services ブログ
Apache Kafka クラスターの適切なサイジングによるパフォーマンスとコストの最適化のベストプラクティス
本記事は 2022 年 3 月 17 日 に公開された「Best practices for right-sizing your Apache Kafka clusters to optimize performance and cost」を翻訳したものです。
2025 年 11 月: この記事は正確性を確認し、更新されました。
Apache Kafka は、さまざまなユースケースに最適化するためのパフォーマンスとチューニング性で広く知られています。しかし、インフラストラクチャコストを最小限に抑えながら、特定のパフォーマンス要件を満たす適切なインフラストラクチャ構成を見つけることは、時として困難な場合があります。
この記事では、基盤となるインフラストラクチャが Apache Kafka のパフォーマンスにどのように影響するかを説明します。スループット、可用性、レイテンシーの要件を満たすためのクラスターのサイジング戦略について説明します。その過程で、「スケールアップとスケールアウトのどちらが適切か」といった疑問にも答えます。最後に、本番クラスターのサイズを継続的に検証する方法についてのガイダンスを提供します。
クラスターのサイジングに関するさまざまな戦略の効果とトレードオフを説明するために、パフォーマンステストを使用します。ただし、通常どおり、インターネット上で見つけたベンチマークを盲目的に信頼しないことが重要です。そのため、結果を再現する方法を示すだけでなく、特定のワークロード特性に対して独自のテストを実行するためのパフォーマンステストフレームワークの使用方法も説明します。
ほとんどのユースケースでは、予測可能なスループットと運用の複雑さの軽減を備えたフルマネージドストレージレイヤーを特徴とする Amazon MSK Express ブローカーから始めることをお勧めします。Express ブローカーは、ストレージとネットワークスループットに関するキャパシティプランニングの必要性を排除し、Kafka の使用開始やアーキテクチャの簡素化に最適です。ただし、ワークロードで Tiered Storage などのストレージ管理方法の手動制御や、特定のレプリケーションクォータなどが必要な場合は、Express ブローカーと Standard ブローカーの選択に関するガイダンスについて How to choose the right Amazon MSK cluster type for you を参照し、Standard ブローカーのサイジングにはこの記事のパフォーマンスベンチマークを使用してください。Express ブローカーのスループット仕様の詳細については、AWS ドキュメントを参照してください。
Apache Kafka クラスターのサイジング
インフラストラクチャの観点から、クラスターの最も一般的なリソースボトルネックは、ネットワークスループット、ストレージスループット、および Amazon Elastic Block Store (Amazon EBS) などのネットワーク接続ストレージを使用するブローカーのストレージバックエンド間のネットワークスループットです。
この記事の残りの部分では、クラスターの持続スループット制限が、ストレージとネットワークスループット制限だけでなく、ブローカー数、コンシューマーグループ数、およびレプリケーションファクター r にも依存することを説明します。特定のクラスターのインフラストラクチャ特性に基づいて、理論上の持続スループット制限 tcluster の以下の式 (この記事全体で式 1 と呼びます) を導出します:
本番クラスターでは、実際のスループットを理論上の持続スループット制限の 80% を目標とすることがベストプラクティスです。例えば、m7g.12xlarge ブローカーを持つ 3 ノードクラスター、レプリケーションファクター 3、ベースラインスループット 1000 MB/秒の EBS ボリューム、およびトピックの先端から消費する 2 つのコンシューマーグループを考えてみましょう。これらすべてのパラメータを考慮すると、クラスターが吸収する持続スループットは 1,000 MB/秒を目標とする必要があります。
ただし、このスループット計算は、高スループットシナリオに最適化されたワークロードの上限を提供しているにすぎません。トピックの構成方法やこれらのトピックへの読み書きを行うクライアントの構成方法に関係なく、クラスターはこれ以上のスループットを吸収できません。レイテンシーに敏感なワークロードや計算集約型のワークロードなど、異なる特性を持つワークロードの場合、これらの追加要件を満たしながらクラスターが吸収できる実際のスループットは、多くの場合より小さくなります。
ワークロードに適した構成を見つけるには、ユースケースから逆算して、適切なスループット、可用性、耐久性、およびレイテンシーの要件を決定する必要があります。次に、式 1 を使用して、スループット、耐久性、およびストレージ要件に基づいてクラスターの初期サイジングを取得します。パフォーマンステストを実行してこの初期クラスターサイジングを検証し、クラスターサイズ、クラスター構成、およびクライアント構成を微調整して他の要件を満たします。最後に、メンテナンス、スケーリング、またはブローカーの損失時など、クラスターが縮小された容量で実行されている場合でも、予想されるスループットを取り込めるように、本番クラスターに追加の容量を追加します。ワークロードによっては、アベイラビリティーゾーン全体のすべてのブローカーに影響するイベントに耐えられるだけの予備容量を追加することも検討できます。
この記事の残りの部分では、クラスターサイジングの側面についてより深く掘り下げます。最も重要な側面は以下のとおりです:
- クラスターのスループットとパフォーマンスを向上させるために、スケールアウトまたはスケールアップのいずれかを選択できることがよくあります。小さなブローカーは、より小さな容量増分を提供し、利用できなくなった場合の影響範囲が小さくなります。ただし、多くの小さなブローカーを持つと、ブローカーへのローリングアップデートを必要とする操作の完了に時間がかかり、障害の可能性が高くなります。
- プロデューサーがクラスターに送信するすべてのトラフィックはディスクに永続化されます。そのため、ストレージボリュームの基盤となるスループットがクラスターのボトルネックになる可能性があります。この場合、可能であればボリュームスループットを増やすか、クラスターにボリュームを追加することが理にかなっています。
