Amazon Web Services ブログ
Amazon Comprehend を使用してカスタムエンティティレコグナイザーを構築する
Amazon Comprehend は、非構造化テキストからキーフレーズ、場所、名前、組織、イベント、さらには感情の抽出などが行える自然言語処理サービスです。 お客様は通常、独自の部品コードや業界固有の用語など、ビジネスに固有の独自のエンティティタイプを追加することを望みます。2018 年 11 月、Amazon Comprehend の機能強化により、デフォルトのエンティティタイプをカスタムエンティティに拡張する機能が追加されました。さらに、カスタム分類機能により、ドキュメントを名前が付けられたカテゴリーにグループ化できます。たとえば、サポート E メールを部署ごとに、ソーシャルメディア記事を製品ごとに、または分析レポートを事業単位ごとにグループ化することができます。
概要
この記事では、カスタムエンティティレコグナイザーの構築方法について説明します。事前の機械学習の知識は必要ありません。カスタムエンティティレコグナイザーをトレーニングする前に、データを圧縮、フィルタリング、およびクリーンアップする必要がある例を示します。それ以外の場合は、次のステップバイステップの手順に従うだけで済みます。この手順は、データセットをすでに準備した状態で始めます。
この例では、Kaggle でホストされている Twitter のカスタマーサポートのデータセットを使用します。 データセットは主に短い発話で構成されています。これは、顧客とサポート担当者との間のチャット会話の典型的で一般的な例です。Twitter データセットからの発話のサンプルを次に示します。
@AppleSupport で返信が無視され、キーボードの下のタップされた通知が開きます???
@SpotifyCares ありがとう! Samsung Galaxy Tab A (2016) モデル SM-T280 のアンカー bluetooth スピーカーのバージョン 8.4.22.857 armv7 スピーカーからの距離が問題なのでしょうか?
データをフィルター処理し、「TMobileHelp」と「sprintcare」を含むツイートのみを保持して、特定のドメインとコンテキストに集中できるようにしました。comprehend_blog_data.zip ファイルからコンピューターにデータセットをダウンロードして解凍します。
チュートリアル
この例では、iPhone および Samsung Galaxy 携帯電話に関する情報を抽出するカスタムエンティティレコグナイザーを作成します。現在、Amazon Comprehend は両方のデバイスを「市販品」として認識しています。 このユースケースでは、より具体的にする必要があります。
特にスマートフォンデバイスを抽出できる必要があるため、抽出されたデータを一般的な市販品に制限すると効率的ではありません。この機能により、サービスプロバイダーはツイートからデバイス情報を簡単に抽出し、問題を関連するテクニカルサポートチームにルーティングすることができます。
Amazon Comprehend コンソールで、デバイスのカスタムエンティティレコグナイザーを作成します。[レコグナイザーをトレーニング] を選択します。
名前と、DEVICE などの [エンティティタイプ] ラベルを指定します。

カスタムエンティティ認識モデルをトレーニングするには、Amazon Comprehend にデータを提供する次の 2 つの方法のいずれかを選択できます。
- アノテーション: アノテーションリストを使用して、多数のドキュメント内のエンティティの場所を指定します。Amazon Comprehend は、エンティティ自体とそのコンテキストの両方からトレーニングできます。
- エンティティリスト: 限られたコンテキストのみを提供します。Amazon Comprehend がカスタムエンティティの識別についてトレーニングできるように、特定のエンティティリストからの選択のみを使用します。
簡単にするために、エンティティリストメソッドを使用します。多くの場合、アノテーションメソッドはより洗練された結果をもたらします。
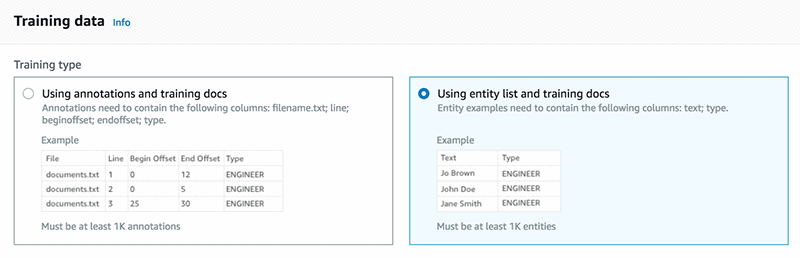
トレーニングデータセット内で少なくとも 1000 の一致がある一意のエンティティリストを指定します。entity_list.csv ファイルに含まれるデバイスのリストは次のとおりです。
初期データセットを分割し、テスト目的で約 1000 レコードを保持します。このレコードのサンプルは、後のステップでモデルをテストするために使用します。
残りのデータはトレーニングデータセット (raw_txt.csv) を構成します。原則として、可能な限り多くの関連データを含める必要があります。追加するデータが多いほど、モデルが自身をトレーニングするコンテキストを増やすことができます。
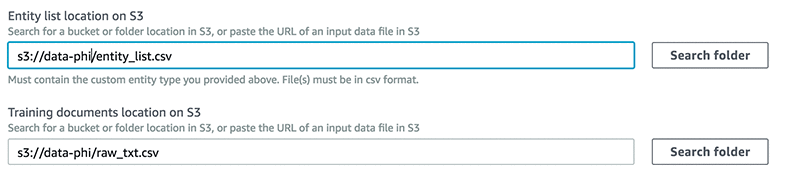
entity_list.csv および raw_txt.csv ファイルを S3 バケットにアップロードし、エンティティリストとトレーニングデータセットの場所のパスを指定します。
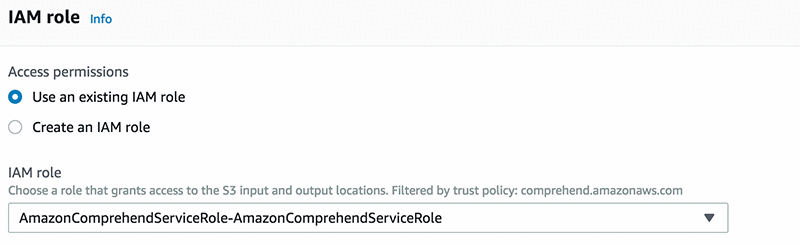
Amazon Comprehend に S3 バケットへのアクセス許可を付与するには、以下のスクリーンショットに示すように、IAM サービスにリンクされたロールを作成します。AmazonComprehendServiceRole-role を使用します。
[トレーニング] を選択します。このコマンドを使用すると、カスタムエンティティレコグナイザーを送信し、多数のモデルを検討し、ハイパーパラメータを調整し、相互検証をチェックして、モデルが堅牢であることを確認できます。これらはすべて、データサイエンティストがモデルの堅牢性を確保するために実行するアクティビティです。
モデルをテストする
次に、下のスクリーンショットに示すように、ジョブを作成してモデルをテストします。
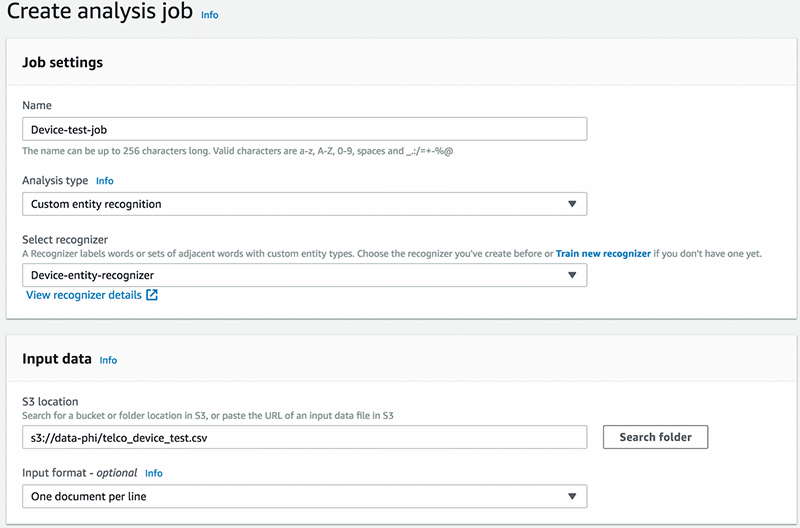
Amazon Comprehend が結果を保存する出力フォルダを指定します。

