AWS Big Data Blog
Split your monolithic Apache Kafka clusters using Amazon MSK Serverless
Today, many companies are building real-time applications to improve their customer experience and get immediate insights from their data before it loses its value. As the result, companies have been facing increasing demand to provide data streaming services such as Apache Kafka for developers. To meet this demand, companies typically start with a small- or medium-sized, centralized Apache Kafka cluster to build a global streaming service. Over time, they scale the capacity of the cluster to match the demand for streaming. They choose to keep a monolithic cluster to simplify staffing and training by bringing all technical expertise in a single place. This approach also has cost benefits because it reduces the technical debt, overall operational costs, and complexity. In a monolithic cluster, the extra capacity is shared among all applications, therefore it usually reduces the overall streaming infrastructure cost.
In this post, I explain a few challenges with a centralized approach, and introduce two strategies for implementing a decentralized approach, using Amazon MSK Serverless. A decentralized strategy enables you to provision multiple Apache Kafka clusters instead of a monolithic one. I discuss how this strategy helps you optimize clusters per your application’s security, storage, and performance needs. I also discuss the benefits of a decentralized model and how to migrate from a monolithic cluster to a multi-cluster deployment model.
MSK Serverless can reduce the overhead and cost of managing Apache Kafka clusters. It automatically provisions and scales compute and storage resources for Apache Kafka clusters and automatically manages cluster capacity. It monitors how the partitions are distributed across the backend nodes and reassigns the partitions automatically when necessary. It integrates with other AWS services such as Amazon CloudWatch, where you can monitor the health of the cluster. The choice of MSK Serverless in this post is deliberate, even though the concepts can be applied to the Amazon MSK provisioned offering as well.
Overview of solution
Apache Kafka is an open-source, high-performance, fault-tolerant, and scalable platform for building real-time streaming data pipelines and applications. Apache Kafka simplifies producing and consuming streaming data by decoupling producers from the consumers. Producers simply interact with a single data store (Apache Kafka) to send their data. Consumers read the continuously flowing data, independent from the architecture or the programming language of the producers.
Apache Kafka is a popular choice for many use cases, such as:
- Real-time web and log analytics
- Transaction and event sourcing
- Messaging
- Decoupling microservices
- Streaming ETL (extract, transform, and load)
- Metrics and log aggregation
Challenges with a monolithic Apache Kafka cluster
Monolithic Apache Kafka saves companies from having to install and maintain multiple clusters in their data centers. However, this approach comes with common disadvantages:
- The entire streaming capacity is consolidated in one place, making capacity planning difficult and complicated. You typically need more time to plan and reconfigure the cluster. For example, when preparing for sales or large campaign events, it’s hard to predict and calculate an aggregation of needed capacity across all applications. This can also inhibit the growth of your company because reconfiguring a large cluster for a new workload often takes longer than a small cluster.
- Organizational conflicts may occur regarding the ownership and maintenance of the Apache Kafka cluster, because a monolithic cluster is a shared resource.
- The Apache Kafka cluster becomes a single point of failure. Any downtime means the outage of all related applications.
- If you choose to increase Apache Kafka’s resiliency with a multi-datacenter deployment, then you typically must have a cluster with the same size (as large) in the other data center, which is expensive.
- Maintenance and operation activities, such as version upgrades or installing OS patches, take significantly longer for larger clusters due to the distributed nature of Apache Kafka architecture.
- A faulty application can impact the reliability of the whole cluster and other applications.
- Version upgrades have to wait until all applications are tested with the new Apache Kafka version. This limits any application from experimenting with Apache Kafka features quickly.
- This model makes it difficult to attribute the cost of running the cluster to the applications for chargeback purposes.
The following diagram shows a monolithic Apache Kafka architecture.

Decentralized model
A decentralized Apache Kafka deployment model involves provisioning, configuring, and maintaining multiple clusters. This strategy generally isn’t preferred because managing multiple clusters requires heavy investments in operational excellence, advanced monitoring, infrastructure as code, security, and hardware procurement in on-premises environments.
However, provisioning decentralized Apache Kafka clusters using MSK Serverless doesn’t require those investments. It can scale the capacity and storage up and down instantly based on the application requirement, adding new workloads or scaling operations without the need for complex capacity planning. It also provides a throughput-based pricing model, and you pay for the storage and throughput that your applications use. Moreover, with MSK Serverless, you no longer need to perform standard maintenance tasks such as Apache Kafka version upgrade, partition reassignments, or OS patching.
