Amazon Web Services ブログ
Amazon SageMaker Studio と Apache Spark を用いた Delta Lake からのデータのロードと変換
この記事は、“Load and transform data from Delta Lake using Amazon SageMaker Studio and Apache Spark” を翻訳したものです。
データレイクは、重要なビジネスデータを保存するための業界標準となっています。データレイクが選ばれる主な理由は、生データから前処理および後処理されたデータまで、あらゆる種類のデータを格納できることであり、構造化データおよび非構造化データの両方の形式が含まれる場合があります。あらゆる種類のデータを一元的に格納することで、最新のビッグデータアプリケーションは、必要となるあらゆる種類のデータをロード、変換、処理することができます。また、データをあらかじめ構造化したり変換したりすることなく、そのまま保存できるというメリットもあります。最も重要なのは、データレイクによって、さまざまな種類の分析や機械学習 (ML) プロセスからのデータへのアクセスを制御し、より良い意思決定を導くことができるようになることです。
AWS Lake Formation をはじめ、複数のベンダーがデータレイクアーキテクチャを作成しています。また、オープンソースのソリューションにより、企業は簡単にデータにアクセスし、ロードし、共有することができます。AWS クラウドにデータを保存するためのオプションの1つが Delta Lake です。Delta Lake ライブラリは、オープンソースの Apache Parquet ファイルフォーマットでの読み込みと書き込みを可能にし、ACID トランザクション、スケーラブルなメタデータ処理、統一されたストリーミングおよびバッチデータ処理といった機能を提供します。Delta Lake は、Amazon Simple Storage Service (Amazon S3) のようなオブジェクトレイヤーのストレージの上にデータを格納するために使用できるストレージレイヤー API を提供しています。
データは ML の心臓部であり、従来の教師ありモデルの学習は、一般的にデータレイクに保存されている高品質の履歴データへのアクセスなしでは不可能です。Amazon SageMaker は、ML ソリューションを構築するための汎用的なワークベンチを提供するフルマネージドサービスであり、データの取り込み、データの処理、モデルの学習、およびモデルのホスティングのための高度な専用ツールを提供します。Apache Spark は、データのロードと操作のための広範な API を備えた、最新のデータ処理の主力製品です。SageMakerは、Spark を使用してペタバイト規模のデータを準備し、高度に分散した ML ワークフローを実現する機能を備えています。本稿では、Amazon SageMaker Studio を使用して Delta Lake が提供する機能をどのように活用できるかを紹介します。
ソリューションの概要
本稿では、SageMaker Studio のノートブックを使用して、Delta Lake 形式で格納されたデータを簡単にロードして変換する方法について説明します。標準的な Jupyter ノートブックを使用して、CSV および Parquet 形式のテーブルデータを読み書きする Apache Spark コマンドを実行します。オープンソースのライブラリ delta-spark を使用すると、このデータにネイティブフォーマットで直接アクセスすることができます。このライブラリで用意されている多数の API 操作を活用して、データ変換の適用、スキーマの変更、タイムトラベルや as-of-timestamp クエリによりデータの特定のバージョンを引き出すことができます。
今回のサンプルノートブックでは、Spark DataFrame に生データをロードし、Delta テーブルを作成し、クエリを発行し、監査履歴を表示し、スキーマの進化 (schema evolution) を実演し、テーブルデータを更新するさまざまな方法を示しています。PySpark ライブラリの DataFrame API を使用して、データセットの属性を取り込み、変換します。また、delta-spark ライブラリを使用して、Delta Lake 形式のデータを読み書きし、スキーマと呼ばれる基礎となるテーブル構造を操作します。
