AWS Big Data Blog
How to choose the right Amazon MSK cluster type for you
March 2025: This post was reviewed and updated for accuracy.
Amazon Managed Streaming for Apache Kafka (Amazon MSK) is an AWS streaming data service that manages Apache Kafka infrastructure and operations, making it easy for developers and DevOps managers to run Apache Kafka applications and Kafka Connect connectors on AWS, without the need to become experts in operating Apache Kafka. Amazon MSK operates, maintains, and scales Apache Kafka clusters, provides enterprise-grade security features out of the box, and has built-in AWS integrations that accelerate development of streaming data applications. You can easily get started by creating an MSK cluster using the AWS Management Console with a few clicks.
When creating a cluster, you must choose a cluster type from two options: Amazon MSK Provisioned or Amazon MSK Serverless. Within the Provisioned cluster type, there are two broker types: Standard and Express. Amazon MSK Provisioned allows users to manually configure and scale their Apache Kafka clusters, offering more control over the infrastructure. Standard brokers provide the most flexibility for configuring clusters, supporting various instance types and allowing customization of storage options. Express brokers, on the other hand, offer higher performance, faster scaling, and easier management. They provide up to three times more throughput per broker, scale up to 20 times faster, and reduce recovery time by 90% compared to Standard brokers. Express brokers come preconfigured with Kafka best practices and offer fully managed storage without pre-provisioning. Amazon MSK Serverless automatically provisions and scales cluster capacity, eliminating the need for manual broker management. It allows users to focus on application development without worrying about cluster sizing or scaling. When comparing with Amazon MSK Serverless, the main difference is the level of control and management required—Amazon MSK Provisioned offers more customization but requires more hands-on management, while Amazon MSK Serverless provides a more automated, hands-off experience with flexibility trade off.
In this post, I examine a use case with the fictitious company AnyCompany, who plans to use Amazon MSK for two applications. They must decide between provisioned or serverless cluster types. I describe a process by which they work backward from the applications’ requirements to find the best MSK cluster type for their workloads, including how the organizational structure and application requirements are relevant in finding the best offering. Lastly, I examine the requirements and their relationship to Amazon MSK features.
Use case
AnyCompany is an enterprise organization that is ready to move two of their Kafka applications to Amazon MSK.
The first is a large ecommerce platform, which is a legacy application that currently uses a self-managed Apache Kafka cluster run in their data centers. AnyCompany wants to migrate this application to the AWS Cloud and use Amazon MSK to reduce maintenance and operations overhead. AnyCompany has a DataOps team that has been operating self-managed Kafka clusters in their data centers for years. AnyCompany wants to continue using the DataOps team to manage the MSK cluster on behalf of the development team. There is very little flexibility for code changes. For example, a few modules of the application require specific topic level settings such as segment.bytes configuration. The ingress throughput for this application doesn’t fluctuate often. The ecommerce platform only experiences a surge in user activity during special sales events. The DataOps team has a good understanding of this application’s traffic pattern and are confident that they can optimize an MSK cluster by setting some custom broker-level configurations.
The second example is a marketing platform that processes millions of customer interactions, purchases, and inventory updates daily. This platform requires a robust, scalable streaming solution to handle its high-volume data processing. Additionally, it needs long-term data retention capabilities for analytics purposes. High availability and resiliency are critical for the platform’s operations. The DataOps team is familiar with Apache Kafka operations. However, they prefer a solution with minimal overhead that offers features such as quick cluster scaling and automatic quota management during recovery scenarios.
The third application is a new cloud-centered gaming application currently in development. AnyCompany hopes to launch this gaming application soon followed by a marketing campaign. Throughput needs for this application are unknown. The application is expected to receive high traffic initially, then user activity should decline gradually. Because the application is going to launch first in the US, traffic during the day is expected to be higher than at night. This application offers a lot of flexibility in terms of Kafka client version, encryption in transit, and authentication. Because this application is built for the cloud, AnyCompany hopes they can delegate full ownership of its infrastructure to the development team.
