Amazon Web Services ブログ
Java と Amazon SageMaker Random Cut Forest アルゴリズムを使ってサーバーレスの異常検知ツールを構築する
ビジネスオーナーの方達が、共通して直面する問題の一つが、ビジネス上で普段と違う出来事に遭遇する、というものです。例えば、ユーザーが日ごろとは違う行動を取ったり、日々のトラフィックパターンに変化が起きるなどは、それらの問題の一部にすぎません。データやメトリクスが常に増加しつづける中、機械学習の力を借りて異常検知をすることは、積極的な問題特定のための、非常に有益な手法と言えます。
今回のブログでは、Amazon SageMaker と Java を使って、サーバーレスの異常検知ツールを作成する方法を解説していきます。Amazon SageMaker を使えば、機械学習モデルのトレーニングとホスティングを簡単に行え、ビルトインのアルゴリズムが、ビジネスに共通の問題を解決します。こういったビジネス上の特有な問題解決には、Random Cut Forest (RCF) 異常検知アルゴリズムを使います。Amazon Web Services ではお客様に、素早い対応力、低い IT コスト、そしてスケーリングなどを提供する、国際的なクラウドベースの製品を幅広く提案しています。ここでは、それらを使い、サーバーレスの異常検知ツールを構成する方法をご提示しましょう。Python は、機械学習の問題を追跡するための、最も普及したプログラミング言語の一つですが、多くのユーザーは、Java やその他の JVM ベース言語を使って、マイクロサービスやサーバーレスのアプリケーションを構築しているでしょう。このブログを読み終えた段階で、 お客様はAmazon SageMaker を使い、Java アプリケーションの中で機械学習を動作させられるようになると思います。
このブログ全体を通して、Java コードのスニペットを示しながら、本ツールの特徴的な側面に焦点を当てていきます。こちらから、構築およびデプロイされたコードを、ご自身の AWS アカウントのために取得することが可能です。
問題の概要
今回の例では、Java 開発者の Alice さんにご登場願います。彼女は、複数の AWS サービスの上層で走るビデオストリーミングプラットフォームを運営しており、顧客は数千人におよびます。Alice さんは、彼女のプラットフォームが上手く機能しているかを表示するメトリクスを追跡するため、ダッシュボードの設定を行っています。彼女にとって最も重要なメトリクスの 1 つは、次の図に示すような、プラットフォーム上のアクティブユーザーの総数です。
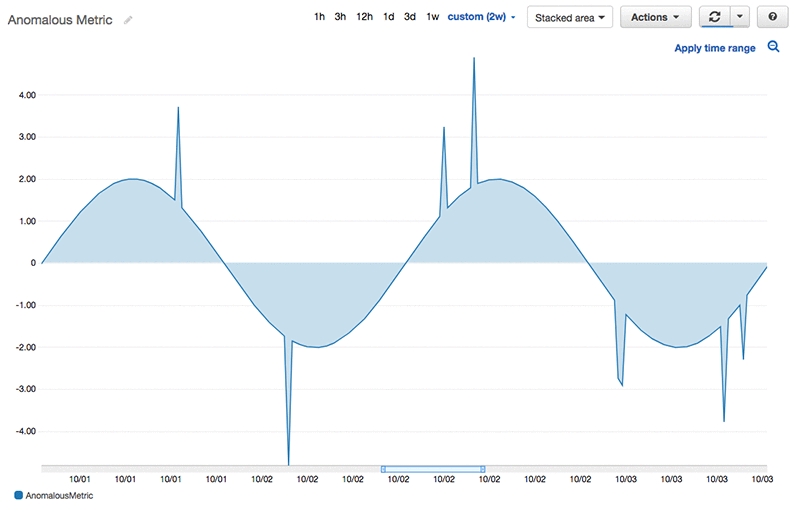
このメトリクスは、ユーザー数の基本的な日次パターンを示していますが、同時に、周期的な変化も見せています。 アクティブユーザー数の低い点、高い点、そして日常パターンから外れた動きなどは、すべて変則値として捉えられます。主に Alice さんが関心を寄せているのは、これらの変則的データポイントの根本原因を突き止めるということです。現在のところ彼女は、データ内の異常を見つけるための自動ツールは使っていません。代わりに、データのスパイクやくぼみ、周期性から外れた部分をみつけるため、マニュアル操作を行い多くの時間を費やしています。そして、この周期性に変化があることから、固定的なしきい値やそのウィンドウを設定しても、さほどの効果は上がりません。彼女には、もっと良い解決策が必要というわけです。
Alice さんの仕事を楽にする方法とは?
