Amazon Web Services ブログ
AWS Entity Resolution でのルールベース・機械学習ベースマッチングの精度測定方法
この記事は Measuring the accuracy of rule or ML-based matching in AWS Entity Resolution (記事公開日 : 2025 年 9 月 29 日) を翻訳したものです。
エンティティマッチングのルールセットやモデルが実際に十分な精度を持っているかどうか、どのように判断すればよいでしょうか?複数のアイデンティティプロバイダーを評価する場合でも、独自のマッチングルールを構築する場合でも、企業は達成したい明確な精度レベルの基準と、異なるアプローチを客観的に測定・比較するためのフレームワークを確立する必要があります。アイデンティティプロセスを客観的に測定しない企業は、実装期間を数週間、場合によっては数ヶ月も延長してしまい、手順を繰り返したり、精度測定の手法に高コストな変更を加えたりすることになります。
本記事では、AWS Entity Resolution の既存機能である独自の機械学習 (ML) アルゴリズムを使用してモデルの精度をテストするアプローチについて説明し、実演します。AWS Entity Resolution は、複数のアプリケーション、チャネル、データストア間に保存された関連する顧客、製品、ビジネス、またはヘルスケア記録のマッチング、リンク、拡張を支援します。また、独自のデータまたは合成オープンソースデータセットを使用して結果を再現するために必要なすべてを提供します。
このフレームワークを使用することで、マッチングの精度を迅速に評価する方法を提供します。このプロセスは、ベンチマークを試みているあらゆるエンティティマッチングプロセスに適用できます。
精度が重要な理由
まず、精度とは何を意味するのでしょうか?本記事での精度とは、同一人物に属する記録を正しく識別し、かつ異なる人物の記録を誤ってマッチングしない頻度を指します。つまり、完全に正確なソリューションは、同一人物に属するすべての重複記録をマッチングし、断片を見逃すことなく、他の人物に属する記録に余分なデータをマッチングすることもありません。
これは直感的な概念ですが、一貫した測定は困難です。多くの企業が顧客データの重複排除・統合プロジェクトに着手する際、真陰性と真陽性を正確に測定する一貫した方法論や指標を持っていません。また、多くの企業は、顧客データで発生する複雑なエッジケースを捉える信頼できる個人情報データセットも不足しています。
100% クリーンなデータ、または十分に小さなサンプルセットで精度指標 100% を達成することは可能です。しかし、実世界のデータやより大きなデータボリュームでは、真の曖昧性を持つ無数のエッジケースが存在するため、100% の精度でマッチングすることは現実的ではありません。したがって、企業は不可能な目標を追い求める無限の実装サイクルに陥らないよう、精度について、測定可能な閾値を設定する必要があります。
今日、企業はこれまで以上に多くの断片化したデータを受け取っています。モバイルアプリのタップ、オンラインクリック、認証セッションのすべてが、企業が消費者行動を理解し、体験をパーソナライズし、運用を最適化するのに役立つデータを生成します。このデータを顧客の統一ビューにまとめることができる企業は、これらの洞察を使用してより良いパーソナライズされた体験を提供できます。また、より情報に基づいた製品、マーケティング、販売の意思決定を行うこともできます。
データからより多くの価値を引き出すことに焦点を当てている企業には、選択できるエンティティマッチングツールやサービスが幅広くあります。しかし、企業はしばしばソリューションの評価と実装で数ヶ月、場合によっては数年間停滞してしまいます。
最初の障害の一つは、アイデンティティマッチングフレームワークとアプローチを評価するための堅牢で一貫したフレームワークが不足していることです。どのアイデンティティマッチング手法が自社データに最も適しているか、企業はどう判断すればよいのでしょうか?精度に関する利害関係はますます高くなっています。顧客は、頻繁に利用するブランドや企業によりパーソナライズされた体験を期待しています。精度のベンチマークも、業界やユースケースに基づいて企業ごとに異なります。
