Amazon Web Services ブログ
AWS Glue DataBrewを使ったレシピジョブの単一出力ファイルの作成
AWS Glue DataBrew は、350 以上のビルド済み変換処理を提供し、手作業で数日から数週間かけて組み込み変換処理を書かなければならないようなデータ準備作業(異常値のフィルタリング、フォーマットの標準化、無効な値の修正など)を自動化することが可能です。
DataBrew のレシピジョブで、これまでの出力ファイルが自動生成されるやり方に加えて、単一または複数の出力ファイルを選択できるようになりました。出力ファイルが小さい場合や、可視化ツールなど下流のシステムで簡単に利用するためには、単一の出力ファイルを生成することができます。また、レシピジョブを構成する際に、希望する出力ファイルの数を指定することもできます。これにより、可視化、データ分析、およびレポート作成のためにレシピジョブの出力を柔軟に管理することができ、同時に、ファイルの生成数が多くなりすぎることを防ぐことができます。場合によっては、効率的な保存と転送のために、出力ファイルのパーティションをカスタマイズすることもできます。
この記事では、Amazon Simple Storage Service (Amazon S3) のデータレイクからデータを接続して変換し、DataBrew コンソールから単一のファイルとして出力を構成する方法について説明します。
ソリューションの概要
下図は、ソリューション・アーキテクチャーを示したものです。

DataBrew は S3 データレイクから販売注文データを読み出し、データ変換を実行します。その後、DataBrew のジョブが最終的な出力を 1 つのファイルにまとめてデータレイクに書き戻します。
このソリューションを実装するには、以下のハイレベルな手順を実施します。
- データセットを作成
- データセットを使用して DataBrew プロジェクトを作成
- 変換レシピを作成
- 全データで DataBrew のレシピジョブを作成・実行
前提条件
このソリューションを構築するには、AWS アカウントと、ソリューションの一部として必要なリソースを作成するための適切な権限が必要です。
また、Amazon S3 にデータセットが必要です。今回のユースケースでは、仮のデータセットを使用します。データファイルは GitHub からダウンロードすることができます。Amazon S3 コンソールで、3 つの CSV ファイルすべてを S3 バケットにアップロードします。
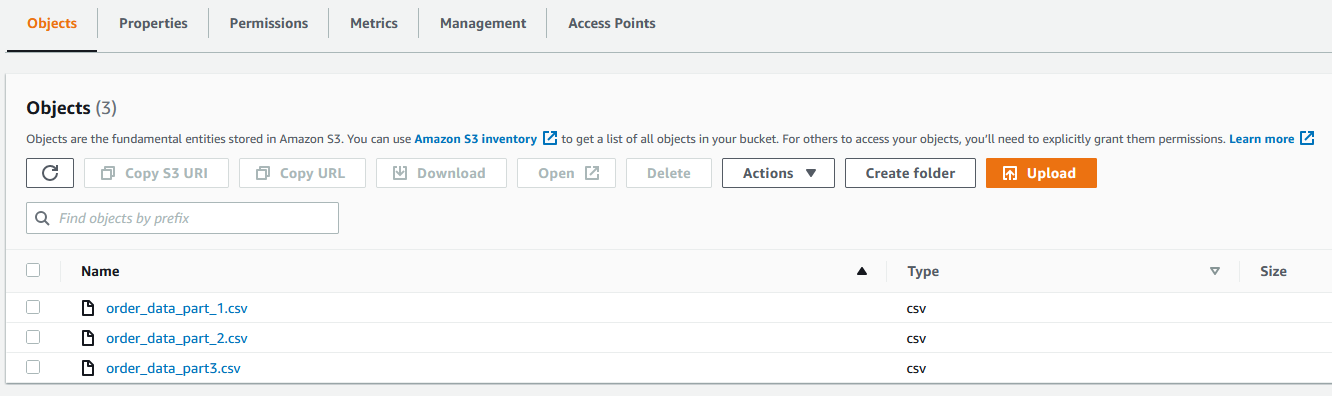
データセットを作成
DataBrew でデータセットを作成するには、以下のステップを実施します。
- DataBrew コンソールのデータセットページで、新しいデータセットの接続を選択します。

- データセット名には、名前(例:
order)を入力します。 - 前提条件の手順の一部としてデータファイルをアップロードした S3 バケットパスを入力します。
- フォルダ全体を選択するを選択します。

- ファイルタイプは、CSV を選択し、CSV 区切り記号はカンマ(,)を選択します。
- 列ヘッダー値は、最初の行をヘッダーとして扱うを選択します。
- データセットの作成を選択します。