- EBS ボリュームに永続化されるすべてのデータはネットワークを経由します。Amazon EBS 最適化インスタンスには Amazon EBS I/O 専用の容量がありますが、専用の Amazon EBS ネットワークがクラスターのボトルネックになる可能性があります。この場合、より大きなブローカーはより高い Amazon EBS ネットワークスループットを持つため、ブローカーをスケールアップすることが理にかなっています。
- クラスターから読み取るコンシューマーグループが多いほど、ブローカーの Amazon Elastic Compute Cloud (Amazon EC2) ネットワーク経由で送出されるデータが多くなります。ブローカーのタイプとサイズによっては、Amazon EC2 ネットワークがクラスターのボトルネックになる可能性があります。その場合、より大きなブローカーはより高い Amazon EC2 ネットワークスループットを持つため、ブローカーをスケールアップすることが理にかなっています。
- p99 put レイテンシーについては、クラスター内暗号化を有効にすると大きなパフォーマンスへの影響があります。クラスターのブローカーをスケールアップすると、小さなブローカーと比較して p99 put レイテンシーを大幅に削減できます。
- コンシューマーが遅れたり、履歴データを再処理する必要がある場合、要求されたデータがメモリに存在しなくなり、ブローカーはストレージボリュームからデータをフェッチする必要があります。これにより、非シーケンシャル I/O 読み取りが発生します。追加のネットワークトラフィックが使用されます: 1/ Tiered Storage を使用する場合は EC2 で、2/ EBS を使用する場合はボリュームで。より多くのメモリを持つ大きなブローカーを使用するか、圧縮を有効にすることで、この影響を軽減できます。
- クラスターのバースト機能を使用することは、完了に時間がかかるクラスターのスケーリングなしで、突然のスループットスパイクを吸収する非常に強力な方法です。バースト容量は、運用イベントへの対応にも役立ちます。例えば、ブローカーがメンテナンス中であったり、パーティションをクラスター内で再バランスする必要がある場合、バーストパフォーマンスを使用して操作をより速く完了できます。
BytesInPerSec、ReplicationBytesInPerSec、BytesOutPerSec、ReplicationBytesOutPerSecなどの重要なインフラストラクチャ関連のクラスターメトリクスを監視またはアラームを設定して、現在のクラスターサイズが現在のクラスターサイズに最適でなくなったときに通知を受け取ります。
この記事の残りの部分では、これらの推奨事項の背景にある追加のコンテキストと理由を説明します。
Apache Kafka のパフォーマンスボトルネックを理解する
インフラストラクチャの観点からパフォーマンスボトルネックについて話し始める前に、クラスター内でデータがどのように流れるかを再確認しましょう。
この記事では、明示的に異なる記述がない限り、プロデューサーとコンシューマーがベストプラクティスに従って適切に動作していると仮定します。例えば、プロデューサーがブローカー間で負荷を均等に分散し、ブローカーが同じ数のパーティションをホストし、スループットを取り込むのに十分なパーティションがあり、コンシューマーがストリームの先端から直接消費するなどを仮定します。ブローカーは同じ負荷を受け、同じ作業を行っています。そのため、以下のクラスター内のデータフロー図では、Broker 1 のみに焦点を当てます。
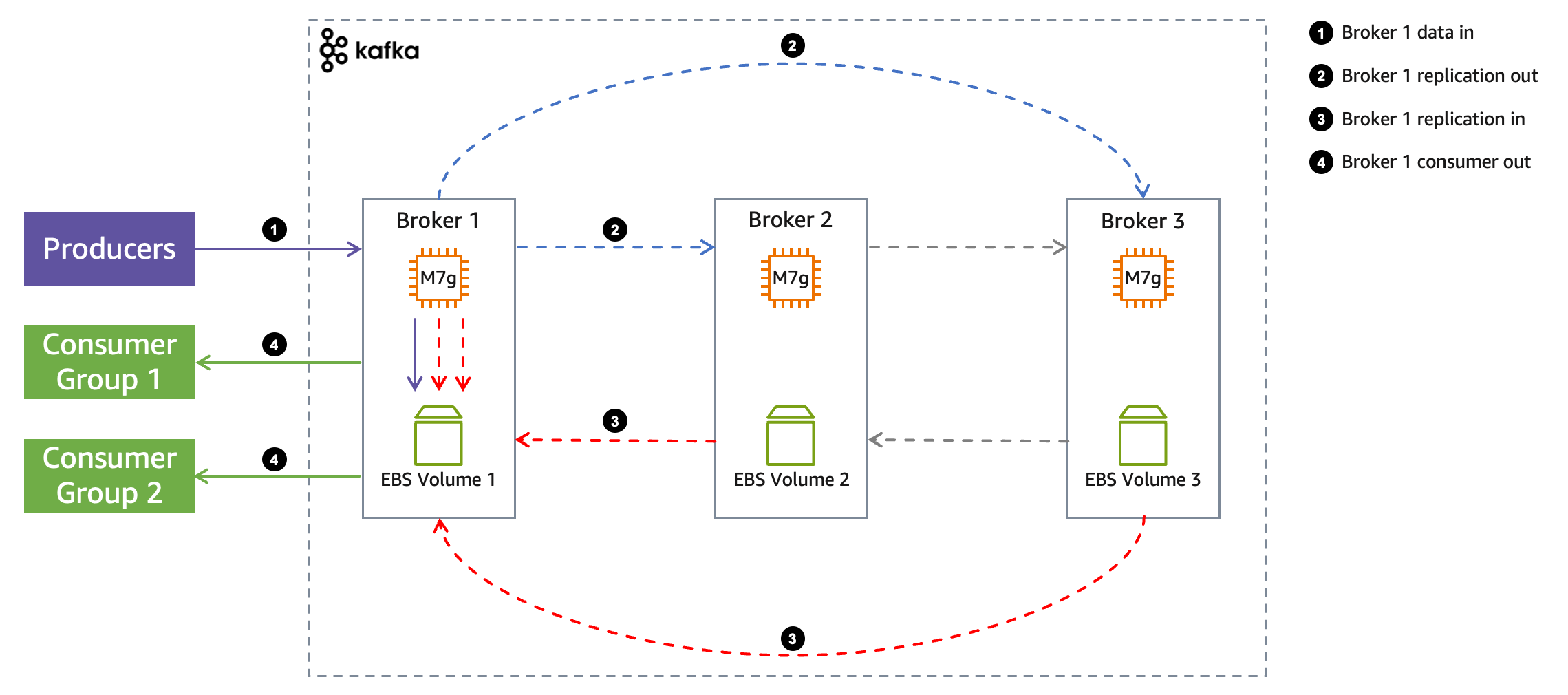
プロデューサーは、tcluster の集約スループットをクラスターに送信します。トラフィックがブローカー間で均等に分散されるため、Broker 1 は tcluster/3 の受信スループットを受け取ります。レプリケーションファクターが 3 の場合、Broker 1 は直接受信したトラフィックを他の 2 つのブローカーにレプリケートします (青い線)。同様に、Broker 1 は 2 つのブローカーからレプリケーショントラフィックを受信します (赤い線)。各コンシューマーグループは、Broker 1 に直接生成されたトラフィックを消費します (緑の線)。プロデューサーからと他のブローカーからのレプリケーショントラフィックとして Broker 1 に到着するすべてのトラフィックは、最終的にブローカーに接続されたストレージボリュームに永続化されます。
したがって、ストレージボリュームのスループットとブローカーネットワークは両方とも全体的なクラスタースループットと密接に結合しており、より詳しく見る価値があります。
ストレージバックエンドのスループット特性
Apache Kafka は、ディスクへのデータ書き込み時に大きなシーケンシャル I/O 操作を利用するように設計されています。プロデューサーは常にログの先端にデータを追加するだけで、シーケンシャル書き込みを引き起こします。さらに、Apache Kafka は同期的にディスクにフラッシュしません。代わりに、Apache Kafka はページキャッシュに書き込み、ページをディスクにフラッシュするのはオペレーティングシステムに任せます。これにより、大きなシーケンシャル I/O 操作が発生し、ディスクスループットが最適化されます。
多くの実用的な目的では、ブローカーはボリュームの完全なスループットを駆動でき、IOPS によって制限されません。コンシューマーがトピックの先端から読み取っていると仮定します。これは、EBS ボリュームのパフォーマンスがスループットに制約され、I/O に制約されず、読み取りがページキャッシュから提供されることを意味します。
ストレージバックエンドの受信スループットは、プロデューサーがブローカーに直接送信するデータと、ブローカーがピアから受信するレプリケーショントラフィックに依存します。クラスターに生成される集約スループット tcluster とレプリケーションファクター r の場合、ブローカーストレージが受信するスループットは以下のとおりです:
したがって、クラスター全体の持続スループット制限は以下によって制約されます:
AWS は、ブロックストレージのさまざまなオプションを提供しています: インスタンスストレージと Amazon EBS です。インスタンスストレージはホストコンピュータに物理的に接続されたディスク上にありますが、Amazon EBS はネットワーク接続ストレージです。