ソリューションのアーキテクチャ
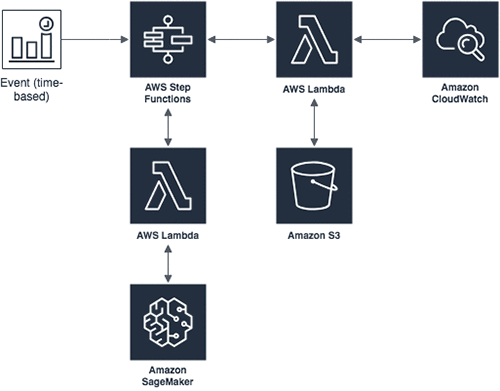
異常検知についてAlice さんが抱える問題を解決するには、まず、異常検知ツールの全構成ブロックを確認することが必要でしょう。
- Amazon SageMaker – メトリクスデータの履歴をもとにしたモデルの構築を容易にするには、Amazon SageMaker を使います。これにより、(前週の値を参考に) 現在の変則的なデータポイントを見つけ出すことができます。Amazon SageMaker Random Cut Forest のアルゴリズムは、データのトレンドを学習し、トレーニング後に異常値検出が可能になります。学習が済んだモデルを異常検知に使う方法は、2 つのオプションから選択できます。(1) モデルをエンドポイントにホストし、そのエンドポイントに対する推論を、HTTP リクエストを使って実行させます。(2) 新しいメトリクスのデータをバルク変換するため、バッチ変換ジョブを使います。取得データは 1 週間に一度必要なので、バッチ変換ジョブを使うのが、より便利な方法です。モデルをホスティングした後、エンドポイントを週に 1 度叩くのは、リソースの浪費となります。
- Amazon CloudWatch Events – Amazon CloudWatch Events は、毎週の変換ジョブを起動する、定期的なイベントをスケジュールするために使用します。基礎データのパターンは経時的に変化します。したがって、運用しているモデルも時折更新することが重要です。そのため、もう 1 つの CloudWatch Events ルールを使い、月に 1 度、トレーニングジョブを実行します。
- Amazon CloudWatch Metrics – Alice さんは、すべてのメトリクスを CloudWatch に格納しており、今回は、これをデータソースとして使います。さらに、変則的メトリクスのスコアを、バッチ変換ジョブから CloudWatch へ発行することで、Alice さんは、発生した異常値を容易に表示することが可能になります。
- Amazon S3 – Amazon SageMaker は、学習とバッチ変換ジョブのための入力データソースとして、Amazon S3 を使用します。CloudWatch のデータを取得・前処理した後、Amazon SageMaker のジョブに渡すため 、このデータを S3 内に格納します。
- AWS Step Functions – 全体として必要なステップは、データを CloudWatch から取得し、S3 にアップロード、学習とバッチ変換ジョブを起動した後、その結果を CloudWatch に戻すことだけです。これで、異常検知ツールが望み通りに機能します。このワークフローを働かせる新たなサービスを記述する代わりに、サーバーレステクノロジーを使いプロセスを簡素化し、AWS Step Functions によって、プロセスの自動化を行います。また、1 つは学習のため、もう 1 つはバッチ推論のために、ステートマシンを 2 つ使用します。これにより、上記の全ステップが正しい順序で実行され、誤動作が問題なく処理されることが保証されます。
- AWS Lambda – ここまで解説したアクションのすべては、AWS Lambda 関数として実行されます。この関数は、AWS Step Functions のステートマシンにより起動されます。すべての Lambda 関数は、Java 8 と AWS SDK を使っています。注: Amazon SageMaker による Amazon States Language サポートを含む最近のリリースでは、Lambda 関数の一部が置き換えられている場合があります。しかし、本ブログ内においては、問題に対する統一的な視点を得るために、Java 開発の側面だけに注目することにします。
次の図は、今回のアーキテクチャを示しています。
トレーニングジョブのステートマシン
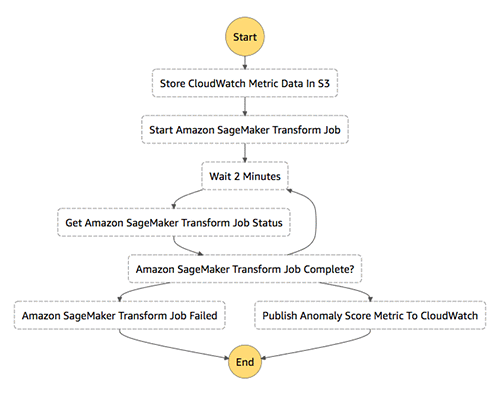
次の図は、トレーニング用ステートマシンを示しています。