Solution overview
Let’s examine a process that helps AnyCompany decide between the three Amazon MSK offerings. The following diagram shows this process at a high level.
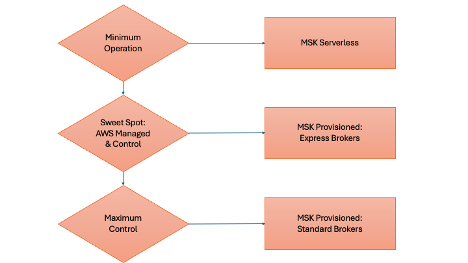
In the following sections, I explain each step in detail and the relevant information that AnyCompany needs to collect before they make a decision.
Competency in Apache Kafka
AWS recommends a list of best practices to follow when using the Amazon MSK provisioned offering. Amazon MSK provisioned, offers more flexibility so you make scaling decisions based on what’s best for your workloads. For example, you can save on cost by consolidating a group of workloads into a single cluster. You can decide which metrics are important to monitor and optimize your cluster through applying custom configurations to your brokers. You can choose your Apache Kafka version, among different supported versions, and decide when to upgrade to a new version. Amazon MSK takes care of applying your configuration and upgrading each broker in a rolling fashion.
With more flexibility, you have more responsibilities. You need to make sure your cluster is right-sized at any time. You can achieve this by monitoring a set of cluster-level, broker-level, and topic-level metrics to ensure you have enough resources that are needed for your throughput. You also need to make sure the number of partitions assigned to each broker doesn’t exceed the numbers suggested by Amazon MSK. If partitions are unbalanced, you need to even-load them across all brokers. If you have more partitions than recommended, you need to either upgrade brokers to a larger size or increase the number of brokers in your cluster. There are also best practices for the number of TCP connections when using AWS Identity and Access Management (IAM) authentication.
With an Amazon MSK Provisioned cluster with Express brokers, customers have fewer operational responsibilities compared to Standard brokers. While both types require manage compute capacity, monitor broker ingress throughput, and handle scaling decisions, Express brokers perform scaling operations up to 20 times faster. Express brokers eliminate the need for storage management and proactive disk capacity monitoring, as they offer unlimited storage without pre-provisioning.
An MSK Serverless cluster takes away the complexity of right-sizing clusters and balancing partitions across brokers. This makes it easy for developers to focus on writing application code.
AnyCompany has an experienced DataOps team who are familiar with scaling operations and best practices for the MSK provisioned cluster type. AnyCompany can use their DataOps team’s Kafka expertise for building automations and easy-to-follow standard procedures on behalf of the ecommerce application team. The gaming development team is an exception, because they are expected to take the full ownership of the infrastructure.
In the following sections, I discuss other steps in the process before deciding which cluster type is right for each application.
Custom configuration
In certain use cases, you need to configure your MSK cluster differently from its default settings. This could be due to your application requirements. For example, AnyCompany’s ecommerce platform requires setting up brokers such that the default retention period for all topics is set to 72 hours. Also, topics should be or auto-created when they are requested and don’t exist.
The Amazon MSK Provisioned offering provides a default configuration for brokers, and topics. It also allows you to create custom configurations and use them to create new MSK clusters or update existing clusters. An MSK cluster configuration consists of a set of properties and their corresponding values.
Amazon MSK’s Express brokers enhance the reliability and performance of Kafka clusters by optimizing critical configurations and safeguarding against common misconfigurations. This feature automatically sets and protects key parameters, improves availability and durability of MSK Provisioned clusters.
AnyCompany’s gaming application requires only topic-level configurations for retention.ms and max.message.bytes, without broker-level customization. Their e-commerce platform developers need specific topic-level settings like segment.bytes to accommodate their programming framework requirements. Meanwhile, the marketing platform team requires replica.selector.class configuration to leverage MSK’s nearest fetch replica feature for reduced networking costs.
