Amazon Web Services ブログ
Amazon OpenSearch Service、FAISS エンジンでのベクトル検索トラブル対処の考え方:新規ベクトルデータの投入が不安定、または失敗する場合
はじめに
Amazon OpenSearch Service を使用したベクトル検索では exact k-NN もしくは Approximate k-NN が使用されます。exact k-NNでは総当たり的に近傍を探索することにより最も正確な検索が可能ですが、ベクトルデータ数に対して線形に実行時間が増えるため、大規模なデータセットに対しては深刻にパフォーマンスが悪化する可能性があります。一方で Approximate k-NN は精度を一定落とす代わりに高速な検索を実現する手法です。Amazon OpenSearch Service において利用できるApproximate k-NNアルゴリズム用のベクトル検索エンジンは主に FAISS と Lucene があり、FAISS エンジンにはアルゴリズムとして HNSW と IVF があります(参考)。
本ブログでは、FAISS エンジンを使用したベクトル検索において、新規ベクトルデータの投入が不安定、または失敗する場合の原因調査および対処法選択の考え方について説明します。
シナリオ:新規ベクトルデータの投入が不安定、または失敗する
一度ベクトルデータベースのセットアップが完了し問題なく稼働していたとしても、検索対象となるドキュメント数が増えたり、使用するユーザー数が増加していくと様々なトラブルが発生する可能性があります。OpenSearch Service におけるトラブルはインスタンスタイプの増強によるスケールアップやノード数追加によるスケールアウトをすることで解決できることは多いですが、何らかのトラブルに対して原因調査を行い、コストや精度、レイテンシーといった要素のトレードオフを理解した上で適切な対処手法を選択していくことは OpenSearch Service を有効活用していく上で非常に重要です。
FAISS エンジンにおけるベクトル検索を使用する場合のトラブルの一つとして、新規ベクトルデータの投入が不安定だったり、失敗する場合が考えられます。次元数の多いベクトルデータを Bulk API などで投入する場合、インデクシングに要する負荷は大きくなりがちです。特に、ベクトル検索を高速化するためのグラフ構造を保持するメモリのようなリソースのキャパシティ枯渇が問題になることが多いです。
調査および対処法選択の大まかな流れは以下にようになります。
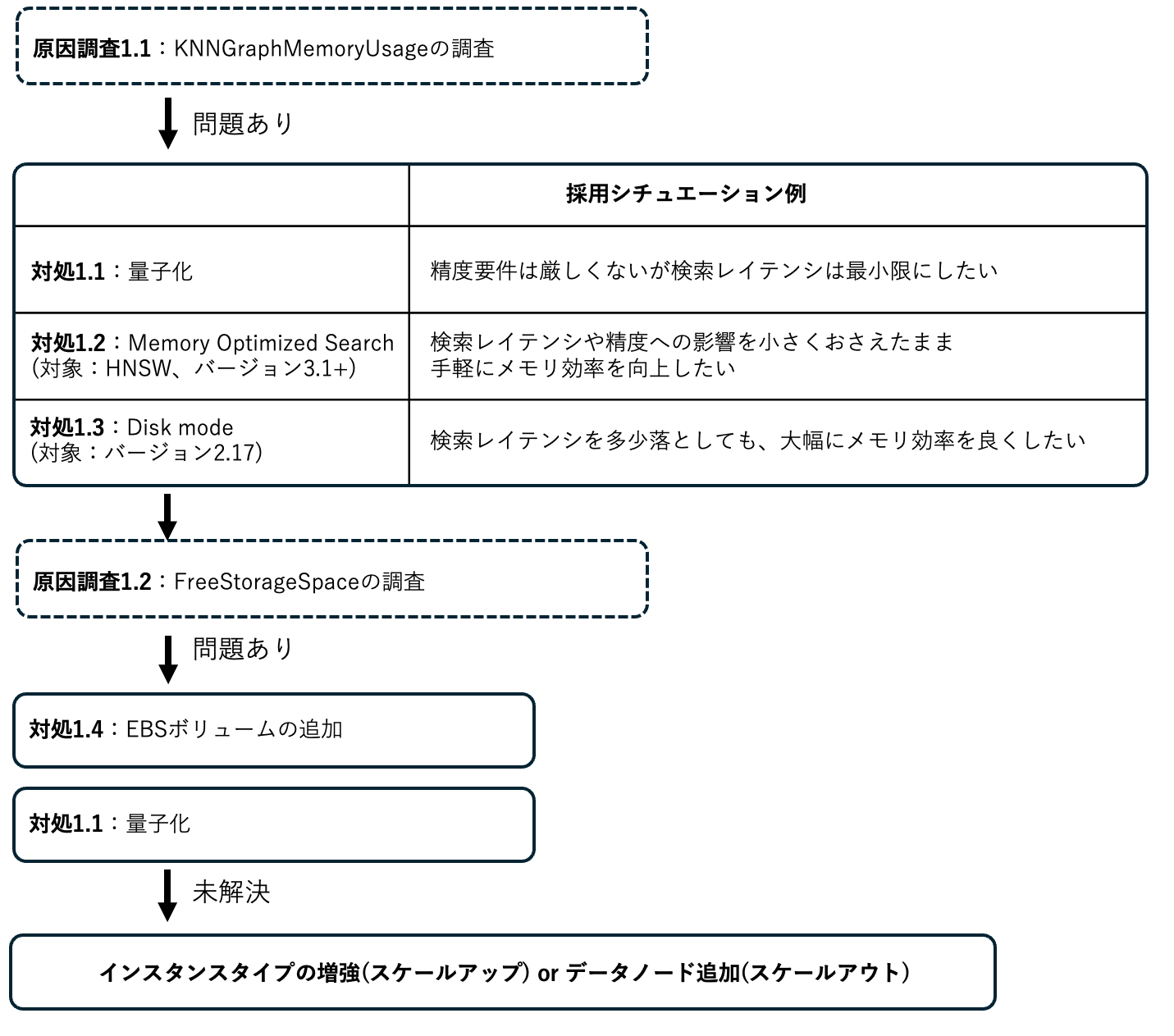
新規ベクトルデータの投入が不安定、または失敗する場合の対処法選択
ベクトル検索を行う際にしばしば問題になるのがメモリ管理です。新規ベクトルデータの投入がブロックされる場合、使用メモリサイズ増加に伴いサーキットブレーカーが発動している可能性があります。OpenSearch 自体は Java により実装されており、デフォルトでは、各ノードが持っているメモリ領域の 50% か 32GB の大きい方が JVM ヒープとして使用されます。残りの領域がネイティブメモリとして、OS やファイルシステムキャッシュ、そして k-NN ベクトルの検索用メモリとして使用されることになります。
