Amazon Web Services ブログ
Amazon MSK Express ベースのクラスターのオンデマンドスケーリングとスケジュールスケーリング
本記事は 2026 年 1 月 22 日 に公開された「On-demand and scheduled scaling of Amazon MSK Express based clusters」を翻訳したものです。
現代のストリーミングワークロードは非常に動的で、トラフィック量は時間帯、ビジネスサイクル、イベント駆動のバーストに応じて変動します。一貫したスループットとパフォーマンスを維持しながら不要なコストを抑えるには、Apache Kafka クラスターを動的にスケールアップ・ダウンする必要があります。例えば、EC サイトでは季節セール中にトラフィックが急増し、金融システムでは市場の取引時間中に負荷が急上昇します。クラスターをスケーリングすれば、増加する受信スループットに応じて容量を調整でき、効率的なリソース活用とコストパフォーマンス向上を実現できます。
Amazon Managed Streaming for Apache Kafka (Amazon MSK) の Express ブローカーは、需要に応じてクラスターを動的にスケーリングするための重要なコンポーネントです。Express ベースのクラスターは、Amazon MSK Provisioned クラスターと比較して、3 倍のスループット、20 倍高速なスケーリング、90% 高速なブローカー復旧を実現します。さらに、Express ブローカーは 180 倍高速なオペレーションパフォーマンスを実現するインテリジェントリバランシングをサポートしており、パーティションがブローカー間で自動的かつ均等に分散されます。インテリジェントリバランシングはすべての新しい Express ベースのクラスターでデフォルトで有効になっており、追加コストはかかりません。クラスター容量を変更する際の手動パーティション管理が不要になります。インテリジェントリバランシングはクラスターの健全性を自動的に追跡し、リソースの不均衡が検出されるとパーティションの再分散をトリガーして、ブローカー間のパフォーマンスを維持します。
本記事では、インテリジェントリバランシングの使用方法と、Amazon CloudWatch メトリクスや事前定義されたスケジュールに基づいて Express ベースのクラスターを水平方向(ブローカーの追加・削除)に動的にスケーリングするカスタムソリューションの構築方法を説明します。このソリューションで、クラスターのパフォーマンスを維持しながら負荷を最小限に抑えた容量管理を実現できます。
Kafka スケーリングの概要
Kafka クラスターのスケーリングでは、データの均等な分散と中断のないサービスを確保しながら、クラスターにブローカーを追加または削除します。新しいブローカーを追加する際は、クラスター全体で負荷を均等に分散するためにパーティションの再割り当てが必要です。再割り当ては通常、Kafka コマンドラインツール(kafka-reassign-partitions.sh)を使用するか、再割り当て計画を適切に計算・実行する Cruise Control などの自動化フレームワークを使用して手動で実行されます。スケールイン操作では、削除対象のブローカーでホストされているパーティションを最初に他のブローカーに移行し、対象ブローカーを空にしてから廃止する必要があります。
