Amazon Web Services ブログ
Amazon DynamoDB での優先度付きキューの実装
キューイングは、分散処理システムで計算コンポーネントを分離するために一般的に使用されるソリューションです。これは、サーバーレスおよびマイクロサービスアーキテクチャで使用する非同期通信システムの形式です。メッセージは処理のためにキューで待機し、1 人のコンシューマーが受信するとキューから出ます。このタイプのメッセージングパターンは、ポイントツーポイント通信と呼ばれます。
この記事では、他の大規模なキューイングシステムで行うように、Amazon DynamoDB テーブルのいずれかを、エンキュー (メッセージをキューに配置) とデキュー (メッセージを読み取り、キューから削除) が行えるキューに変換する方法について説明します。
DynamoDB は、任意の規模で 1 桁のミリ秒のパフォーマンスを実現するキーと値のドキュメントデータベースです。これは、モバイル、ウェブ、ゲーム、広告技術、IoT、および大規模で低レイテンシーのデータアクセスを必要とするその他のアプリケーションに使用できる、サーバーレスで完全マネージド型のサービスです。
永続性、単一メッセージ処理、および分散コンピューティングを提供する多くのキュー実装があります。一般的なキューイングソリューションには、Amazon SQS、Amazon MQ、Apache ActiveMQ、RabbitMQ、Kafka などがあります。これらのサービスは、実装方法、スケーリング、パフォーマンスなど、いくつかの異なる特性を持つさまざまなキュー機能を処理します。
ただし、キューシステムのほとんどは、アイテムがキューに到着した後、アイテムの順序を簡単に変更することはできません。DynamoDB で議論された実装は、処理前にキュー内の順序を変更したり、アイテムをキャンセルしたりできます。
この記事では、DynamoDB のキューイングシステムの重要な側面についても説明します。たとえば、アイテムの優先度の変更、メッセージごとに 1 人のコンシューマーのみの許可、処理成功時のメッセージの削除、メッセージ処理の順序の保証方法、例外の処理方法などです。
通常のキューと優先度付きキュー
キューは、アイテム (メッセージ) のコレクションを順番に保持する線形データ構造を定義する抽象データ型です。1 人のコンシューマーは、個々のメッセージを 1 回だけ処理します。最も一般的なキューイング方法の 1 つは、先入れ先出し (FIFO) 構造です。この構造では、新しいアイテムがキューの最後に結合し、キュープロセスは前 (ヘッド) から順番に処理されます。
この記事では、キュー内のメッセージをメッセージの特性でソートする機能を追加することにより、典型的なメッセージキューの実装を強化する方法を示します。これは、優先度付きキューとして知られています。
優先度付きキューでは、各アイテムにキュー内の優先度を定義する追加の属性があります。優先度が変わると、キュー内のアイテムの順序が変わります。優先度付きキューは、ヒープと呼ばれる構造を頻繁に使用するか、自己バランスツリーを使用します。
DynamoDB は、アイテム (レコード) を動的に並べ替えるためにグローバルセカンダリインデックス (GSI) を使用します。キュー項目が表示されている (まだ処理されていない) 限り、キュー内の項目の順序を変更できます。
ソリューションのアーキテクチャ
この記事では、DynamoDB のテーブルを使用するマイクロサービスがあるシナリオを使用します。この記事では、キューイングの主なアイデアを説明するために、仮想アプリケーションオブジェクトであるシップメントも紹介します。倉庫内のすべてのアイテムを見つけて、発送の準備ができていることを確認するまで、シップメントを発送できません。シップメントの準備ができたら、それをマークし、ダウンストリーム処理のために FIFO キューに入れることができます。キューでは、アイテムのタイムスタンプが優先度属性として使用されます。
次の図は、このワークフローを示しています。

この記事のアーキテクチャは比較的単純です。JSON を使用して簡単なドメイン固有言語 (DSL) を作成し、AWS のサービスを記述することができます。ファイルはメタデータに解析され、AWS Cloud Development Kit (AWS CDK) に送られ、AWS で必要な部分 (IAM ロール、DynamoDB、Lambda、および Amazon S3) が構築およびデプロイされます。AWS CDK は、いくつかのプログラミング言語をサポートするソフトウェア開発フレームワークであり、コードでクラウドインフラストラクチャを定義し、AWS CloudFormation を通じてプロビジョニングします。詳細については、「AWS CDK とは」を参照してください。
基本的な例を取り上げたら、アイテムの優先度の変更、メッセージごとに 1 人のコンシューマーのみの許可、処理の成功によるメッセージの削除、メッセージ処理の順序の保証方法、例外の処理方法など、キューイングシステムのその他の重要な側面について説明します。
アーキテクチャの概要
このブログ記事のアーキテクチャは比較的単純です。JSON を使用して、AWS でサービスを記述するための簡単なドメイン固有言語 (DSL) を作成しました。JSON ファイルはメタデータに解析され、Cloud Development Kit (CDK) に送られ、DynamoDB などの AWS で必要なすべてのインフラストラクチャコンポーネントがビルドおよびデプロイされます。CDK は、コードでクラウドインフラストラクチャを定義し、AWS CloudFormation を介してプロビジョニングするための、多数のプログラミング言語をサポートするソフトウェア開発フレームワークです。