アイデンティティ解決プロセスが特定のニーズに対応していることを企業が信頼するためには、本番データで実際に見られるエッジケースを含む信頼できるデータのベンチマークを作成し、顧客データを収集するあらゆるシステムから受け取る記録の種類に基づいて精度を定義する必要があります。
正解データセット (グラウンドトゥルース)
マッチングプロセスの精度を評価する最も広く受け入れられている方法は、プロセスの結果を手動で注釈付けされた正解データセット (真実セットとも呼ばれる) と比較することです。AI における正解データセットとは、事実として知られているデータを指し、モデル化されているシステムの期待されるユースケースの結果を表します。
このユースケースでは、正解データセットは、人間が手動でレビューし、マッチングすべきかどうかを注釈付けした記録ペアの小さなサブセットです。正解データセットは大きくある必要はありませんが、データで頻繁に発生するユースケースの代表的なセットを含むのに十分な大きさである必要があります。
ただし、正解データセットには個人識別情報 (PII) が必要であるため、企業は概念実証でそれらを共有または使用することについて慎重である必要があります。また、必要なすべてのセキュリティプロトコルが整っていることを確認する必要があります。正解データセットは、他のベンチマークデータセットと比較して、より良い再現可能な結果を得ることができます。
アイデンティティ解決精度測定の課題
顧客の単一ビューの価値は、そのデータが表現しようとしている現実世界をどれだけ忠実に反映しているかにほぼ依存しています。しかし、個々の記録のみを見ている場合、精度の評価基準が一定せず、変動してしまう可能性があります。企業は、アイデンティティマッチングのルールを構築したりアルゴリズムを使用したりする際に、明確な精度の閾値を持つ必要があります。そうでなければ、修正と変更の無限のプロセスに陥ってしまいます。これらの閾値は顧客によって異なります。
例えば、同じ業界の 2 つの企業が、データを収集する場所のコンテキストに基づいて異なる精度の閾値を設定する必要がある場合を見てみましょう。2 つの異なる小売業者、企業 A と B を考えてみます。
企業 A は、取引イベントとロイヤルティプログラムから顧客データを収集する実店舗の食料品小売業者です。これらの取引は、現金が使用された場合はデータがないか、世帯内で共有されたり企業によって使用されたりする可能性のあるクレジットカードトークンを使用します。さらに、カードベースのロイヤルティプログラムを通じてロイヤルティデータを収集する場合、空白、不完全なデータ、または複数の異なる人々に関連付けられた多くの共有住所と固定電話データを持つカードがある可能性があります。新しいカードや共有されたカードを提示することでロイヤルティ特典を受けることができるため、顧客が正確なデータを共有するインセンティブはありません。
企業 A は、不完全な名前データ、クレジットカードトークン、高い割合で共有されるデータを含む記録ペアでマッチングをテストする必要があります。さらに、顧客がデータを共有する方法に基づいて企業 A が可能な最も正確な解決レベルであるため、グループ化のための世帯レベルのマッチングにのみ関心があります。
これを、ウェブサイトですべての取引を行うオンライン小売業者である企業 B と対比してみましょう。ほぼすべての顧客がメールアドレスで認証し、閲覧行動に関連付けられたプロファイルを持っています。顧客は実際に購入した商品を受け取るために、正確な住所、名前、メールアドレスの値を共有する必要があります。同じ世帯内の個人でも、個人のアカウントやメールアドレスを通じて領収書を受け取り、返品を開始する方が迅速であるため、自分の名前とメールアドレスで購入する可能性が高くなります。
実店舗小売業者である企業 A とは異なり、企業 B は個人レベルでユーザーをマッチングできます。配送先住所と電話番号が共有される可能性があるため、マッチングする前により高い割合の共有属性を要求することができます。しかし、他の多くの信頼できるデータが世帯のメンバーや重複するデータを持つユーザーを区別することができます。
両方の小売業者は、自社のデータに存在するシナリオを反映し、許容可能なマッチングの独自の閾値を持つ独自の正解データセットを作成すれば、最良の結果を得られるでしょう。このセットには、まとめるべき記録の断片 (真陽性) と、多くの特徴を共有するが分離しておく必要がある記録 (真陰性) の両方のテストケースを含める必要があります。マッチングに使用するために、これらのテストケースは、記録がマッチングすべきかどうかを示す正解データセットとして注釈付けされる必要があります。
