Amazon Web Services ブログ
AI コーディングに潜む非効率性とその発見方法
本記事は 2026 年 2 月 23 日に公開された Joe Hsu, Shweta Garg, Murali Krishna Ramanathan による “The hidden inefficiencies in AI coding (and how we find them)” を翻訳したものです。
タスクが完了しました。コードはコンパイルされ、テストはグリーンになり、全員が次へ進みます。しかし、その「合格」したタスクが、エージェントがすぐそこにあるファイルを見つけられなかったために 17 ターンもかかっていたとしたら?絶対に成功しないシェルコマンドのパターンでリトライを繰り返していたとしたら?
ベンチマークはこれを捉えられません。合格/不合格のメトリクスは成功を確認して次へ進むだけです。私たちはより深く、エージェントが最終的にどこに到達したかだけでなく、そこに至るまでの全経路を見たいと考えました。そこで、推論と適応学習による継続的最適化のための専門システムを構築しました。社内では愛称で CORAL と呼んでいます。
なぜベンチマークだけでは不十分なのか
AI コーディングエージェントは通常、合格率・トークン数・レイテンシといったベンチマークで評価されます。これらのメトリクスは何が 起きたかを教えてくれますが、なぜ 起きたかは教えてくれませんし、全体的なプロセスをどう改善すべきかも示してくれません。
タスクが「合格」しながらも、エージェントが壊れた検索パターンでターンを無駄にしていることがあります。また、モデルの性能が低いからではなく、ツールの説明が誤解を招くものだったために失敗することもあります。毎日何千ものエージェントインタラクションを処理している場合、手動レビューはスケールしません。
私たちには、本番環境から自動的に学習し、ベンチマークが見逃すパターンを発見できるシステムが必要でした。
エージェントの動作を分析する方法
私たちの適応学習システムは、実際の Kiro インタラクションを分析して、合格/不合格のメトリクスが見落とす非効率性を浮き彫りにします。1
チェスプレイヤーが自分の対局を振り返るようなものです。試合後、彼らは結果を確認するだけではありません。どこでテンポを失ったか?どのパターンがミスにつながったか?次回はどうすべきか?と問いかけます。私たちのシステムは、これを Kiro のエージェントに対して自動的かつ大規模に行います。
そのために軌跡ベースの学習(trajectory-based learning)を使用しています。コードがコンパイルされるかどうかを確認するだけでなく、エージェントが取った一連のアクション全体、つまりすべてのツール呼び出し、すべての意思決定ポイント、すべての回復試行を検証します。5 つのクリーンなステップで合格するタスクと、17 の雑然としたステップで合格するタスクは大きく異なり、システムはその違いを識別できます。
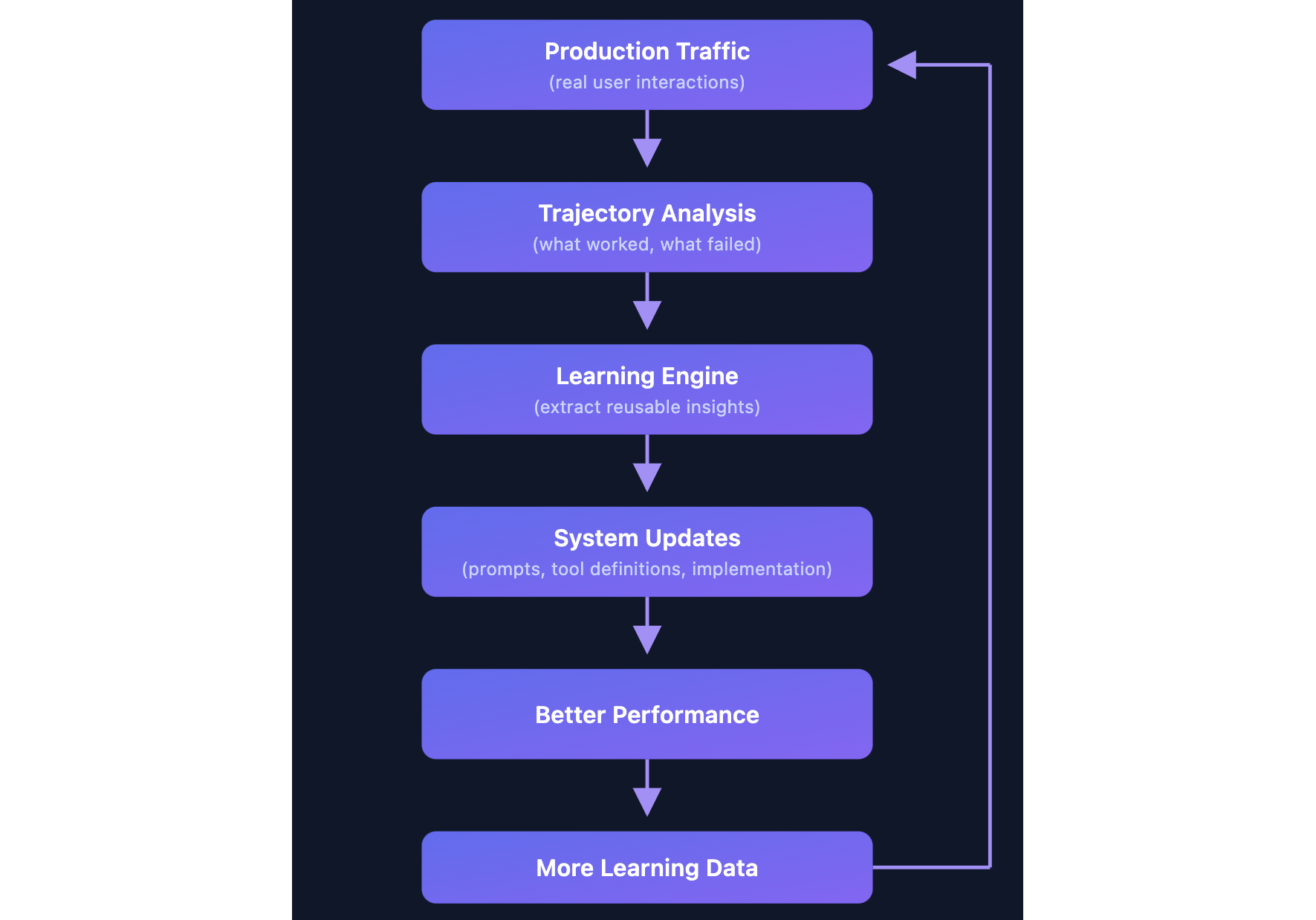
仕組み
毎日、私たちは同意を得たユーザーの実際の Kiro セッションを何千件もサンプリングし、LLM ベースの分析を使って検証します。各軌跡に対して、エージェントが何をしたか、何が問題だったか(あるいは正しかったか)、そしてその理由を問いかけます。