Jupyter ノートブックから Python コードを作成し、実行するために、SageMaker の組み込み IDE である SageMaker Studio を使用しています。今回のノートブックと、本サンプルを自分で実行するためのその他のリソースを含む GitHub リポジトリを作成しました。こちらのノートブックでは、Delta Lake 形式で保管されたデータの扱い方を具体的に説明しています。この形式では、異なるデータストアにデータを複製することなく、その場でテーブルにアクセスすることができます。
本サンプルでは、Lending Club から一般に公開されている、顧客のローンデータを表すデータセットを使用します。あらかじめ、ローン審査が承認された (accepted) データファイル (accepted_2007_to_2018Q4.csv.gz) をダウンロードし、元の属性のサブセットを選択してあります。このデータセットは、クリエイティブ・コモンズ (CCO) ライセンスの下で利用可能です。
依存関係
delta-spark の機能を使用する前に、いくつか依存関係をインストールする必要があります。必要な依存関係を満たすために、いくつかのライブラリを Studio 環境にインストールします。Studio 環境は Docker コンテナとして実行され、Jupyter Gateway アプリを介してアクセスされます。
- Java と関連ライブラリにアクセスするための OpenJDK
- PySpark (Python 用 Spark) ライブラリ
- Delta Spark オープンソースライブラリ
これらのライブラリは、conda-forge、PyPIサーバー、または Maven リポジトリで公開されており、conda または pip を使用してインストールすることができます。
このノートブックは、SageMaker Studio 内で実行するように設計されています。Studio でノートブックを起動したら、Python 3 (Data Science) カーネルタイプを選択してください。さらに、PySpark コマンドをより高速に実行できるように、少なくとも 16 GB の RAM を持つインスタンスタイプ (ml.g4dn.xlarge など) を使用することをお勧めします。ノートブックの最初のいくつかのセルで以下のコマンドを使用して、必要な依存関係をインストールします。
インストールコマンドの実行が完了すると、ノートブックのコアとなるロジックを実行する準備が整います。
ソリューションの実装
Apache Spark のコマンドを実行するには、SparkSession オブジェクトをインスタンス化する必要があります。必要なインポートコマンドをリストに含めた後、いくつかの追加設定パラメータを設定することで SparkSession を構成します。spark.jars.packages というパラメータでは、Spark が delta コマンドを実行するために使用する追加ライブラリの名前を渡します。以下のコードの冒頭では、伝統的なMavenの座標 (groupId:artifactId:version) を使用してパッケージのリストを作成し、これらの追加パッケージを SparkSession に渡しています。
また、spark.sql.extensions と spark.sql.catalog.spark_catalog をキーとするパラメーターによって、Spark が Delta Lake 機能を適切に扱えるようになります。最後の設定パラメータである fs.s3a.aws.credentials.provider は ContainerCredentialsProvider クラスを追加し、コンテナ環境から利用できる AWS Identity and Access Management (IAM) ロールのパーミッションを Studio が検索できるようにします。このコードで、SageMaker Studio 環境用に適切に初期化された SparkSession オブジェクトが作成されます。
次のセクションでは、Lending Club 消費者ローンデータセットのサブセットを含むファイルを、デフォルトの S3 バケットにアップロードします。元のデータセットは非常に大きい (600 MB 以上) ので、このノートブックで使用するために1つの代表的なファイル (2.6 MB) を使用します。PySpark は、Hadoop ライブラリの追加機能を有効化するために s3a プロトコルを使用します。そのため、このノートブック全体のセルで s3 プロトコルの各ネイティブ S3 URI を修正して s3a を使用するようにしています。