インスタンスストレージを備えたインスタンスファミリーは、高い IOPS とディスクスループットを実現します。例えば、Amazon EC2 I3 インスタンスには、低レイテンシー、非常に高いランダム I/O パフォーマンス、および高いシーケンシャル読み取りスループットに最適化された NVMe SSD ベースのインスタンスストレージが含まれています。ただし、ボリュームはブローカーに紐付けられています。その特性、特にサイズはインスタンスファミリーにのみ依存し、ボリュームサイズは適応できません。さらに、ブローカーが障害を起こして交換が必要な場合、ストレージボリュームは失われます。交換ブローカーは他のブローカーからデータをレプリケートする必要があります。このレプリケーションは、ブローカー損失による容量低下に加えて、クラスターに追加の負荷を引き起こします。
対照的に、EBS ボリュームの特性は使用中に適応できます。これらの機能を使用して、ピーク用にストレージをプロビジョニングしたり、追加のブローカーを追加したりするのではなく、時間の経過とともにブローカーストレージを自動的にスケーリングできます。gp3、io2、st1 などの一部の EBS ボリュームタイプでは、既存のボリュームのスループットと IOPS 特性を適応させることもできます。さらに、EBS ボリュームのライフサイクルはブローカーから独立しています。ブローカーが障害を起こして交換が必要な場合、EBS ボリュームを交換ブローカーに再アタッチできます。これにより、そうでなければ必要となるレプリケーショントラフィックのほとんどを回避できます。
したがって、EBS ボリュームの使用は、多くの一般的な Apache Kafka ワークロードにとって良い選択であることが多いです。より柔軟性があり、より高速なスケーリングとリカバリ操作を可能にします。
MSK は、事実上無制限のストレージにスケーリングする低コストのストレージ層である Tiered Storage もサポートしています。アプリケーションが Tiered Storage からデータの読み取りを開始すると、最初の数バイトの読み取りレイテンシーが増加することが予想されます。低コスト層から残りのデータをシーケンシャルに読み取り始めると、プライマリストレージ層と同様のレイテンシーが期待できます。書き込みに関してはレイテンシーの違いはありません。
Amazon EBS スループット特性
Amazon EBS をストレージバックエンドとして使用する場合、選択できるボリュームタイプがいくつかあります。さまざまなボリュームタイプのスループット特性は、250 MB/秒から 4000 MB/秒の範囲です (詳細については、Amazon EBS ボリュームタイプを参照してください)。単一のボリュームで提供できるスループットを超えてスループットを増やすために、ブローカーに複数のボリュームをアタッチすることもできます。
ただし、Amazon EBS はネットワーク接続ストレージです。ブローカーが EBS ボリュームに書き込むすべてのデータは、Amazon EBS バックエンドへのネットワークを経由する必要があります。M7g ファミリーなどの新世代のインスタンスファミリーは、Amazon EBS I/O 専用の容量を持つ Amazon EBS 最適化インスタンスです。ただし、ボリュームサイズだけでなく、インスタンスのサイズに依存するスループットと IOPS に制限があります。Amazon EBS 専用容量は、より大きなインスタンスに対してより高いベースラインスループットと IOPS を提供します。容量は 78.75 MB/秒から 2,500 MB/秒の範囲です。詳細については、サポートされているインスタンスタイプを参照してください。
ストレージに Amazon EBS を使用する場合、クラスターの持続スループット制限の式を適応させて、より厳密な上限を取得できます:
Amazon EC2 ネットワークスループット
これまで、EBS ボリュームへのネットワークトラフィックのみを考慮してきました。しかし、レプリケーションとコンシューマーグループも、ブローカーからの Amazon EC2 ネットワークトラフィックを引き起こします。プロデューサーがブローカーに送信するトラフィックは、r-1 個のブローカーにレプリケートされます。さらに、すべてのコンシューマーグループは、ブローカーが取り込むトラフィックを読み取ります。したがって、全体的な送信ネットワークトラフィックは以下のとおりです:
このトラフィックを考慮すると、最終的に式 1 で既に見たクラスターの持続スループット制限の妥当な上限が得られます:
本番ワークロードでは、ワークロードの実際のスループットを、この式で決定される理論上の持続スループット制限の 80% 未満に保つことをお勧めします。さらに、プロデューサーがクラスターに送信するすべてのデータは、最終的に少なくとも 1 つのコンシューマーグループによって読み取られると仮定します。コンシューマー数が 1 以上の場合、ブローカーからの Amazon EC2 ネットワークトラフィックは常にブローカーへのトラフィックよりも高くなります。したがって、潜在的なボトルネックとしてブローカーへのデータトラフィックを無視できます。
式 1 を使用すると、特定のインフラストラクチャを持つクラスターが、理想的な条件下でワークロードに必要なスループットを吸収できるかどうかを検証できます。m7g.8xlarge 以上のインスタンスの Amazon EC2 ネットワーク帯域幅の詳細については、Amazon EC2 インスタンスタイプを参照してください。同じページで m7g.4xlarge インスタンスの Amazon EBS 帯域幅も確認できます。小さいインスタンスは、Amazon EC2 ネットワーク帯域幅と Amazon EBS 帯域幅にクレジットベースのシステムを使用します。Amazon EC2 ネットワークベースライン帯域幅については、ネットワークパフォーマンスを参照してください。Amazon EBS ベースライン帯域幅については、サポートされているインスタンスタイプを参照してください。
パフォーマンスとコストを最適化するためのクラスターの適切なサイジング
では、これから何を学べるでしょうか?最も重要なのは、これらの結果は理想的な条件下でのクラスターの持続スループット制限のみを示していることを念頭に置くことです。これらの結果は、クラスターの予想される持続スループット制限の一般的な数値を提供できます。ただし、特定のワークロードと構成についてこれらの結果を検証するには、独自の実験を実行する必要があります。
ただし、このスループット推定からいくつかの結論を導き出すことができます: ブローカーを追加すると、クラスターの持続スループットが増加します。同様に、レプリケーションファクターを減らすと、クラスターの持続スループットが増加します。Amazon EC2 ネットワークがボトルネックになると、複数のコンシューマーグループを追加すると、クラスターの持続スループットが減少する可能性があります。