Kafka の動的スケーリングの課題
スケーリングの複雑さは、基盤となるストレージモデルに大きく依存します。ブローカーデータが完全にローカルストレージに存在するデプロイメントでは、スケーリングにブローカー間の物理的なデータ移動が伴い、パーティションサイズとレプリケーションファクターによってはかなりの時間がかかる場合があります。一方、階層型ストレージを使用する環境では、データの大部分が Amazon Simple Storage Service (Amazon S3) などのリモートオブジェクトストレージに移されるため、スケーリングは主にメタデータ駆動の操作になります。データ転送の負荷が大幅に削減され、ブローカーの追加と削除の両方が高速化されるため、より弾力的で運用効率の高い Kafka クラスターを実現できます。
しかし、ストレージ、データ移動、ブローカーリソース使用率の相互作用により、Kafka のスケーリングは依然として簡単な操作ではありません。パーティションがブローカー間で再割り当てされると、大量のデータをネットワーク経由でコピーする必要があり、ネットワーク帯域幅の飽和、ストレージ帯域幅の枯渇、CPU 使用率の上昇につながることがよくあります。データ量とレプリケーションファクターによっては、パーティションのリバランシングに数時間かかる場合があり、その間クラスターのパフォーマンスとスループットが一時的に低下し、データ移動を抑制するための追加設定が必要になることがよくあります。Cruise Control などのツールはリバランシングを自動化しますが、別の複雑さが生じます。適切なリバランシング目標の組み合わせ(ディスク容量、ネットワーク負荷、レプリカ分散など)を選択するには、Kafka の内部構造と速度、バランス、安定性間のトレードオフについて深い理解が必要です。そのため、効率的なスケーリングは最適化問題であり、ストレージ、コンピューティング、ネットワークリソースの慎重なオーケストレーションが求められます。
Express ブローカーによるスケーリングの簡素化
Express ブローカーは、コンピューティングとストレージを分離したアーキテクチャにより Kafka のスケーリングを管理します。この設計により、事前プロビジョニングなしで無制限のストレージが可能になり、クラスターのサイジングと管理が大幅に簡素化されます。コンピューティングとストレージリソースの分離により、Express ブローカーは標準の MSK ブローカーよりも高速にスケーリングでき、数分以内にクラスターを迅速に拡張できます。Express ブローカーでは、管理者は必要に応じて垂直方向と水平方向の両方で容量を調整でき、過剰プロビジョニングが不要になります。このアーキテクチャはスケーリング操作中も持続的なブローカースループットを提供し、Express ブローカーは m7g.16xl インスタンスで 500 MBps の受信と 1000 MBps の送信を処理できます。Express ベースのクラスターでのスケーリングプロセスの詳細については、Express brokers for Amazon MSK: Turbo-charged Kafka scaling with up to 20 times faster performance を参照してください。
