Amazon Web Services ブログ
AWS Lambda および Tensorflow を使用してディープラーニングモデルをデプロイする方法
ディープラーニングは、実際のデータを処理する方法に革命をもたらしました。ディープラーニングアプリケーションの種類は、ユーザーの写真アーカイブの整理から、本のレコメンド機能、不正な動作の検出、自動運転車周辺の認識まで、多岐にわたります。
この投稿では、AWS Lambda で独自にトレーニングしたモデルを使用して、単純なサーバーレスのコンピューティング手法を大規模に活用する方法を段階的にご説明します。このプロセスの中で、サーバーレスを使って推論を実行するために使用できる AWS の主要なサービスをいくつかご紹介します。
ここでは、イメージ分類について取り上げます。パフォーマンスが高いオープンソースモデルを多数利用できます。イメージ分類では、ディープラーニングで最も一般的に使用されている畳み込みニューラルネットワークと全結合ニューラルネットワーク (Vanilla Neural Networks としても知られる) の 2 種類のネットワークを使用することができます。
トレーニングされたモデルを配置する AWS の場所や、AWS Lambda が推論のためのコマンドで実行できる方法でコードをパッケージ化する方法についてご紹介します。
このブログ投稿では、AWS のサービス (AWS Lambda、Amazon Simple Storage Service (S3)、AWS CloudFormation、Amazon CloudWatch、AWS Identity and Access Management (IAM)) についてご説明します。使用する言語フレームワークおよびディープラーニングフレームワークには、Python や TensorFlow などがあります。ここで説明するプロセスは、MXNet、Caffe、PyTorch、CNTK などの他のディープラーニングフレームワークを使用して適用できます。
全体的なアーキテクチャ
AWS アーキテクチャ
プロセスの視点から、ディープラーニングの開発およびデプロイは、従来のソフトウェアソリューションの開発やデプロイと同じように行う必要があります。
以下の図は、開発ライフサイクルの一例です。
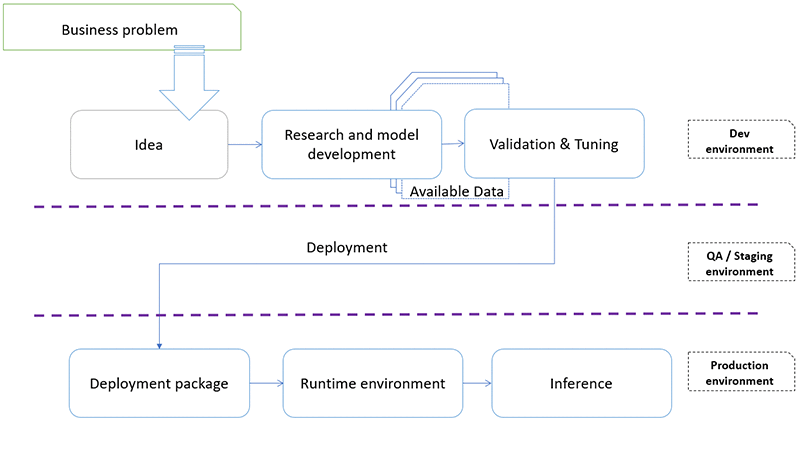
図を見て分かるように、通常のソフトウェア開発プロセスは、アイデア開始や開発環境のモデリングから、本番稼働用のモデルの最終デプロイまで複数の段階があります。ほとんどの場合、この開発段階では、環境を絶えず、繰り返し変更する必要があります。通常、この反復は、ソフトウェア/モデルの開発時に使用されるリソースの性質や量に影響を及ぼします。アジャイル開発では、環境をすばやく構築/再構築/解放できることが不可欠です。構築されているソフトウェアにすばやく変更を加えるには、インフラストラクチャの調整が必要です。アジャイル開発やイノベーションの加速の前提条件のひとつに、コードによってインフラストラクチャを管理できること (IaC: infrastructure as code) があります。
ソフトウェア設計の管理、構築およびデプロイの自動化は、継続的な統合および継続的な配信 (CI/CD) の一環です。この投稿では、綿密に計画された CI/CD パイプラインの詳細には触れていませんが、開発/デプロイの俊敏性およびプロセスの自動化を促進する反復可能プロセスを構築する開発チームは、念頭に置いておくべきです。
AWS は、開発タスクを簡略化する多数のサービスやプラクティスをコミュニティに対して提供しています。自動化コードを使用して環境が構築されると、開発環境で使用されるテンプレートからステージングシステムおよび本稼働システムを構築する場合など、わずか数分で簡単に使用して複製することができます。