プロデューサーの put レイテンシーも考慮した実用的な持続クラスタースループットに関する経験的データを取得するために、いくつかの実験を実行してみましょう。これらのテストでは、スループットをクラスターの持続スループット制限の推奨される 80% 以内に保ちます。独自のテストを実行すると、クラスターが示すよりも高いスループットを提供できることに気付くかもしれません。
Amazon MSK クラスターのスループットと put レイテンシーの測定
実験用のインフラストラクチャを作成するために、Standard ブローカーを備えた Amazon Managed Streaming for Apache Kafka (Amazon MSK) を使用します。Amazon MSK は、Amazon EBS ストレージによってバックアップされた高可用性 Apache Kafka クラスターをプロビジョニングおよび管理します。したがって、以下の説明は、EBS ボリュームによってバックアップされている場合、Amazon MSK を通じてプロビジョニングされていないクラスターにも適用されます。
実験は、Apache Kafka ディストリビューションに含まれている kafka-producer-perf-test.sh および kafka-consumer-perf-test.sh ツールに基づいています。テストでは、6 つのプロデューサーと、それぞれ 6 つのコンシューマーを持つ 2 つのコンシューマーグループを使用し、クラスターから同時に読み書きします。前述のとおり、クライアントとブローカーがベストプラクティスに従って適切に動作していることを確認します: プロデューサーがブローカー間で負荷を均等に分散し、ブローカーが同じ数のパーティションをホストし、コンシューマーがストリームの先端から直接消費し、プロデューサーとコンシューマーが測定のボトルネックにならないようにオーバープロビジョニングされているなどです。
ブローカーが 3 つのアベイラビリティーゾーンにデプロイされたクラスターを使用します。さらに、レプリケーションは 3 に設定され、acks は all に設定されて、クラスターに永続化されるデータの高い耐久性を実現します。また、256 kB または 512 kB の batch.size を構成し、linger.ms を 5 ミリ秒に設定しました。これにより、小さなバッチのレコードを取り込むオーバーヘッドが削減され、スループットが最適化されます。パーティション数は、ブローカーサイズとクラスタースループットに合わせて調整されます。
m7g.2xlarge より大きいブローカーの構成は、Amazon MSK デベロッパーガイドのガイダンスに従って適応されています。特にプロビジョンドスループットを使用する場合、それに応じてクラスター構成を最適化することが不可欠です。
以下の図は、異なるブローカーサイズを持つ 3 つのクラスターの put レイテンシーを比較しています。各クラスターについて、プロデューサーは異なるスループット構成で約 12 個の個別のパフォーマンステストを実行しています。最初に、プロデューサーは 18 MB/秒の合計スループットをクラスターに生成し、個別のテストごとにスループットを徐々に増加させます。各個別テストは 1 時間実行され、この期間はテスト仕様の duration_sec パラメータで構成可能です。これらのテストは、Amazon MSK クラスター作成直後にクレジット枯渇なしで実行されました。EC2 ネットワーキング、EBS、および EBS ネットワーキングのバーストクレジットを蓄積したクラスターの場合、フレームワークドキュメントの Advanced Configuration Options に従ってクレジット枯渇を構成し、ベースラインパフォーマンス測定を確保できます。
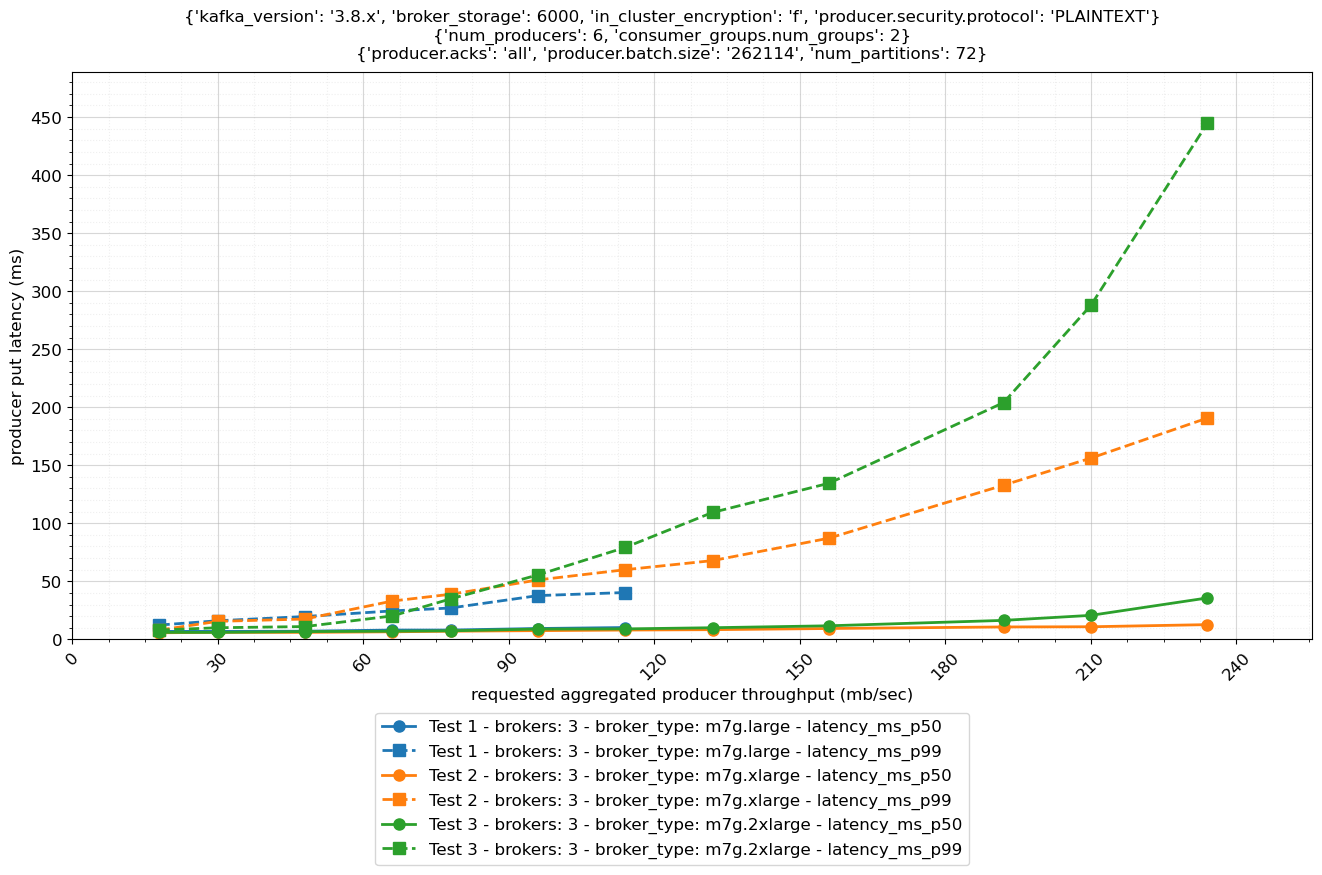
334 GB を超えるストレージを持つブローカーの場合、EBS ボリュームのベースラインスループットは 250 MB/秒と仮定できます。Amazon EBS ネットワークベースラインスループットは、異なるブローカーサイズに対して 78.75、156.25、312.50、および 625.00 MB/秒です (詳細については、サポートされているインスタンスタイプを参照してください)。Amazon EC2 ネットワークベースラインスループットは 119.9、240.1、480、および 960 MB/秒です (詳細については、ネットワークパフォーマンスを参照してください)。これは持続スループットのみを考慮していることに注意してください。バーストパフォーマンスについては後のセクションで説明します。
レプリケーション 3 と 2 つのコンシューマーグループを持つ 3 ノードクラスターの場合、式 1 による推奨受信スループット制限は以下のとおりです。
| ブローカーサイズ | 推奨持続スループット制限 |
| m7g.large | 63 MB/秒 |
| m7g.xlarge | 125 MB/秒 |
| m7g.2xlarge | 200 MB/秒 |
| m7g.4xlarge | 200 MB/秒 |
m7g.4xlarge ブローカーは m7g.2xlarge ブローカーと比較して vCPU とメモリが 2 倍ありますが、クラスターの持続スループット制限はまったく同じです。これは、この構成では、ブローカーが使用する EBS ボリュームがボトルネックになるためです。これらのボリュームのベースラインスループットは 250 MB/秒と仮定していることを思い出してください。3 ノードクラスターとレプリケーションファクター 3 の場合、各ブローカーはクラスターに送信されるのと同じトラフィックを EBS ボリュームに書き込む必要があります。そして、EBS ボリュームのベースラインスループットの 80% は 200 MB/秒であるため、m7g.4xlarge または m7g.2xlarge ブローカーを持つクラスターの推奨持続スループット制限は 200 MB/秒です。
次のセクションでは、プロビジョンドスループットを使用して EBS ボリュームのベースラインスループットを増加させ、クラスター全体の持続スループット制限を増加させる方法について説明します。
プロビジョンドスループットによるブローカースループットの増加