データサイエンスコミュニティでは、精度を測定する最も標準的な方法は、F1 スコアと呼ばれる指標です。F1 スコアは、正解データセットに対するモデルパフォーマンスの 2 つの主要な側面である精密度と再現率を平均化した指標です。
エンティティマッチングモデルのコンテキストでは、精密度は、正解データセットでマッチングされていない 2 つの記録を誤ってまとめてしまう偽陽性マッチをモデルがどの程度防げるかを指します。この文脈での再現率は、正解データセットでグループ化されている記録をモデルがどの程度正しくまとめることができるかを指します。したがって、正解データセットには、まとめるべき記録ペアと、類似性を共有するが一緒に属さない記録ペアの両方が含まれている必要があります (図 1 参照) 。
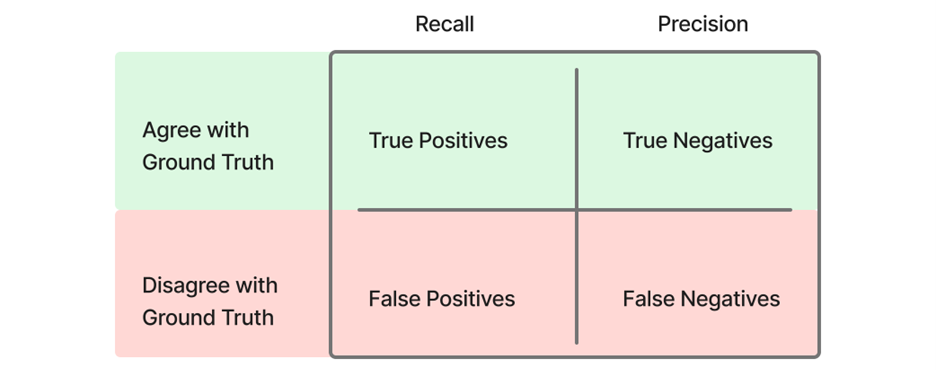
図 1 – 再現率と精密度を定義する表
F1 スコアは、精密度と再現率の調和平均として定義され、次のように計算されます :
F1 スコア = 2 × [(精密度 × 再現率) / (精密度 + 再現率)]
精密度は、真陽性 (正しいマッチ) を、真陽性と偽陽性 (不正なマッチ) の合計で割った比率です。再現率は、真陽性を、真陽性および偽陰性 (見逃されたマッチ) の合計で割った比率です。F1 スコアは 0 から 1 の範囲で、値が高いほど精密度と再現率のバランスが良いことを示します。このバランスは、異なる業界が精密度または再現率を異なって優先するため重要です。例えば、ヘルスケア業界はしばしば偽陽性を最小化することを目指し (精密度を重視) 、広告業界は真陽性を最大化することに焦点を当てます (再現率を重視) 。
データ評価のウォークスルー
精度をテストするために顧客が使用できる公開データセットはそれほど多くありません。これらの分析でよく使用されるデータセットの一つが、オハイオ州有権者ファイルです。オハイオ州有権者ファイルは、人物マッチングのためのよく知られた公開データセットです。オハイオ州の有権者情報から名前、住所、生年月日を含む 105,000 件の記録が含まれています。
オハイオ州有権者ファイルは、実際のデータを含むため、開発者による多くのエンティティマッチングソリューションで最も一般的に使用される正解データセットです。しかし、実際の顧客データの代理としての有用性を制限するいくつかの欠点があります。電話番号とメールフィールドが不足しており、正規化されていない郵便住所などのよくあるデータ品質問題がなく、記録が非常に完全である傾向があります。
これらのより複雑でデータ品質の低い例に対応するため、AWS Entity Resolution Data Science チームは、こうした困難なエンティティ解決シナリオをより忠実に再現する新しい合成データセットを開発し、オープンソース化しました。これは、BPID: A Benchmark for Personal Identity Deduplication と呼ばれています。BPID は、名前、メール、電話、住所、生年月日フィールドにわたる複雑なパターンを持つ 2 万件の合成記録を含む、はるかに困難なデータセットです。BPID は、世界有数の自然言語処理会議の一つである Empirical Methods in Natural Language Processing (EMNLP) 2024 で発表されました。
以下の例では、AWS Entity Resolution の機能である機械学習ベースのマッチングモデルの精度を測定する手順を実演します。BPID からのオープンソースの正解データセットを使用します。
前提条件
- AWS アカウント
- データマッチング概念の基本的理解
- 分析実行のための Jupyter Notebook または類似環境
- Python とデータ処理ライブラリの知識
1. データのダウンロード
まず、テストで使用するデータをダウンロードする必要があります。BPID データセットをダウンロードして解凍します。精度評価には matching_dataset.jsonl を使用します。以下は、BPID データセットからのペアの例です:
2. テストと正解データセットの前処理