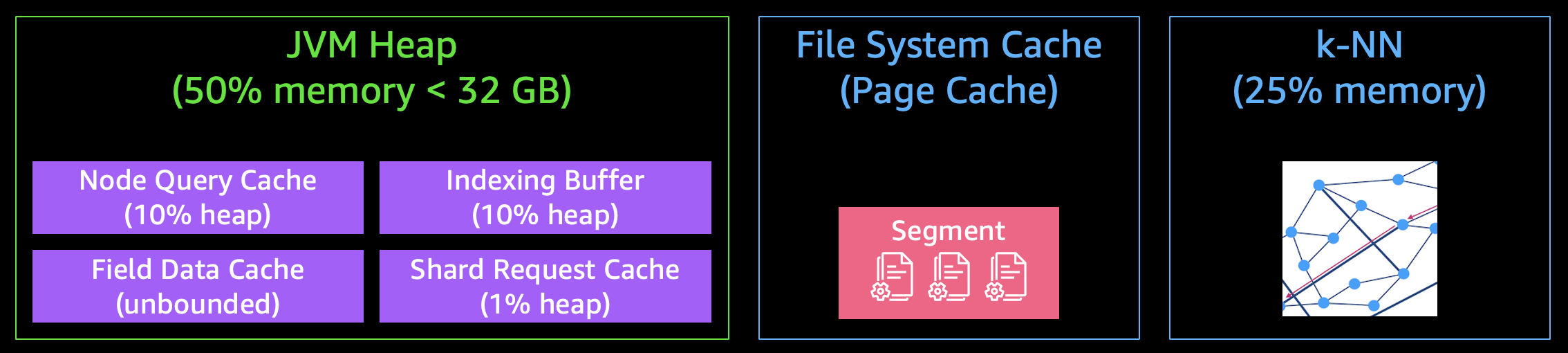
OpenSearchベクトル検索におけるメモリ管理
原因調査1.1: KNNGraphMemoryUsage によるネイティブメモリ使用状況の調査
ベクトル検索を行う際にしばしば問題になるのがメモリ管理です。新規ベクトルデータの投入がブロックされる場合、使用メモリサイズ増加に伴いサーキットブレーカーが発動している可能性があります。OpenSearch 自体は Java により実装されており、デフォルトでは、各ノードが持っているメモリ領域の50%か 32GB の大きい方が JVM ヒープとして使用されます。残りの領域がネイティブメモリとして、OS やファイルシステムキャッシュ、そして k-NN ベクトルの検索用メモリとして使用されることになります。
CloudWatch メトリクスを参照して、データノードにおける KNNGraphMemoryUsage もしくは KNNGraphMemoryUsagePercentage を参照することで、ネイティブメモリのうちどの程度をベクトルグラフが占有しているかモニタリングすることができ、大きなベクトルデータを扱っている場合非常に重要なドメインサイジングの指標になります。
特に FAISS エンジンで HNSW のインデックスを作成している場合、検索を高速化するためベクトルデータ投入時にグラフ構造が構築されます。検索クエリが実行された際、もしくは Warm-up API が呼ばれた際にこのグラフはネイティブメモリにロードされますが、グラフのデータサイズが大きくなると上記の k-NN 用ネイティブメモリサイズを超過し、サーキットブレーカーが発動する可能性があります。これに伴い、インデックスは新規ベクトルデータの投入をブロックするようになります。
サーキットブレーカーが発動するメモリサイズに関しては、knn.circuit_breaker.limit(デフォルト 50%)に設定されており、この値に対して上記メトリクスが猶予を持っている必要があります。
各ノードの k-NN に関する統計情報は以下のコマンドによっても取得することが可能です。サーキットブレーカーによりデータ投入がブロックされている場合、レスポンスに含まれる circuit_breaker_triggered の値が true になります。
このシチュエーションにおいて、ベクトルグラフによるメモリ使用を削減する、もしくはメモリを増強する対応が必要になります。
原因調査1.2:FreeStorageSpace によるディスク容量の確認
CloudWatch メトリクスの一つである、FreeStorageSpace を参照することで、OpenSearch Service における各ノードがどの程度のストレージ残量があるかを調査することができます。
OpenSearch Service は各データノードのストレージの 20%(最大 20 GiB)を、セグメントマージやログなどの内部操作用にあらかじめ予約しています。CloudWatch メトリクスの FreeStorageSpace はこの予約分を差し引いた後の残量を示すため、OpenSearch の _cluster/stats や _cat/allocation API が返す値よりも常に低い値になります。