With MSK Serverless, you benefit from a decentralized deployment without the operational burden that usually comes with a self-managed Apache Kafka deployment. In this strategy, the DevOps managers don’t have to spend time provisioning, configuring, monitoring, and operating multiple clusters. Instead, they invest more in building more operational tools to onboard more real-time applications.
In the remainder of this post, I discuss different strategies for implementing a decentralized model. Furthermore, I highlight the benefits and challenges of each strategy so you can decide what works best for your organization.
Write clusters and read clusters
In this strategy, write clusters are responsible for ingesting data from the producers. You can add new workloads by creating new topics or creating new MSK Serverless clusters. If you need to scale the size of current workloads, you simply increase the number of partitions of your topics if the ordering isn’t important. MSK Serverless manages the capacity instantly as per the new configuration.
Each MSK Serverless cluster provides up to 200 MBps of write throughput and 400 MBps of read throughput. It also allocates up to 5 MBps of write throughput and 10 MBps of read throughput per partition.
Data consumers within any organization can usually be divided to two main categories:
- Time-sensitive workloads, which need data with very low latency (such as millisecond or subsecond) and can only tolerate a very short Recovery Time Objective (RTO)
- Time-insensitive workloads, which can tolerate higher latency (sub-10 seconds to minute-level latency) and longer RTO
Each of these categories also can be further divided into subcategories based on certain conditions, such as data classification, regulatory compliance, or service level agreements (SLAs). Read clusters can be set up according to your business or technical requirements, or even organizational boundaries, which can be used by the specific group of consumers. Finally, the consumers are configured to run against the associated read cluster.
To connect the write clusters to read clusters, a data replication pipeline is necessary. You can build a data replication pipeline many ways. Because MSK Serverless supports the standard Apache Kafka APIs, you can use the standard Apache Kafka tools such as MirrorMaker 2 to set up replications between Apache Kafka clusters.
The following diagram shows the architecture for this strategy.
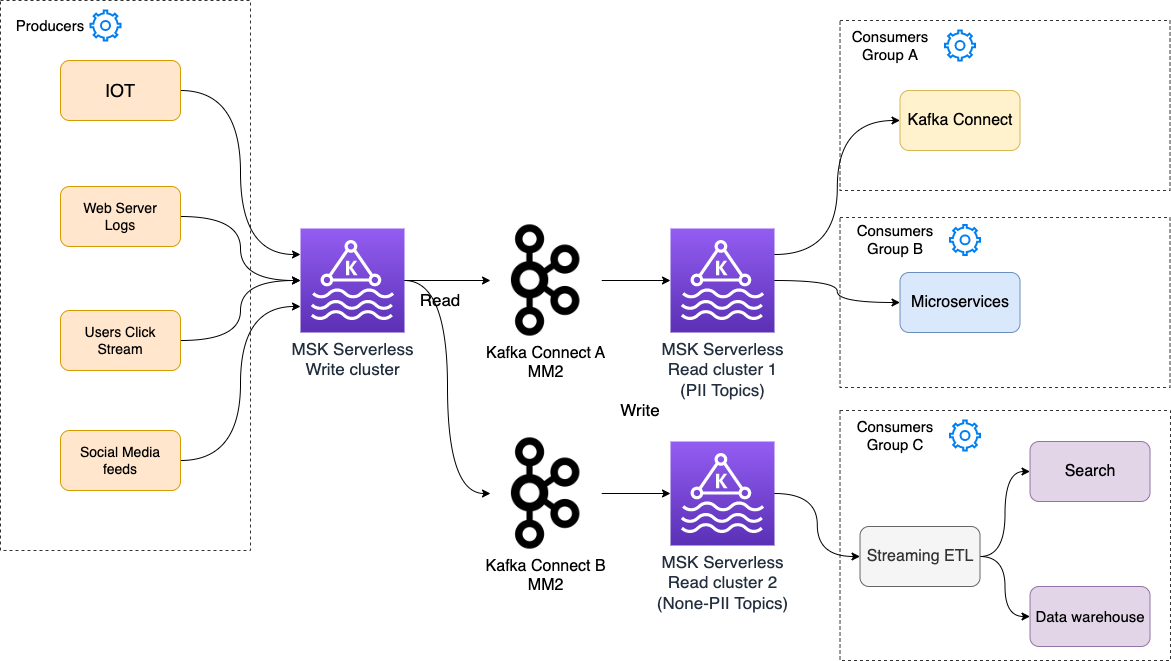
This approach has the following benefits:
- Producers are isolated from the consumers; therefore, your write throughput can scale independently from your read throughput. For example, if you have reached your max read throughput with existing clusters and need to add a new consumer group, you can simply provision a new MSK Serverless cluster and set up replication between the write cluster and the new read cluster.
