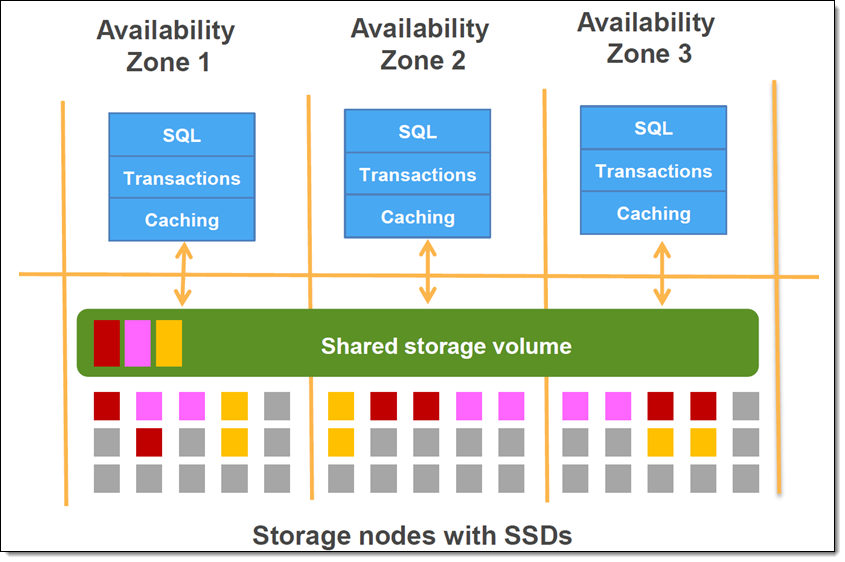
Amazon Aurora は、豊富なネットワーキング、処理、およびクラウド上で利用可能なストレージリソースを最大限に活用できるように設計されたリレーショナルデータベースです。Amazon Aurora は、MySQL と PostgreSQL との互換性をユーザー側で維持することができ、最新かつ専用の分散ストレージシステムを使用しています。データは、3 つの異なる AWS アベイラビリティゾーンに分散する数百のストレージノードにストライプ化され、高速 SSD ストレージの各ゾーンに 2 つづつコピーを作成します。次のようになります (Amazon Aurora の開始方法から抜粋):
新しくなった Parallel Query
Amazon Aurora を立ち上げた際、同じスケールアウト設計原理を、他のデータベーススタックの層にも適用するつもりであることをお伝えしていました。今日は、今後の予定についてお話したいと思います。
上に描かれたストレージ層の各ノードは、大きな処理能力も持ち合わせています。Amazon Aurora は現在、分析クエリ (通常は、かなりサイズが大きいテーブルのすべてまたは大部分を処理するクエリ) を使用して、処理能力を最大限に活用することができます。また、数百または数千のストレージノード全体を並列で実行することで、処理スピードは2 桁台に近づいています。今回のニューモデルは、ネットワーク、CPU、およびバッファプールの競合を減らすため、同じテーブル上で分析クエリとトランザクションクエリを同時に実行でき、かつ両クエリで高いスループットを維持します。
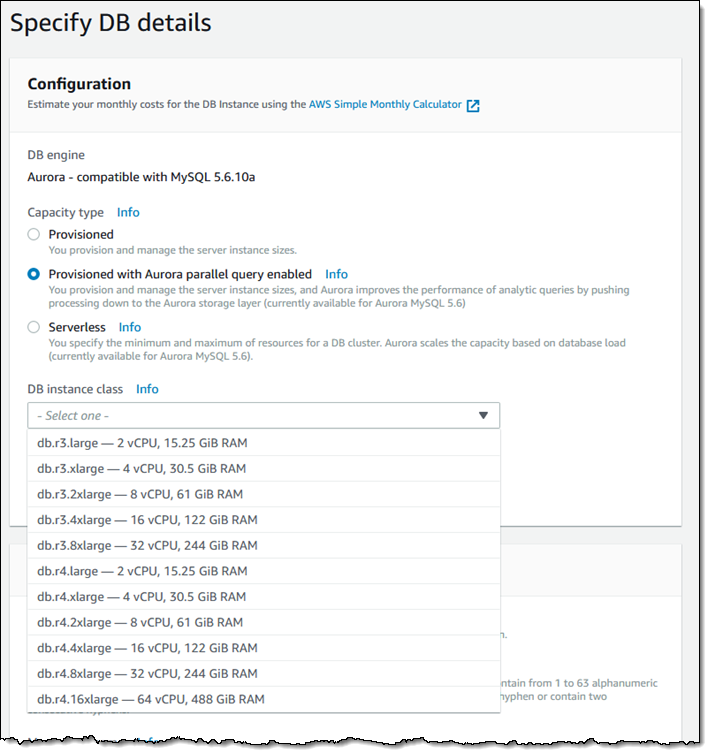
インスタンスクラスは、指定された時間にアクティブにできる並列クエリの数を決定します:
- db.r*.large – 1 つの同時並列クエリセッション
- db.r*.xlarge – 2 つの同時並列クエリセッション
- db.r*.2xlarge – 4 つの同時並列クエリセッション
- db.r*.4xlarge – 8 つの同時並列クエリセッション
- db.r*.8xlarge –16 個の同時並列クエリセッション
- db.r4.16xlarge – 16 個の同時並列クエリセッション
Aurora_pq パラメーターを使用して、グローバルレベルおよびセッションレベルで、並列クエリの使用を有効または無効にすることができます。
並列クエリは、200を超える単一テーブルの述語およびハッシュ結合のパフォーマンスを向上させることが可能です。Amazon Aurora のクエリオプティマイザは、テーブルのサイズとすでにメモリー内にあるテーブルデータの量に基づいた Parallel Query を使用するかどうかを自動的に判断します。aurora_pq_force セッション変数を使用して、テスト目的でオプティマイザをオーバーライドすることもできます。
実行中の Parallel Query
Parallel Query の機能を使用するには、新しいクラスタを作成する必要があります。最初から作成することも、あるいはスナップショットを復元することもできます。
Parallel Query をサポートするクラスタを作成するには、Provisioned with Aurora parallel query enabled をCapacity typeとして選択するだけです :
CLI を使用してテスト用の 100 GB のスナップショットを復元してから、TPC-H ベンチマークからクエリの 1 つを調べました。基本的なクエリは次のとおりです :
SELECT
l_orderkey,
SUM(l_extendedprice * (1-l_discount)) AS revenue,
o_orderdate,
o_shippriority
FROM customer, orders, lineitem
WHERE
c_mktsegment='AUTOMOBILE'
AND c_custkey = o_custkey
AND l_orderkey = o_orderkey
AND o_orderdate < date '1995-03-13'
AND l_shipdate > date '1995-03-13'
GROUP BY
l_orderkey,
o_orderdate,
o_shippriority
ORDER BY
revenue DESC,
o_orderdate LIMIT 15;
EXPLAIN コマンドは、Parallel Query の使用を含むクエリ計画を示しています :
+----+-------------+----------+------+-------------------------------+------+---------+------+-----------+--------------------------------------------------------------------------------------------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+----------+------+-------------------------------+------+---------+------+-----------+--------------------------------------------------------------------------------------------------------------------------------+
| 1 | SIMPLE | customer | ALL | PRIMARY | NULL | NULL | NULL | 14354602 | Using where; Using temporary; Using filesort |
| 1 | SIMPLE | orders | ALL | PRIMARY,o_custkey,o_orderdate | NULL | NULL | NULL | 154545408 | Using where; Using join buffer (Hash Join Outer table orders); Using parallel query (4 columns, 1 filters, 1 exprs; 0 extra) |