さらに、AWS では、ストリーミング、バッチ処理、キューイング、モニタリング、アラート、リアルタイムのイベント駆動システム、サーバーレスコンピューティングなどの完全マネージド型のサービスを通じて、多数のコンピュータサイエンスおよびソフトウェアエンジニアリングの概念を使用して複雑なソリューションの設計を大幅に簡素化しています。この投稿では、ディープラーニングで使用するサーバーレスコンピューティングについてご説明します。この方法では、サーバーのプロビジョニングや管理など、手間のかかるタスクを減らすことができます。これらのタスクは AWS のサービスによって行われており、データサイエンティストやソフトウェア開発者は、十分なコンピューティングキャパシティーを確保できるだけでなく、システム障害時の再試行などの複雑さを軽減することができます。
この投稿では、本番稼働用システムを模倣したステージングのような環境に焦点を当てます。
Amazon S3 ベースのユースケース
このユースケースでは、Amazon Simple Storage Service (S3) バケットにイメージを格納するプロセスをシミュレートします。S3 バケットには、オブジェクトが保存されており、オブジェクトの PUT イベントに関する AWS クラウドエコシステムの残りの部分を通知することができます。ほとんどの場合、Amazon Simple Notification Service (SNS) 通知メカニズムが使用されるか、AWS Lambda 関数内に配置されたユーザーのコードが自動的にトリガーされます。分かりやすくするために、S3 オブジェクトの PUT イベントで、Lambda 関数のトリガーを使用します。お気付きのように、私たちは非常に洗練された概念を取り扱っています。この概念は、実際にサイエンティストや開発者が使用することはほとんどありません。
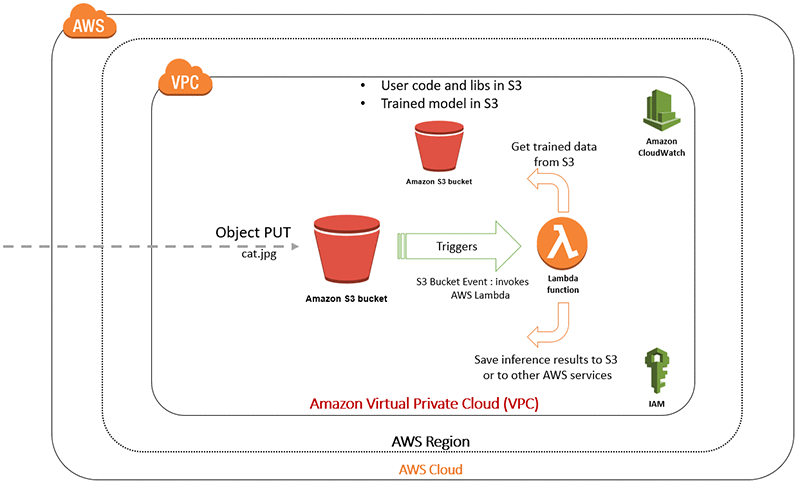
トレーニング済みのマシンラーニングモデルは、Python TensorFlow で開発され、S3 バケットに格納されています。シミュレーションを行う上で、バケットのイベント通知がオンになっている任意のバケットに猫の画像をアップロードします。Lambda 関数は、これらの S3 バケットの通知イベントにサブスクライブされます。
この投稿では、クラウドインフラストラクチャはすべて、AWS のサービスを作成し起動するための高速で柔軟なインターフェイスである、AWS CloudFormation を使用して構築されます。そのため、AWS リソースを設計して起動する別の方法として、AWS マネジメントコンソール、または AWS コマンドラインインターフェイス (AWS CLI) を使用して手動で行うこともできます。
ディープラーニングのコード
現在、AI ベースのシステムを迅速に開発する簡単で効率的な方法は、既存のモデルを使用して、特に公開されている最新モデルを使用するユースケース向けに微調整することです。
イメージ分類を目的として事前トレーニング済みの強力な Inception-v3 モデルのデプロイを見てみましょう。
Inception-v3 アーキテクチャ

この Inception-v3 アーキテクチャは色を使用したレイヤータイプを示しています。モデルのすべての部分を理解する必要はありません。しかし、これが深層ネットワークであり、一からトレーニングするには膨大な時間とリソース (データとコンピューティング) が必要になることを理解することは重要です。
TensorFlow のイメージ認識チュートリアルを活用して、事前トレーニング済みの Inception-v3 モデルをダウンロードします。
まず、Python 2.7 の virtualenv または Anaconda 環境を作成し、CPU 用の TensorFlow をインストールします (GPU は不要です)。
次に、 classify_image.py を https://github.com/tensorflow/models/tree/master/tutorials/image/imagenet からダウンロードし、シェルで次のように実行します。