ストレージ保護の観点では、いずれかのノードの空き容量が「利用可能ストレージの 20%」または「20 GiB」のうち小さい方を下回った時点で、書き込み操作をブロックします(ClusterBlockException)。ブロック機構は、OSS の OpenSearch が持つ disk watermark(low: 85%、high: 90%、flood_stage: 95%)よりも先に発動するのが一般的です。FreeStorageSpace メトリクスを監視し、CloudWatch アラームを設定することで、ブロック発生前にストレージ逼迫を検知できます。
対処1.1:量子化
OpenSearchにおけるベクトルはknn_vector型の32ビット浮動小数点配列として保存されますが、これらをよりデータ量の小さなベクトルに圧縮するアプローチです。以下の4つの量子化手法をサポートしています。より圧縮度の高い量子化は検索の精度を落とす可能性がありますが、メモリ使用量の削減だけでなく、検索パフォーマンスの向上やディスク使用量の削減にもつながります。精度要件に余裕があり、検索速度を維持もしくは高速化した上でメモリ効率化も行いたい場合有用な手法です。
詳細に関してはこちらのブログも参照ください。
スカラー量子化 (Scaler Quantization)
- バイナリ量子化
ベクトルの各次元を 1 ビット(-1 または +1)で表現する最も圧縮率の高い量子化手法。最大 32 倍と大幅にメモリ、ストレージ使用量を低減できますが、精度の低下が最も大きくなります。 - バイト量子化
各次元を 8 ビット整数(int8)で表現し、元の浮動小数点数を 256 段階に量子化する手法。メモリを約 1/4 に削減しつつ、比較的高い精度を維持できるバランスの良い方式です。 - FP16量子化
32 ビット浮動小数点数(FP32)を 16 ビット浮動小数点数(FP16)に変換する手法。メモリを半分に削減し、精度の劣化が少ないため、高精度が求められる用途に適しています。
直積量子化(Product Quantization)
ベクトルを複数のサブベクトルに分割し、各サブベクトルを独立にクラスタリングしてコードブックで表現する手法。最大 64 倍と高い圧縮率と高速な検索を両立でき、大規模ベクトル検索でしばしば使用されますが、利用にあたり事前のトレーニングが必要になります。
対処1.2:Memory Optimized Search (対象:HNSW、バージョン3.1+)
Lucene エンジンと FAISS エンジンのハイブリッドアプローチを行うことで、ベクトルグラフの全てをメモリに載せることなく検索を実行することが可能です。数% の Recall およびスループットの低下が生じる可能性がありますが、3〜4 倍のメモリ使用量削減の可能性があります。この手法を使用する場合、グラフの一部を載せるメモリとして OS ページキャッシュを使用するため、KNNGraphMemoryUsage は増加しません。