データセットを使用して DataBrew プロジェクトを作成
DataBrew プロジェクトを作成するには、以下の手順を実行します。
- DataBrew コンソールのプロジェクトページで、プロジェクトを作成を選択します。

- プロジェクト名には、
valid-orderと入力します。 - アタッチされたレシピで、新しいレシピを作成を選択します。
レシピ名は自動的に入力されます (valid-order-recipe)。

- データセットの選択で、マイデータセットを選択します。
orderデータセットを選択します。
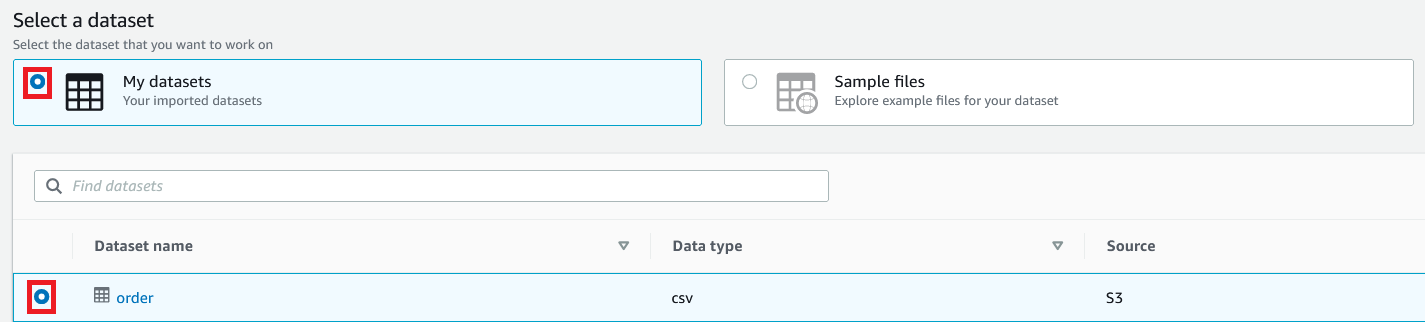
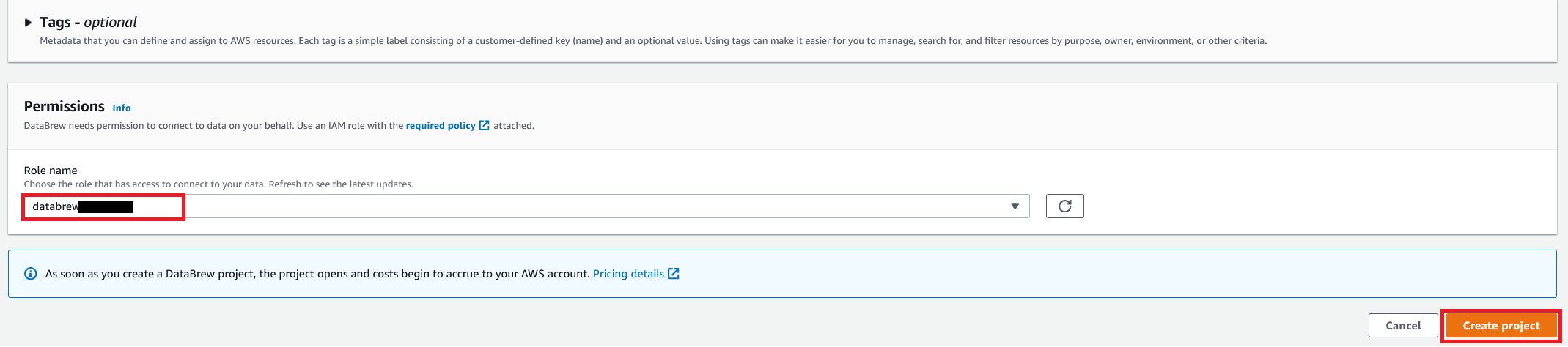
- ロール名には、DataBrewで使用する AWS Identity and Access Management (IAM) のロールを選択します。
- プロジェクトを作成 を選択します。
500 行の order テーブルとともに、成功メッセージが表示されます。
プロジェクトが開かれると、DataBrew の対話型セッションが作成されます。DataBrew はサンプリング選択設定に基づいて、サンプルデータを取得します。
変換レシピを作成
DataBrew のインタラクティブセッションでは、350 以上の組み込み変換処理を使用して、データのクレンジングと正規化を行うことができます。この投稿では、DataBrew を使っていくつかの変換を行い、注文金額が 0 ドルより大きい有効な注文のみをフィルタリングしています。
これを行うには、以下の手順を実行します。
- 列 を選択し、削除を選択します。