以下のコードで Spark を使用して生データ(CSV または Parquet ファイルの両方のオプションがあります)を読み込み、loans_df という Spark DataFrame を返します。
次のスクリーンショットは、この結果の DataFrame から最初の10行を抜粋して表示したものです。
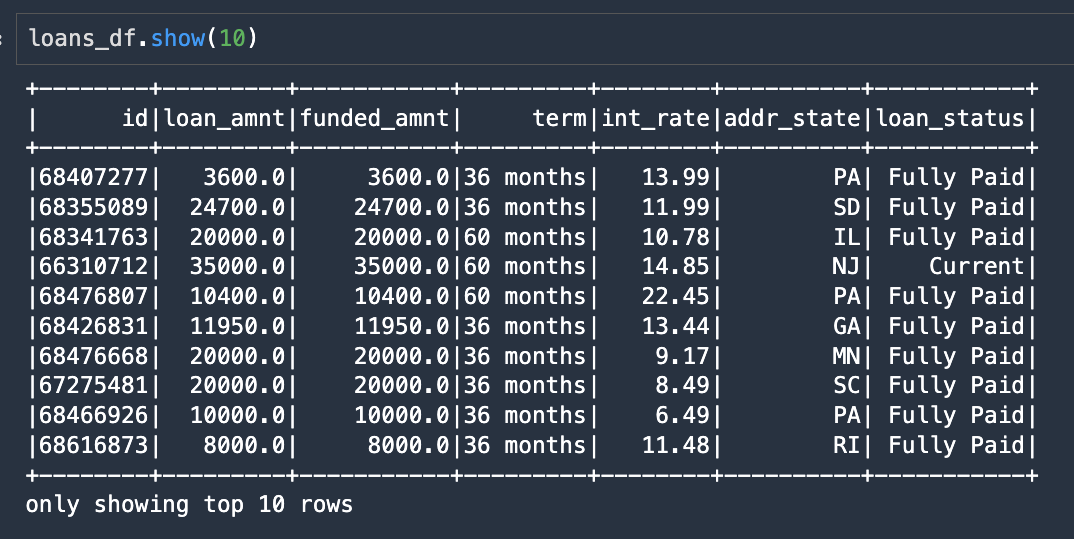
この DataFrame を Delta Lake のテーブルとして書き出すには、.format("delta") を指定し、テーブルデータを書き込む S3 URI の場所を指定すれば、1行で書き出すことができます。
次のいくつかのノートブックセルは、Delta Lake テーブルをクエリするためのオプションを提示しています。標準 SQL クエリを作成し、delta フォーマットとテーブルの場所を指定し、Spark SQL 構文を使ってこのコマンドを送信します。
次のスクリーンショットは、SQL クエリの結果を loan_amnt でソートしたものです。

Delta Lake テーブルとの対話
このセクションでは、delta-spark ライブラリの DeltaTable クラスを紹介します。DeltaTable は、プログラム的に Delta Lake のテーブルと対話するための主要なクラスです。このクラスは、テーブルに関する情報を発見するためのいくつかの静的メソッドを含んでいます。たとえば、isDeltaTable メソッドは、テーブルが delta 形式で保存されているかどうかを示すブール値を返します。
DeltaTable インスタンスは、Delta テーブルのパス (ここでは S3 の URI の場所) を使って作成することができます。次のコードでは、テーブルの変更の完全な履歴を取得します。
この出力は、テーブルが6つの変更を履歴に保存していることを示し、最新の3つのバージョンを表示しています。

スキーマの進化
このセクションでは、Delta Lake のスキーマの進化 (schema evolution) がどのように機能するかを説明します。デフォルトでは、delta-spark は制約を強制することにより、テーブルの書き込みを既存のスキーマに従わせます。しかし、特定のオプションを指定することで、テーブルのスキーマを安全に変更することができます。
まず、Delta テーブルからデータを読み込んでみましょう。このデータは delta 形式で書き出されているので、データを読み込む際に .format("delta") を指定し、Delta テーブルがある S3 URI を渡しています。次に、DataFrame を別の S3 ロケーションに書き戻し、スキーマの進化を示します。以下のコードをご覧ください。
次に、Spark DataFrame API を使用して、データセットに2つの新しいカラムを追加します。カラム名は funding_type とexcess_int_rate で、カラムの値は DataFrame の withColumn メソッドを使用して定数に設定しています。以下のコードをご覧ください。
データ型 (dtypes) を見てみると、追加カラムが DataFrame の一部に含まれていることがわかります。

次に、以下の Spark write コマンドで mergeSchema オプションを true に設定することで、スキーマの変更を有効化し、それによって Delta テーブルの基礎スキーマを変更することにします。
新しいテーブルの修正履歴を確認してみましょう。テーブルスキーマが修正されたことがわかります。
履歴のリストには、メタデータの各リビジョンが表示されます。

条件付きテーブル更新
DeltaTable update メソッドを使用して、引数を評価し、条件部が True と評価された場合に変換を適用することができます。この例では、loan_amnt が funded_amnt と等しい場合に、FullyFunded という値を funding_type 列に書き込んでいます。これは、テーブルのデータに対して条件付き更新を行うための強力なメカニズムです。