「検索結果が返ってこなかった」といった表面的な結果だけを見るのではありません。エージェントが試みたこと、どのように回復したか、どこで時間を失ったかという一連のアクション全体を追跡します。その一連の流れから、LLM が根本原因分析を行い、一般化可能な教訓を抽出します。一時的な修正ではなく、タスク全体に適用できるものです。
その教訓は、すでに学習済みのすべての内容と照合されます。新しいものか?具体的に対処できるものか?既存のインサイトと矛盾しないか?これらをパスすれば、ツール使用・ワークフローパターン・エラー回復・行動ガイダンスといったカテゴリで整理された構造化ナレッジベースに追加されます。
各インサイトはエビデンスも追跡します。あるパターンが多くの軌跡にわたって繰り返し現れると、信頼度が高まります。以前のインサイトが問題を引き起こすことが判明した場合は、修正または削除されます。ナレッジベースは静的ではなく、エージェントとツールの変化に合わせて進化します。
高信頼度のインサイトが見つかると、それを具体的な修正に変換します。ツールの説明の更新、システムプロンプトの変更、またはエージェントの動作修正です。これらはモデルの再トレーニングなしに即座にリリースされます。エージェントが改善されると、実際のセッションからより多くのデータが収集され、サイクルが続きます。
2 つの実例
発見 #1: サイレント検索失敗
ほとんどのメトリクスが見逃してしまうパターンを捉えた例を紹介します。
何が起きていたか: エージェントが *.py のようなパターンでファイルを検索し、結果がゼロになっていました。検索はツール呼び出しとして成功とマークされていた(エラーは発生しない)ため、エージェントはファイルが単純に存在しないと判断していました。しかし、ファイルは存在していました。エージェントが見つけられなかっただけです。
理由: LLM は ripgrep のようなツールから学習しており、*.py はデフォルトで再帰的に検索されます。しかし Code-OSS 上に構築された Kiro の検索 API では、再帰的なマッチングには **/*.py が必要です。微妙な違いですが、ツールの説明にはその点が明記されていませんでした。
コスト: grep 検索の 4 分の 1 以上がサイレントに失敗していました。検索が何も返さないとき、エージェントは諦めません。即興で対応します。ファイルを手動で読み込み、別のクエリで再試行し、ディレクトリツリーを探索します。平均して、エージェントは失敗した検索ごとに約 5 ターンの余分な作業を費やしており、本来不要だった作業をしていました。
修正: ツールの説明に 1 行追加するだけ。
- includePattern (optional): 対象ファイルの glob パターン(例: '*.ts')
+ includePattern (optional): 対象ファイルの glob パターン(例: '**/*.ts')。再帰検索には ** を使用してください。結果:
|
メトリクス |
修正前 |
修正後 |
|
誤ったパターン率 |
26.10% |
0.30% |
|
影響を受けたセッション |
約 23% |
<0.3% |