- ソース列には、
order_id、timestampおよびtransaction_dateの 3 つのカラムを選択します。 - 適用を選択します。
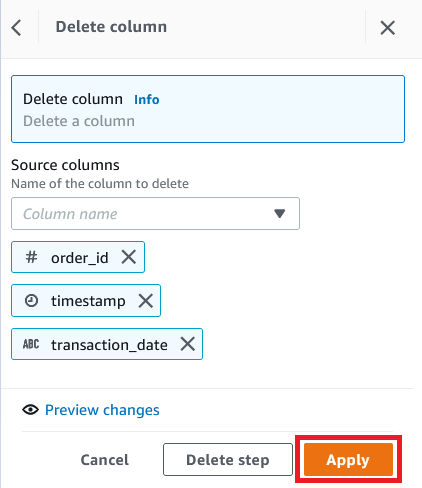
- 0 ドルより大きい
金額に基づいて行をフィルタリングし、適用を選択し、レシピのステップとして条件を追加します。

- 状態に応じてカスタムのソートを作成するには、ソートを選択し、昇順を選択します。

- Source に、
state_nameという列を選択します。 - Sort by custom values を選択します。
- 州名のリストをカンマで区切って入力します。
- 適用を選択します。
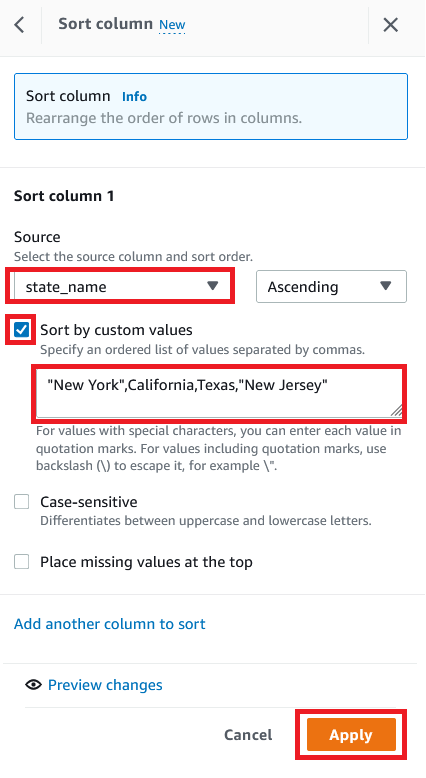
次のスクリーンショットは、私たちのデータセットに適用した完全なレシピです。

全データで DataBrew のレシピジョブを作成・実行
レシピの準備ができたので、DataBrew のレシピジョブを作成し、実行します。
- プロジェクトの詳細ページで、ジョブを作成を選択します。
- ジョブ名に、
valid-orderと入力します。

- 出力先で、Amazon S3 を選択します。
- 出力ファイルを保存する S3 パスを入力します。
- 設定を選択します。

File output options では、複数のオプションがあります。
-
- Autogenerate files – これはデフォルトのファイル出力設定で、複数のファイルを生成します。通常、最も速いジョブ実行時間になります。
- Single file output – このオプションは、単一の出力ファイルを生成します。
- Multiple file output – このオプションで、データを分割するファイルの最大数を指定します。
- この投稿では、Single file output を選択します。
- 保存を選択します。

- ロール名は、DataBrew で使用する IAM ロールを選択します。
- ジョブを作成し実行するを選択します。
- ジョブページに移動し、
valid-orderのジョブが完了するのを待ちます。
- 出力用 S3 バケットに移動し、そこに 1 つの出力ファイルが保存されていることを確認します。

クリーンアップ
今後の課金を避けるため、このチュートリアルで作成したすべてのリソースを削除してください。
注)下記リソースを削除しない場合、継続的な課金がなされますのでご注意ください。
- レシピジョブを削除(
valid-order) - S3 バケットに保存されているファイルを空にし、バケットを削除
- プロジェクトやジョブの一部として作成された IAM ロールを削除
- プロジェクトを削除(
valid-orderとそれに関連するレシピvalid-order-recipe) - DataBrew のデータセットを削除
結論
この投稿では、S3 データレイクからデータを接続して変換し、DataBrew データセットを作成する方法を解説しました。また、データレイクから DataBrew にデータを取り込み、シームレスに変換を適用し、準備したデータを単一の出力ファイルとしてデータレイクに書き戻す方法を解説しました。
詳しくは、AWS Glue DataBrew レシピジョブの作成と操作方法を参照してください。
原文はこちらです。