AWS Big Data Blog
Amazon MSK Replicator and MirrorMaker2: Choosing the right replication strategy for Apache Kafka disaster recovery and migrations
June 2026: This post was reviewed and updated.
Customers need to replicate data from their Apache Kafka clusters for a variety of reasons, such as compliance requirements, cluster migrations, and disaster recovery (DR) implementations. However, the right replication strategy can vary depending on the application context. In this post, we walk through the different considerations for using Amazon MSK Replicator over Apache Kafka’s MirrorMaker 2 and help you choose the right replication solution for your use case. We also discuss how to make Amazon Managed Streaming for Apache Kafka (Amazon MSK) applications resilient to disasters using a multi-Region Kafka architecture using MSK Replicator.
Challenges with choosing DR strategies
Customers create business continuity plans and DR strategies to maximize resiliency for their applications because downtime or data loss can result in losing revenue or halting operations. For applications processing real-time data, DR is even more critical, as applications are more latency sensitive and downtime has a higher cost to operations and users. DR planning helps the business continue running in the event of a disaster impacting a subset of their application architecture. For customers using Kafka as a core streaming and messaging service in their applications, planning for DR is an essential part of meeting goals for their application Recovery Time Objective (RTO) and Recovery Point Objective (RPO).
Amazon MSK is a fully managed service that makes it straightforward to build and run Kafka to process streaming data. Amazon MSK provides high availability by offering configurations that distribute brokers across multiple Availability Zones (AZs) within an AWS Region. A single MSK cluster deployment provides message durability through intra-cluster data replication. Data replication with a replication factor of 3 and min-ISR value of 2 along with the producer setting acks=all provides the strongest availability guarantees by forcing other brokers in the cluster to acknowledge receiving the data before the leader broker responds to the producer. This design provides robust protection against single broker failure as well as single-AZ failure.
For enhanced resilience within a single Region, Amazon MSK also offers Express brokers, which significantly improve Kafka cluster reliability, throughput, and recovery times. Express brokers include pay-as-you-go storage, automatic best-practice reliability configurations, no maintenance windows, and faster broker scaling and recovery times. This architecture reduces recovery time, minimizes the chance of errors with misconfigurations, and increases throughput, making your Kafka clusters more resilient across Availability Zones.
However, if an issue is impacting your applications or infrastructure across more than one Availability Zone, the architecture outlined in this post can help you prepare, respond, and recover from it.
For companies that can withstand a longer RTO but require a lower RPO on Amazon MSK, backing up data to Amazon Simple Storage Service (Amazon S3) is sufficient as a DR plan, though you will need to consider how to handle restarting the application after a DR failover. In this approach, you build a system to recover the data from Amazon S3 to Kafka topics (as described in Back up and restore Kafka topic data using Amazon MSK Connect). Depending on the volume of data being restored, it might take a long time to recover in this scenario. You must also consider how to handle consumer group offsets and whether to allow applications to consume from the latest offset in the restored Kafka topics. Due to the high RTO, as well as the complexity and challenges associated with this approach, most streaming use cases rely on the availability of the MSK cluster itself for their business continuity plan. In these cases, setting up MSK clusters in multiple Regions and configuring data replication between clusters provides the required business resilience and continuity.
Choosing the right replication solution: MSK Replicator vs MirrorMaker 2
AWS recommends two primary solutions for cross-Region Kafka replication: MSK Replicator and MirrorMaker 2. Understanding when to use each solution is crucial for designing an effective DR strategy.
