Amazon Web Services ブログ
Amazon Elasticsearch Service をはじめよう: シャード数の算出方法
Dr. Jon Handler (@_searchgeek) は検索技術にスペシャライズした Amazon Web Services のプリンシパルソリューションアーキテクトです。
Elasticsearch および Amazon Elasticsearch Service(Amazon ES) のブログポストシリーズへようこそ。ここでは今後もAWS上でElasticsearchをはじめるにあたって必要な情報を提供していく予定です。
いくつのシャードが必要?
Elasticsearchは、大量のデータを、シャードと呼ばれる細かいユニットに分割し、それらのシャードを複数のインスタンスに分散して保持します。Elasticsearchではインデックス作成の際にシャード数を設定します。既存のインデックスのシャード数を変更することは出来ないため、最初のドキュメントをインデックスに投入する前にシャード数を決定しなければなりません。最初はインデックスのサイズからシャード数を算出するにあたって、それぞれのシャードのサイズの目安を30GBにします。
シャード数 = インデックスのサイズ / 30GB
インデックスのサイズ算出に関しては、AWS Solutions Architect ブログ: 【AWS Database Blog】Amazon Elasticsearch Service をはじめよう: インスタンス数の見積もり方法をご覧ください。
データの送信やクエリをクラスタに対して行っていく中で、クラスタのパフォーマンスを元に、継続的にリソースのユーセージを評価しながら、シャード数を調整していきます。
シャードとは?
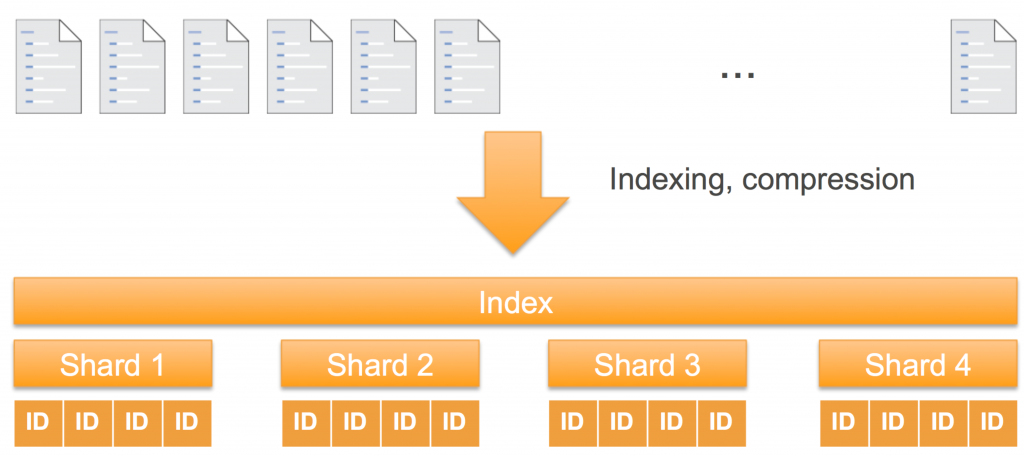
サーチエンジンには2つの役割があります: ドキュメントを元にしたインデックスの作成と、インデックスの中からマッチしたドキュメントを引き当てる検索です。インデックスが小さければ一つのデータ構造で一台のマシンで事足りるでしょう。しかし、大量のドキュメントにおいては、インデックスを保存するのに一台のマシンでは足りませんし、ピースに分割されたインデックスから検索結果を求めるためのコンピュート能力も足りません。Elasticsearchではこれらのピースのことをシャードと呼びます。それぞれのドキュメントは計算結果に基いてシャードにルーティングされます。デフォルトではドキュメントのIDのハッシュ値に基づいたルーティングになります。
シャードは ストレージ(storage) の単位であり、また 処理(computation) の単位でもあります。Elasticsearchはシャードを独立した形でクラスタ内のインスタンスにデプロイし、インデックスの処理をそれぞれで並列に行います。Elasticsearchという名前の通り”elastic”なものであると言えるでしょう。クラスタにインスタンスを追加する場合、Amazon Elasticsearch Serviceは自動的にシャードのリバランスを行い、クラスタ内のインスタンスにシャードを再配置します。
ストレージ(storage)においては、シャードはそれぞれ別のもの(distinct)です。シャード内のドキュメントは、他のシャードに重複して保持されることはありません。このアプローチによってシャード毎の独立性を保っています。
処理(computation)においても、シャードはそれぞれ別のもの(distinct)です。それぞれのシャードはドキュメントが処理されて生成されたApache Lucene indexのインスタンスです。インデックスには全てのシャードが含まれるため、クエリや更新リクエストのプロセスにおいて、それぞれのシャードはお互いに協調して機能する必要があります。クエリのプロセスにおいては、Elasticsearchはインデックス内の全てのシャードにクエリをルーティングします。それぞれのシャードはローカルで個別に処理を行い、それぞれの結果をアグリゲートして最終的にレスポンスします。書き込みリクエストにおいては(ドキュメントの追加、もしくは、既存のドキュメントの更新)、Elasticsearchはリクエストを適切なシャードにルーティングします。
Elasticsearchには2つの種類のシャードがある
Elasticsearchには2つの種類のシャードがあります – プライマリシャードとレプリカシャードです。プライマリシャードは全ての書き込みリクエストを受け付けます。プライマリシャードは新しく追加されたドキュメントをレプリカにパスします。デフォルトでは、書き込みがレプリカに確認(acknowledge)されるのを待ってから呼び出し元に書き込み成功のレスポンスを行います。プライマリとレプリカシャードはデータの保存に冗長性をもたらし、データのロスを起こりにくくします。