- 最初の Lambda 関数 (Store CloudWatch Metric Data in S3) は、CloudWatch から、5 分の分解能を持つ 1 か月分のメトリクスデータを取得します。Lambda 関数により、タイムスタンプと各 5 分ごとのデータポイントが示す値が記述された CSV ファイルが作成され、S3 バケットにアップロードされます。
- 第 2 の Lambda 関数 (Start SageMaker Training Job) は、前のステップで作成された S3 データセットを使い、Amazon SageMaker のトレーニングジョブを起動します。このトレーニングジョブの起動は、非同期で実行され、ステートマシンは次の動作に移ります。
- Amazon SageMaker のトレーニングジョブが終了するのを待ちます。このジョブが失敗した場合は、その旨のレポートが送られ、実行は停止します。このジョブが正しく完了したら、次のステートへと移行します。
- 最後の Lambda 関数 (Create SageMaker Model) は、トレーニングジョブが作成・出力したモデルに基づき、Amazon SageMaker のモデルを作成します。
変換ジョブのステートマシン
次の図は、変換ジョブのステートマシンを示しています。
次に示すステップは、変換ジョブステートマシンの一部として実行されます。
- トレーニングステップ (Store CloudWatch Metric Data in S3) で示した Lambda 関数と同じものを再利用しますが、CloudWatch から取得するデータを 1 週間分に設定しなおします。
- 第 2 の Lambda 関数 (Start SageMaker Transform Job) は、(トレーニングステートマシンが作成した) 学習済みモデルを検索し最新のものを抽出します。その後、Amazon SageMaker のバッチ変換ジョブを非同期で起動します。
- バッチ変換ジョブが正常に終了するのを待ちます。
- 最後の Lambda 関数 (Publish Anomaly Score Metric to CloudWatch) は、バッチ変換ジョブが出力したスコアを取得します。この関数は、異常値を見分けるために、平均値から第 3 標準偏差より外にあるすべての値を変則的として扱う、シンプルかつ一般的な手法を使います。最後に、変則的だと分類されたすべてのデータポイントに 1 という数字が付加され、変則的ではないと分類されたものすべてに 0 が付加されて、CloudWatch に対し発行されます。変則的なスコアのメトリクスとして発行するタイムスタンプは、入力データセットから取得します。
両ステートマシンの動作が完了すると、Amazon CloudWatch コンソール内で新しいメトリクスを見る事ができます。この更新されたメトリクスは、オリジナルのメトリクス上に描画し、どこで異常値が発生したか確認することも可能です。これで、Alice さんは、オリジナルのメトリクスで調べたい特定のポイント上で、新たなメトリクスにズームインでき、Amazon CloudWatch Logs コンソールで、これらのデータポイントを利用できるようになりました。
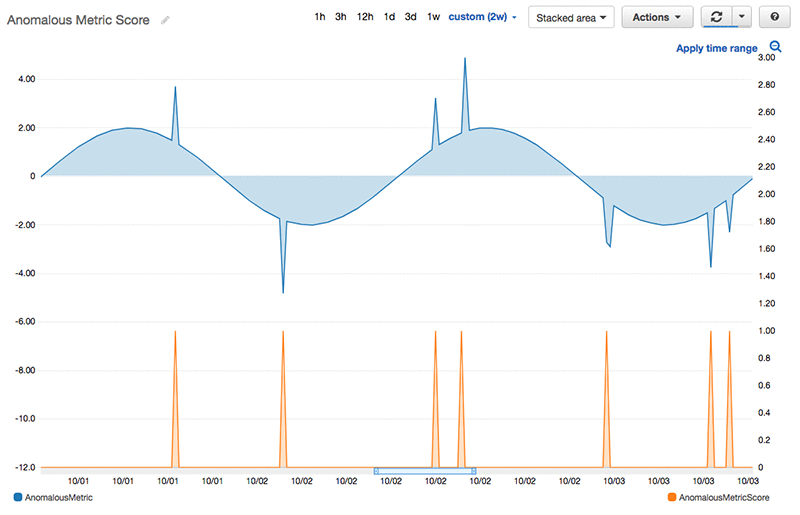
Alice さんは、CloudWatch に異常値を格納していますので、そこに用意された非常に豊富なアラートやモニタリングの機能を使うことができます。これで、何か異常が発生すれば、自動的に知らせを受けられます。同様に、彼女は Amazon SageMaker を使っているので、希望するなら将来、そこからモデルを選びオンライン推論をさせることも可能です (例えば、ホスティングしたエンドポイントに HTTP 要求をし、リアルタイムに近い異常値評価を行えます)。
結論
今回のブログでは、Amazon SageMaker を使い自動の異常検知ツールを構成する方法をご紹介しました。普段、何げなく行っている、工数のかかるツール構成をなくすのに有用なサービスを紹介し、それらを有意義な形でワークフローにまとめる方法を解説しました。また、リアルタイムに近い推論のためのモデルホスティングが必要ない場合に適した、最新の Amazon SageMaker リリースと、バッチ変換ジョブをご紹介しました。ここでの Lambda 関数は、すべて Java 8 により記述しています。これらのコード例と合わせて、今回のブログが Java 開発者の皆さまにとって、Amazon SageMaker を、サービスやアプリケーションに統合する際の一助となれれば幸いと思っております。