これにより、事前トレーニング済みの Inception-v3 モデルがダウンロードされ、サンプル画像 (パンダ) 上で実行されます。その結果、正しく実装されていることが確認できます。
この場合、次のようなディレクトリ構造が作成されます。
これで、このモデルファイルと、コンパイル済みの必要な Python パッケージを使用して、AWS Lambda で実行可能なバンドルを作成します。これらの手順を簡素化するために、必要なバイナリファイルをご用意しています。デモを数分間実行するには、以下の手順に従います。
デモバンドルの一部として、大規模なモデルファイルをご用意しています。このファイルは大容量のため (90 MB 以上)、Amazon S3 から AWS Lambda の推論を実行中にロードする必要があります。表示された推論コード (classify_image.py) を見ると、ハンドラー関数の範囲外でダウンロードするモデルを配置したことが分かります。これは、AWS Lambda コンテナの再利用を活用するために行います。ハンドラーメソッドの範囲外で実行されたコードは、コンテナの作成時に一度だけ呼び出され、同じ Lambda コンテナへの呼び出しでメモリ内に保持されます。そのため、その後は Lambda 関数をすばやく呼び出すことができます。
AWS Lambda の事前ウォーミングアクションとは、最初の本番稼働を実行する前に AWS Lambda を開始することです。これにより、AWS Lambda の「コールドスタート」による問題を回避できます。「コールドスタート」では、大規模なモデルをすべての「コールド」の Lambda インスタンス化で S3 からロードする必要があります。AWS Lambda が動作したら、次回の推論の実行に対して迅速に応答できるように、AWS Lambda をウォーム状態に保つことが有益です。AWS Lambda が数分で 1 回起動されていれば、何らかの ping 通知を使用した場合でも、AWS Lambda で推論タスクを実行する必要があるとウォーム状態が維持されます。
ここで、コードと、必要なパッケージをすべて一緒に圧縮する必要があります。通常、AWS Lambda で使用する前に、Amazon Linux EC2 インスタンスの必要なパッケージをすべてコンパイルする必要があります。(これについては、http://docs.aws.amazon.com/lambda/latest/dg/lambda-python-how-to-create-deployment-package.html で説明しています)。ただし、このブログ投稿では、コンパイル済みのファイルと、 deeplearning-bundle.zip ファイルを提供しており、前述のすべてのコードに加え、AWS Lambda で使用できる必要なパッケージが含まれています。
AWS Lambda を使用したデプロイ
開始するための主な手順は次のとおりです。
- DeepLearningAndAI-Bundle.zip をダウンロードします。
- ファイルを解凍し、Amazon S3 バケットにコピーします。このバケットの名前を dl-model-bucket とします。このフォルダには、このデモを実行するのに必要な以下のものがすべて含まれます。
- classify_image.py
- classify_image_graph_def.pb
- deeplearning-bundle.zip
- DeepLearning_Serverless_CF.json
- cat-pexels-photo-126407.jpeg (著作権フリーのテスト用イメージ)
- dog-pexels-photo-59523.jpeg (著作権フリーのテスト用イメージ)
- CloudFormation スクリプトを実行して AWS に必要なリソース (例: テスト用の S3 バケット) をすべて作成し、それを deeplearning-test-bucket (このバケット名を使用されている場合は別の名前を使用する必要がある) としましょう。 手順は以下のとおりです。
