Amazon Web Services ブログ
グラフデータベースってどんなもの?Amazon Neptune を使って グラフデータベースのクエリを体験しよう(Gremlin 編)
みなさんこんにちは。ソリューションアーキテクト(SA)の上原です。
私は普段SAとして製造業のお客様をサポートさせて頂く傍ら、フルマネージドなグラフデータベースである Amazon Neptune を技術領域として活動しています。
いきなりグラフデータベースと言われてピンと来ない方もいるかもしれませんが、グラフデータベースの活用は様々な領域で進んでいます。例えば、公共領域では 法人情報検索ツール、ヘルスケア領域では薬物間相互作用のチェック、マーケティング領域ではカスタマーインサイト分析、製造業ではトレーサビリティなどで利用されています。
アプリケーションから大量のリレーションシップを持つ大規模なデータセットを利用する場合、リレーショナルデータベースでは、複数の結合が必要になりクエリが複雑化する、期待するレスポンスが得られないといった課題があります。しかし、フルマネージドなグラフデータベースである Neptune は、リレーションシップの格納とナビゲートを目的として構築されたデータベースで、 ナレッジグラフ、 ID グラフや 不正検出といった代表的なグラフアプリケーションを構築することができます。
グラフデータベースでどんなことができるのか具体的なクエリを見てみたいという方向けに、以前のブログ「グラフデータベースってどんなもの?Amazon Neptune を使って グラフデータベースのクエリを体験しよう(準備編)」で、Neptune のハンズオンをご紹介しました。
現在 Neptune では 、Gremlin、openCypher、SPARQL の3つの言語でクエリが可能です。前述のハンズオンでは3つのクエリ言語についてそれぞれ紹介していますが、本ブログでは準備編の続きとして、公開しているサンプルの中から Gremlin を例に基本となるクエリをご紹介します。