テストデータから 2 つのデータセットを準備します。1 つは入力用、もう 1 つはマッチング後の精度測定用の正解データセットです。matching_dataset.jsonl をプロセッサに必要なスキーマに変換する必要があります。AWS Entity Resolution で使用するためにこのデータを準備するには、まずローカルまたは仮想環境にデータを読み込む必要があります。
次に、入力レコードをフラット化・変換して、AWS Entity Resolution で読み込める形式にします。ラベルは以下に概説されているように別のファイルに保存されます:
次に、以下のスクリプトを実行し、精度スコア計算用にラベルを分離・準備します:
次に、以下を使用して処理されたプロファイルとラベルを json ファイルとして保存します:
この前処理を実行した後、プロファイルデータ (BPID_matching_profiles_processed.jsonl) は以下のようになります:
付随するラベルファイル (BPID_matching_label.jsonl) は以下のようになります:
3. マッチングワークフローの実行
テストデータが変換されたら、評価予定のワークフローに対してマッチングワークフローを実行します。
目標は、入力データセット内の任意の 2 つの記録が同一人物に属するかどうかを肯定的または否定的にマッチングできるマッチング結果を取得することです。この手順はサービスによって異なります。
最後に、AWS Entity Resolution マッチングワークフローを実行します。以下は、AWS Entity Resolution からの出力例です:
4. F1 スコアの計算
マッチング結果を取得した後、生データのラベル情報とマッチング結果を使用して F1 スコア指標を計算できます。データセット matching_dataset.jsonl 内の各ペアには、マッチまたは非マッチのラベルがあります。各ペアについて、マッチング結果でラベルと一致するかどうかを確認します。その後、このペアを 4 つのカテゴリのいずれかに割り当てます:
- 真陽性 (TP) :ラベルとマッチング結果の両方がマッチを示唆
- 偽陽性 (FP) :ラベルは「非マッチ」だがマッチング結果はマッチ
- 真陰性 (TN) :ラベルとマッチング結果の両方が非マッチを示唆
- 偽陰性 (FN) :ラベルは「マッチ」だがマッチング結果は非マッチ
これら 4 つのタイプの数を取得した後、以下を計算できます:
精密度 = TP / (TP + FP)
再現率 = TP / (TP + FN)
F1 スコア = 2 × [(精密度 × 再現率) / (精密度 + 再現率)]
独自のベンチマークテストの実行
ベンチマークプロセスを実行することで、これらの結果を再現できます。以下は、機械学習ベースマッチングのための AWS Entity Resolution でこのプロセスを実行するために必要な手順とノートブックの概要です。手順とデータは、ルールベースマッチングワークフローまたは他のプロバイダーからのマッチングプロセスの精度を評価するために再利用することもできます。BPID データには実際の顧客 PII が含まれていないため、基礎となる参照グラフを使用するプロバイダーを評価するために使用できます。
アイデンティティ解決プロセスの改善を目指すチームには、以下をお勧めします:
- 独自の評価のための BPID データセットのダウンロード
- AWS Entity Resolution の機械学習ベースマッチング機能の探索
- ベンダー評価における主要指標としての F1 スコアの検討
結論
企業が顧客データを統合するために使用するルールやアルゴリズムの精度を測定することは非常に困難です。ほとんどの企業は、ベンチマークとなる注釈付き正解データセットを持たず、測定のための一貫した方法論を欠いている可能性があります。
AWS Entity Resolution を使用したアイデンティティ解決サービスの包括的な精度評価の実施方法を実演しました。ベンチマーク手法、オープンソースデータセット、そして読者が精度評価を再現できるステップバイステップガイドを提供しました。
AWS の担当者に連絡して、お客様のビジネスの加速をどのように支援できるかをご確認ください。
参考資料
- AWS Entity Resolution の高度なルールベースファジーマッチングを使用して不完全なデータを解決する
- 顧客の統一ビューを構築する方法
- AWS でのエンティティ解決のためのルール推奨生成に関するガイダンス
本稿の翻訳は、ソリューションアーキテクトの髙橋が担当しました。原文はこちら。