1 行の変更で、本番環境における誤った grep パターンを約 99%削減しました。
発見 #2: cd コマンドの罠
何が起きていたか: エージェントが cd src && npm test のようなシェルコマンドを記述していました。これらはすべて失敗していました。Kiro の executeBash ツールは各コマンドをワークスペースルートから実行し、入力バリデーションによって cd の使用を拒否するため、cd は永続的な効果を持ちません。このツールにはまさにこの目的のために cwd パラメータが用意されていますが、bash 呼び出しの約 4% で、モデルはツールの説明に従う代わりにトレーニングデータから学習した慣れ親しんだシェルパターンに戻ってしまっていました。
理由: cd dir && command はシェルスクリプトの一般的なパターンです。LLM はこれを何百万回も見てきました。cwd パラメータのアプローチは馴染みがないため、エージェントは学習済みのパターンに頼ってしまいました。
コスト: 全シェル呼び出しの 3.46% がこのパターンを使用しており、18% のセッションに影響を与えていました。すべての試みが失敗し、エージェントはコマンドの再試行・代替手段の探索などで平均 2.7 ターンの回復作業を費やし、セッション内で完全に回復できないこともありました。
修正: 制限をより強くプロンプトするだけでなく、自動修正を構築しました。エージェントが送信すると、
executeBash(command="cd src && npm test")Kiro はそれを自動的に変換します。
executeBash(command="npm test", cwd="src")実行後、正しいパターンを強化するための穏やかなリマインダーが表示されます。
<system-reminder>
作業ディレクトリがワークスペースルートに戻りました。別のディレクトリでコマンドを実行するには cwd パラメータを使用してください。
</system-reminder>これによりエージェントは常に現在地を把握できます。作業ディレクトリを見失うことで生じる混乱や連鎖的なエラーを防ぎます。
予測される影響:
|
メトリクス |
修正前 |
修正後(予測) |
|
|
100% |
約 0%(自動修正) |
|
影響を受けたセッション |
18% |
約 0% |
注目しているパターン
分析は大きな成果だけを見つけるわけではありません。積み重なると大きな影響を持つ小さなパターンを継続的に浮き彫りにします。現在積極的に調査中のものをいくつか紹介します。
ツールインタラクションパターン
フォーマット後のコンテンツドリフト。エージェントがファイルを編集した後、Prettier や Black のようなフォーマッターが空白と構造を整形します。エージェントの次の編集は、ファイルが書いた時と同じ状態であると仮定しますが、実際には変化しています。私たちの分析では、エージェントがフォローアップの変更を試みる際に「oldStr が見つからない」という失敗が繰り返し発生することが判明しました。自動フォーマットされた可能性のあるファイルに対してさらなる編集を試みる前に、エージェントが変更されたセクションを再読み込みする方法を検討しています。