前の結果から、純粋なスループットの観点からは、デフォルトのクラスター構成でブローカーサイズを m7g.2xlarge から m7g.4xlarge に増やすメリットはほとんどないことがわかります。ブローカーが使用する EBS ボリュームのベースラインスループットがスループットを制限しています。ただし、Amazon MSK は最大 1,000 MB/秒のプロビジョンドストレージスループットをサポートしています。セルフマネージドクラスターの場合、gp3、io2、または st1 ボリュームタイプを使用して同様の効果を達成できます。ブローカーサイズによっては、これによりクラスター全体のスループットが大幅に増加する可能性があります。
以下の図は、異なるブローカーサイズと異なるプロビジョンドスループット構成のクラスタースループットと put レイテンシーを比較しています。
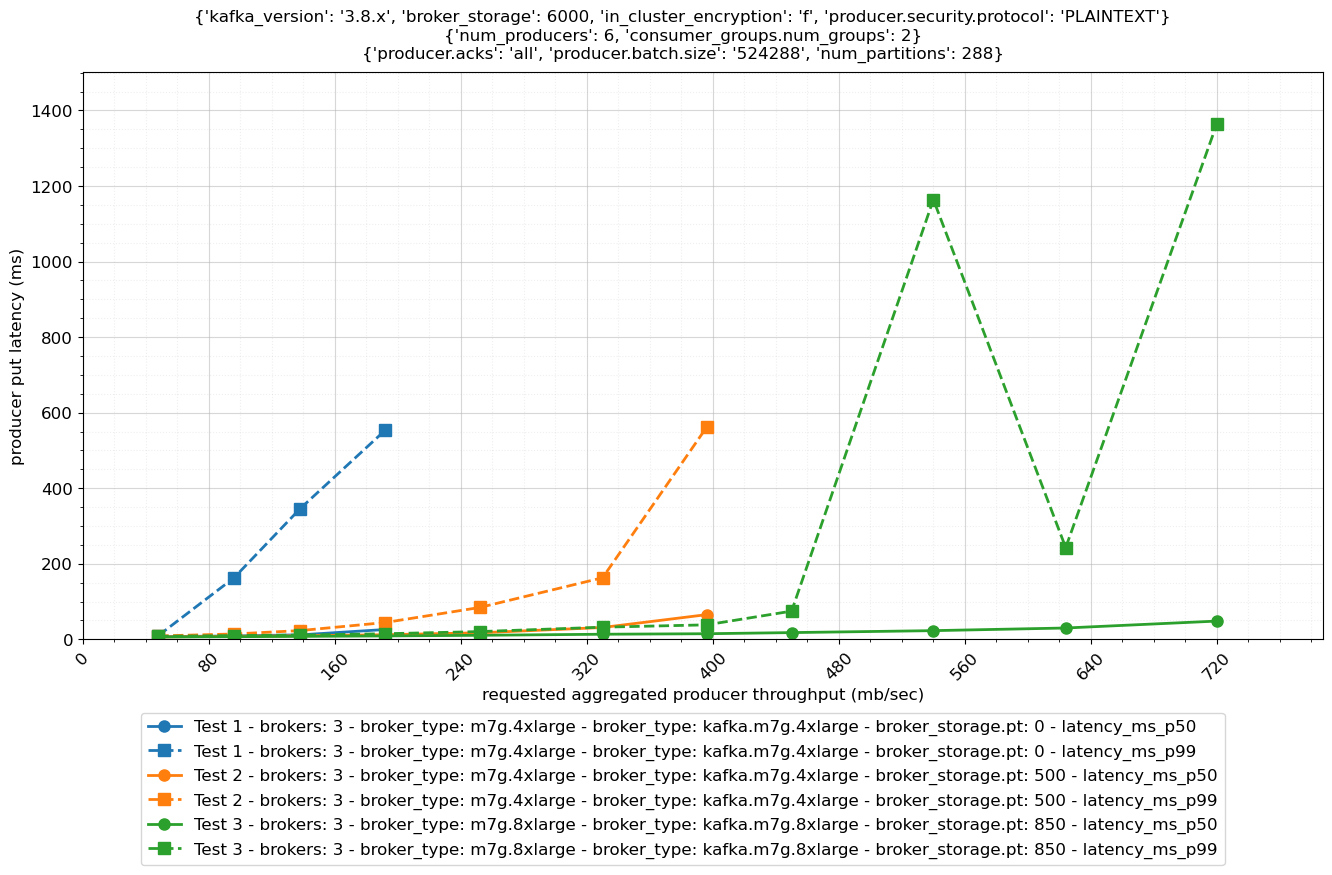
レプリケーション 3 と 2 つのコンシューマーグループを持つ 3 ノードクラスターの場合、式 1 による推奨受信スループット制限は以下のとおりです。
| ブローカーサイズ | プロビジョンドスループット構成 | 推奨持続スループット制限 |
| m7g.4xlarge | – | 200 MB/秒 |
| m7g.4xlarge | 500 MB/秒 | 400 MB/秒 |
| m7g.8xlarge | 850 MB/秒 | 680 MB/秒 |
| m7g.12xlarge | 1000 MB/秒 | 800 MB/秒 |
| m7g.16xlarge | 1000 MB/秒 | 800 MB/秒 |
プロビジョンドスループット構成は、特定のワークロードに対して慎重に選択されました。クラスターから消費する 2 つのコンシューマーグループがある場合、m7g.4xlarge ブローカーのプロビジョンドスループットを 625 MB/秒を超えて増やす意味はありません。EBS ネットワーク (EBS ボリュームスループットではなく) が、クラスターの推奨持続スループット制限を 500 MB/秒に制限しています。ただし、コンシューマー数が異なるワークロードの場合、Amazon EC2 ネットワークのベースラインスループットに合わせてプロビジョンドスループット構成をさらに増減することが理にかなう場合があります。
スケールアウトによるクラスター書き込みスループットの増加
クラスターをスケールアウトすると、当然クラスタースループットが増加します。しかし、これはパフォーマンスとコストにどのように影響するでしょうか?以下の図に示すように、2 つの異なるクラスターを比較してみましょう: 3 ノードの m7g.4xlarge と 6 ノードの m7g.2xlarge クラスターです。m7g.4xlarge クラスターのストレージサイズは、両方のクラスターが同じ合計ストレージ容量を持つように調整されているため、これらのクラスターのコストは同じです。
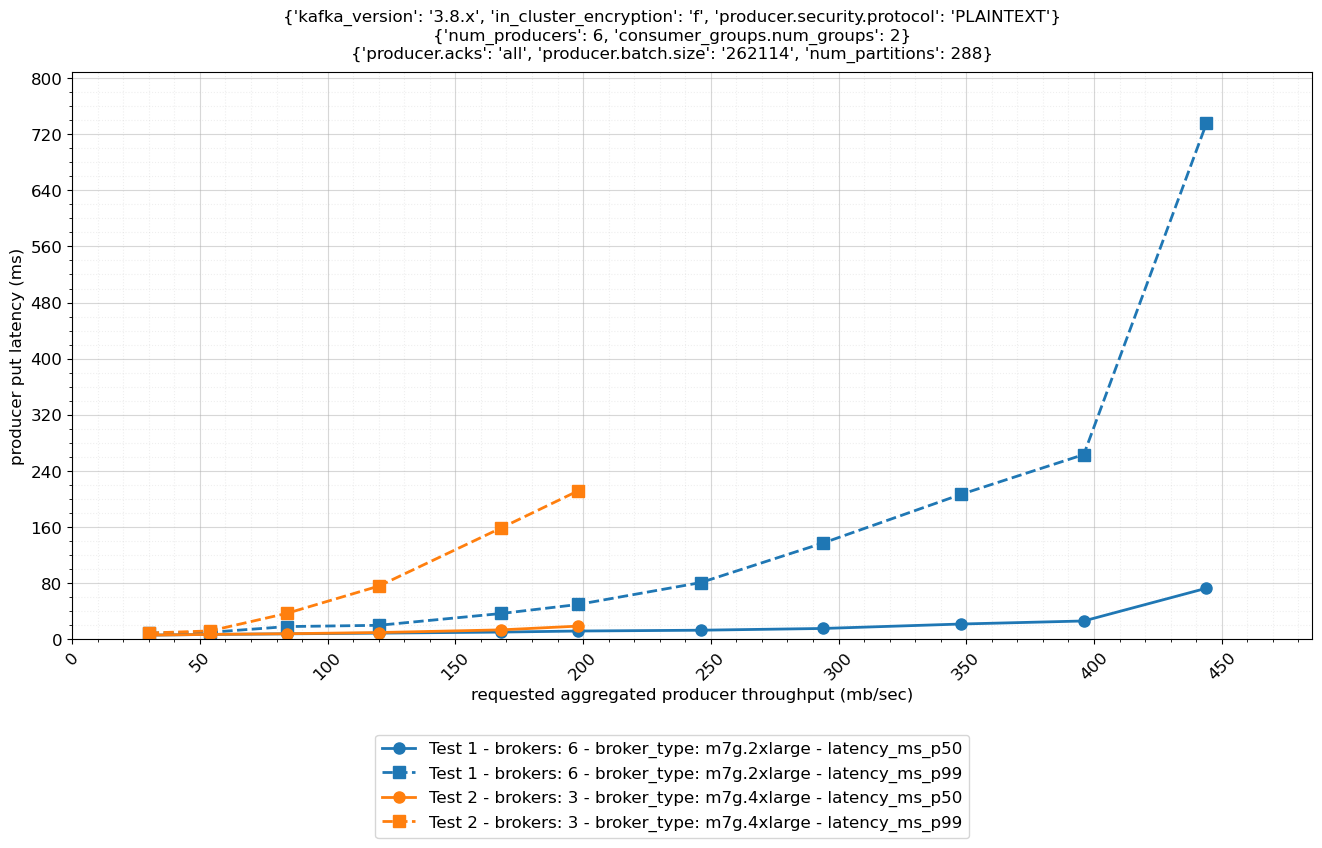
6 ノードクラスターは 3 ノードクラスターの 2 倍のスループットを持ち、p99 put レイテンシーが大幅に低くなっています。クラスターの受信スループットだけを見ると、200 MB/秒を超えるスループットが必要な場合は、スケールアップよりもスケールアウトする方が理にかなう場合があります。以下の表はこれらの推奨事項をまとめています。
| ブローカー数 | 推奨持続スループット制限 | ||
| m7g.large | m7g.2xlarge | m7g.4xlarge | |
| 3 | 63 MB/秒 | 200 MB/秒 | 200 MB/秒 |
| 6 | 126 MB/秒 | 400 MB/秒 | 400 MB/秒 |
| 9 | 189 MB/秒 | 600 MB/秒 | 600 MB/秒 |
この場合、プロビジョンドスループットを使用してクラスターのスループットを増加させることもできました。例えば、前の図の 6 ノード m7g.2xlarge クラスターの持続スループット制限と、前の例のプロビジョンドスループットを持つ 3 ノード m7g.4xlarge クラスターを比較してください。両方のクラスターの持続スループット制限は同じです。これは、通常ブローカーサイズに比例して増加する同じ Amazon EC2 ネットワーク帯域幅制限によって引き起こされます。
スケールアップによるクラスター読み取りスループットの増加
クラスターから読み取るコンシューマーグループが多いほど、ブローカーの Amazon EC2 ネットワーク経由で送出されるデータが多くなります。より大きなブローカーはより高いネットワークベースラインスループット (最大 25 Gb/秒) を持ち、クラスターから読み取るより多くのコンシューマーグループをサポートできます。
以下の図は、3 ノード m7g.2xlarge クラスターの異なるコンシューマーグループ数に対してレイテンシーとスループットがどのように変化するかを比較しています。
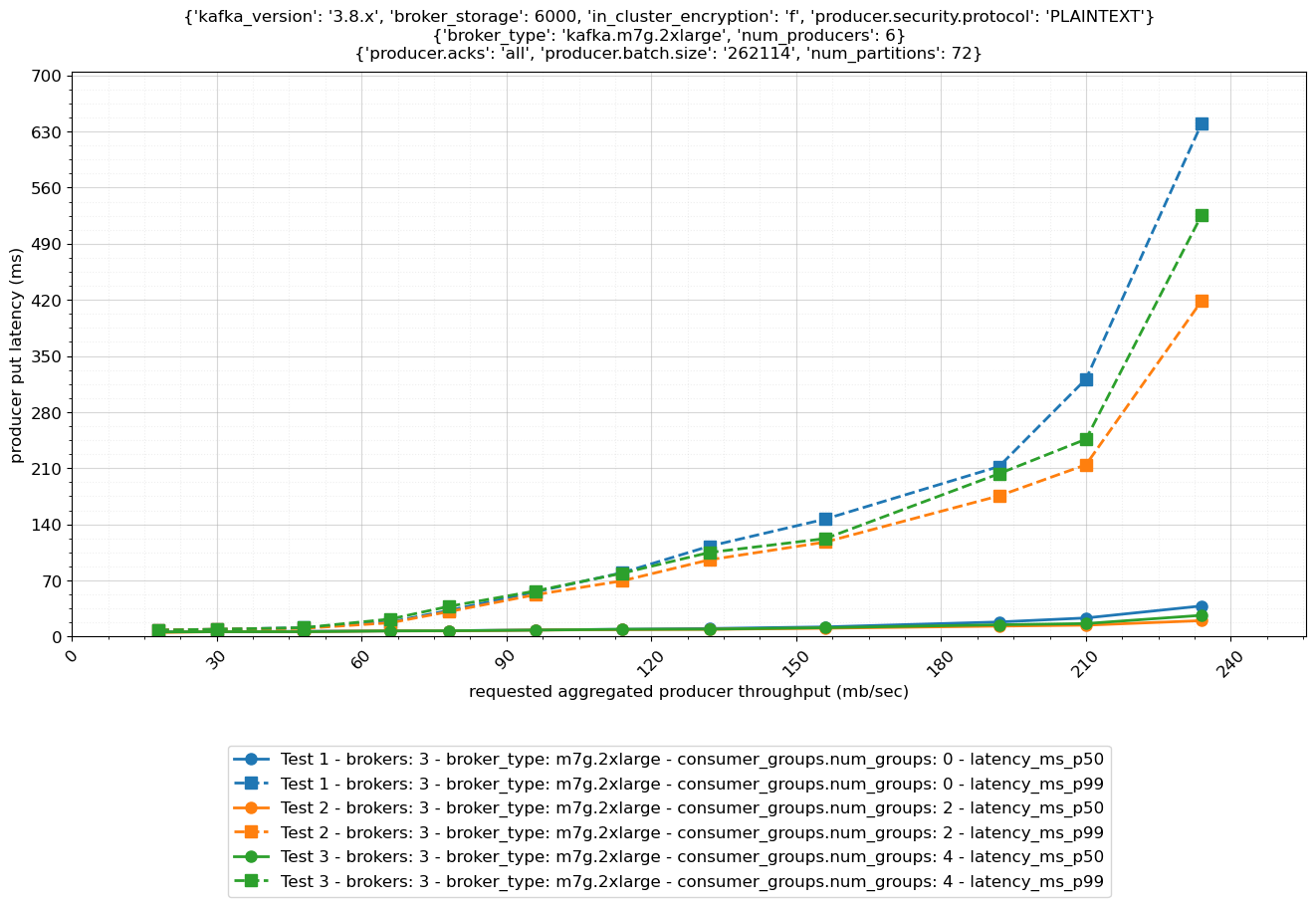
この図で示されているように、クラスターから読み取るコンシューマーグループ数を増やすと、持続スループット制限が減少します。コンシューマーグループがクラスターから読み取るコンシューマーが多いほど、Amazon EC2 ネットワーク経由でブローカーから送出する必要があるデータが多くなります。以下の表はこれらの推奨事項をまとめています。
| コンシューマーグループ | 推奨持続スループット制限 | ||
| m7g.large | m7g.2xlarge | m7g.4xlarge | |
| 0 | 63 MB/秒 | 200 MB/秒 | 200 MB/秒 |
| 2 | 63 MB/秒 | 200 MB/秒 | 200 MB/秒 |
| 4 | 48 MB/秒 | 192 MB/秒 | 200 MB/秒 |
| 6 | 35 MB/秒 | 144 MB/秒 | 200 MB/秒 |
ブローカーサイズが Amazon EC2 ネットワークスループットを決定し、スケールアップ以外にそれを増やす方法はありません。したがって、クラスターの読み取りスループットをスケーリングするには、ブローカーをスケールアップするか、ブローカー数を増やす必要があります。
ブローカーサイズとブローカー数のバランス
クラスターのサイジング時には、クラスターのスループットとパフォーマンスを向上させるためにスケールアウトまたはスケールアップのいずれかを選択できることがよくあります。ストレージサイズがそれに応じて調整されていると仮定すると、これら 2 つのオプションのコストは多くの場合同じです。では、いつスケールアウトまたはスケールアップすべきでしょうか?