高速スケーリング機能に加えて、Express ベースのクラスターでブローカーを追加または削除すると、インテリジェントリバランシングがパーティションを自動的に再分散してブローカー間のリソース使用率を均等化します。単一の更新操作でスケールインとスケールアウトが可能になり、クラスターは最高のパフォーマンスで動作し続けます。インテリジェントリバランシングは新しい Express ブローカークラスターでデフォルトで有効になっており、リソースの不均衡やホットスポットがないかクラスターの健全性を継続的に監視します。例えば、パーティションの不均等な分散やトラフィックパターンの偏りにより特定のブローカーが過負荷になった場合、インテリジェントリバランシングはパーティションを使用率の低いブローカーに自動的に移動してバランスを回復します。
最後に、Express ベースのクラスターは、ブローカーの追加・削除に伴いクライアントがシームレスに接続できるよう、ブローカーブートストラップ接続文字列のクライアント設定を自動化します。Express ベースのクラスターは、クラスター内のブローカーとは独立した 3 つの接続文字列(アベイラビリティーゾーンごとに 1 つ)を提供します。クライアントはこれらの接続文字列を設定するだけで、ブローカーの追加・削除時も一貫した接続を維持できます。Express ベースのクラスターの主要機能(高速スケーリング、インテリジェントリバランシング、動的ブローカーブートストラップ)は、Kafka クラスターの動的スケーリングを実現するために不可欠です。次のセクションでは、これらの機能を使用して Express ベースのクラスターのスケーリングプロセスを自動化する方法を説明します。
オンデマンドスケーリングとスケジュールスケーリング
Express ブローカーの高速スケーリング機能とインテリジェントリバランシングを活用して、Kafka クラスターリソースを最適化する柔軟で動的なスケーリングソリューションを構築できます。パフォーマンスニーズとコスト効率のバランスを取る自動スケーリングには、オンデマンドスケーリングとスケジュールスケーリングの 2 つの主要なアプローチがあります。
オンデマンドスケーリング
オンデマンドスケーリングは、クラスターのパフォーマンスを追跡し、容量の需要に応じて対応します。ワークロードパターンでトラフィックスパイクが発生するシナリオに対応できます。オンデマンドスケーリングは、CPU 使用率やブローカーごとのネットワーク受信・送信スループットなどの Amazon MSK パフォーマンス指標を追跡します。インフラストラクチャメトリクスに加えて、ソリューションは CloudWatch メトリクスを使用したビジネスロジック駆動のスケーリング判断もサポートしています。