- It helps enforce security and regulatory compliance. You can build streaming jobs that can mask or remove the sensitive fields of data events, such as personally identifiable information (PII), while replicating the data.
- Different clusters can be configured differently in terms of retention. For example, read clusters can be configured with different maximum retention periods, to save on storage cost depending on their requirements.
- You can prioritize your response time for outages for certain clusters over the others.
- For implementing increased resiliency, you can have fewer clusters in the backup Region by only replicating the data from the write clusters. Other clusters such as read clusters can be provisioned when the workload failover is invoked. In this model, with the MSK Serverless pricing model, you pay additionally for what you use (lighter replica) in the backup Region.
There are a few important notes to keep in mind when choosing this strategy:
- It requires setting up multiple replications between clusters, which comes with additional operational and maintenance complexity.
- Replication tools such as MirrorMaker 2 only support at-least-once processing semantics. This means that during failures and restarts, data events can be duplicated. If you have consumers that can’t tolerate data duplication, I suggest building data pipelines that support the exactly-once processing semantic for replicating the data, such as Apache Flink, instead of using MirrorMaker 2.
- Because consumers don’t consume data directly from the write clusters, the latency is increased between the writers and the readers.
- In this strategy, even though there are multiple Apache Kafka clusters, ownership and control still reside with one team, and the resources are in a single AWS account.
Segregating clusters
For some companies, providing access to Apache Kafka through a central data platform can create scaling, ownership, and accountability challenges. Infrastructure teams may not understand the specific business needs of an application, such as data freshness or latency requirements, security, data schemas, or a specific method needed for data ingestion.
You can often reduce these challenges by giving ownership and autonomy to the team who owns the application. You allow them to build and manage their application and needed infrastructure, rather than only being able to use a common central platform. For instance, development teams are responsible for provisioning, configuring, maintaining, and operating their own Apache Kafka clusters. They’re the domain experts of their application requirements, and they can manage their cluster according to their application needs. This reduces overall friction and puts application teams accountable to their advertised SLAs.
As mentioned before, MSK Serverless minimizes the operation and maintenance work associated with Apache Kafka clusters. This enables the autonomous application teams to manage their clusters according to industry best practices, without needing to be an expert in running highly available Apache Kafka clusters on AWS. If the MSK Serverless cluster is provisioned within their AWS account, they also own all the costs associated with operating their applications and the data streaming services.
The following diagram shows the architecture for this strategy.
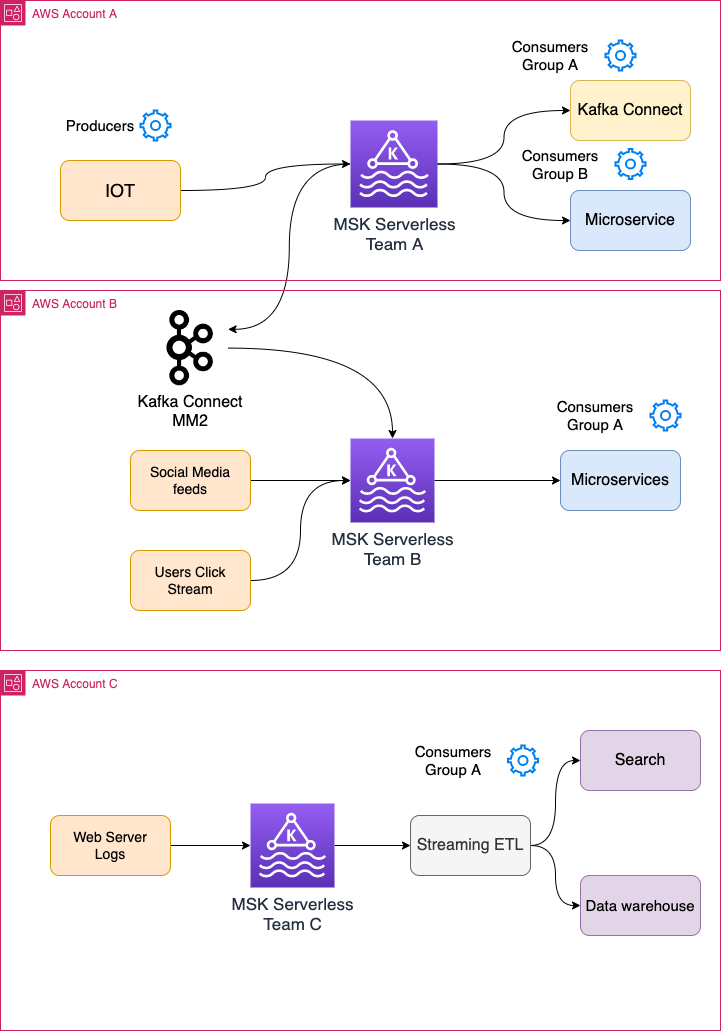
This approach has the following benefits:
- MSK Serverless clusters are managed by different teams; therefore, the overall management work is minimized.