Application requirements
Apache Kafka applications differ in terms of their security; the way they connect, write, or read data; data retention period; and scaling patterns. For example, some applications can only scale vertically, whereas other applications can scale only horizontally. Although a flexible application can be configured with IAM authentication, a legacy application can only authenticate using SASL_SCRAM, a credential-based authentication, and authorization scheme.
Cluster-level quotas
Amazon MSK enforces some quotas to ensure the performance, reliability, and availability of the service for all customers. These quotas are subject to change at any time. To access the latest values for each dimension, refer to Amazon MSK quota. Note that some of the quotas are soft limits and can be increased using a support ticket.
When choosing a cluster type in Amazon MSK, it’s important to understand your application requirements and compare those against quotas in relation with each offering. This makes sure you choose the best cluster type that meets your goals and application’s needs. Let’s examine how you can calculate the throughput you need and other important dimensions you need to compare with Amazon MSK quotas:
- Number of clusters per account – Amazon MSK may have quotas for how many clusters you can create in a single AWS account. If this is limiting your ability to create more clusters, you can consider creating those in multiple AWS accounts and using secure connectivity patterns to provide access to your applications.
- Message size – You need to make sure the maximum message size that your producer writes for a single message is lower than the configured size in the MSK cluster. MSK provisioned clusters allow you to change the default value in a custom configuration. If you choose MSK Serverless, check this value in Amazon MSK quota. The average message size is helpful when calculating the total ingress or egress throughput of the cluster, which I demonstrate later in this post.
- Message rate per second – This directly influences total ingress and egress throughput of the cluster. Total ingress throughput equals the message rate per second multiplied by message size. You need to make sure your producer is configured for optimal throughput by adjusting
batch.sizeandlinger.msproperties. If you’re choosing MSK Serverless, you need to make sure you configure your producer to optimal batches with the rate that is lower than its request rate quota. - Number of consumer groups – This directly influences the total egress throughput of the cluster. Total egress throughput equals the ingress throughput multiplied by the number of consumer groups. If you’re choosing MSK Serverless, you need to make sure your application can work with these quotas.
- Maximum number of partitions – Amazon MSK provisioned recommends not exceeding certain limits per broker (depending the broker size). If the number of partitions per broker exceeds the maximum value specified in the previous table, you can’t perform certain upgrade or update operations. MSK Serverless also has a high number of 2400 soft limit for number of lead partitions per clusters. You can also request to increase the quota by creating a support case.
Partition-level quotas
Apache Kafka organizes data in structures called topics. Each topic consists of a single or many partitions. Partitions are the degree of parallelism in Apache Kafka. The data is distributed across brokers using data partitioning. Let’s examine a few important Amazon MSK requirements, and how you can make sure which cluster type works better for your application:
- Maximum throughput per partition – MSK Serverless automatically balances the partitions of your topic between the backend nodes. It instantly scales when your ingress throughput increases. However, each partition has a quota of how much data it accepts. This is to ensure the data is distributed evenly across all partitions and backend nodes. In an MSK Serverless cluster, you need to create your topic with enough partitions such that the aggregated throughput is equal to the maximum throughput your application requires. You also need to make sure your consumers read data with a rate that is below the maximum egress throughput per partition quota. If you’re using Amazon MSK provisioned, there is no partition-level quota for write and read operations. However, AWS recommends you monitor and detect hot partitions and control how partitions should balance among the broker nodes.
- Data storage – The amount of time each message is kept in a particular topic directly influences the total amount of storage needed for your cluster. Amazon MSK allows you to manage the retention period at the topic level. MSK provisioned clusters allow broker-level configuration to set the default data retention period. MSK Serverless clusters allow unlimited data retention MSK Serverless quota.
Security
Amazon MSK recommends that you secure your data in the following ways. Availability of the security features varies depending on the cluster type. Before making a decision about your cluster type, check if your preferred security options are supported by your choice of cluster type.
- Encryption at rest – Amazon MSK integrates with AWS Key Management Service (AWS KMS) to offer transparent server-side encryption. Amazon MSK always encrypts your data at rest. When you create an MSK cluster, you can specify the KMS key that you want Amazon MSK to use to encrypt your data at rest.