ソリューションは、スケーリングアクションが必要かどうかを判断するために、設定可能なしきい値に対してパフォーマンスメトリクスを継続的に評価します。ブローカーが一定期間にわたって容量しきい値を超えて動作している場合、Amazon MSK API を呼び出してクラスターのブローカー数を増やします。本記事のソリューションは現在、水平スケーリング(ブローカーの追加・削除)のみをサポートしています。インテリジェントリバランシングは、追加された新しいブローカー全体に負荷を分散するためにパーティションを自動的に再分散します。同様に、使用率がしきい値を下回ると、ソリューションは Amazon MSK API を呼び出してブローカーを削除します。リバランシングプロセスは、削除対象のブローカーからクラスター内の他のブローカーにパーティションを自動的に移動します。このソリューションでは、ブローカー追加時に新しいブローカーへのリバランシングをサポートするために、トピックに十分なパーティションが必要です。
次の図は、オンデマンドスケーリングのワークフローを示しています。

スケジュールスケーリング
スケジュールスケーリングは、時間ベースのトリガーを使用してクラスター容量を調整します。トラフィックパターンが営業時間やスケジュールと相関するアプリケーションに適しています。例えば、EC サイトは顧客アクティビティがピークになるセール期間中にスケジュールスケーリングの恩恵を受けます。スケジュールスケーリングは、営業時間中のクラスター変更操作を避けたいお客様にも有用です。ソリューションは、設定可能なスケジュールを使用して、営業時間前に予想されるトラフィックを処理するためにクラスター容量をスケールアウトし、営業時間後にコストを削減するためにスケールインします。現在、水平スケーリング(ブローカーの追加・削除)のみをサポートしています。スケジュールスケーリングでは、平日の営業時間、週末のメンテナンスウィンドウ、特定の日付などの特定のシナリオに対応できます。スケールアウトとスケールイン時の希望するブローカー数も指定できます。
次の図は、スケジュールスケーリングのワークフローを示しています。

ソリューションの概要
このソリューションは、2 つのアプローチで Express ブローカーのスケーリング自動化を提供します。
- オンデマンドスケーリング – 組み込みのクラスターパフォーマンスメトリクスまたはカスタム CloudWatch メトリクスを追跡し、しきい値を超えるとブローカー容量を調整
- スケジュールスケーリング – 特定のスケジュールに基づいてクラスターをスケーリング
以下のセクションでは、両方のスケーリング方法の実装詳細を説明します。
前提条件
前提条件として以下の手順を完了してください。
- インテリジェントリバランシングを有効にした Express クラスターを作成します。このソリューションが機能するにはインテリジェントリバランシング機能が必要です。クラスターの Amazon リソースネーム (ARN) をメモしてください。
- Amazon Elastic Compute Cloud (Amazon EC2) に Python 3.11 以降をインストールします。
- AWS Command Line Interface (AWS CLI) をインストールし、AWS 認証情報で設定します。
- AWS CDK CLI をインストールします。
オンデマンドスケーリングソリューション
