Amazon SageMaker は、さまざまな問題の種類で使用できる組み込み機械学習 (ML) アルゴリズムを複数提供しています。これらのアルゴリズムは、高性能でスケーラブルな機械学習を提供し、速度、スケール、精度が最適化されています。 これらのアルゴリズムを使用して、ペタバイト規模のデータを学習できます。これらは、利用可能な他の実装の最高 10 倍のパフォーマンスを提供するように設計されています。このブログ記事では、教師なし学習の問題である k-means について探っていきます。さらに、Amazon SageMaker の組み込み k-means アルゴリズムの詳細も説明します。
k-means とは?
k-means アルゴリズムは、グループのメンバーがお互いにできる限り類似し、他のグループメンバーとできる限り異なるようなデータ内の離散グループを探します (以下の図を参照)。アルゴリズムで類似性を決定するために使用する属性を定義します。 k-means を定義するもう 1 つの方法は、クラスター内のすべての点が、他の中心よりもその中心に近い距離になるように、与えられたレコードセットに対して、k クラスター中心を見つけるクラスター問題です。
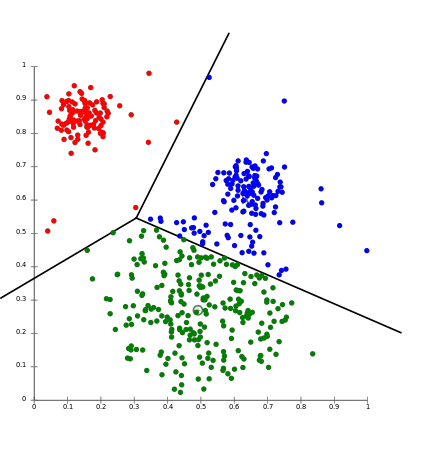
与えられたデータセットを示すこの図では、赤、青、緑の 3 つの明確なクラスターが見えます。各クラスターにはクラスター中心があります。各クラスターの点は、他のクラスター中心より、割り当てられているクラスター中心に空間的に近いことに注意してください。
数学的には、以下のように解釈できます。
前提条件: S={x1…xn}、次元 d の n ベクトルのセット S と整数 k
目標: 以下の式を最小化する、k クラスターセンターのセット C={µ1… µk } を探します。

k-means を使う場所
k-means アルゴリズムは、明示的にラベル付されていない、大きなデータセットのパターンまたはグループを見つけることに適しています。さまざまなドメインでのいくつかのユースケースを紹介します。
- E コマース
- 購入履歴またはクリックストリームアクティビティで顧客を分類。
- ヘルスケア
- 病気のパターン検出または成功する治療シナリオ。
- 画像検出で類似画像をグループ化する。
- 金融
- データセットの異常検知により、不正取引を検出。例えば異常な購入パターンによるクレジットカード詐欺の検出。
- テクノロジー
- 攻撃や悪意のある活動を識別するためのネットワーク侵入検知システムを構築。
- 気象
- 嵐を予測するなど、センサーデータ収集における異常の検出。
Amazon SageMaker の組み込み k-means アルゴリズムと、与えられたデータセットに対して最適な k を選択する技術によって、k-means の手順ごとのチュートリアルを提供します。
Amazon SageMaker k-means アルゴリズム
Amazon SageMaker の k-means 実装は、いくつかの独立した手法を組み合わせています。1 つ目は、Lloyds 反復の確率的変形で、詳細は [Scully’ 10 https://www.eecs.tufts.edu/~dsculley/papers/fastkmeans.pdf] にあります。2 つ目は、施設配置に基づいた理論的な手法で、[Mayerson’ 01 http://web.cs.ucla.edu/~awm/papers/ofl.pdf および移行の研究] にあります。3 つ目は分割統治法、またはコアセット手法 [Guha et al.’ 03 http://theory.stanford.edu/~nmishra/Papers/clusteringDataStreamsTheoryPractice.pdf] です。
高レベルのアイディアは、[Scully’ 10] の改変である確率的 Lloyd を実装することですが、必要以上の中心があります。データ処理フェーズでは、クラスターサイズを追跡し、小さなクラスターを持つ中心を無視し、施設配置アルゴリズムに発想を得た手法を使用して、新しい中心を開きます。必要以上に中心のある状態を取り扱うため、コアセットに発想を得た手法を使用し、データセットをより大きな中心のセットとして表現します。つまり、各中心がそのクラスター内のデータポイントを表します。このビューを考えると、ストリーム処理が完了後、k-means++ 初期化と Lloyds 反復を用いて、k-means のローカル版を実行し、より大きな中心セットをクラスタリングすることで、k 中心のモデルに状態を完成させます。
ハイライト
シングルパス。Amazon SageMaker k-means は、データのシングルパスだけで、良好なクラスタリングを得ることができます。このプロパティは驚異的な速さのランタイムに変換されます。さらに、増分更新が可能です。例えば、毎日増え続けるデータセットがあるとします。全クラスタリングセットが必要な場合には、毎日コレクション全体を再トレーニングする必要はありません。代わりに、新しいデータ量に比例して、時間的に更新することができます。
速度と GPU サポート。 シングルパスの実装以外にも、当社のアルゴリズムは驚くほど高速な速度を達成する GPU マシン上で実行できます。例えば、2300 万エントリ (約 37 GB) の 400 次元のデータセット処理では、k=500 クラスターを使用して、7 分間で完了します。コストは 1 ドル弱です。比較のため、人気のある高速な代替手法の Spark ストリーミング k-means では、26 分間の実行と、約 8.50 ドルの費用が必要です。