- イメージをテストバケットにアップロードします。
- 推論を実行する Lambda 関数の Amazon Cloud Watch ログに移動し、関数の結果を検証します。
次の手順ガイドに従って、CloudFormation スクリプトを実行します。
- AWS CloudFormation コンソールに移動し、[Create new stack] ボタンを選択します。
- 「Amazon S3 テンプレート URL の指定」に、CloudFormation スクリプト (json) へのリンクを入力します。[Next] を選択します。
- CloudFormation スタックの名前に必要な値、テストバケットの名前 (認識するイメージをアップロードする場所。deeplearning-test-bucket とする)、モデルやコードを保存しているバケットを入力します。

- [Next] を選択します。[Options] ページをスキップします。[Review] ページに移動します。ページの一番下で、内容を承認する必要があります。[Create] ボタンを選択します。[CREATE_IN_PROGRESS] ステータスになり、その直後に [CREATE_COMPLETE] ステータスになります。

この時点で、CloudFormation スクリプトによって、ソリューション全体が構築されます。これには、AWS Identity and Access Management (IAM) ロール、DeepLearning Inference Lambda 関数に加え、オブジェクトがテストバケットに PUT されるときに Lambda 関数をトリガーするために必要な S3 バケットのアクセス許可などが含まれます。
AWS Lambda サービスを見ると、新しい DeepLearning_Lambda 関数が表示されます。AWS CloudFormation によって、必要なパラメータがすべて設定され、推論の際に使用される必要な環境変数が追加されました。
新しいテストバケットが追加されています。ディープラーニングの推論機能をテストするために、以前作成した S3 バケット (deeplearning-test-bucket) に画像をアップロードします。
推論結果の取得
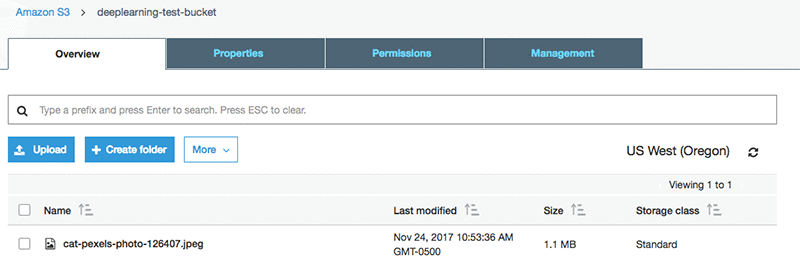
記述したコードを実行するには、CloudFormation スクリプトで作成した Amazon S3 バケットに任意の画像をアップロードします。このアクションによって、推論を実行する Lambda 関数がトリガーされます。
以下の例は、テストイメージをテストバケットにアップロードする様子を示したものです。
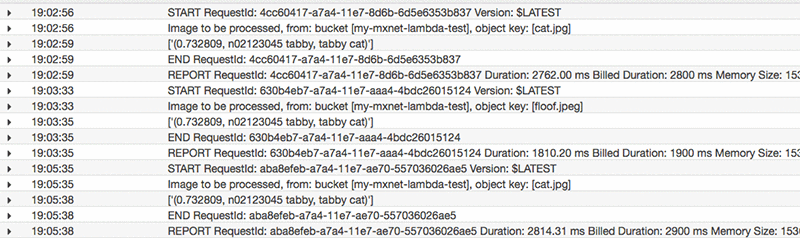
ここで、S3 バケットによって、推論を実行する Lambda 関数がトリガーされました。このブログ投稿では、CloudWatch ログを使用して、推論の結果を表示します。コンソールの AWS Lambda サービス画面で、[Monitoring]、[View Logs] の順に選択します。実際に推論の結果を表示する場合は、Amazon DynamoDB や Amazon Elasticsearch Service など、永続的なストアのいずれかに格納する必要があります。ここでは、画像や関連ラベルのインデックスを簡単に作成することができます。

Lambda コンテナ構築時に行われる、モデルのローディングの様子をこのログで確認できます。以降の呼び出しでは、このコンテナが「ウォーム」状態である限り、推論のみ実行され (モデルはすでにメモリに格納されている)、合計ランタイムは短縮されます。以下のスクリーンショットは、その後 Lambda 関数が実行される様子を示したものです。
サーバーレス環境でディープラーニングを活用するヒント