この図の例では、Elasticsearchクラスタは3つのデータインスタンスを保持しています。緑と青の2つのインデックスがあり、それぞれ3つのシャードがあります。それぞれのシャードのプライマリは赤枠で囲われています。それぞれのシャードにはレプリカがあり、それらに枠はありません。Elasticsearchはいくつかのルールを元にシャードをインスタンスに配置します。最も基本的なルールとして、プライマリとレプリカのシャードを同じインスタンスに配置しない、というものが挙げられます。
最初にストレージにフォーカスする
お客様のワークロードには2つの種類があります: シングルインデックスとローリングインデックス。シングルインデックスのワークロードは、全てのコンテンツを保持する”source of truth”な外部のリポジトリを使い、データは一つのインデックスに保持されます。ローリングインデックスのワークロードは、データを継続的に受け取り、データはタイムスタンプによって(通常は1日24時間)異なるインデックスに保持されます。
それぞれのワークロードにおけるシャーディングの計算のスタート地点は、インデックスに必要なストレージサイズです。それぞれのシャードをストレージの単位として扱うと、いくつのシャードが必要になるかのベースラインを見出すことが出来ます。シングルインデックスのワークロードであれば、トータルのストレージ容量を30GBで割って最初に必要なシャード数を算出します。ローリングインデックスのワークロードの場合は一期間のインデックスのサイズを30GBで割ることで最初のシャード数を算出します。
シングルシャードを恐れるな!
もし、あなたのインデックスのサイズが30GB以下であるのであれば、一つのシャードのみを使うべきです。”more is better”というガッツフィーリングをお持ちの方もいらっしゃいますが、誘惑を断ち切りましょう! シャードは処理とストレージのエンティティであり、あなたが追加するシャードによってインデックスに対するリクエストはアディショナルなCPUに分散されて処理されます。必要以上のプロセッサーを使うことで、その管理や処理結果の結合などに追加で処理が必要になり、パフォーマンスが下がることにつながります。scatter-gatherなクエリおよびレスポンスにおけるネットワークのオーバーヘッドもかかるでしょう。
シャード数の設定
Elasticsearchのインデックス作成APIを叩いく際にシャード数を設定します。Amazon Elasticsearch ServiceでのAPIコールは以下のようになります:
>>> curl –XPUT https://search-tweets-EXAMPLE.us-west-2.es.amazonaws.com/tweet -d '{
"settings": {
"index" : {
"number_of_shards": 2,
"number_of_replicas": 1
}
}
}'
シングルインデックスのワークロードの場合、この設定を行うのはインデックスを最初に作成する際の1回のみですが、ローリングインデックスのワークロードの場合、インデックスを定期的に作成することになります。その場合は _template APIを使って、テンプレートにマッチする新しいインデックスには自動的に設定が適用されるようにします。
>>> curl –XPUT https://search-tweets-EXAMPLE.us-west-2.es.amazonaws.com/_template/template1 -d '{
"template": "logs*",
"settings": {
"index" : {
"number_of_shards": 2,
"number_of_replicas": 1
}
}
}'
この例では、”log”というプレフィックスで作られたインデックスは、2つのシャードと1つのレプリカを保持します。
ワークロードに合わせた調整
今回カバーした内容は最もシンプルなシャーディングに関することでしたが、今後のポストではユーセージを元にしたシャード数の調整といったネクストレベルなところまで踏み込む予定です。もし、はじめたばかりであれば、30GBでインデックスのサイズを割り算することでシャード数を算出しましょう。データをインデックスに投入する前にシャード数を設定するのをお忘れなく。
あなたのシャーディングアドベンチャーのエピソードを是非お聞かせください!
Amazon Elasticsearch Serviceのより詳細な情報に関しては、https://aws.amazon.com/jp/elasticsearch-service/ をご覧ください。
原文:Get Started with Amazon Elasticsearch Service: How Many Shards Do I Need?(翻訳:篠原 英治)