GPU を使用する利点としては、次元 d の各データポイントを処理するのに必要な時間は、クラスター数 k の場合に O(kd) です。多数のクラスターでは、GPU マシンは、CPU 実装よりもはるかに高速 (かつ安価) なソリューションを提供します。
精度。シングルパスが要求されますが、当社のアルゴリズムは、k-means++ (または k-means||) 初期化と Lloyds 反復を組み合わせた最先端のマルチパス実装としての、同じ平均二乗距離コストを達成します。比較のため、当社の実験では、[Scully ‘10] の論文を多少改変したシングルパスソリューションの現在の実装では、マルチパスソリューションより 1.5 ~ 2 倍大きな平均二乗距離でクラスタリングを達成しています。
開始方法
この例では、GDELT データセットで k-means を使用し、世界中のニュースを監視し、データを毎日、毎秒ごとに保存しています。この情報は、AWS パブリックデータセットプログラムの一部として、Amazon S3 で無料で入手できます。
データは 1979 年から 2013 年の履歴と、2013 年から現在までをカバーする毎日の更新の 2 種類の形式で、Amazon S3 に複数ファイルとして保存されます。 この例では、履歴形式に注目します。インタラクティブな検索目的で、1979 年のデータを取り込みます。必要なライブラリをインポートして、後から複数のファイルをダウンロードするためにこれを使用できるようにシンプルな関数を書きます。ユーザーデータバケットを Amazon S3 バケットに置き換えます。
import boto3
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from IPython.display import display
import io
import time
import copy
import json
import sys
import sagemaker.amazon.common as smac
import os
import mxnet as mx
from scipy.spatial.distance import cdist
import numpy as np
from numpy import array
import urllib.request
import gzip
import pickle
import sklearn.cluster
import sklearn
import re
from sagemaker import get_execution_role
# S3 バケットとプレフィックス
bucket = '<user-data-bucket>' # '<user-data-bucket>' # お使いのバケット名に置き換え'
prefix = 'sagemaker/DEMO-kmeans'
role = get_execution_role()
def get_gdelt(filename):
s3 = boto3.resource('s3')
s3.Bucket('gdelt-open-data').download_file('events/' + filename, '.gdelt.csv')
df = pd.read_csv('.gdelt.csv', sep='\t')
header = pd.read_csv('https://www.gdeltproject.org/data/lookups/CSV.header.historical.txt', sep='\t')
df.columns = header.columns
return df
data = get_gdelt('1979.csv')
data
ここでは 57 行があり、その一部はまばらに入力され、あいまいに名前が付けられ、この形式は機械学習には使いやすいものではありません。そのため、このユースケースでは、いくつかのコア属性を詳しく説明します。以下を使用します。
- EventCode: これは Actor1 が Actor2 に対して実行したアクションを記述する生の CAMEO アクションコードです。 詳細は (https://www.gdeltproject.org/data/documentation/CAMEO.Manual.1.1b3.pdf) を参照ください。
- NumArticles: これはイベントの 1 つ以上の言及を含むソース文書の合計数です。これは、イベントの「重要度」を評価する方法として使用できます。そのイベントについて議論が多いほど、重要である可能性が高くなります。
- AvgTone: これはイベントの 1 つ以上の言及を含むすべての文書の平均「トーン」です。スコアの範囲は -100 (非常にマイナス) から +100 (非常にプラス) までです。一般的な値の範囲は -10 から +10 で、0 は中立です。
- Actor1Geo_Lat: これはマッピングのための Actor1 ランドマークの中心点の緯度です。
- Actor1Geo_Long: これはマッピングのための Actor1 ランドマークの中心点の経度です。
- Actor2Geo_Lat: これはマッピングのための Actor2 ランドマークの中心点の緯度です。
- Actor2Geo_Long: これはマッピングのための Actor2 ランドマークの中心点の経度です。
これから機械学習のためのデータを準備します。他の年からこれを GDELT データセットにスケールするのに役立つ、いくつかの関数も使用します。
data = data[['EventCode', 'NumArticles', 'AvgTone', 'Actor1Geo_Lat', 'Actor1Geo_Long', 'Actor2Geo_Lat', 'Actor2Geo_Long']]