このソリューションは、Amazon EventBridge スケジューラによって定期的にトリガーされる AWS Lambda 関数を使用します。Lambda 関数は、クラスターの状態と最後のブローカー追加・削除からの経過時間をチェックします。チェック結果から、クラスターがスケーリング可能な状態かどうかを判断します。クラスターがスケーリング可能な場合、関数はスケーリング判断に必要な CloudWatch メトリクスを収集します。スケーリング設定と CloudWatch のメトリクスに基づいて、関数はスケーリングロジックを評価し、スケーリング判断を実行します。スケーリング判断により、クラスターへのブローカーの追加または削除が行われます。どちらの場合も、インテリジェントリバランシングが手動介入なしでブローカー間のパーティション分散を処理します。スケーリングロジックの詳細は GitHub リポジトリで確認できます。
次の図は、オンデマンドスケーリングソリューションのアーキテクチャを示しています。
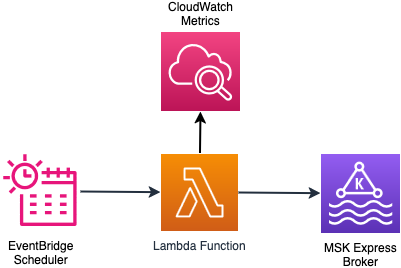
オンデマンドスケーリングソリューションのデプロイ
以下の手順に従って、オンデマンドスケーリングインフラストラクチャをデプロイします。本記事では、オンデマンドスケールアウト機能を説明します。
- 以下のコマンドを実行してプロジェクトをセットアップします。
src/config/on_demand_scaling_config.jsonを編集して、MSK ブローカーインスタンスサイズとビジネス要件に合わせてしきい値を変更します。利用可能な設定オプションの詳細については、設定ドキュメントを参照してください。
デフォルトでは、on_demand_scaling_config.jsonは express.m7g.large ブローカーインスタンスサイズを想定しています。そのため、スケールイン/スケールアウトの受信/送信しきい値は、インスタンスサイズの推奨持続スループットの 70% に設定されています。- AWS CDK で使用するために環境をブートストラップします。
- オンデマンドスケーリング AWS CDK アプリケーションをデプロイします。
monitoring_frequency_minutes パラメータは、EventBridge スケジューラがスケーリングロジック Lambda 関数を呼び出してクラスターメトリクスを評価する頻度を制御します。
デプロイにより、オンデマンドスケーリングソリューションの実行に必要な AWS リソースが作成されます。作成されたリソースの詳細はコマンドの出力に表示されます。
オンデマンドスケーリングソリューションのテストと監視
MSK クラスターのブートストラップサーバーを設定します。ブートストラップサーバーは AWS マネジメントコンソールまたは AWS CLI から取得できます。
クラスターに Kafka トピックを作成します。Amazon MSK の特定の認証方法に合わせて以下のコマンドを更新してください。詳細については、Amazon MSK Labs ワークショップを参照してください。
トピックには、より多くのブローカーセットに分散できる十分な数のパーティションが必要です。
MSK クラスターに負荷を生成して、スケーリング操作をトリガーし検証します。クラスターに負荷をかける既存のアプリケーションを使用できます。また、Kafka ディストリビューションにバンドルされている kafka-producer-perf-test.sh ユーティリティを使用して負荷を生成することもできます。