著者について
 Luka Krajcar は、AWS AI ラボチームのソフトウェア開発エンジニアです。彼は、ザグレブ大学の電気工学コンピューティング学部でコンピュータサイエンスの修士号を取得しています。仕事以外では、Luka はフィクションの読書、ランニング、ビデオゲームを楽しんでいます。
Luka Krajcar は、AWS AI ラボチームのソフトウェア開発エンジニアです。彼は、ザグレブ大学の電気工学コンピューティング学部でコンピュータサイエンスの修士号を取得しています。仕事以外では、Luka はフィクションの読書、ランニング、ビデオゲームを楽しんでいます。
 Julio Delgado Mangas は、AWS AI ラボチームのソフトウェア開発エンジニアです。彼は、Amazon CloudWatch や Amazon QuickSight SPICE エンジンなどの、AWS サービスのために貢献してきました。Amazon に参加するまでは、Human Brain Project で研究エンジニアとして働いていました。
Julio Delgado Mangas は、AWS AI ラボチームのソフトウェア開発エンジニアです。彼は、Amazon CloudWatch や Amazon QuickSight SPICE エンジンなどの、AWS サービスのために貢献してきました。Amazon に参加するまでは、Human Brain Project で研究エンジニアとして働いていました。
 Laurence Rouesnel は、Amazon AI ラボのアルゴリズム & プラットフォーム部門グループマネージャーです。 深層学習と Machine Learning の研究や製品に取り組む、エンジニアとサイエンティストのチームを率いています。余暇には、旅行、ハイキング、スキー、ウインドサーフィンなど、野外活動を楽しんでいます。
Laurence Rouesnel は、Amazon AI ラボのアルゴリズム & プラットフォーム部門グループマネージャーです。 深層学習と Machine Learning の研究や製品に取り組む、エンジニアとサイエンティストのチームを率いています。余暇には、旅行、ハイキング、スキー、ウインドサーフィンなど、野外活動を楽しんでいます。
 Chris Swierczewski は、AWS AI ラボチームの応用科学者で、Amazon SageMaker Latent Dirichlet Allocation や Amazon SageMaker Random Cut Forest アルゴリズムに貢献してきました。Amazon に加わる以前、Chris は、ワシントン大学で応用数学の博士課程を学ぶ学生でした。彼は、奥さんと愛犬リバーと共に、ハイキングやバックパッキング、キャンプなどを楽しんでいます。
Chris Swierczewski は、AWS AI ラボチームの応用科学者で、Amazon SageMaker Latent Dirichlet Allocation や Amazon SageMaker Random Cut Forest アルゴリズムに貢献してきました。Amazon に加わる以前、Chris は、ワシントン大学で応用数学の博士課程を学ぶ学生でした。彼は、奥さんと愛犬リバーと共に、ハイキングやバックパッキング、キャンプなどを楽しんでいます。
 Madhav Jha は、AWS AI ラボチームの応用科学者で、スケーラブルな機械学習アルゴリズム開発に、自身の劣線形アルゴリズムに関する知識で貢献しています。彼は、プログラミングが好きなコンピュータ理論科学者でもあります。彼は、コーヒーを飲みながら起業やテクノロジーに関する雑談をよくしています。
Madhav Jha は、AWS AI ラボチームの応用科学者で、スケーラブルな機械学習アルゴリズム開発に、自身の劣線形アルゴリズムに関する知識で貢献しています。彼は、プログラミングが好きなコンピュータ理論科学者でもあります。彼は、コーヒーを飲みながら起業やテクノロジーに関する雑談をよくしています。