コードをすばやく実行するために、DynamoDB でデモテーブルを作成するために使用できる Cloud Formation JSON テンプレートを提供しています。デモを実行するために、他の AWS コンポーネントをデプロイする必要はありません。Java コードを実行するには、端末と機能のみが必要です。
付随するプロジェクトには、次のアーティファクトが付属しています。
- インフラストラクチャおよびサービスコンポーネントを定義する DSL (JSON)
- コード構築スクリプト
- CDK (AWS コンポーネントのビルドとデプロイ) + Cloud Formation JSON テンプレート
- カスタムシップメント SDK
- シップメントモデル
- キュー管理
- API
- テストアプリケーションスクリプト (プロデューサーとコンシューマー)
- 教育およびテスト用のコマンドラインインターフェイス (CLI)
DynamoDB モデルの属性
シップメントの DynamoDB データモデルは単純で、最初は次のようないくつかの属性で構成されています。
- id、パーティション (プライマリ) キーとして
- data、すべてのアプリケーションデータをマップとして保存する属性
- system_info は、アプリケーションオブジェクトの状態を追跡するために使用するさまざまなシステム情報のマップとして、そして最後に
- last_updated_timestamp、最新のタイムスタンプの値を UTC で保持します。
レコードが DynamoDB テーブルに保存されると、レコード上のその他のアクティビティは system_info マップ内で追跡され、さまざまなタイムスタンプ、ステータス情報、およびキュー情報が保持されます。
以下は、最初にデータベースに保存されたレコードのシステム情報の例です。
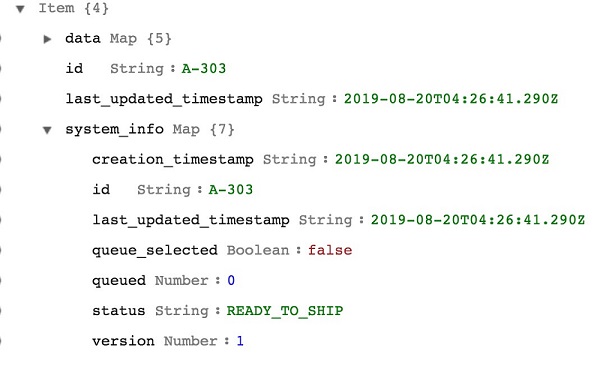
キューイング動作をモデル化するための主要なエンティティは、「キュー」属性です。そして、queued-last_updated_timestamp-index という名前の対応する GSI。

この記事ではスパースインデックスを使用しており、キューに登録された属性を持つレコードのみがインデックスに表示されます。レコードをソートするために、この記事では last_updated_timestamp を使用します。これにより、アイテムのタイムスタンプに基づいて優先度付きキューが作成されます。昇順または降順のソートを選択できます。ビジネスケースに応じて、他の属性を追加して独自の優先度メカニズムを実装できます。詳細については、「スパースインデックスの活用」を参照してください。
キューに入れられた属性を追加または削除すると、GSI にアイテムが追加または削除され、アイテムがキューに追加または削除されます。この記事では、大きなテーブルから少数のレコードをキューに入れるだけでよいため、ソリューションの実装は効率的です。
処理が完了すると、アイテムはキューを離れますが、テーブルに残ります。
この記事では、レコードの更新前および更新中にバージョン番号をチェックする楽観的ロックの助けを借りて、DynamoDB の更新式を使用します。詳細については、「式の更新」と「バージョン番号で楽観的ロック」を参照してください。
シップメントオブジェクトのライフサイクル
ソリューションは特定のライフサイクルに従います。ただし、その一般原則を多くのユースケースに適用できます。
すべてのシップメントアイテムが利用可能になるのを待っている間、シップメントオブジェクトは UNDER_CONSTRUCTION 状態です。オブジェクトは、ステータスが READY_TO_SHIP に変わるとキューに参加します。peek() メソッドを使用して、コンシューマーがレコードをキューから取得した後、レコードのステータスは PROCESSING_SHIPMENT に変わります。ステータスが COMPLETED に変わると、レコードはキューを離れます。
処理が失敗した場合、レコードはキューに再結合され、再処理のためにピークされる準備を整えます。オブジェクトは READY_TO_SHIP 状態に戻ります。複数の障害が発生した場合、レコードは検査のためにこのキューから送達不能キュー (DLQ) に移動します。状態は IN_DLQ に変わります。レコードが修正されている場合、復元プロセスは処理のためにキューにレコードを返します。
実装では、キュー属性を除き、オブジェクトのライフサイクルを追跡するために状態を何も使用しない可能性があります。
次の図は、このライフサイクルの手順を示しています。