Lambda 関数のログをテールしてスケーリング操作を監視します。
ログで以下のメッセージを探して、スケーリング操作が発生した正確な時刻を特定します。メッセージの上のログステートメントには、スケーリング判断の根拠が示されています。
ソリューションは、スケーリング操作やその他多くのブローカーメトリクスを可視化する CloudWatch ダッシュボードも作成します。ダッシュボードへのリンクは cdk deploy コマンドの出力に表示されます。
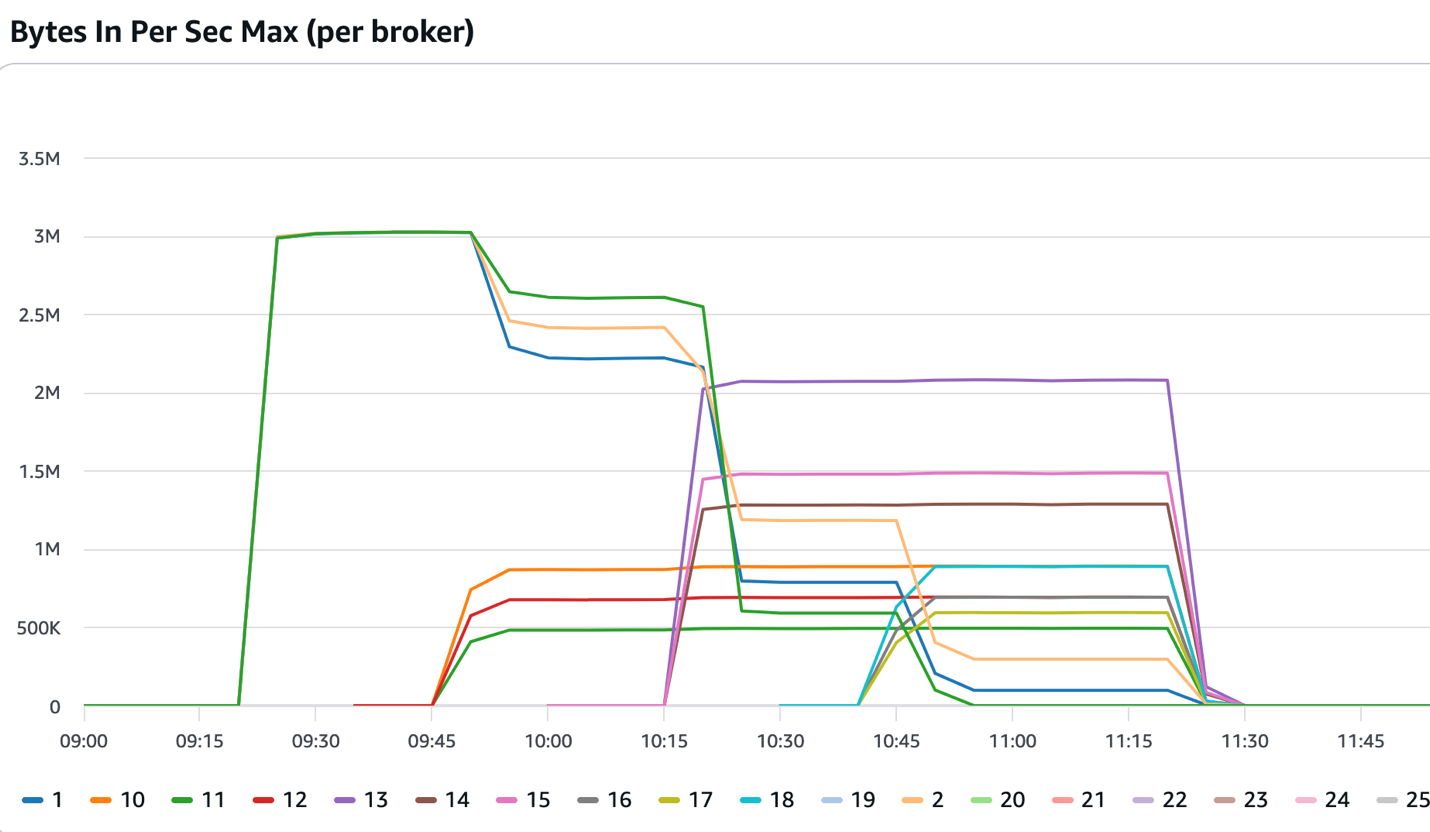
次の図は、3 つのブローカーで開始したクラスターを示しています。09:15 以降、ソリューションで設定されたしきい値を超える一貫した受信トラフィックを受信しました。ソリューションは 3 つのブローカーを追加し、09:45 頃にサービスが開始されました。インテリジェントリバランシングは新しく追加されたブローカーにパーティションの一部を再割り当てし、受信トラフィックは 6 つのブローカーに分散されました。ソリューションはクラスターが 12 ブローカーになるまでブローカーを追加し続け、インテリジェントリバランシング機能は新しく追加されたブローカー全体にパーティションを分散し続けました。
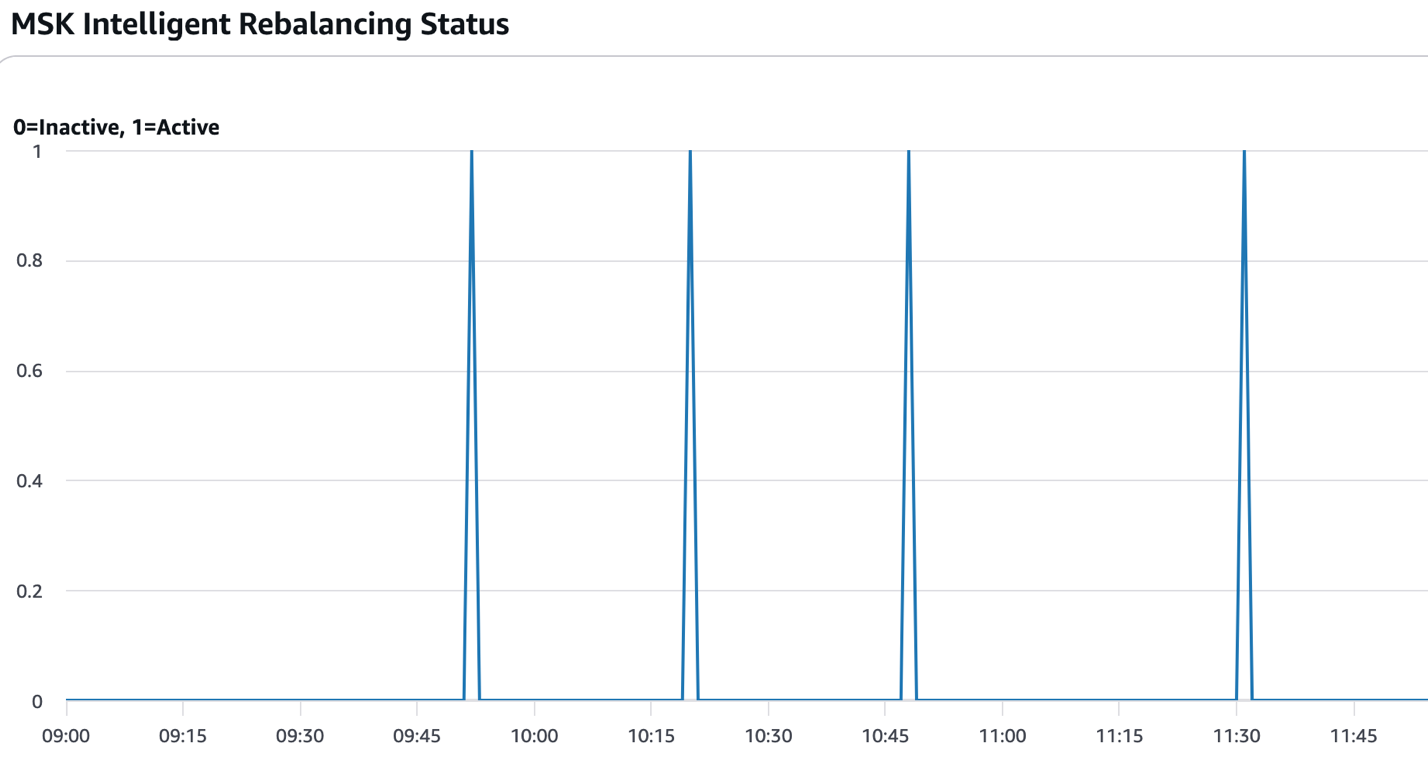
次の図は、パーティションリバランシングがアクティブだった時間(値=1)を示しています。ソリューションのコンテキストでは、通常、新しいブローカーが追加または削除され、スケーリング操作が完了した後に発生します。
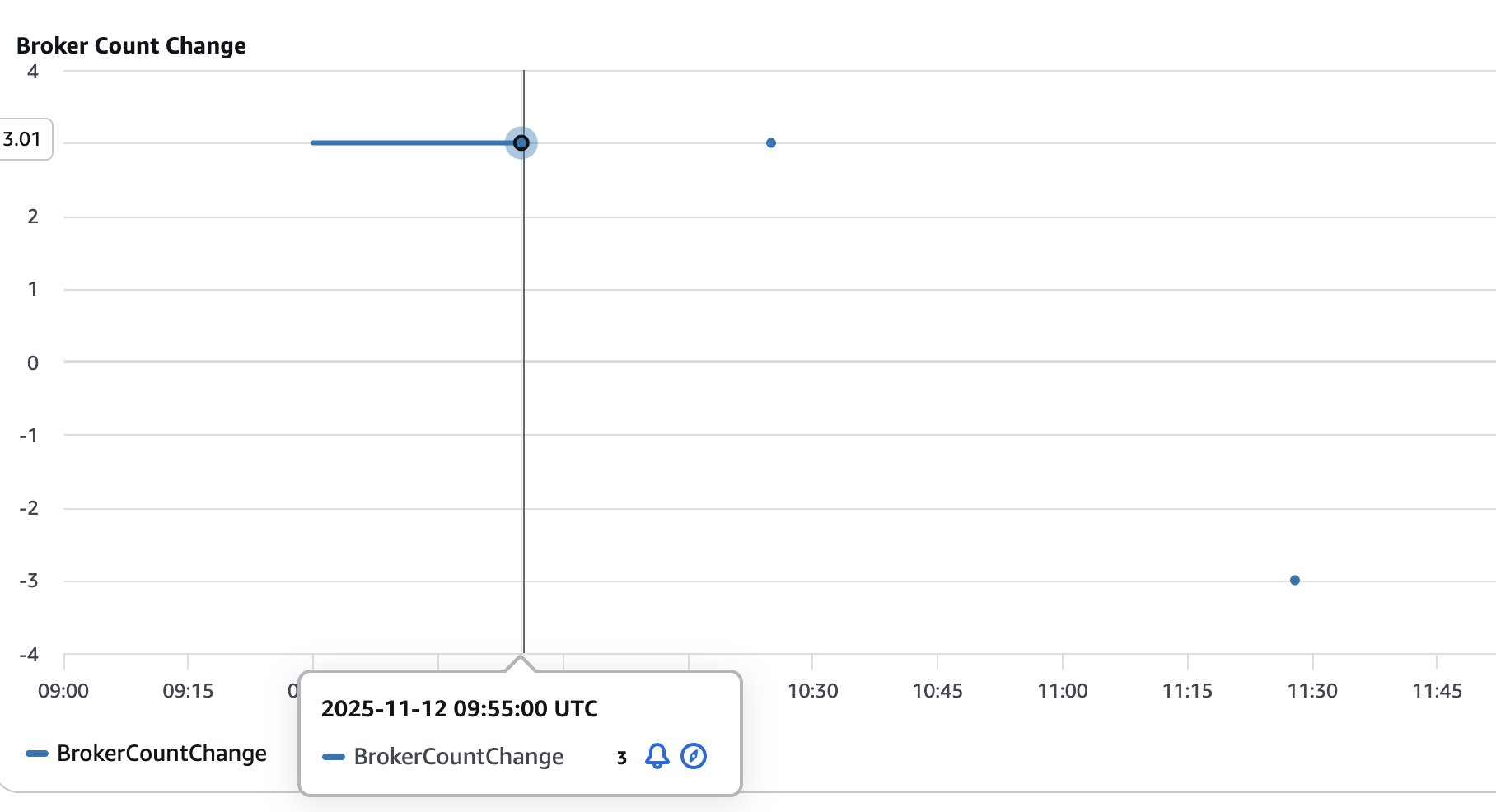
次の図は、クラスターに追加(正の値)または削除(負の値)されたブローカーの数を示しています。スケーリング操作を経るクラスターのサイズを可視化して追跡するのに役立ちます。
スケジュールスケーリングソリューション
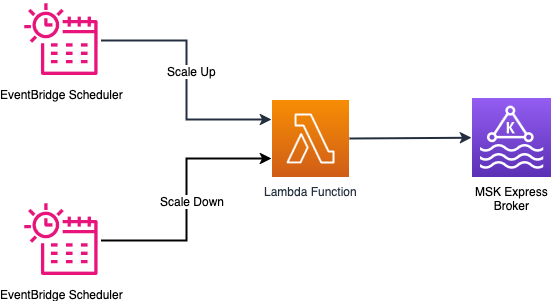
スケジュールスケーリングの実装は、EventBridge スケジュールによるタイミングパターンをサポートしています。cron 式を使用してアクションをトリガーするタイミングを設定できます。cron 式に基づいて、EventBridge スケジューラは指定された時刻に Lambda 関数をトリガーしてスケールアウトまたはスケールインを実行します。Lambda 関数は、クラスターがスケーリング操作の準備ができているかどうかをチェックし、Amazon MSK コントロールプレーン API を呼び出して要求されたスケーリング操作を実行します。サービスでは、クラスターから一度に削除できるブローカーは 3 つまでです。ソリューションは、希望するブローカー数に達するまで 3 つずつブローカーを繰り返し削除することでこのシナリオに対応します。
次の図は、スケジュールスケーリングソリューションのアーキテクチャを示しています。
設定パラメータ