data['EventCode'] = data['EventCode'].astype(object)
events = pd.crosstab(index=data['EventCode'], columns='count').sort_values(by='count', ascending=False).index[:20]
#トレーニングデータを Sagemaker K-means に必要な protobuf 形式に変換するルーチン。
def write_to_s3(bucket, prefix, channel, file_prefix, X):
buf = io.BytesIO()
smac.write_numpy_to_dense_tensor(buf, X.astype('float32'))
buf.seek(0)
boto3.Session().resource('s3').Bucket(bucket).Object(os.path.join(prefix, channel, file_prefix + '.data')).upload_fileobj(buf)
#上記のアクター場所とイベントに基づいて、データをフィルタリング
def transform_gdelt(df, events=None):
df = df[['AvgTone', 'EventCode', 'NumArticles', 'Actor1Geo_Lat', 'Actor1Geo_Long', 'Actor2Geo_Lat', 'Actor2Geo_Long']]
df['EventCode'] = df['EventCode'].astype(object)
if events is not None:
df = df[np.in1d(df['EventCode'], events)]
return pd.get_dummies(df[((df['Actor1Geo_Lat'] == 0) & (df['Actor1Geo_Long'] == 0) != True) &
((df['Actor2Geo_Lat'] == 0) & (df['Actor2Geo_Long'] == 0) != True)])
#トレーニングを準備し、S3 に保存。
def prepare_gdelt(bucket, prefix, file_prefix, events=None, random_state=1729, save_to_s3=True):
df = get_gdelt(file_prefix + '.csv')
model_data = transform_gdelt(df, events)
train_data = model_data.sample(frac=1, random_state=random_state).as_matrix()
if save_to_s3:
write_to_s3(bucket, prefix, 'train', file_prefix, train_data)
return train_data
# 1979 年用のデータセットを使用。
train_79 = prepare_gdelt(bucket, prefix, '1979', events, save_to_s3=False
トレーニングデータを使用し、t 分布型確率的近傍埋め込み (TSNE) を使用して可視化します。 TSNE は高次元のデータを探索するために使用される非線形次元削減アルゴリズムです。
# 1979 年のデータセットから最初の 10000 データポイントを可視化するために TSNE を使用
from sklearn import manifold
tsne = manifold.TSNE(n_components=2, init='pca', random_state=1200)
X_tsne = tsne.fit_transform(train_79[:10000])
plt.figure(figsize=(6, 5))
X_tsne_1000 = X_tsne[:1000]
plt.scatter(X_tsne_1000[:, 0], X_tsne_1000[:, 1])
plt.show()
データを探索し、モデリングの準備ができたら、トレーニングを開始できます。この例では、1979 年から 1980 年のデータを使用しています。
BEGIN_YEAR = 1979
END_YEAR = 1980
for year in range(BEGIN_YEAR, END_YEAR):
train_data = prepare_gdelt(bucket, prefix, str(year), events)
# SageMaker k-means ECR 画像 ARN
images = {'us-west-2': '174872318107.dkr.ecr.us-west-2.amazonaws.com/kmeans:latest',
'us-east-1': '382416733822.dkr.ecr.us-east-1.amazonaws.com/kmeans:latest',
'us-east-2': '404615174143.dkr.ecr.us-east-2.amazonaws.com/kmeans:latest',
'eu-west-1': '438346466558.dkr.ecr.eu-west-1.amazonaws.com/kmeans:latest'}
image = images[boto3.Session().region_name]