次のスクリーンショットは、こちらの結果を示しています。

テーブルデータに対する最後の変更箇所では、update メソッドに関数を渡す構文を利用しています。この関数では、ローンの int_rate 属性から 10.0% を減算して超過金利を計算します。もうひとつの SQL コマンドは、WHERE 句を使用して、int_rate が 10.0% より大きいレコードを検索し、この条件を満たすレコードを取り出します。
新しい excess_int_rate カラムには、int_rate から 10.0% を差し引いた値が正しく格納されています。
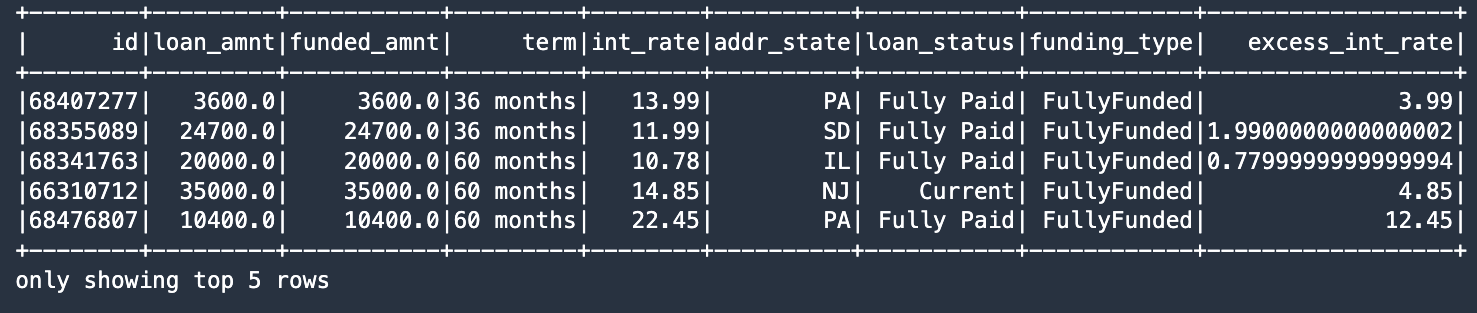
最後のノートブックセルは、Delta テーブルから再び履歴を取得し、今回はスキーマの変更が実行された後の変更点を表示します。
次のスクリーンショットは、こちらの結果を示しています。

まとめ
SageMaker Studio のノートブックを使用すると、オープンソースの Delta Lake 形式で保存されたデータと直接対話することができます。本稿では、オープンソースの delta-spark ライブラリを使用してこのデータを読み書きするサンプルコードを提供しました。このライブラリはデータセットを Delta テーブルとして作成、更新、管理することを可能にします。また、これらの重要な技術を組み合わせることで、既存のデータレイクから価値を引き出せることを実証し、SageMaker 上で Delta Lake の機能を利用する方法を紹介しました。
ノートブックサンプルでは、依存関係のインストール、Spark データ構造のインスタンス化、Delta Lake フォーマットでのDataFrame の読み書き、スキーマの進化などの機能利用について、エンドツーエンドのレシピを提供しています。これらの技術を統合することで、変革的なビジネス成果を効果的に生み出すことができます。
著者について
 Paul Hargis は、AWS、Amazon、Hortonworksなど複数の企業で機械学習に注力してきました。テクノロジーソリューションの構築と、それを最大限に活用する方法を人々に教えることを楽しんでいます。AWS 以前は、Amazon Exports and Expansions のリードアーキテクトとして、amazon.com の海外向けショッピングのエクスペリエンス向上に貢献しました。Paul は、お客様が実世界の問題を解決するために機械学習の取り組みを拡大するのを支援したいと考えています。
Paul Hargis は、AWS、Amazon、Hortonworksなど複数の企業で機械学習に注力してきました。テクノロジーソリューションの構築と、それを最大限に活用する方法を人々に教えることを楽しんでいます。AWS 以前は、Amazon Exports and Expansions のリードアーキテクトとして、amazon.com の海外向けショッピングのエクスペリエンス向上に貢献しました。Paul は、お客様が実世界の問題を解決するために機械学習の取り組みを拡大するのを支援したいと考えています。
 Vedant Jain は Sr. AI/ML Specialist Solutions Architectで、AWS の機械学習エコシステムからお客様が価値を引き出せるよう支援しています。AWS に入社する前は、Databricks、Hortonworks (現Cloudera)、JP Morgan Chase などさまざまな企業で ML/データサイエンスのスペシャリストとして活躍してきました。仕事以外では、音楽を作ること、有意義な人生を送るためにサイエンスを活用すること、世界中の美味しいベジタリアン料理を探求することに情熱を注いでいます。
Vedant Jain は Sr. AI/ML Specialist Solutions Architectで、AWS の機械学習エコシステムからお客様が価値を引き出せるよう支援しています。AWS に入社する前は、Databricks、Hortonworks (現Cloudera)、JP Morgan Chase などさまざまな企業で ML/データサイエンスのスペシャリストとして活躍してきました。仕事以外では、音楽を作ること、有意義な人生を送るためにサイエンスを活用すること、世界中の美味しいベジタリアン料理を探求することに情熱を注いでいます。
翻訳は機械学習パートナーソリューションアーキテクトの本橋が担当しました。