MSK Replicator: For most MSK cluster replications in the same account
MSK Replicator is a fully managed serverless Kafka replication service that makes it straightforward to reliably replicate data across MSK clusters in different Regions or within the same Region. It also supports replicating data from external Apache Kafka clusters to MSK Express brokers with bidirectional replication of data and enhanced consumer group offset synchronization for both migration and disaster recovery scenarios. MSK Replicator is the recommended solution for application scenarios replicating data within the same AWS account. MSK Replicator has the following benefits:
- Replication between MSK clusters – It supports replicating between MSK clusters in the same AWS account (including active-active or active-passive DR architectures for Amazon MSK)
- Migrations to Amazon MSK – It enables simplified migrations from existing Kafka clusters on premises, in other clouds, or on self-managed Amazon Elastic Compute Cloud (Amazon EC2) deployments
- Bidirectional replication of data– It supports replicating data bidirectionally between two Kafka clusters with identical topic names
- Enhanced consumer group offset synchronization – It can synchronize consumer group offsets between clusters when producer and consumer applications are running across clusters. This allows for simplified migrations and active-active disaster recovery strategies where consumers and producers can switch between clusters independently without data loss or duplicate data processing
- Cross-cloud or hybrid cloud scenarios – It can replicate between Kafka running on-premises or on different cloud providers and Amazon MSK for disaster recovery or data analytics use cases
- No infrastructure management – MSK Replicator is fully serverless with automatic scaling and straightforward setup through the AWS Management Console, AWS Command Line Interface (AWS CLI), or APIs
- Built-in monitoring – MSK Replicator is integrated with Amazon CloudWatch metrics and logging
- Built-in high availability – As a managed service, it offers built-in fault tolerance across Availability Zones
MSK Replicator requires both Kafka clusters to be on Kafka version 2.8.1 or later. For external Kafka clusters, MSK Replicator requires SASL/SCRAM or mutual TLS (mTLS) authentication with TLS enabled. TLS can be enabled alongside your current authentication and encryption methods by enabling an additional listener for SASL/SCRAM or mTLS.
MirrorMaker 2: For scenarios when MSK Replicator cannot be used
MirrorMaker 2 (MM2) is the preferred solution for specific use cases that require more flexibility than MSK Replicator can provide. MM2 is a utility bundled as part of Kafka that helps replicate data between Kafka clusters using the Kafka Connect framework. It lacks the ability to replicate data and consumer group offsets bidirectionally, which MSK Replicator supports, but offers more control over exactly how replication is performed.We recommend MirrorMaker 2 for the following use cases:
- Cross-account replication – Replicating data between MSK clusters in different AWS accounts
- Using other authentication methods – When you cannot enable SASL/SCRAM or mTLS authentication on the external Kafka cluster or AWS Identity and Access Management (IAM) authentication in your MSK cluster due to technical or compliance requirements
- In general, we still recommend MSK Replicator for these scenarios, as IAM, SASL/SCRAM, and mTLS authentication can generally be enabled alongside existing authentication mechanisms by adding an additional listener to the cluster
- Custom replication policies – Advanced topic naming or transformation requirements, such as schema registry conversions
In the following sections, we discuss the architecture and deployment approaches for use cases where MSK Replicator and MirrorMaker 2 are the appropriate choices.
MSK Replicator solution overview
The following diagram illustrates one architecture for using MSK Replicator:
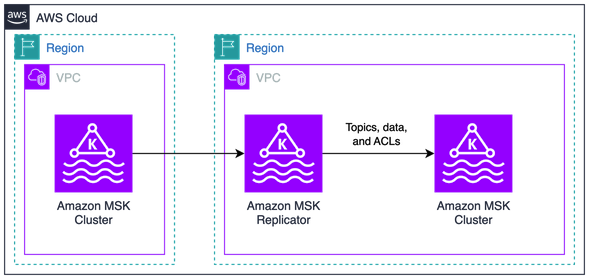
We create two MSK clusters. One is created in the primary Region, the other in the secondary Region as a standby cluster for disaster recovery. We deploy MSK Replicator in the secondary region to replicate topics, ACLs, data, and consumer group offsets from the primary cluster. In this solution, we showcase a single-direction replication for active-passive disaster recovery. This solution can also be extended for active-active disaster recovery scenarios. Our Kafka clients connect to the primary cluster and can be configured to connect to the secondary cluster in the event of a disaster recovery failover.