前のステップで作成した IAM ロールを選択し、[ジョブの作成] を選択します。
ジョブ分析が完了すると、出力 S3 バケットパスに JSON ファイルが作成されます。

次に、スキーマを作成してデータをクエリするには、AWS Glue と Amazon Athena をそれぞれ使用します。手順に従って、結果の出力パスを指定し、AWS Glue でデータベースを作成します。AWS Glue クローラは、次のスクリーンショットに示されています。

次に、Athena でいくつかのクエリを実行し、カスタムアノテーターが取得するエンティティを確認します。

Amazon Comprehend がさまざまなスペルの単語をさらにピックアップしていることに気付くかもしれません。これは、タイプミスやスペルの短縮が含まれるソーシャルメディアデータを分析する際に予想されることです。
まとめ
この投稿では、カスタムエンティティ認識モデルを構築し、検証を実行し、結果をクエリする方法を示しました。NLP モデルを構築するために習得しなければならない複雑で入り組んだ手順を知る必要なしに、この記事に従うことができます。
実際のシナリオでは、ツイートを監視するサービスプロバイダーは、Amazon Comprehend のカスタムエンティティ認識機能を活用して、ツイートで述べられているデバイスの種類に関する情報を抽出できます。また、Amazon Comprehend の組み込みセンチメント分析 API を使用して、ツイートのトーンやセンチメントを抽出し評価できる可能性もあります。
この機械学習アプリケーションは、重要なコンテキストを提供してお客様の意図の評価を行えます。これにより、Amazon Comprehend はインテリジェントなルーティングと修復の決定を行うことができます。全体として、このプロセスはサービスを改善し、顧客満足度を高めます。
Amazon Comprehend コンソールからカスタムエンティティを今すぐ試し、Amazon Comprehend ドキュメントで詳細な手順を確認してください。このソリューションは、Amazon Comprehend が利用できるすべてのリージョンで活用できます。詳細については、「AWS リージョンテーブル」を参照してください。
著者について
 Phi Nguyen は AWS のソリューションアーキテクトで、データレイク、分析、セマンティクステクノロジー、機械学習に特に重点を置いて、お客様のクラウドジャーニーを支援しています。空き時間には、サイクリングをしたり、息子のサッカーチームを指導したり、家族と一緒に自然散策を楽しんだりしています。
Phi Nguyen は AWS のソリューションアーキテクトで、データレイク、分析、セマンティクステクノロジー、機械学習に特に重点を置いて、お客様のクラウドジャーニーを支援しています。空き時間には、サイクリングをしたり、息子のサッカーチームを指導したり、家族と一緒に自然散策を楽しんだりしています。
 Ro Mullier はAWS のシニアソリューションアーキテクトです。お客様が AWS でさまざまなアプリケーション、特に機械学習ワークロードを実行する際のサポートを行っています。余暇には、家族や友人と過ごしたり、サッカーをしたり、機械学習に関するコンテストに参加したりしています。
Ro Mullier はAWS のシニアソリューションアーキテクトです。お客様が AWS でさまざまなアプリケーション、特に機械学習ワークロードを実行する際のサポートを行っています。余暇には、家族や友人と過ごしたり、サッカーをしたり、機械学習に関するコンテストに参加したりしています。