Amazon Web Services ブログ
Amazon OpenSearch Service、FAISS エンジンでのベクトル検索トラブル対処の考え方:検索レイテンシの増加が問題になっている場合
はじめに
Amazon OpenSearch Service を使用したベクトル検索では exact k-NN もしくは Approximate k-NN が使用されます。exact k-NN では総当たり的に近傍を探索することにより最も正確な検索が可能ですが、ベクトルデータ数に対して線形に実行時間が増えるため、大規模なデータセットに対しては深刻にパフォーマンスが悪化する可能性があります。一方で Approximate k-NN は精度を一定落とす代わりに高速な検索を実現する手法です。Amazon OpenSearch Service において利用できる Approximate k-NN アルゴリズム用のベクトル検索エンジンは主に FAISS と Lucene があり、FAISS エンジンにはアルゴリズムとして HNSW と IVF があります(参考)。
本ブログでは、FAISSエンジンを使用したベクトル検索において、検索レイテンシが構築初期より増加していることが問題になっている場合の原因調査および対処法選択の考え方について説明します。
シナリオ:検索レイテンシーが構築初期より著しく増加している
OpenSearch Service において検索リクエストに対するパフォーマンスはユーザーの視点でもクラスター全体の健全な運用をする上でも重要な要素です。ベクトル検索ワークロード構築初期においてはデータ量が少ないため大抵の場合検索レイテンシーが問題になることはありませんが、検索対象となっているベクトルデータや新規に投入されてインデクシングされるベクトルが多くなるにつれて、さまざまな要因により検索レイテンシーが悪化する可能性があります。このような問題は単純な、検索パフォーマンスが悪化しているタイミングや CPU リソースやメモリの使用状況からどのようことが要因となっているか調査し、対処法を選択することが重要です。インスタンスタイプを増強したり、データノード数を増やすなどの対応によりクラスター全体のキャパシティを大きくすることでこのような問題に対処できることは多いですが、ここではその前段階として検討すべき最適化の手法について紹介します。
調査および対処法選択の大まかな流れは以下にようになります。
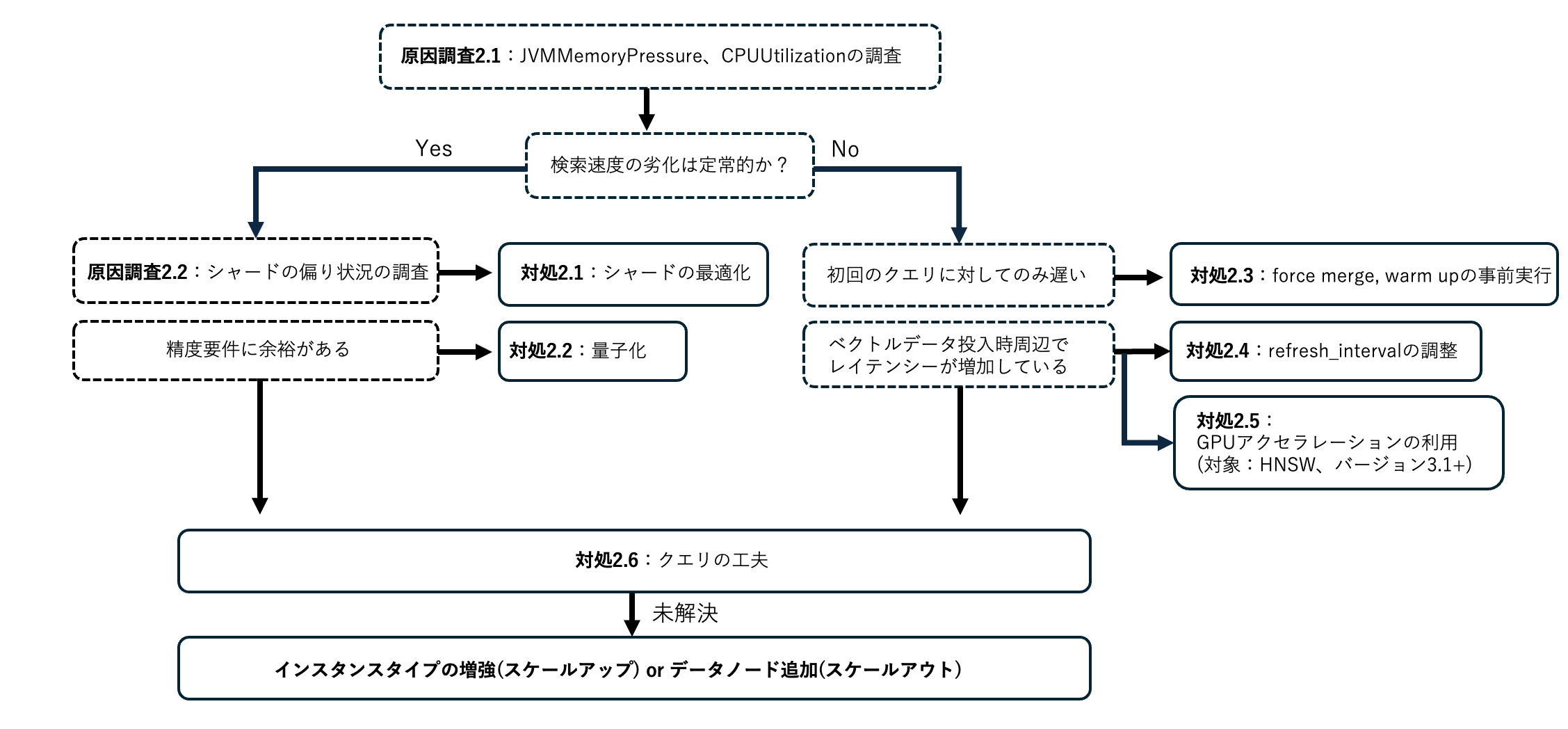
原因調査2.1:JVMMemoryPressure、CPUUtilizationの確認
検索パフォーマンスが悪化している場合などにおいて調査すべきメトリクスの一つが JVMMemoryPressure および CPUUtilization です。これらのメトリクスは AWS コンソールの OpenSearch Service ページにおける、ドメインの Cluster Health および CloudWatch Metrics から調査することができます。
JVMMemoryPressure や CPUUtilization を確認することにより、検索およびインデクシングといった処理にどの程度の負荷がかかっているかが確認できます。JVMMemoryPressure は JVM ヒープメモリの使用率であり、CPUUtilization はデータノードにおける CPU 使用率です。k-NN グラフ構築などのデータ投入処理やセグメントのマージなどで上昇します。これらのメトリクスが高い値を示している場合は、クエリやデータ投入のパフォーマンスが悪化している可能性があります。一般的に JVMMemoryPressure は 75% 以上になると GC が発生しますが、インデクシングや検索リクエストの処理が追いつかない場合 GC が多発し、JVMMemoryPressure も下降しない状態になります。さらに 95% に到達するとサーキットブレーカーにより新規リクエストを拒否します。
原因調査2.2:シャードの偏り状況の調査
OpenSearch Service のドメインでは、シャード分布がノード間で偏りが生じることにより特定のノードに処理が集中する場合があります。このような場合、ドメイン全体のリソース状況に余裕があったとしてもノード単体のリソース不足によりパフォーマンスに支障をきたす可能性があります。
以下のコマンドにより、ノードごとにシャード数やデータ量の偏りがないか調査することができます。