小さなブローカーを使用すると、より小さな増分で容量をスケーリングできます。Amazon MSK は、ブローカーが構成されたすべてのアベイラビリティーゾーン間で均等にバランスされることを強制します。したがって、アベイラビリティーゾーン数の倍数のブローカー数のみを追加できます。例えば、プロビジョンドスループットなしの 3 ノード m7g.4xlarge クラスターに 3 つのブローカーを追加すると、推奨持続クラスタースループット制限が 100% 増加し、200 MB/秒から 400 MB/秒になります。ただし、6 ノード m7g.2xlarge クラスターに 3 つのブローカーを追加すると、推奨クラスタースループット制限は 50% 増加し、400 MB/秒から 600 MB/秒になります。
非常に大きなブローカーが少なすぎると、メンテナンスのために単一のブローカーがダウンしたり、基盤となるインフラストラクチャの障害が発生した場合の影響範囲も増加します。例えば、3 ノードクラスターの場合、単一のブローカーはクラスター容量の 33% に相当しますが、6 ノードクラスターでは 17% にすぎません。ベストプラクティスに従ってクラスターをプロビジョニングする場合、これらの操作中にワークロードに影響を与えないように十分な予備容量を追加しています。ただし、より大きなブローカーの場合、より大きな容量増分のために必要以上の予備容量を追加する必要がある場合があります。
ただし、クラスターに含まれるブローカーが多いほど、メンテナンスと更新操作の完了に時間がかかります。サービスは、クラスターの可用性への影響を最小限に抑えるために、これらの変更を一度に 1 つのブローカーに順次適用します。ベストプラクティスに従ってクラスターをプロビジョニングする場合、これらの操作中にワークロードに影響を与えないように十分な予備容量を追加しています。ただし、操作の完了にかかる時間は、1 つの操作が完了するのを待ってから別の操作を実行する必要があるため、考慮すべき事項です。
ワークロードに適したバランスを見つける必要があります。小さなブローカーは、より小さな容量増分を提供するため、より柔軟です。ただし、小さなブローカーが多すぎると、メンテナンス操作の完了に時間がかかり、障害の可能性が高くなります。より少ない大きなブローカーを持つクラスターは、更新操作をより速く完了します。ただし、より大きな容量増分と、ブローカー障害時のより大きな影響範囲が伴います。
CPU 集約型ワークロードのためのスケールアップ
これまで、ブローカーのネットワークスループットに焦点を当ててきました。しかし、クラスターのスループットとレイテンシーを決定する他の要因があります。その 1 つが暗号化です。Apache Kafka には、転送中および保存中のデータを保護できる暗号化のいくつかのレイヤーがあります: ストレージボリュームに保存されたデータの暗号化、ブローカー間のトラフィックの暗号化、およびクライアントとブローカー間のトラフィックの暗号化です。
Amazon MSK は常に保存中のデータを暗号化します。Amazon MSK が保存中のデータを暗号化するために使用する AWS Key Management Service (AWS KMS) カスタマーマスターキー (CMK) を指定できます。CMK を指定しない場合、Amazon MSK は AWS マネージド CMK を作成し、代わりに使用します。転送中のデータについては、プロデューサーとブローカー間のデータの暗号化 (転送中暗号化)、ブローカー間の暗号化 (クラスター内暗号化)、またはその両方を有効にすることを選択できます。
クラスター内暗号化を有効にすると、ブローカーは個々のメッセージを暗号化および復号化する必要があります。そのため、ネットワーク経由でメッセージを送信する際に、効率的なゼロコピー操作を利用できなくなります。これにより、追加の CPU とメモリ帯域幅のオーバーヘッドが発生します。
以下の図は、m7g.large および m7g.2xlarge ブローカーを持つ 3 ノードクラスターに対するこれらのオプションのパフォーマンスへの影響を示しています。
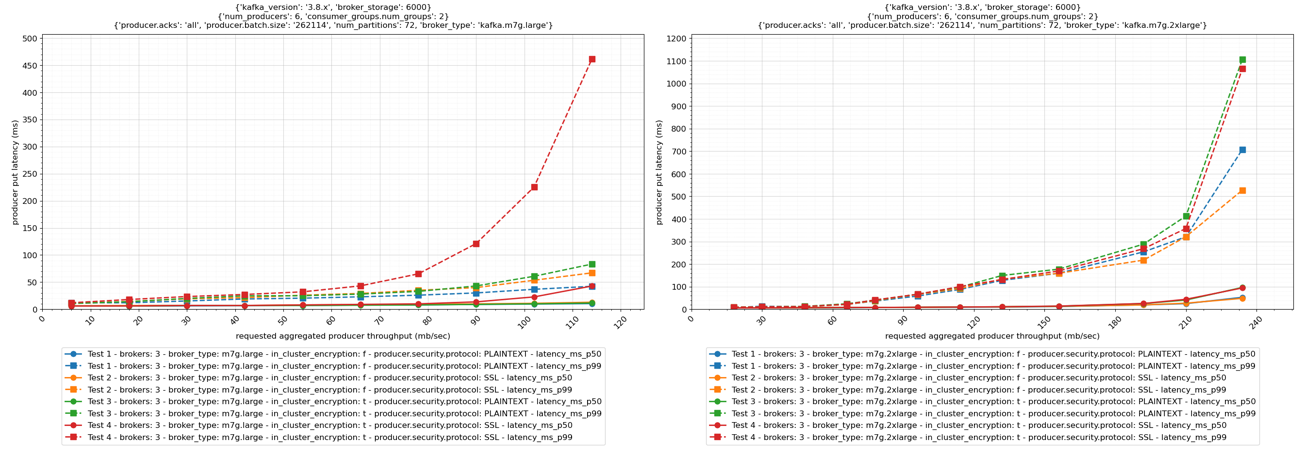
p99 put レイテンシーについては、クラスター内暗号化を有効にすると大きなパフォーマンスへの影響があります。前のグラフに示されているように、ブローカーをスケールアップすることでその影響を軽減できます。転送中暗号化とクラスター内暗号化を有効にした m7g.large クラスターの 90 MB/秒スループットでの p99 put レイテンシーは 120 ミリ秒を超えています (左のグラフの赤い破線)。クラスターを m7g.2xlarge ブローカーにスケーリングすると、同じスループットでの p99 put レイテンシーが 50 ミリ秒未満に低下します (右のグラフの赤い破線)。
CPU 要件を増加させる他の要因があります。圧縮やログコンパクションもクラスターの負荷に影響を与える可能性があります。
ストリームの先端から読み取らないコンシューマーのためのスケールアップ
コンシューマーが常にトピックの先端から読み取るようにパフォーマンステストを設計しました。これは事実上、ブローカーがコンシューマーからの読み取りをメモリから直接提供でき、Amazon EBS への読み取り I/O を引き起こさないことを意味します。この記事の他のすべてのセクションとは対照的に、遅れたコンシューマーがクラスターパフォーマンスにどのように影響するかを理解するために、この仮定を外します。以下の図はこの設計を示しています。
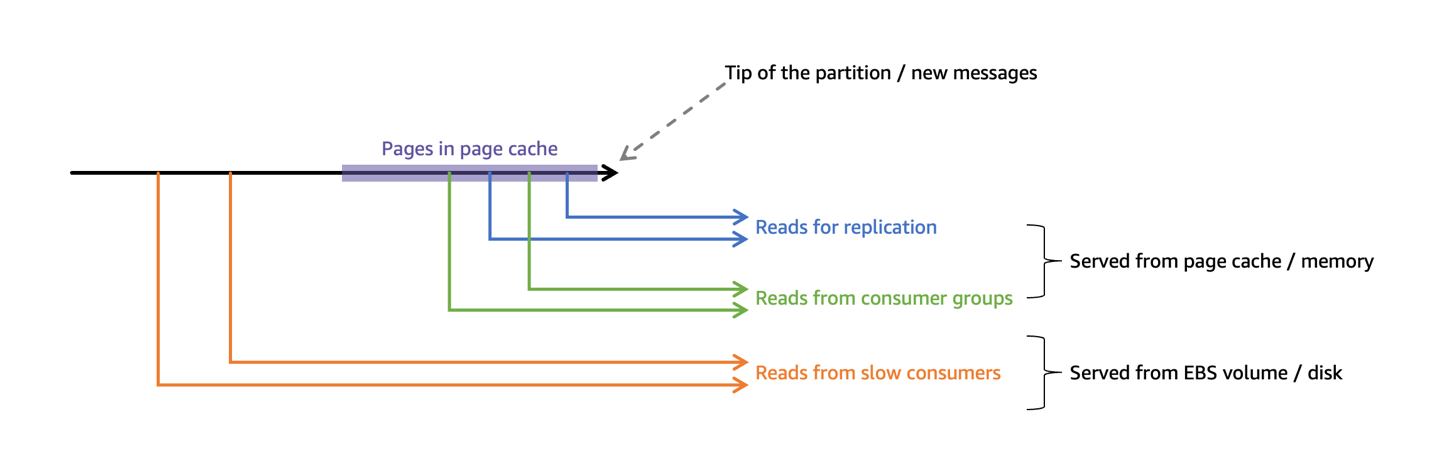
コンシューマーが遅れたり、障害から回復する必要がある場合、古いメッセージを再処理します。その場合、データを保持しているページがページキャッシュに存在しなくなり、ブローカーは EBS ボリュームからデータをフェッチする必要があります。これにより、ボリュームへの追加のネットワークトラフィックと非シーケンシャル I/O 読み取りが発生します。これにより、EBS ボリュームのスループットに大きな影響を与える可能性があります。
極端なケースでは、バックフィル操作がイベントの完全な履歴を再処理する可能性があります。その場合、操作は EBS ボリュームへの追加の I/O を引き起こすだけでなく、履歴データを保持する多くのページをページキャッシュにロードし、より最近のデータを保持するページを効果的に追い出します。その結果、トピックの先端よりわずかに遅れていて、通常はページキャッシュから直接読み取るコンシューマーが、バックフィル操作が読み取る必要のあるページをメモリから追い出したため、EBS ボリュームへの追加の I/O を引き起こす可能性があります。
