AWS Database Blog
Get Started with Amazon Elasticsearch Service: How Many Shards Do I Need?
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details.
Welcome to this introductory series on Elasticsearch and Amazon Elasticsearch Service (Amazon ES). In this and future articles, we provide the basic information that you need to get started with Elasticsearch on AWS.
How many shards?
Elasticsearch can take in large amounts of data, split it into smaller units, called shards, and distribute those shards across a dynamically changing set of instances. When you create an Elasticsearch index, you set the shard count for that index. Because you can’t change the shard count of an existing index, you have to make the decision on shard count before sending your first document. To begin, set the shard count based on your calculated index size, using 30 GB as a target size for each shard.
Number of Shards = Index Size / 30GB
To learn how to calculate your index size, see the blog post Get Started with Amazon Elasticsearch Service: How Many Data Instances Do I Need?
As you send data and queries to the cluster, continuously evaluate the resource usage and adjust the shard count based on the performance of the cluster.
What is a shard?
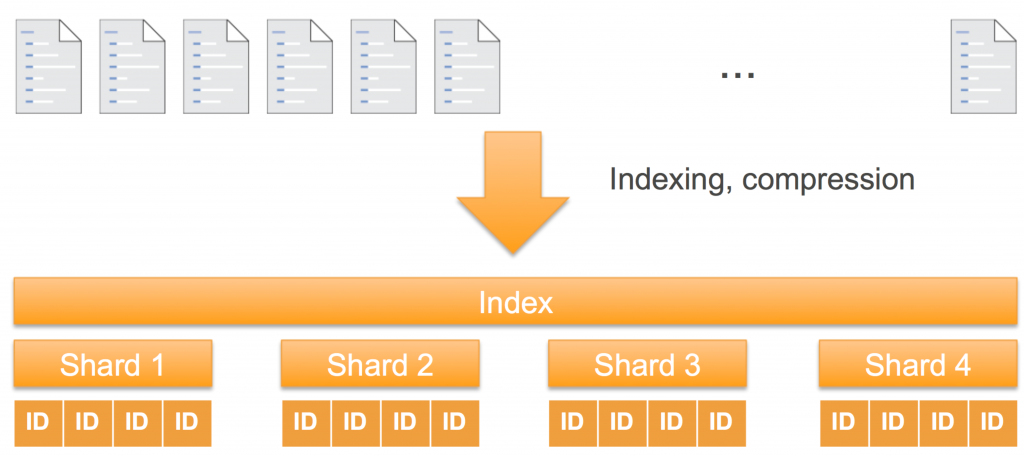
A search engine has two jobs: Create an index from a set of documents, and search that index to compute the best, matching documents. If your index is small enough, a single data structure on a single machine can easily store that index. For larger document sets, in cases where a single machine is not large enough to hold the index, or in cases where a single machine can’t compute your search results, the index is split into pieces. These pieces are called shards in Elasticsearch. Each document is routed to a shard that is calculated, by default, by using a hash of that document’s ID.
A shard is both a unit of storage and a unit of computation. Elasticsearch deploys shards independently to the instances in the cluster to parallelize the storage and processing for the index. And it does this elastically (hence the “elastic” in the name “Elasticsearch”). If you add more instances to a cluster, Amazon Elasticsearch Service automatically rebalances the shards of the cluster, moving them between instances.
As storage, shards are distinct from one another. The document set in one shard doesn’t overlap the document set in any other shard. This approach makes shards independent for storage.
As computational units, shards are also distinct from one another. Each shard is an instance of an Apache Lucene index that computes results on the documents it holds. Because all of the shards comprise the index, they must function together to process each query and update request for that index. To process a query, Elasticsearch routes the query to all shards in the index. Each shard computes its response locally and then these responses are aggregated for the final response. To process a write request (a document addition or an update to an existing document), Elasticsearch routes the request to the appropriate shard.
Elasticsearch has two different kinds of shards
There are two kinds of shard in Elasticsearch—primary shards and replica shards. The primary shard receives all writes first. It passes new documents off to all replicas for indexing. By default, it then waits for the replicas to acknowledge the write before returning success to the caller. The primary and a replica shard are redundant storage for the data, hardening the cluster to the loss of an instance.

In the example shown, the Elasticsearch cluster has three data instances. There are two indices, green and blue, each of which has three shards. The primary for each shard is outlined in red. Each shard also has a single replica, shown with no outline. Elasticsearch maps shards to instances based on a number of rules. The most basic rule is that primary and replica shards are never put onto the same instance.
Focus on the storage first
We’ve described two kinds of workloads that our customers run: single index and rolling index. Single index workloads use an external “source of truth” repository that holds all the content. Rolling index workloads receive data continuously. That data is put into a changing set of indices, based on a timestamp and an indexing period—usually one 24-hour day.
With each of these workloads, the place to start calculating sharding is the storage size required for the index. Treat each shard as a unit of storage first, and you can find a baseline for how many shards you need. For single-index workloads, divide the total storage by 30 GB to get the initial shard count. For rolling index workloads, divide a single time period’s index size by 30 GB to get the initial shard count.
Don’t be afraid of using a single shard!
If you have less than 30 GB of data in your index, you should use a single shard for your index. Some people have a gut feeling that “more is better.” Resist the temptation! Shards are both computational and storage entities. Each shard you add to an index distributes the processing of requests for that index across an additional CPU. Performance decreases because you’ll be using more processors than needed, requiring extra computation to manage and combine the results. You will also add network overhead for the scatter-gather of the query and responses.
Set the shard count
You set the shard count when you create each index, with the Elasticsearch create index API action. With Amazon Elasticsearch Service, an API call might be:
>>> curl –XPUT https://search-tweets2-ldij2zmbn6c5oijkrljEXAMPLE.us-west-2.es.amazonaws.com/tweet -d ‘{
“settings”: {
“index” : {
“number_of_shards”: 2,
“number_of_replicas”: 1,
}
}
}’
If you have a single index workload, you only have to do this once, when you create your index for the first time. If you have a rolling index workload, you create a new index regularly. Use the _template API to automate applying settings to all new indices whose name matches the template.
>>> curl –XPUT https://search-tweets2-ldij2zmbn6c5oijkrljEXAMPLE.us-west-2.es.amazonaws.com/_template/template1 -d ‘{
“template”: “logs*”,
“settings”: {
“index” : {
“number_of_shards”: 2,
“number_of_replicas”: 1,
}
}
}’
Be sure to replace the endpoint and template name in these examples with your endpoint and template name.
Any new index that you create whose name has “logs” as a prefix will have two shards and one replica.
Adjust according to workload
What we’ve covered so far is the simplest layer of the sharding question. In a future post, we’ll cover the next level down: adjusting shard count based on usage. If you’re just getting started, use index size divided by 30 GB to start when selecting a shard count. Make sure to set the shard count on your index before sending any data to it.
Let me know about your adventures in sharding!
For more information, take a look at Amazon Elasticsearch Service’s details page.
About the Author
 Dr. Jon Handler (@_searchgeek) is an AWS solutions architect specializing in search technologies. He works with our customers to provide guidance and technical assistance on database projects, helping them improve the value of their solutions when using AWS.
Dr. Jon Handler (@_searchgeek) is an AWS solutions architect specializing in search technologies. He works with our customers to provide guidance and technical assistance on database projects, helping them improve the value of their solutions when using AWS.