このソリューションのコーディング言語
DynamoDB の AWK SDK と API をサポートする任意のコーディング言語を使用します。この記事では Java 8 を使用しています。
Java 開発者にとって、次のプロジェクトに使用できるコードには追加の価値があります。これは、本番環境向けのコードではなく、旅の素晴らしい第一歩です。この記事では、Java の DynamoDBMapper などの高レベル API と、DynamoDB や AmazonDynamoDB などの Java AWS SDK にある低レベル API の両方を紹介します。
ソリューションの実装
パーティションキーによる DynamoDB からのデータの保存と取得は、この記事ではあまり焦点を当てていない基本的なアクションです。関連情報は、キュー属性が最初はレコードに存在しないということです。属性が存在する場合、レコードはキューの配置の対象となります。さらに、レコードが最初にデータベースに到着すると、バージョン属性値は 1 に設定されます。この属性は楽観的ロックに関連しており、更新中に他のコンシューマーがレコードを更新しないようにします。
コードには以下のいくつかの一般的なプラクティスがあります。
- いつでも適切な数のレコードがキューにあるという仮定。詳細については、「パーティションキーを効率的に設計し、使用するためのベストプラクティス」を参照してください。
- クエリはデフォルト設定
scanIndexForward = trueを使用します。これは、クエリリストの最初の最も古いレコードを優先します。優先順位と順序付けのニーズに応じて、たとえば、最高スコアでレコードをソートする場合、このパラメータを false に変更する必要があります。 - 再び使用することのない属性を保持するよりも、REMOVE 更新式を使用して不要な属性を削除することをお勧めします
- システム属性をグループ化し、パーティションキーとソートキーがトップレベルの属性を持つという要件を満たす属性を複製します。たとえば、
SET last_updated_timestamp = :lut, #sys.last_updated_timestamp = :lut。 - 更新式の名前プレースホルダーは、予約名との競合を避けます。たとえば、バージョンの場合は
#v、ステータス属性の場合は#stです。 - 属性のプロジェクションにより、DynamoDB クエリリターンの効率が向上します。システム属性のみを処理する場合、アプリケーションデータを返す必要はありません。
- メインテーブルは、データベースレコードホルダーとしてだけでなく、キューの永続性としても機能します。マイクロサービスアーキテクチャがより厳密な懸念の分離を好む場合は、キューのニーズ専用の別のテーブルを作成できます。
- シップメントステータスは、シップメントがまだ構築されておらず、出荷の準備ができており、処理中であり、最終的に完了または失敗したときに追跡します。
- コンシューマーがメッセージを覗くのを遅らせる機能。この記事では説明していませんが、これは指数関数的なバックオフを実装する場合に役立ちます。指数バックオフでは、失敗したメッセージの処理を時間の経過とともに徐々に遅らせます。ダウンストリームシステムが一時的に利用できない場合、これは適切なアプローチです。
キューメソッド
次のコードの抜粋は、QueueSdkClient.java からのものです。
enqueue(ID)
エンキューは、レコードがキューに参加するときにマークする操作です。実際の移動は発生せず、queued 属性の減少のみが発生します。このソリューションでは、すぐに出荷できるレコードのみをキューに配置できます。
レコードを更新するコードは次のとおりです。
前述のコード例では、レコードをキューに配置することを決定するときに重要な要素を確認できます。SET #q = :one は、レコードのルートにキュー属性を作成します。パーティションをネストして、GSI のキー属性を並べ替えることはできません。トップレベルの属性である必要があるからです。GSI のパーティションキーに許可される属性タイプは、String、Numeric、または Binary です。この記事では、整数値 1 の数値を使用しています。ゼロより大きい整数値を使用すると、通常のキュー、処理中のレコードキュー、DLQ など、同じアプリケーションに対して複数のキュータイプをサポートできます。