サーバーレス環境を使用すると、開発コードおよび本稼働コードを簡単にデプロイすることができます。コードおよびその依存関係をパッケージ化する手順はランタイム環境によって異なるため、学習の質を高め、初回のデプロイ時に問題が発生しないようにします。Python は、データサイエンティストがマシンラーニングモデルを構築する上で一般的な言語です。AWS Lambda 実行時のパフォーマンスを最大限に高めるために、従来の C や Fortran に依存する Python ライブラリを構築し、Amazon Linux Amazon Machine Image (AMI) (その構築ファイルは後にエクスポート可能) を使用して Amazon Elastic Compute Cloud (EC2) にインストールする必要があります。このブログ投稿では、既に対応済みとします。これらのライブラリを活用して、最終的なデプロイパッケージを構築できます。さらに、事前コンパイル済みの Lambda バンドルは、オンラインでいつでも確認することができます (例: https://github.com/ryfeus/lambda-packs)。
モデルのトレーニングには通常、高負荷の計算を伴うため、専用ハードウェアで高価な GPU を使用する必要があります。ありがたいことに、推論は、トレーニングよりも非常に計算負荷が低いため、CPU を使用し、Lambda サーバーレスのコンピューティングモデルを活用することができます。推論にどうしても GPU が必要な場合は、Amazon ECS や Kubernetes などのコンテナサービスを使用することができます。これらのサービスを使用すれば、推論環境を詳細にコントロールすることができます。詳細については、こちらの投稿 (https://aws.amazon.com/blogs/ai/deploy-deep-learning-models-on-amazon-ecs/) をご覧ください。
プロジェクトをサーバーレスアーキテクチャに移行するにつれて、このコンピューティングメソッドから生じる機会が増え、課題についての理解が深まります。
- サーバーレスによって、コンピューティングインフラストラクチャを使用するのが非常に簡単になり、VPC、サブネット、セキュリティの管理や、Amazon EC2 サーバーのデプロイに伴う複雑性を軽減することができます。
- AWS は、容量の問題を解決します。
- コスト効率が良い – コンピューティングリソース使用時のみ課金されます (100ms 単位)。
- 例外処理 – AWS は、後に処理できるように、Amazon SQS/Amazon SNS で問題のあるデータやメッセージを再試行し、保存します。
- ログはすべて収集され、Amazon CloudWatch ログに格納されます。
- パフォーマンス状況は、AWS X-Ray ツールを使用してモニタリングできます。
サイズの大きいファイルやオブジェクトを処理する場合は、メモリ内のコンテンツ全体をロードせずに入力ストリームを使用します。AWS では、大容量ファイル (20 GB 以上) を処理するために、従来のファイル/オブジェクトのストリームで AWS Lambda の機能を使用することも少なくありません。ほとんどの場合 (特に、CSV や JSON のエンコード時)、ファイルやオブジェクトのサイズを大幅に抑えられる圧縮を使用し、ネットワーク I/O を向上させます。
このブログ投稿では、Inception-v3 モデル (最大メモリ使用量 400 MiB 未満) を使用していますが、MobileNets や SqueezeNet などの低メモリのオプションを使用することができます。他のモデルを展開するか、コンピューティング/メモリ/正確性の制限がある場合は、別のモデルの優れた分析を Canziani et al で使用することができます。 この投稿で Inception-v3 に注目したのは、この分析が理由です。精度、コンピューティング要件、メモリ使用量の点で、優れたトレードオフを実現します。