散在するマルチファイル編集。変更が複数のファイルにまたがる場合、すぐに編集に入るエージェントは他のファイルの関連コードを見落とすことがよくあります。変更を加える前にコードベース全体の変更ポイントをまずマッピングする(検索を使用して)エージェントの方が、より完全で一貫した結果を生み出すことがわかりました。クロスファイルタスクに対してこの「まず把握、次に編集(map first, edit second)」パターンを促進する方法を検討しています。
コミュニケーションパターン
承認の行き詰まり。エージェントがリクエストに対して「了解しました」や「わかりました」と応答した後、何もしない軌跡を発見しました。ユーザーは実際の作業を進めるために再度プロンプトを送る必要があります。小さなことですが、1 ターンを無駄にし、フローを妨げます。エージェントが単に承認するだけでなく、すぐに行動するよう行動ガイダンスに取り組んでいます。
曖昧さのコスト。最善の行動が明確化の質問をすることである場合があります。エージェントが曖昧なリクエストに対して誤った推測をし、間違ったものを構築し、作業をやり直さなければならない軌跡を発見しました。最初に 1 つの質問をするだけで、複数ターンの無駄な作業を節約できたはずです。推測するのではなく明確化を求めるようエージェントを促すタイミングと方法を調査しています。
複合効果
個々の修正は小さなものです。ツールの説明の 1 行、行動への一押し、自動修正。しかし、あなたにとってはそれらが積み重なります。5 回目ではなく 1 回目の試行で正しいファイルを見つける検索。失敗して再試行するのではなく、そのまま動作するシェルコマンド。無駄なターンが減ることで、より速い結果が得られ、エージェントが軌道を見つけるのを待つ時間が短縮されます。
これらの問題の多くを軌跡レベルの分析で迅速に修正できると確信しています。従来の評価は合格したタスクを確認して次へ進みます。このシステムは、壊れた検索パターンで 17 ターンかかった完了タスクを見て、次回はどうすれば 5 ターンにできるか?と問いかけます。
結果を測定するだけでなく、合格/不合格のメトリクスが見逃す非効率性を発見するために、完全な実行パスを積極的に分析しています。
継続的に改善される開発者体験
これらはすべてバックグラウンドで実行され、チームがレビューしてリリースできる修正を洗い出します。目標は、このループを将来的に完全に自動化することです。今日の Kiro エージェントは先月より優れており、来月はさらに良くなります。あなたが何かをする必要はありません。ただし、Kiro の提案にフィードバックを残したり、問題を報告したり、何かおかしいと感じたことにフラグを立てたりすると、そのシグナルが私たちの学習システムに取り込まれます。あなたの入力が Kiro をすべての人にとってよりスマートにするのに役立ちます。
上記の発見はほんの始まりに過ぎません。毎週新しいパターンを発見しており、学んだことを共有し続けます。
Kiro を使い始めて、継続的な改善を体験してください。
1 Kiro のインタラクションの共有をオプトアウトすることができます。エンタープライズユーザーはデフォルトでオプトアウトされています。
翻訳は Solutions Architect の吉村が担当いたしました。