さらに、コードは最後のレコードが更新されてキューに参加したときのタイムスタンプを更新します。すべてのタイムスタンプ値は、UTC タイムスタンプの文字列表現です。この文字列は、ソートプロパティを自動的に提供します。
このソリューションでは、条件式を使用して、最後に確認したときからレコードが変更されていないようにします。ネストされた属性はすべて dereference operator を使用します。
レコードが正常に更新されると、キュー属性の値は 1 になり、version 属性は 1 増加します。このソリューションは、返ってくるシップメントオブジェクトを簡単に作成するために追加の読み取りを行います。更新 API 呼び出しが新しいレコードを返すときに、これを最適化できます。
更新に Java の DynamoDBMapper API を使用している場合、楽観的ロックが組み込まれています。バージョン属性に@ DynamoDBVersionAttribute のアノテーションを付けるだけです。
peek()
peek() メソッドは、指定された優先度を満たすアイテムをキューから取得します。この記事は最新のタイムスタンプでソートされます。デフォルト設定 scanIndexForward = true は、優先レコードの先頭に古いレコードを配置します。次のコード例を参照してください。
キューに入れられた属性値が 1 のレコードを取得した後、レコードを反復処理して、処理に適格な最初のアイテムを探します。これが当てはまる可能性があるシナリオは 2 つあります。レコードの可視性のタイムアウトに達しているため、取得の対象となっている場合と、レコードがまだ処理対象としてマークされていない場合です。
レコード ID を決定したら、キューイングを管理するレコードの属性を更新します。次のコード例を参照してください。
system_info.queue_selected 属性のブール値は true です。この属性は、レコードがキューから取得され、処理段階にあることを示します。メッセージ処理中、レコードは他のコンシューマーには見えません。何らかの理由で可視性タイムアウト値の期間中にアプリケーションの処理が完了しない場合、基礎となるキューイング peek() ロジックにより、他のコンシューマーがキューを覗くことができるようになります。
同様に、dequeue() メソッドは、処理が成功したかどうかに関係なく、コンシューマーにレコードを提供し、キューからレコードをすぐに削除します。このため、dequeue() ではなく、常に peek() メソッドを使用する必要があります。
レコードが正常に更新されると、キュー属性と queue_selected 属性の値は 1 になり、バージョン属性は 1 ずつ増加します。peek() 操作のタイムスタンプが保存されます。この記事では、出荷記録のステータスが StatusEnum.PROCESSING_SHIPMENT に変わります。
この記事の実装により、他のコンシューマーが誤って同じレコードを覗くことはありません。キューにレコードが見つからない場合、返される PeekResult オブジェクトは失敗した操作を示し、シップメントオブジェクトへの参照は null です。
取得 (ピーク) するレコードの system_info の例は次のとおりです。

コンシューマーがレコードを取得したら、コンシューマーがレコードを処理し、SDK メソッドの 1 つを呼び出して、レコードが適切に処理されたか、またはプロセスが失敗したかを示す責任があります。
正常に処理されたレコードの例:

上記のスクリーンショットからわかるように、ステータス属性の値は COMPLETED です。キューに属することを示す属性は 0 に設定され、オブジェクトのルートから削除されます。さらに、system_info.queue_selected は false に設定され、メッセージが処理モードではなくなったことを示します。このレコードに対してこれ以上のアクションは許可されません。
remove(ID)
キュー項目の削除は、レコードからキュー属性を削除し、queue_selected 属性を 0 に設定する簡単な操作です。次のコード例を参照してください。
上記の実装では、まだ処理中であるかどうかに関係なく、キューからレコードを削除することにしました。レコードが処理中で、非表示のタイムアウトがまだアクティブな場合、削除を制限するためのロジックを追加できます。
restore(ID)
このメソッドは enqueue() に似ていますが、すでにキューにあり、処理のために選択されたアイテムに対して機能します。このメソッドは、コンシューマーがダウンストリームシステムで問題に遭遇し、処理を中止し、それによってメッセージをキューの最後に戻すときに役立ちます。次のコード例を参照してください。
上記のコードは、これらの属性が存在するかどうかに関係なく、system_info.queue_selected および DLQ を削除します。この関数を使用して、固定レコードを DLQ から通常のキューに戻すことができます。
また、レコードが処理のために非表示になる期間を変更することもできます。
touch(ID)
これは、last_updated_timestamp 属性を最新のタイムスタンプ値で更新する簡単な方法です。キューで待機しているレコードに touch() すると、GSI インデックスにはこの属性がソートキーとしてあるため、レコードがキューの最後に送信されます。次のコード例を参照してください。
他の方法と同様に、このコードはレコードのバージョン番号を 1 ずつ増やします。
同様の方法を作成して、レコードの優先度を更新できます。GSI が優先順位属性でソートしている限り、レコードを新しい優先順位の位置に移動させます。少しの創造性で、複合ソートキーを使用して、優先度とタイムスタンプの両方でレコードをソートできます。
sendToDLQ(ID)
レコードの処理に問題があった場合、たとえば、ダウンストリームで問題を引き起こす無効なデータを含むレコードを検出した場合、レコードをキューから取り出して修正アクションを行う必要があります。このメソッドでは、GSI インデックスがレコードを認識し、インデックスに表示する新しいキュー属性を作成する点で、このメソッドは enqueue() に似ています。次のコード例を参照してください。
次のスクリーンショットは、処理に失敗し、修正のために DLQ に送られたシップメントレコードを示しています。ご覧のとおり、レコードがさまざまな状態変化を経るにつれて、system_info の属性の数は時間とともに増加しました。