Lambda 関数のデバッグは、従来のローカル/ホスト/ノート PC をベースとした環境でのデバッグとは異なります。その代わり、ローカルホストコード (デバッグが簡単) を作成してから、Lambda 関数にすることをお勧めします。ノート PC 環境から AWS Lambda への切り替えに必要な変更はほとんどありません。
- ローカルファイル参照の置き換え – たとえば、S3 オブジェクトに置き換えます。
- 環境変数の読み取り – 同様のロジックを使用するために抽象化することができます。
- コンソールへの出力 – 出力関数を引き続き使用することはできますが、CloudWatch ログにリダイレクトされるため、数秒以内に表示されます。
- デバッグ – AWS Lambda でデバッガを使用することはできませんが、前述の通り、ホストで開発するためのツールをすべて使用し、ホスト環境で正常に実行している場合のみ、結果をデプロイします。
- ランタイム計測 – AWS X-Ray サービスによってランタイムデータに対する洞察を得られるため、問題を見極め、最適化することができます。
コードと依存関係を 1 つの ZIP ファイルにまとめれば、AWS Lambda に簡単にデプロイすることができます。この投稿の冒頭で述べたように、CI/CD ツールを使用すれば、このステップは簡素化されるだけでなく、さらに重要なことに完全に自動化されます。コードの変更が検出されると、CI/CD パイプラインによって自動的に構築され、設定する度に、リクエストされた環境に結果がデプロイされます。さらに、AWS Lambda は、バージョニングおよびエイリアシングに対応しており、さまざまな Lambda 関数の中ですばやく切り替えることができます。そのため、研究、開発、ステージング、本稼働など、さまざまな環境で操作する場合は有益です。バージョンの公開後は変更することができないため、コードに対する望ましくない変更を回避できます。
まとめ
要約すると、この投稿では、AWS Lambda を使用したサーバーレス環境で、トレーニングされた独自のモデルを広範囲で使用する、ディープラーニングを取り扱いました。
その他の参考資料
- AWS Lambda および MXNet を使ったシームレスなスケーリング予測
- AWS Deep Learning AMI の更新: TensorFlow、Apache MXNet、Keras、PyTorch の新バージョン
今回のブログの投稿者について
 Boris Ivanovic は、スタンフォード大学のコンピュータサイエンスの学生で、人口知能 (AI) を専攻しています。彼は 2017 年の夏、Prime Air の SDE インターンを行い、現在は無人航空機を使用してお客様の荷物を 30 分以内に安全にお届けしています。
Boris Ivanovic は、スタンフォード大学のコンピュータサイエンスの学生で、人口知能 (AI) を専攻しています。彼は 2017 年の夏、Prime Air の SDE インターンを行い、現在は無人航空機を使用してお客様の荷物を 30 分以内に安全にお届けしています。
 Zoran Ivanovic は、AWS プロフェッショナルサービスを使用して、カナダでビッグデータのプリンシパルコンサルタントをしています。Amazon で最大のビッグデータチームの一員として 5 年の経験を積んだ後、AWS に移り、その経験を生かし、AWS のサービスを活用してミッションクリティカルなシステムをクラウド上に構築したいと考える、より大規模の企業のお客様をお手伝いしています。
Zoran Ivanovic は、AWS プロフェッショナルサービスを使用して、カナダでビッグデータのプリンシパルコンサルタントをしています。Amazon で最大のビッグデータチームの一員として 5 年の経験を積んだ後、AWS に移り、その経験を生かし、AWS のサービスを活用してミッションクリティカルなシステムをクラウド上に構築したいと考える、より大規模の企業のお客様をお手伝いしています。