前提条件
本ハンズオンの実施には、以下が必要です。
-
- AWSアカウント – 作成されていない方は、こちらからアカウントを作成してください。
- AWS Region – 本ブログでは
us-east-1を利用します。
※ ハンズオンで提供される AWS CloudFormation テンプレートは、東京リージョンを含む15のリージョンで利用可能です。 - IAM ユーザ – 本ブログでは
AdministratorAccess権限をもつ IAM ユーザ を利用します。
※ ハンズオンで提供される CloudFormation テンプレートでは、Neptune クラスターや、前提となるネットワークの構成、クエリ実行環境となる Neptune グラフノートブック 等の作成 及び クラスターへのデータロード、クラスターへのアクセスやデータロードに必要な AWS Identity and Access Management (IAM) ロールの作成等が実行されます。必要な権限を持つ IAM ユーザまたは IAM ロールを作成し、ハンズオンを実施してください。 - ハンズオン環境 – 以前のブログ を参照し、ハンズオン環境の作成およびデータのロードを実施してください。
ハンズオン環境
ハンズオン手順の中で実行する CloudFormation テンプレートによって作成される全体アーキテクチャは以下です。
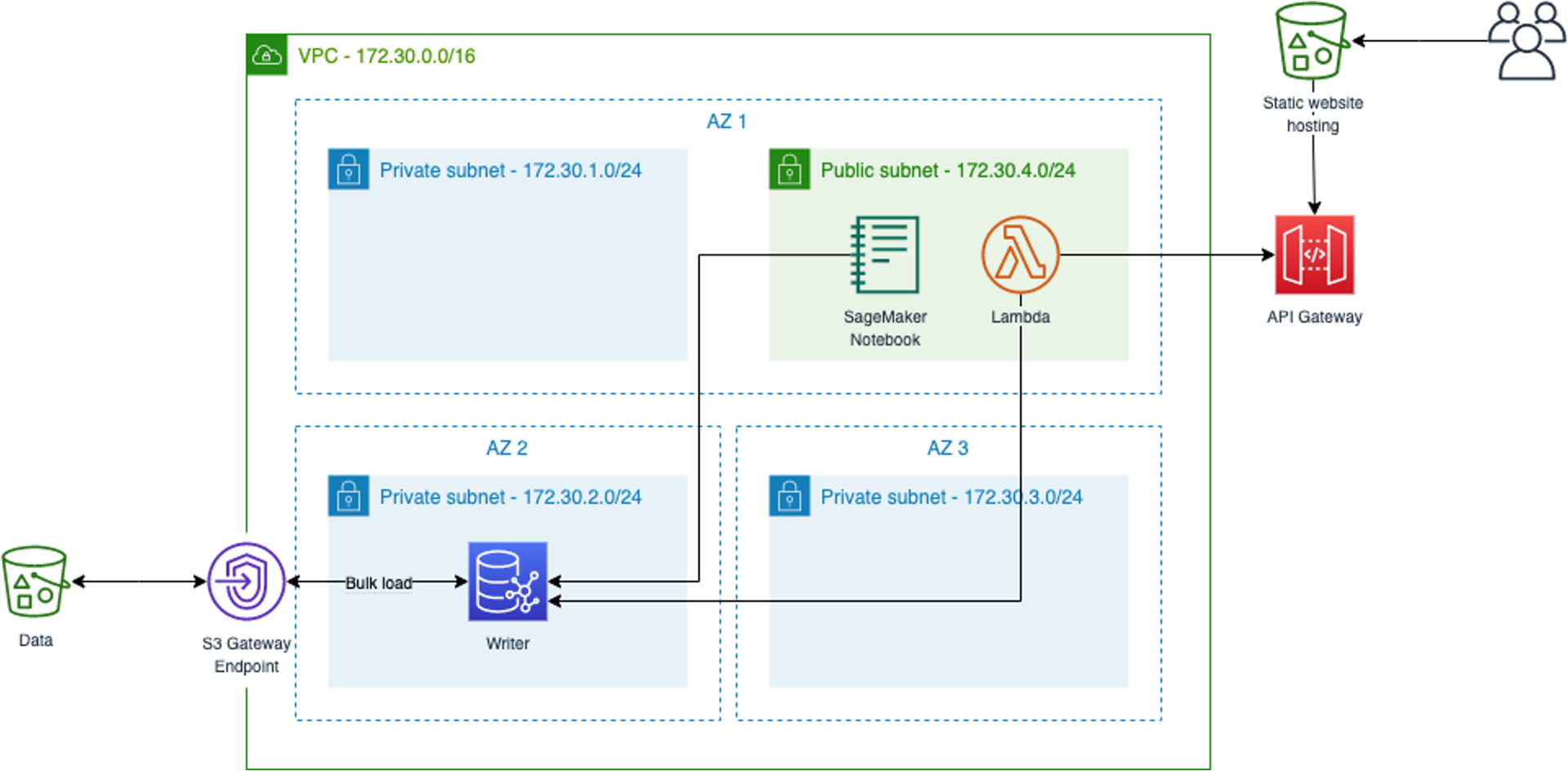
公開しているハンズオンでは、Neptune を利用するWebアプリケーションの作成までを範囲としていますが、このブログではグラフノートブックから Neptune へのクエリ部分にフォーカスして手順をご紹介します。
グラフノートブックは Amazon SageMakerノートブック サービスによってホストされるため、構成図では SageMaker Notebook と記載します。
ハンズオン(ノートブックの実行)
データモデル