MSK クラスターが Tiered Storage を使用してリモートストレージからデータを読み取っている場合、効果は EBS について前述したものと非常に似ていますが、唯一の違いは、データがリモートストレージから直接 EC2 に来るため、EBS ネットワークではなく EC2 ネットワークが影響を受けることです。ページキャッシュの動作はまったく同じです。
これらのシナリオを軽減する 1 つのオプションは、圧縮を有効にすることです。生データを圧縮することで、ブローカーはメモリから追い出される前により多くのデータをページキャッシュに保持できます。ただし、圧縮にはより多くの CPU リソースが必要であることに注意してください。圧縮を有効にできない場合、または圧縮を有効にしてもこのシナリオを軽減できない場合は、スケールアップしてブローカーで使用可能なメモリを増やすことで、ページキャッシュのサイズを増やすこともできます。
バーストパフォーマンスを使用したトラフィックスパイクへの対応
これまで、クラスターの持続スループット制限を見てきました。これは、クラスターが無期限に維持できるスループットです。ストリーミングワークロードでは、ベースラインのスループット要件を理解し、それに応じてサイジングすることが重要です。ただし、Amazon EC2 ネットワーク、Amazon EBS ネットワーク、および Amazon EBS ストレージシステムはクレジットシステムに基づいています。これらは特定のベースラインスループットを提供し、インスタンスサイズに基づいて一定期間より高いスループットにバーストできます。これは MSK クラスターのスループットに直接変換されます。MSK クラスターには持続スループット制限があり、短期間はより高いスループットにバーストできます。
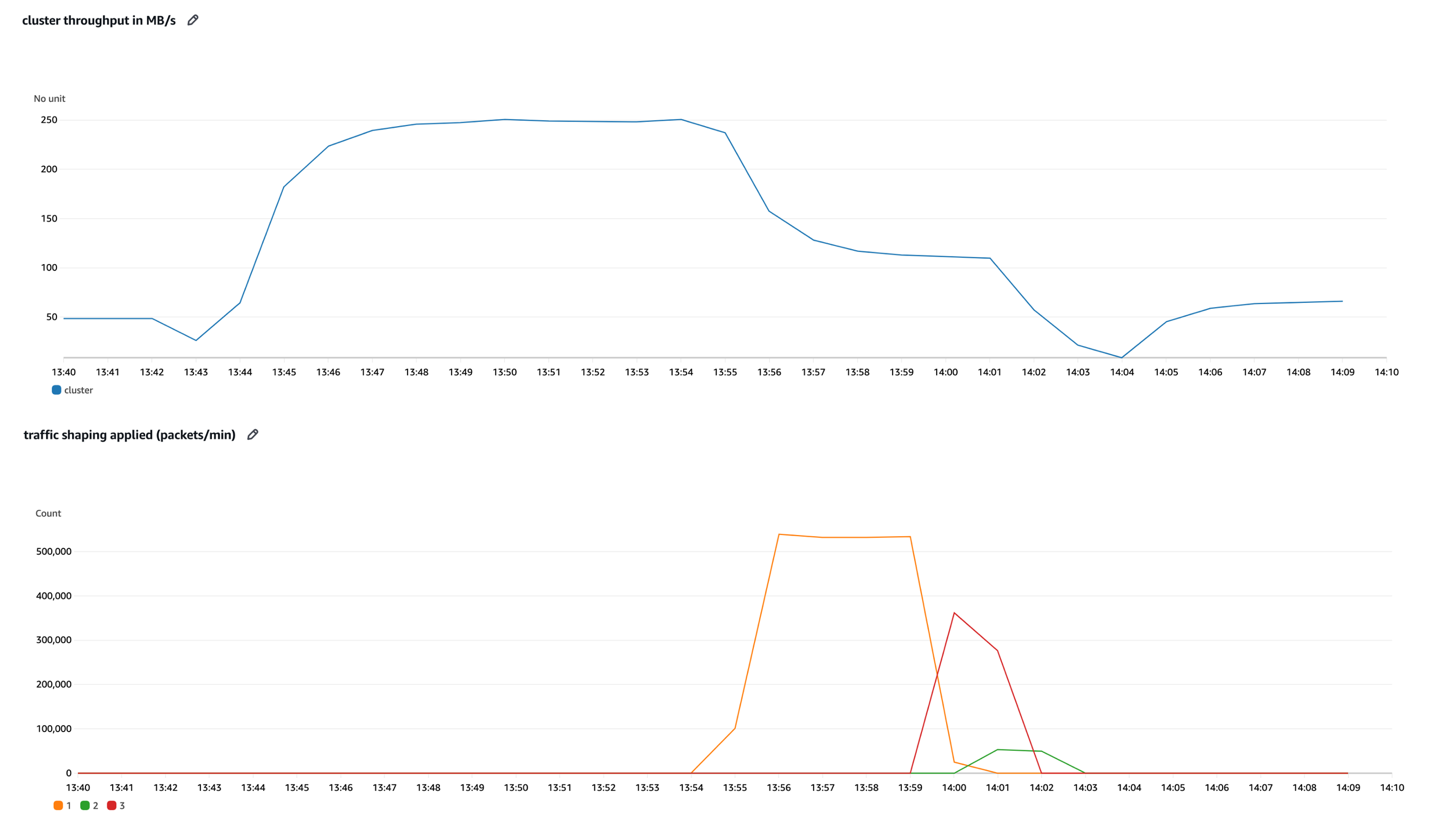
以下のグラフの青い線は、2 つのコンシューマーグループを持つ 3 ノード m7g.large クラスターの集約スループットを示しています。実験全体を通じて、プロデューサーはできるだけ速くクラスターにデータを送信しようとしています。したがって、クラスターの持続スループット制限の 80% は約 63 MB/秒ですが、クラスターは約 10 分間 200 MB/秒をはるかに超えるスループットにバーストできます。
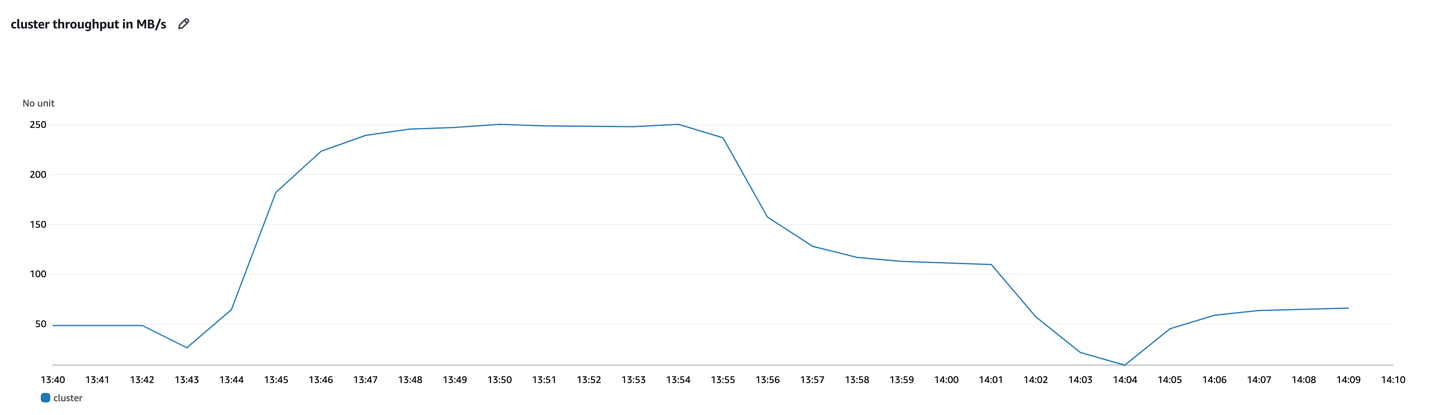
次のように考えてください: クラスターの基盤となるインフラストラクチャを構成するとき、基本的に特定の持続スループット制限を持つクラスターをプロビジョニングしています。バースト機能により、クラスターはしばらくの間、はるかに高いスループットを瞬時に吸収できます。例えば、ワークロードの平均スループットが通常約 50 MB/秒の場合、前のグラフの 3 ノード m7g.large クラスターは、約 10 分間、通常のスループットの 4 倍以上を受信できます。そして、変更は必要ありません。このより高いスループットへのバーストは完全に透過的であり、スケーリング操作を必要としません。
これは、完了に時間がかかるクラスターのスケーリングなしで、突然のスループットスパイクを吸収する非常に強力な方法です。さらに、追加の容量は運用イベントへの対応にも役立ちます。例えば、ブローカーがメンテナンス中であったり、パーティションをクラスター内で再バランスする必要がある場合、バーストパフォーマンスを使用してブローカーをより速くオンラインにし、同期を取り戻すことができます。バースト容量は、アベイラビリティーゾーン全体に影響を与え、イベントへの応答として大量のレプリケーショントラフィックを引き起こす運用イベントから迅速に回復するためにも非常に価値があります。
モニタリングと継続的な最適化
これまで、クラスターの初期サイジングに焦点を当ててきました。しかし、正しい初期クラスターサイズを決定した後、サイジングの取り組みを止めるべきではありません。本番環境で実行された後、ワークロードを継続的にレビューして、ブローカーサイズがまだ適切かどうかを確認することが重要です。初期の仮定が実際には当てはまらなくなったり、設計目標が変更されたりする可能性があります。結局のところ、クラウドコンピューティングの大きな利点の 1 つは、API 呼び出しを通じて基盤となるインフラストラクチャを適応できることです。
前述のとおり、本番クラスターのスループットは持続スループット制限の 80% を目標とする必要があります。基盤となるインフラストラクチャがスループット制限を長時間超えたためにスロットリングを経験し始めた場合、クラスターをスケールアップする必要があります。理想的には、このポイントに達する前にクラスターをスケーリングすることさえできます。デフォルトでは、Amazon MSK は、このスロットリングが基盤となるインフラストラクチャに適用されたときを示す 3 つのメトリクスを公開しています:
- BurstBalance – EBS ボリュームの残りの I/O バーストクレジットを示します。このメトリクスが低下し始めた場合、ボリュームのベースラインパフォーマンスを向上させるために EBS ボリュームのサイズを増やすことを検討してください。Amazon CloudWatch がクラスターに対してこのメトリクスを報告していない場合、ボリュームは 5.3 TB を超えており、バーストクレジットの対象ではなくなっています。
- CPUCreditBalance – T3 ファミリーのブローカーにのみ関連し、利用可能な CPU クレジットの量を示します。このメトリクスが低下し始めた場合、ブローカーは CPU ベースラインパフォーマンスを超えてバーストするために CPU クレジットを消費しています。ブローカータイプを M7g ファミリーに変更することを検討してください。
- TrafficShaping – ネットワーク割り当てを超えたためにドロップされたパケット数を示す高レベルのメトリクスです。クラスターに
PER_BROKERモニタリングレベルが構成されている場合、より詳細な情報が利用可能です。このメトリクスが通常のワークロード中に上昇している場合は、ブローカーをスケールアップしてください。
前の例では、ネットワーククレジットが枯渇し、トラフィックシェーピングが適用された後、クラスタースループットが大幅に低下するのを見ました。クラスターの最大持続スループット制限がわからなくても、以下のグラフの TrafficShaping メトリクスは、Amazon EC2 ネットワークレイヤーでのさらなるスロットリングを回避するためにブローカーをスケールアップする必要があることを明確に示しています。