レコードが修正されたら、restore(ID) 呼び出しを使用して DLQ 属性を削除し、レコードをキューに戻すことができます。
キューの状態を確認する
クエリを使用して、キューの状態を確認できます。次のコード例を参照してください。
ソリューション GitHub リポジトリへのアクセス
プロジェクトコードの内容は、この記事で扱う内容よりもはるかに豊富です。詳細については、この記事の「GitHub リポジトリ」を参照してください。デモを試すには、プロジェクトをダウンロードしてください。デモをビルド、デプロイ、および実行するには、有効な AWS アカウント、Java 8+、および AWS CLI が必要です。ビルダーの場合、リポジトリは pom.xml を指定します。
README.md ファイルの手順では、このプロジェクトの AWS のサービスをビルドおよびデプロイする方法を説明しています。これが完了したら、CLI 実装で提供されるプロジェクトを使用して、キューイングソリューションを試すことができます。
改善点
DynamoDB の変更をストリーミングして、イベント駆動型ソリューションを作成できます。この変更は、あらゆるタイプの処理を実行できる Lambda 関数をトリガーします。ニーズに応じて、(別テーブル中の) DynamoDB のメトリクス値を更新したり、S3 に変更データキャプチャ (CDC) を保存して、さらに分析することができます。詳細については、「DynamoDB ストリームを使用したテーブルアクティビティのキャプチャ」を参照してください。
これらのアイデアのいずれかを実稼働の実装に使用する場合は、適切な例外処理を使用してください。このステップを逃すと、システムの動作が予測不能になるか、処理フローが中断する可能性があります。たとえば、peek() を使用しても例外を適切に処理しない場合、レコードは処理のために繰り返し再表示されます。この例では、キューイング SDK で sendToDLQ() メソッドを使用します。
この記事のソリューションは、専用のキューイングソリューションにある多くの機能を処理します。それらの 1 つは、注文に加えて、1 回の配信を保証することです。他のコンシューマーがキューからレコードを削除するのをブロックする必要がある場合は、peek() メソッドを使用できます。peek() はキューの先頭から反復します。他のレコードの system_info.queue_selected が 1 に設定されている場合、適格なレコードがないため、null オブジェクトが返されます。
まとめ
この記事では、DynamoDB の汎用性について説明しました。DynamoDB テーブルのモデリング、高度な GSI の使用、効率的なデータ処理のためのスパースインデックスの使用、さらに DynamoDB 属性を試用したプログラミングのヒントとテクニックについて説明しました。この記事では、次のプロジェクトを開始するためのすべてのコードも提供しました。使用するプログラミング言語に応じて、ニーズに合わせてコードを変更し、キューイング SDK からあらゆる種類のテーブルまたはレコードを抽出できます。ここで説明した設計概念の一部を使用すると、アーキテクチャに新しいコンポーネントを導入する必要なく、ソリューションに高度な機能を追加できます。
著者について

Zoran Ivanovic はカナダの AWS プロフェッショナルサービスのビッグデータプリンシパルコンサルタントです。Amazon で最大のビッグデータチームの 1 つを率いて 5 年の経験を積んだ後、彼は AWS に移り、AWS のサービスを活用してクラウドにミッションクリティカルなシステムを構築することに関心のある大企業のお客様と経験を共有しています。