- Encryption in transit – Amazon MSK uses TLS 1.2. By default, it encrypts data in transit between the brokers of your MSK cluster. You can override this default when you create the cluster. For communication between clients and brokers, you must specify one of the following settings:
- Only allow TLS encrypted data. This is the default setting.
- Allow both plaintext and TLS encrypted data.
- Only allow plaintext data.
- Authentication and authorization – Use AWS Identity and Access Management (IAM) for authentication and authorization for all programming languages to authenticate clients and allow or deny Apache Kafka actions. For instructions on configuring clients for IAM, see Configure clients for IAM access control. If you have use-case to use TLS or SASL for your authentication, MSK Provisioned type is right for you.
Cost of ownership
Amazon MSK automatically provisions and runs Apache Kafka clusters. Amazon MSK continuously monitors cluster health and automatically replaces unhealthy nodes with no application downtime. In addition, Amazon MSK secures Apache Kafka clusters by encrypting data at rest and in transit. Additionally, MSK Provisioned clusters do not charge customers for cross-AZ data replication needed for High Availability. Nearest replica fetching in Amazon MSK allows consumers to read data from the same Availability Zone, reducing cross-AZ traffic costs by up to two-thirds. These capabilities can significantly reduce your Total Cost of Ownership (TCO).
MSK Express brokers can provide lower TCO through several efficiency improvements compared to regular Kafka. They deliver up to three times more throughput per broker, allowing smaller clusters to handle the same workload. The unlimited storage without pre-provisioning eliminates disk management overhead, while 20 times faster scaling and 90% faster recovery times reduce operational costs. Express brokers come preconfigured with best practices by default, reducing failures due to misconfiguration and minimizing the need for continuous monitoring and manual intervention. These features combined result in lower infrastructure costs, reduced operational overhead, and improved resource utilization.
MSK Serverless automatically scales the cluster capacity based on the throughput, and you only pay per GB of data that your producers write to and your consumers read from the topics in your cluster. Additionally, you pay an hourly rate for your serverless clusters and an hourly rate for each partition that you create. The MSK Serverless cluster type generally offers a lower cost of ownership by taking away the cost of engineering resources needed for monitoring, capacity planning, and scaling MSK clusters. See the MSK_Sizing_Pricing; For provisioned cluster type you need to plan for your peak throughput while with MSK Serverless cluster type use your average throughput for getting a cost estimate.
However, if your organization has a DataOps team with Kafka competency, you can use this competency to operate optimized MSK provisioned clusters. This allows you to save on Amazon MSK costs by consolidating several Kafka applications into a single cluster. There are a few critical considerations to decide when and how to split your workloads between multiple MSK clusters.
Apache ZooKeeper and Kafka on Raft mode (KRaft)
Amazon MSK now offers KRaft mode support starting with Apache Kafka version 3.7, which replaces the traditional ZooKeeper-based metadata management. Apache ZooKeeper is a service included in Amazon MSK when you create a cluster. It manages the Apache Kafka metadata and acts as a quorum controller for leader elections. Although interacting with ZooKeeper is not a recommended pattern, some Kafka applications have a dependency to connect directly to ZooKeeper. During the migration to Amazon MSK, you may find a few of these applications in your organization. This could be because they use an older version of the Kafka client library or other reasons. For example, applications that help with Apache Kafka admin operations or visibility such as Cruise Control usually need this kind of access.
Before you choose your cluster type, you first need to check which offering provides direct access to the ZooKeeper cluster. As of writing this post, only Amazon MSK provisioned provides direct access to ZooKeeper.