対処2.5:GPUアクセラレーションの活用(対象:HNSW、バージョン3.1+)
ベクトルデータ数が非常に大きくなると、データ投入のタイミングで発生するグラフ構築に長い時間がかかり、CPU リソースの消費も大きくなります。ベクトルデータのインデクシングにおける GPU 加速を使用すると、大規模ベクトルデータに対するグラフ構築をマネージドな GPU を使用して高速化しつつ、CPU への負荷をオフロードすることが可能です。もし、検索クエリなどのパフォーマンス低下がベクトルデータのインデクシングによる CPU リソースの枯渇が原因であった場合、この機能の活用により改善する可能性があります。
$ aws opensearch update-domain-config \
--domain-name <domain-name> \
--aiml-options '{"ServerlessVectorAcceleration": {"Enabled": true}}'GPU アクセラレーションを使用するかどうかは index.knn.remote_index_build.enabled からインデックスごとに設定可能です。
ベクトルグラフ構築の高速化は最大 10 倍にのぼり、ユーザーは GPU リソースの使用を全く意識する必要はありません。有効化にはまず、OpenSearch ドメインの設定をアップデートします。この設定変更によるダウンタイムの発生はありません。
詳細についてはこちらのブログを参照ください。
対処2.6:クエリの工夫
検索パフォーマンスに問題がある場合、しばしばクエリ設計を工夫するアプローチが有効です。一般に OpenSearch におけるクエリ設計の最適化は様々な要素があり、クエリの種類によって取ることのできるアプローチも異なります。
ここでは、knn_vector フィールドへのクエリに対して取ることのできるアプローチを紹介します。
ef_search(対象:HNSW、バージョン2.16+)
HNSW を使用している場合、クエリに対して ef_search として小さい値を指定することで、精度を落として検索速度を向上することができます。ef_search はインデックスマッピング作成時に指定することができるパラメータですが、デフォルトは 100 となっており、クエリごとに調整することで、精度と検索速度のトレードオフを調整することが可能です。
HNSW ではこれ以外にもパラメーターが存在し、精度、レイテンシー、メモリ使用量のトレードオフを調整することができます。クエリのタイミングで指定できるパラメーターは ef_search のみであり、他のパラメーターはインデックス作成時に指定することができます。詳細に関してはこちらの資料を参考にしてください。
_sourceフィルタリングでベクトルデータ転送量を削減
ベクトル検索の多くの場合、ヒットしたドキュメントが持つベクトルデータはアプリケーションから直接利用されません。検索クエリで事前にベクトルデータを返さないように設定することでネットワーク転送や json シリアライゼーションのオーバーヘッドが削減され、結果的に検索レイテンシを低減する効果があります。
まとめ
本ブログでは、OpenSearch Service において FAISS エンジンを使用したベクトル検索ワークロードを運用している際に発生しうるトラブルとして検索クエリに対するレイテンシーの増加に着目し、その原因究明と対処方法選択の考え方について紹介しました。一般的に OpenSearch を利用した検索のクエリパフォーマンスを改善する場合は、様々な要素が複雑に絡み合う場合があり、特に複数の検索条件、フィルター、集計などを併用している場合にクエリパフォーマンスに影響が出る場合が多いです。一方で今回取り上げたようにベクトル検索単体においてもそのパフォーマンスの改善の余地があり、適切にモニタリングをした上で改善施策を取ることが重要です。
OpenSearch Service の機能は継続的に拡充されているため、新機能を活用するためにもクラスターのバージョンアップグレードを定期的に検討することを推奨します。
著者
 黒木 琢央 (Takuo Kuroki)
黒木 琢央 (Takuo Kuroki)
アマゾンウェブサービスジャパン合同会社ソリューションアーキテクト
2024年4月入社。現在toCのITサービス提供企業におけるクラウド全般の技術支援を行いつつ、OpenSearchのコミュニティ活動や機能改善に取り組んでいます。