EventBridge スケジュールは正確なタイミング制御のための cron 式をサポートしており、特定の時刻や曜日に合わせてスケーリング操作を細かく調整できます。例えば、cron 式 cron(0 8 ? * MON-FRI *) を使用して平日の午前 8 時にスケーリングを設定できます。同じ曜日の午後 6 時にスケールインするには、cron(0 18 ? * MON-FRI *) を使用します。その他のパターンについては、Amazon EventBridge でのスケジュールルール(レガシー)のスケジュールパターンの設定を参照してください。スケールアウトとスケールイン操作時に到達する希望のブローカー数も設定できます。
スケジュールスケーリングソリューションのデプロイ
以下の手順に従って、スケジュールスケーリングソリューションをデプロイします。
- 以下のコマンドを実行してプロジェクトをセットアップします。
scaling/cdk/src/config/scheduled_scaling_config.jsonを編集してスケーリングスケジュールを変更します。利用可能な設定オプションの詳細については、設定ドキュメントを参照してください。- スケジュールスケーリング AWS CDK アプリケーションをデプロイします。
スケジュールスケーリングソリューションのテストと監視
スケジュールスケーリングは、EventBridge スケジューラの cron で指定されたとおりにトリガーされます。ただし、スケールアウト操作をテストする場合は、以下のコマンドを実行して Lambda 関数を手動で呼び出します。
同様に、以下のコマンドを実行してスケールイン操作を手動で開始できます。
Lambda 関数のログをテールしてスケーリング操作を監視します。
オンデマンドスケーリングセクションで説明した CloudWatch ダッシュボードを使用してスケジュールスケーリングを監視できます。
スケーリング設定パラメータの確認
オンデマンドスケーリングとスケジュールスケーリングの両方の設定パラメータは、Configuration Options に記載されています。これらの設定により、スケーリングの方法とタイミングを柔軟に変更できます。設定パラメータを確認し、ビジネス要件を満たしているか確認してください。オンデマンドスケーリングでは、組み込みのパフォーマンスメトリクスまたはカスタムメトリクス(例: MessagesInPerSec)に基づいてクラスターをスケーリングできます。
考慮事項
いずれかのソリューションをデプロイする際は、以下の考慮事項に留意してください。
- スケーリング失敗時の EventBridge 通知 – オンデマンドスケーリングとスケジュールスケーリングの両方のソリューションは、スケーリング操作が失敗した場合に EventBridge 通知を発行します。EventBridge ルールを作成して、これらの失敗イベントを監視およびアラートシステムにルーティングし、スケーリングの失敗を検出して対応できるようにします。イベントソース、タイプ、ペイロードの詳細については、GitHub リポジトリの EventBridge notifications セクションを参照してください。
- クールダウン期間の管理 – クラスターが急速にスケールアウトとスケールインを繰り返すスケーリングの振動を防ぐために、クールダウン期間を適切に設定します。振動は通常、トラフィックパターンに持続的な需要を表さない短期的なスパイクがある場合に発生します。しきい値が通常の動作レベルに近すぎる場合にも振動が発生する可能性があります。ワークロードの特性とスケーリング完了時間に基づいてクールダウン期間を設定します。また、スケールイン操作(