2 ~ 12 までの k 値からトレーニングアルゴリズムを実行して、適切な数のクラスターを決定します。トレーニングジョブを並行して実行している場合は、平行トレーニングに必要なインスタンスを作成するために、アカウントに Amazon EC2 の制限があることを確認してください。上限を増やす要求については、AWS サービスの制限 文書をお読みください。この例では、24 ml.c4.8xlarge を並行で使用しています。run_parallel_jobs 変数を false に設定すると、ジョブを順番に実行できます。トレーニングジョブは約 8 分間実行しました。価格の詳細は、Amazon SageMaker 料金 ページをご覧ください。
from time import gmtime, strftime
output_time = strftime("%Y-%m-%d-%H-%M-%S", gmtime())
output_folder = 'kmeans-lowlevel-' + output_time
K = range(2, 12) # k が使用する範囲を変更
INSTANCE_COUNT = 2
run_parallel_jobs = True #一度に 1 つのジョブを実行するには、これを false にします。
#特に多数の EC2 インスタンスを 1 度に作成し、上限に達するのを避けたい場合。
job_names = []
# すべての k でジョブを起動する
for k in K:
print('starting train job:'+ str(k))
output_location = 's3://{}/kmeans_example/output/'.format(bucket) + output_folder
print('training artifacts will be uploaded to: {}'.format(output_location))
job_name = output_folder + str(k)
create_training_params = \
{
"AlgorithmSpecification": {
"TrainingImage": image,
"TrainingInputMode": "File"
},
"RoleArn": role,
"OutputDataConfig": {
"S3OutputPath": output_location
},
"ResourceConfig": {
"InstanceCount": INSTANCE_COUNT,
"InstanceType": "ml.c4.8xlarge",
"VolumeSizeInGB": 50
},
"TrainingJobName": job_name,
"HyperParameters": {
"k": str(k),
"feature_dim": "26",
"mini_batch_size": "1000"
},
"StoppingCondition": {
"MaxRuntimeInSeconds": 60 * 60
},
"InputDataConfig": [
{
"ChannelName": "train",
"DataSource": {
"S3DataSource": {
"S3DataType": "S3Prefix",
"S3Uri": "s3://{}/{}/train/".format(bucket, prefix),
"S3DataDistributionType": "FullyReplicated"
}
},
"CompressionType": "None",
"RecordWrapperType": "None"
}
]
}
sagemaker = boto3.client('sagemaker')
sagemaker.create_training_job(**create_training_params)
status = sagemaker.describe_training_job(TrainingJobName=job_name)['TrainingJobStatus']
print(status)
if not run_parallel_jobs:
try:
sagemaker.get_waiter('training_job_completed_or_stopped').wait(TrainingJobName=job_name)
finally:
status = sagemaker.describe_training_job(TrainingJobName=job_name)['TrainingJobStatus']
print("Training job ended with status: " + status)
if status == 'Failed':
message = sagemaker.describe_training_job(TrainingJobName=job_name)['FailureReason']
print('Training failed with the following error: {}'.format(message))
raise Exception('Training job failed')
job_names.append(job_name)
トレーニングジョブを開始しました。すべての仕事が完了したことを確認するために、ジョブを探してみましょう。これは並列してトレーニングジョブを実行する場合のみ使用されます。
while len(job_names):
try:
sagemaker.get_waiter('training_job_completed_or_stopped').wait(TrainingJobName=job_names[0])