ベンチマーキングなどはこちらのブログから参照ください。以下のように、knn.memory_optimized_search を設定することにより有効化できます。この手法の特徴として、index 単位で有効化する場合は reindex が必要ないことが挙げられます。index の設定のみで有効化できるので手軽にメモリ使用量削減が可能です。
対処1.3: Disk mode (対象:バージョン2.17+)
ディスクベースのベクトル検索では、量子化したベクトルのみをメモリに乗せサンプリングを行い、ディスク上の完全な精度のベクトルでリランクを行う手法です。量子化の圧縮率を選択することにより、メモリに載せるベクトルデータのサイズを最大 32 倍低減することができますが、精度の低下は最小限に抑えることが可能です。
検索速度の低下を許容できるワークロードでありつつ、精度の低下をおさえて最大限のメモリ効率を実現したい場合有用な手法です。
以下のように、knn_vector のフィールドの mode を on_disk に設定することで有効化できます。量子化の圧縮率は compression_level として指定することができ、FAISS エンジンでは 1x、2x、8x、16x、32x が選択可能です。
対処1.4:EBSボリュームの追加
OpenSearch Service におけるデータノードはストレージとして EBS ボリュームを使用しています。データノードのストレージが枯渇した際、クラスターの設定からノードあたりの EBS ストレージサイズを追加することで非常に簡単に対処することができます。データノードあたりの EBS ストレージの最大サイズは 1536 GiB です。
クラスター自体のデータノード数を増やしたり、データノードのインスタンスタイプをより大きいものに変更するのに比べてコスト効率よく手軽にストレージ枯渇に対処できる手法になっています。
CLI では以下のオペレーションによって設定変更可能です。
aws opensearch update-domain-config \
--domain-name your-domain-name \
--ebs-options '{
"EBSEnabled": true,
"VolumeType": "gp3",
"VolumeSize": 1024
}'まとめ
本ブログでは、OpenSearch Service において FAISS エンジンを使用したベクトル検索ワークロードを運用している際に発生しうるトラブルとして新規ベクトルデータの投入が不安定、または失敗する場合に着目し、その原因究明と対処方法選択の考え方について紹介しました。このトラブル自体はベクトルグラフのメモリに起因することがおおく、OpenSearch が提供するメモリ最適化手法の中から適切な選択を行っていくことが重要です。
OpenSearch Service の機能は継続的に拡充されているため、新機能を活用するためにもクラスターのバージョンアップグレードを定期的に検討することを推奨します。
著者
 黒木 琢央 (Takuo Kuroki)
黒木 琢央 (Takuo Kuroki)
アマゾンウェブサービスジャパン合同会社ソリューションアーキテクト
2024年4月入社。現在toCのITサービス提供企業におけるクラウド全般の技術支援を行いつつ、OpenSearchのコミュニティ活動や機能改善に取り組んでいます。