For details on implementation steps, refer to Introducing Amazon MSK Replicator – Fully Managed Replication across MSK Clusters in Same or Different AWS Regions. For details on disaster recovery scenarios, refer to Use replication to increase the resiliency of a Kafka streaming application across Regions. These resources provide the following benefits:
- Full deployment steps – Step by step deployment process for MSK Replicator between regions
- Comprehensive examples – Multiple deployment scenarios and configurations
- Failover process – Key steps in executing a disaster recovery failover when using MSK Replicator
We can also use MSK Replicator to migrate from external Kafka clusters running on-premises, in other clouds, or in Kafka-compatible SaaS offerings:
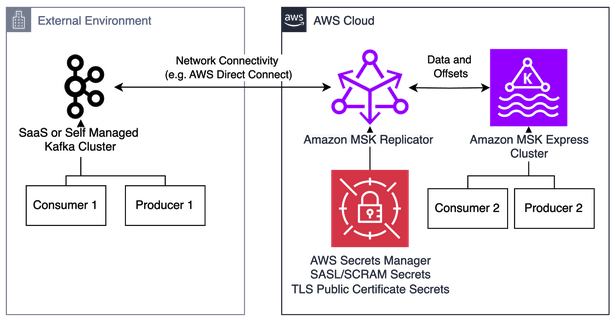
For more information on migrating to Amazon MSK Express brokers with MSK Replicator, refer to Migrate 3rd party and self-managed Apache Kafka clusters to Amazon MSK Express brokers with Amazon MSK Replicator. For a step-by-step walkthrough of deploying MSK Replicator for migrations, refer to the Amazon MSK Migration Workshop.
MirrorMaker2 solution overview
The following diagram illustrates an architecture for using MirrorMaker 2. In this case, we assume that the source cluster uses mTLS authentication and cannot enable SASL/SCRAM authentication to support MSK Replicator.
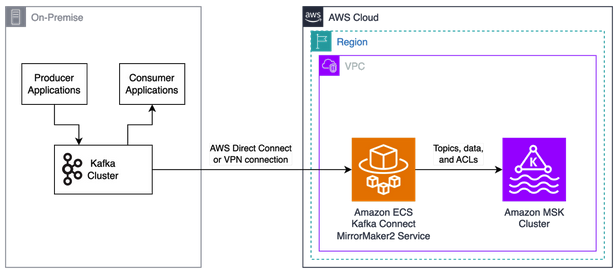
We create an MSK cluster in the primary Region with the existing Kafka cluster on premises. This Kafka cluster is analogous to Kafka clusters running in other clouds or in self-managed Kafka clusters on Amazon EC2. In this solution, we showcase a single-direction replication for cluster migration scenarios. Our Kafka clients interact with the on-premises Kafka cluster and can be migrated to run on AWS to interact with the MSK cluster.
Rather than manually configuring each component, we recommend using the automated deployment resources available in the following GitHub repository. These resources provide the following benefits:
- Infrastructure as code – Terraform for MSK clusters and supporting infrastructure
- Containerized Kafka Connect – Docker images optimized for AWS
- Amazon ECS with AWS Fargate deployment – Scalable, serverless container deployment using Amazon Elastic Container Service (Amazon ECS) with AWS Fargate
- Auto scaling configuration – Automatic scaling based on workload demands
- Comprehensive examples – Multiple deployment scenarios and configurations
Conclusion
Choosing the right replication solution depends on your specific requirements. We recommend using MSK Replicator for most migration and disaster recovery scenarios. MirrorMaker 2 is recommended for complex migrations that require custom replication policies or otherwise cannot use MSK Replicator due to technical limitations. These approaches provide a customizable set of options for the data redundancy and business continuity capabilities that are needed to meet regulatory compliance and disaster recovery requirements while minimizing operational overhead through automation and best practices.
For MSK Replicator deployments, refer to Use replication to increase the resiliency of a Kafka streaming application across Regions, Migrate 3rd party and self-managed Apache Kafka clusters to Amazon MSK Express brokers with Amazon MSK Replicator, and the Amazon MSK Migration Workshop to implement production-ready migration solutions.
For MirrorMaker 2 deployments, refer to the GitHub repository to benefit from automated deployment, monitoring, and scaling capabilities.