How AnyCompany chooses their cluster types
AnyCompany first needs to collect some important requirements about each of their applications. The following table shows these requirements. The rows marked with an asterisk (*) are calculated based on the values in previous rows.
| Dimension | Ecommerce Platform | Marketing Platform | Gaming Application |
| Message rate per second | 150,000 | 50,000 | 1,000 |
| Maximum message size | 15 MB | 10 KB | 1 MB |
| Average message size | 30 KB | 10 KB | 15 KB |
| * Ingress throughput (average message size * message rate per second) | 4.5 GBps | 500 MBps | 15 MBps |
| Number of consumer groups | 2 | 2 | 1 |
| * Outgress throughput (ingress throughput * number of consumer groups) | 9 GBps | 1 GBps | 15 MBps |
| Number of topics | 100 | 200 | 10 |
| Average partition per topic | 100 | 50 | 5 |
| * Total number of partitions (number of topics * average partition per topic) | 10,000 | 10,000 | 50 |
| * Ingress per partition (ingress throughput / total number of partitions) | 450 KBps | 50 KBps | 300 KBps |
| * Outgress per partition (outgress throughput / total number of partitions) | 900 KBps | 100 KBps | 300 KBps |
| Data retention | 72 hours | 168 hours | 168 hours |
| * Total storage needed (ingress throughput * retention period in seconds) | 1,139.06 TB | 288 TB | 1.3 TB |
| Authentication | Plaintext and SASL/SCRAM | SASL/SCRAM and IAM | IAM |
| Need ZooKeeper access | Yes | No | No |
For the gaming application, AnyCompany opts for MSK Serverless since they don’t require in-house Kafka expertise, need no custom configurations, and their throughput falls within serverless quotas. The e-commerce platform, however, leverages their Kafka expertise and requires an MSK Provisioned cluster with standard brokers due to higher degree of customization requirements for brokers. For the marketing platform, AnyCompany selects MSK Provisioned with Express brokers, as it provides needed flexibility and throughput, while providing fully managed storage capabilities. The cost analysis demonstrates that Express brokers deliver superior value through lower TCO. This reduced TCO is achieved through two key factors: triple the performance capabilities and optimized storage utilization requiring fewer brokers. Together, these advantages result in a significant 50% reduction in infrastructure costs.
Conclusion
Selecting the best cluster type for your applications might initially seem complex, but this post outlines a process to help you work backward from your application requirements and available resources. MSK Provisioned clusters offer greater flexibility in scaling, configuration, and optimization. Meanwhile, MSK Serverless simplifies running Apache Kafka clusters without managing compute and storage capacity. Generally, I recommend starting with MSK Provisioned with Express brokers if your application doesn’t require overriding critical configurations. If you prefer a hands-off experience and your throughput needs are within MSK Serverless quotas, that cluster type is ideal. While splitting workloads across multiple MSK Serverless clusters can be beneficial, an MSK Provisioned cluster might be necessary if that’s not feasible. Operating an optimized MSK Provisioned cluster requires in-house Kafka expertise.
For further reading on Amazon MSK, visit the official product page.
About the authors
 Ali Alemi is a Streaming Specialist Solutions Architect at AWS. Ali advises AWS customers with architectural best practices and helps them design real-time analytics data systems that are reliable, secure, efficient, and cost-effective. He works backward from customers’ use cases and designs data solutions to solve their business problems. Prior to joining AWS, Ali supported several public sector customers and AWS consulting partners in their application modernization journey and migration to the cloud.
Ali Alemi is a Streaming Specialist Solutions Architect at AWS. Ali advises AWS customers with architectural best practices and helps them design real-time analytics data systems that are reliable, secure, efficient, and cost-effective. He works backward from customers’ use cases and designs data solutions to solve their business problems. Prior to joining AWS, Ali supported several public sector customers and AWS consulting partners in their application modernization journey and migration to the cloud.
 Ogbeide Uwagboe is an Associate Specialist Solutions Architect at Amazon Web Services (AWS). He specializes in streaming analytics services and is passionate about helping customers solve complex problems and enabling them to achieve their goals.
Ogbeide Uwagboe is an Associate Specialist Solutions Architect at Amazon Web Services (AWS). He specializes in streaming analytics services and is passionate about helping customers solve complex problems and enabling them to achieve their goals.
Audit History
Last reviewed and updated in March 2025 by Ogbeide Uwagboe | Associate Solutions Architect