- Applications are isolated from each other. A faulty application or downtime of a cluster doesn’t impact other applications.
- Consumers read data directly with low latency from the same cluster where the data is written.
- Each MSK Serverless cluster scales differently per its write and read throughput.
- Simple cost attribution means that application teams own their infrastructure and its cost.
- Total ownership of the streaming infrastructure allows developers to adopt streaming faster and deliver more functionalities. It may also help shorten their response time to failures and outages.
Compared to the previous strategy, this approach has the following disadvantages:
- It’s difficult to enforce a unified security or regulatory compliance across many teams.
- Duplicate copies of the same data may be ingested in multiple clusters. This increases the overall cost.
- To increase resiliency, each team individually needs to set up replications between MSK Serverless clusters.
Moving from a centralized to decentralized strategy
MSK Serverless provides AWS Command Line Interface (AWS CLI) tools and support for AWS CloudFormation templates for provisioning clusters in minutes. You can implement any of the strategies that I mentioned earlier via the methods AWS provides, and migrate your producers and consumers when the new clusters are ready.
The following steps provide further guidance on implementation of these strategies:
- Begin by focusing on the current issues with the monolithic Apache Kafka. Next, compare the challenges with the benefits and disadvantages, as listed under each strategy. This helps you decide which strategy serves your company the best.
- Identify and document each application’s performance, resiliency, SLA, and ownership requirements separately.
- Attempt grouping applications that have similar requirements. For example, you may find a few applications that run batch analytics; therefore, they’re not sensitive to data freshness and also don’t need access to sensitive (or PII) data. If you decide segregating clusters is the right strategy for your company, you may choose to group applications by the team who owns them.
- Compare each group of applications’ storage and streaming throughput requirements against the MSK Serverless quotas. This helps you determine whether one MSK Serverless cluster can provide the needed aggregated streaming capacity. Otherwise, further divide larger groups to smaller ones.
- Create MSK Serverless clusters per each group you identified earlier via the AWS Management Console, AWS CLI, or CloudFormation templates.
- Identify the topics that correspond to each new MSK Serverless cluster.
- Choose the best migration pattern to Amazon MSK according to the replication requirements. For example, when you don’t need data transformation, and duplicate data events can be tolerated by applications, you can use Apache Kafka migration tools such as MirrorMaker 2.0.
- After you have verified the data is replicating correctly to the new clusters, first restart the consumers against the new cluster. This ensures no data will be lost as the result of the migration.
- After the consumers resume processing data, restart the producers against the new cluster, and shut down the replication pipeline you created earlier.
As of this writing, MSK Serverless only supports AWS Identity and Access Management (IAM) for authentication and access control. For more information, refer to Securing Apache Kafka is easy and familiar with IAM Access Control for Amazon MSK. If your applications use other methods supported by Apache Kafka, you need to modify your application code to use IAM Access Control instead or use the Amazon MSK provisioned offering.
Summary
MSK Serverless eliminates operational overhead, including the provisioning, configuration, and maintenance of highly available Apache Kafka. In this post, I showed how splitting Apache Kafka clusters helps improve the security, performance, scalability, and reliability of your overall data streaming services and applications. I also described two main strategies for splitting a monolithic Apache Kafka cluster using MSK Serverless. If you’re using Amazon MSK provisioned offering, these strategies are still relevant when considering moving from a centralized to a decentralized model. You can decide the right strategy depending on your company’s specific needs.
For further reading on Amazon MSK, visit the official product page.
About the Author
 Ali Alemi is a Streaming Specialist Solutions Architect at AWS. Ali advises AWS customers with architectural best practices and helps them design real-time analytics data systems that are reliable, secure, efficient, and cost-effective. He works backward from customers’ use cases and designs data solutions to solve their business problems. Prior to joining AWS, Ali supported several public sector customers and AWS consulting partners in their application modernization journey and migration to the cloud.
Ali Alemi is a Streaming Specialist Solutions Architect at AWS. Ali advises AWS customers with architectural best practices and helps them design real-time analytics data systems that are reliable, secure, efficient, and cost-effective. He works backward from customers’ use cases and designs data solutions to solve their business problems. Prior to joining AWS, Ali supported several public sector customers and AWS consulting partners in their application modernization journey and migration to the cloud.