Amazon MSK は、クラスターがオーバープロビジョニングまたはアンダープロビジョニングされているかどうかを理解するのに役立つ追加のメトリクスを公開しています。サイジング演習の一環として、クラスターの持続スループット制限を決定しました。BytesInPerSec、ReplicationBytesInPerSec、BytesOutPerSec、および ReplicationBytesInPerSec メトリクスを監視したり、アラームを作成したりして、現在のクラスターサイズが現在のワークロード特性に最適でなくなったときに通知を受け取ることができます。同様に、CPUIdle メトリクスを監視し、クラスターが CPU 使用率の観点からアンダープロビジョニングまたはオーバープロビジョニングされている場合にアラームを設定できます。
これらは、インフラストラクチャの観点からクラスターのサイズを監視するための最も関連性の高いメトリクスにすぎません。クラスターとワークロード全体の健全性も監視する必要があります。クラスターの監視に関する詳細なガイダンスについては、ベストプラクティスを参照してください。
Apache Kafka パフォーマンステストのフレームワーク
前述のとおり、クラスターのパフォーマンスが特定のワークロード特性に一致するかどうかを検証するには、独自のテストを実行する必要があります。多くのテストのスケジューリングと可視化を自動化するのに役立つパフォーマンステストフレームワークを GitHub で公開しています。この記事で説明してきたグラフを生成するために、同じフレームワークを使用しています。
このフレームワークは、Apache Kafka ディストリビューションの一部である kafka-producer-perf-test.sh および kafka-consumer-perf-test.sh ツールに基づいています。これらのツールの周りに自動化と可視化を構築しています。
バースト機能の対象となる小さなブローカーの場合、フレームワークを構成して、最初にネットワーキング、ストレージ、またはストレージネットワーククレジットを枯渇させるために長期間にわたって過剰な負荷を生成することもできます。クレジット枯渇が完了した後、フレームワークは実際のパフォーマンステストを実行します。これは、一定期間のみ維持できるピークパフォーマンスを測定するのではなく、無期限に維持できるクラスターのパフォーマンスを測定するために重要です。
独自のテストを実行するには、GitHub リポジトリを参照してください。そこには、AWS Cloud Development Kit (AWS CDK) テンプレートと、パフォーマンステストの構成、実行、および結果の可視化方法に関する追加のドキュメントがあります。
まとめ
インフラストラクチャの観点から Apache Kafka のパフォーマンスに寄与するさまざまな要因について説明しました。Apache Kafka に焦点を当てましたが、Amazon EC2 ネットワーキングと Amazon EBS パフォーマンス特性についても学びました。
クラスターの適切なサイズを見つけるには、ユースケースから逆算して、スループット、可用性、耐久性、およびレイテンシーの要件を決定します。
スループット、ストレージ、および耐久性の要件に基づいて、クラスターの初期サイジングから始めます。クラスターの書き込みスループットを増加させるには、スケールアウトするか、プロビジョンドスループットを使用します。クラスターから消費できるコンシューマー数を増やすには、スケールアップします。転送中暗号化またはクラスター内暗号化を容易にし、ストリームの先端から読み取らないコンシューマーに対応するには、スケールアップします。
パフォーマンステストを実行してこの初期クラスターサイジングを検証し、レイテンシーなどの他の要件に合わせてクラスターサイズと構成を微調整します。ブローカーのメンテナンスまたは損失に耐えられるように、本番クラスターに追加の容量を追加します。ワークロードによっては、アベイラビリティーゾーン全体に影響するイベントに耐えることも検討できます。最後に、クラスターメトリクスを監視し続け、初期の仮定が当てはまらなくなった場合はクラスターのサイズを変更します。
著者について
 Steffen Hausmann AWS の Principal Streaming Architect です。世界中のお客様と協力して、ストリーミングデータから価値を得られるようにストリーミングアーキテクチャを設計および構築しています。ミュンヘン大学でコンピュータサイエンスの博士号を取得しており、自由時間には、カンファレンスで集めたかわいいステッカーで娘たちをテクノロジーに引き込もうとしています。
Steffen Hausmann AWS の Principal Streaming Architect です。世界中のお客様と協力して、ストリーミングデータから価値を得られるようにストリーミングアーキテクチャを設計および構築しています。ミュンヘン大学でコンピュータサイエンスの博士号を取得しており、自由時間には、カンファレンスで集めたかわいいステッカーで娘たちをテクノロジーに引き込もうとしています。
 Sebastian Vlad AWS の Senior Solutions Architect で、金融サービステクノロジーとデータ分析ソリューションを専門としています。金融セクターのエンタープライズのお客様と協力して、ビジネス変革を推進するモダンで安全かつスケーラブルなクラウドアーキテクチャの設計と構築を支援しています。
Sebastian Vlad AWS の Senior Solutions Architect で、金融サービステクノロジーとデータ分析ソリューションを専門としています。金融セクターのエンタープライズのお客様と協力して、ビジネス変革を推進するモダンで安全かつスケーラブルなクラウドアーキテクチャの設計と構築を支援しています。
 Victor Valdevite Pinto AWS の Senior Technical Account Manager です。Enterprise Support のお客様と協力して、お客様が独自の目標を達成し、安全で回復力があり最適化されたクラウドジャーニーで成功できるよう支援しています。また、Streaming Analytics を専門としています。
Victor Valdevite Pinto AWS の Senior Technical Account Manager です。Enterprise Support のお客様と協力して、お客様が独自の目標を達成し、安全で回復力があり最適化されたクラウドジャーニーで成功できるよう支援しています。また、Streaming Analytics を専門としています。
この記事は Kiro が翻訳を担当し、Solutions Architect の 榎本 貴之 がレビューしました。