scale_in_cooldown_minutes)にはスケールアウト(scale_out_cooldown_minutes)よりも長いクールダウン期間を設定することで、スケールアウトとスケールインで異なるクールダウン期間を検討してください。最適なパフォーマンスを達成するために、本番デプロイ前に現実的な負荷パターンでクールダウン設定をテストしてください。 - 監視頻度によるコスト管理 – ソリューションは、Lambda 関数、EventBridge スケジュール、CloudWatch メトリクス、ログなどのサービスのコストが発生します。オンデマンドスケーリングとスケジュールスケーリングの両方のソリューションは、クラスターの健全性状態とスケーリング操作が必要かどうかを定期的にチェックすることで動作します。デフォルトの 1 分間の監視頻度は応答性の高いスケーリングを提供しますが、ソリューションに関連する他のコストが増加します。スケーリングの応答性とソリューションによって発生するコストのバランスを取るために、ワークロードの特性に基づいて監視間隔を増やすことを検討してください。ソリューションをデプロイする際に monitoring_frequency_minutes を変更することで監視頻度を変更できます。
- ソリューションの分離 – オンデマンドスケーリングとスケジュールスケーリングのソリューションは、予測可能な動作と最適なパフォーマンスをサポートするために分離して設計およびテストされました。いずれかのソリューションをデプロイできますが、同じクラスターで両方のソリューションを同時に実行することは避けてください。両方のアプローチを一緒に使用すると、ソリューションが互いのスケーリング判断と競合し、リソースの競合やスケーリングの振動につながる可能性のある予測不能なスケーリング動作が発生する可能性があります。ワークロードパターンに最も適したアプローチを選択し、クラスターごとに 1 つのスケーリングソリューションのみをデプロイしてください。
クリーンアップ
以下の手順に従って、ソリューションによって作成されたリソースを削除します。クリーンアップを実行する前に、進行中のすべてのスケーリング操作が完了していることを確認してください。以下のコードでオンデマンドスケーリングソリューションを削除します。
以下のコードでスケジュールスケーリングソリューションを削除します。
まとめ
本記事では、手動パーティションリバランシングを必要とせずに、ビジネス要件に基づいて Express ベースのクラスターをスケーリングするためにインテリジェントリバランシングを使用する方法を説明しました。ビジネスが依存する特定の CloudWatch メトリクスを使用して Kafka クラスターを動的にスケーリングするようにソリューションを拡張できます。同様に、特定の時間にクラスターへのトラフィックの大幅な変化が予想される場合に、クラスターをスケールアウトおよびスケールインするようにスケジュールスケーリングソリューションを調整できます。このソリューションで使用されているサービスの詳細については、以下のリソースを参照してください。
著者について
この記事は Kiro が翻訳を担当し、Solutions Architect の 榎本 貴之 がレビューしました。