| 1 | SIMPLE | lineitem | ALL | PRIMARY,l_shipdate | NULL | NULL | NULL | 606119300 | Using where; Using join buffer (Hash Join Outer table lineitem); Using parallel query (4 columns, 1 filters, 1 exprs; 0 extra) |
+----+-------------+----------+------+-------------------------------+------+---------+------+-----------+--------------------------------------------------------------------------------------------------------------------------------+
3 rows in set (0.01 sec)
Extras列の関連部分は、次のとおりです :
Using parallel query (4 columns, 1 filters, 1 exprs; 0 extra)
Parallel Query を使用すると、クエリは 2 分以内に実行されます。
+------------+-------------+-------------+----------------+
| l_orderkey | revenue | o_orderdate | o_shippriority |
+------------+-------------+-------------+----------------+
| 92511430 | 514726.4896 | 1995-03-06 | 0 |
| 593851010 | 475390.6058 | 1994-12-21 | 0 |
| 188390981 | 458617.4703 | 1995-03-11 | 0 |
| 241099140 | 457910.6038 | 1995-03-12 | 0 |
| 520521156 | 457157.6905 | 1995-03-07 | 0 |
| 160196293 | 456996.1155 | 1995-02-13 | 0 |
| 324814597 | 456802.9011 | 1995-03-12 | 0 |
| 81011334 | 455300.0146 | 1995-03-07 | 0 |
| 88281862 | 454961.1142 | 1995-03-03 | 0 |
| 28840519 | 454748.2485 | 1995-03-08 | 0 |
| 113920609 | 453897.2223 | 1995-02-06 | 0 |
| 377389669 | 453438.2989 | 1995-03-07 | 0 |
| 367200517 | 453067.7130 | 1995-02-26 | 0 |
| 232404000 | 452010.6506 | 1995-03-08 | 0 |
| 16384100 | 450935.1906 | 1995-03-02 | 0 |
+------------+-------------+-------------+----------------+
15 rows in set (1 min 53.36 sec)
セッション用の Parallel Query を無効にできます (RDS カスタムクラスタパラメータグループを使用するとより効果が持続します):
set SESSION aurora_pq=OFF;
クエリの実行は、Parallel Query がないと非常に遅くなります :
+------------+-------------+-------------+----------------+
| l_orderkey | o_orderdate | revenue | o_shippriority |
+------------+-------------+-------------+----------------+
| 92511430 | 1995-03-06 | 514726.4896 | 0 |
...
| 16384100 | 1995-03-02 | 450935.1906 | 0 |
+------------+-------------+-------------+----------------+
15 rows in set (1 hour 25 min 51.89 sec)
これは db.r4.2xlarge インスタンス上にありました。他のインスタンスサイズ、データセット、アクセスパターン、およびクエリは、異なる動作をします。また、クエリオプティマイザをオーバーライドし、テスト目的で Parallel Query を使用することもできます :
set SESSION aurora_pq_force=ON;
知っておくべきこと
Amazon Aurora Parallel Query を使い始める際、留意すべき点をいくつかご紹介します :
エンジンのサポート – MySQL 5.6 のサポートはもうすぐ始まります。MySQL 5.7 および PostgreSQL のサポート準備にも、現在取り組んでいます。
テーブル形式 – テーブル行形式は COMPACT である必要があります。パーティションテーブルのサポートはありません。
データタイプ – TEXT、BLOB、および GEOMETRY のデータタイプにはサポートがありません。
DDL – テーブルには、保留中の高速オンライン DDL オペレーションはありません。
費用 – Parallel Query の利用には、追加料金はありません。ただし、ストレージに直接アクセスできるため、IO コストが増加する可能性があります。
試してみる
新しい機能はすでにご利用可能です。今日からすぐに使用を開始できます!
— Jeff;