finally:
status = sagemaker.describe_training_job(TrainingJobName=job_name)['TrainingJobStatus']
print("Training job ended with status: " + status)
if status == 'Failed':
message = sagemaker.describe_training_job(TrainingJobName=job_name)['FailureReason']
print('Training failed with the following error: {}'.format(message))
raise Exception('Training job failed')
print(job_name)
info = sagemaker.describe_training_job(TrainingJobName=job_name)
job_names.pop(0)
ここではエルボー法を使用して、 k-means の最適な k を特定します。
plt.plot()
colors = ['b', 'g', 'r']
markers = ['o', 'v', 's']
models = {}
distortions = []
for k in K:
s3_client = boto3.client('s3')
key = 'kmeans_example/output/' + output_folder +'/' + output_folder + str(k) + '/output/model.tar.gz'
s3_client.download_file(bucket, key, 'model.tar.gz')
print("Model for k={} ({})".format(k, key))
!tar -xvf model.tar.gz
kmeans_model=mx.ndarray.load('model_algo-1')
kmeans_numpy = kmeans_model[0].asnumpy()
distortions.append(sum(np.min(cdist(train_data, kmeans_numpy, 'euclidean'), axis=1)) / train_data.shape[0])
models[k] = kmeans_numpy
# エルボーをプロット
plt.plot(K, distortions, 'bx-')
plt.xlabel('k')
plt.ylabel('distortion')
plt.title('Elbow graph')
plt.show()
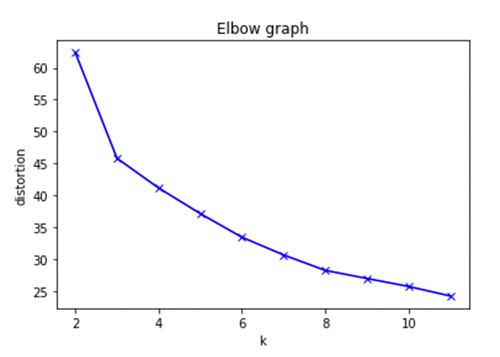
グラフでは、クラスター中心までのユークリッド距離をプロットします。k が大きくなるとエラーが減少することが分かります。これは、クラスター数が増えると、これらは小さくなり、ひずみも小さくなるためです。これにより、グラフでは「エルボー効果」が生じます。エルボー法の考え方は、減少率が急激に変化する k を選ぶことです。上のグラフに基づくと、このデータセットの良いクラスターサイズは k=7 です。完了したら、追加料金を避けるためにノートブックインスタンスを停止してください。
まとめ
この記事では、k-means を使用して一般的なクラスタリング問題を評価する方法を説明しました。Amazon SageMaker で k-means を使用することで、インフラストラクチャの設定や管理を行うことなく、分散トレーニングやマネージドモデルホスティングなどの追加の利点を提供します。始めるためには、Amazon SageMaker のサンプルノートブックを参照できます。
著者について
 Gitansh Chadha は AWS のソリューションアーキテクトです。サンフランシスコのベイエリアに住んでおり、お客様が AWS でアプリケーションを設計し最適化するサポートを行っています。時間があるときは、アウトドアを楽しみ、双子の娘たちと時間を楽しみます。
Gitansh Chadha は AWS のソリューションアーキテクトです。サンフランシスコのベイエリアに住んでおり、お客様が AWS でアプリケーションを設計し最適化するサポートを行っています。時間があるときは、アウトドアを楽しみ、双子の娘たちと時間を楽しみます。
 Piali Das は AWS AI アルゴリズムチームのソフトウェア開発エンジニアであり、Amazon SageMaker の組み込みアルゴリズムの構築を担当しています。彼女は一般的な科学アプリケーションプログラミングを楽しんでおり、機械学習と分散システムに興味を持っています。
Piali Das は AWS AI アルゴリズムチームのソフトウェア開発エンジニアであり、Amazon SageMaker の組み込みアルゴリズムの構築を担当しています。彼女は一般的な科学アプリケーションプログラミングを楽しんでおり、機械学習と分散システムに興味を持っています。
 Zohar Karnin は Amazon AI の主任科学者です。彼の対象とする研究分野は、大規模なオンライン機械学習アルゴリズムです。彼は Amazon SageMaker 用に無制限に拡張可能な機械学習アルゴリズムを開発しています。
Zohar Karnin は Amazon AI の主任科学者です。彼の対象とする研究分野は、大規模なオンライン機械学習アルゴリズムです。彼は Amazon SageMaker 用に無制限に拡張可能な機械学習アルゴリズムを開発しています。