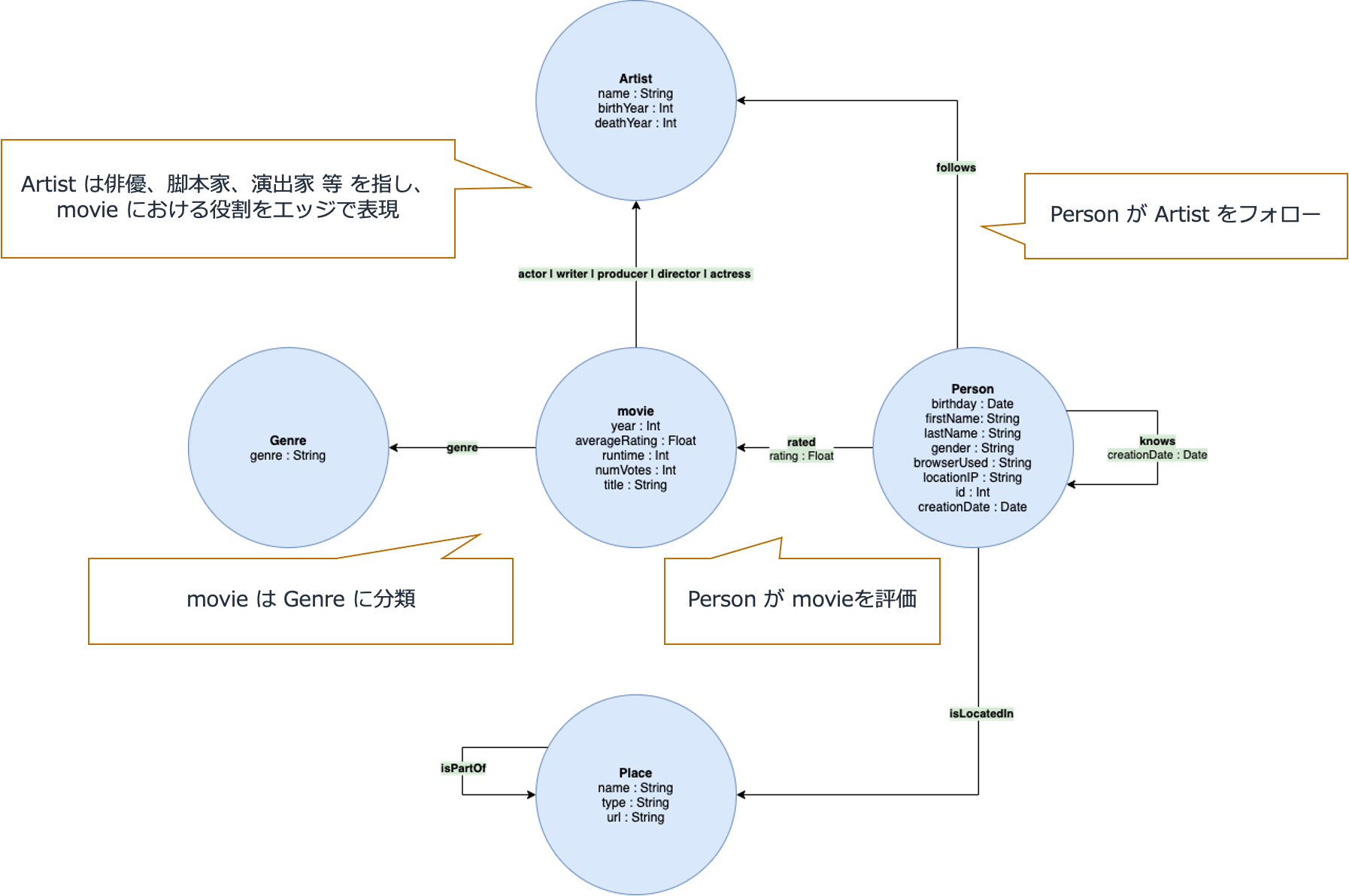
本ハンズオンでは IMDb(インターネットムービーデータベース)データセットの修正バージョンを使用します。 このデータの一部を、頂点、エッジ、およびプロパティとして表す次のグラフデータモデルに変換しました。
頂点(Vertex)は、下図では丸で表現されており、IDのある実態を指します。属性やメタデータを表すプロパティ(例:name)とロール名やタグを表すラベル(例:Artist)を付与することが可能です。頂点はノードと表記することもあります。
エッジ(edge)は、下図では矢印で表現されており、頂点間の関連や構造を形作ります。関連の強さやメタデータを表すプロパティ(例:rating)とエッジの意味を表すラベル(例:rated)を付与することが可能です。
グラフノートブックへのアクセス
グラフノートブックにより、Neptune データベースへのクエリ環境をすばやく簡単に準備できます。ライブコードとナレーションテキストを含む、完全マネージド型のインタラクティブな開発環境です。
以降の手順では、事前に用意されたサンプルのノートブックにアクセスしクエリを実行します。
Neptune コンソール を開き、左手のサイドバーから ノートブック を選択します。
表示されたノートブックのチェックボックスを選択し、右上の アクション > Open Jupyter を選択します。

表示された Jupyter 画面にて Neptune > 00-Workshop-Notebooks-START-HERE > Gremlin を選択します。

ノートブックについて
以降の手順では、上記一覧に表示されたノートブックを開き、表示されたセルを順に実行します。
実行したいセルを選択し、上部の Run ボタンをクリックすることで実行できます。
次のセルに移動する前に、必ずセルが完了するのを待ってください。セル実行の完了は、各セルの左側の In [] 内に表示される整数で示されます。[*] という表示の場合、セルはまだ実行中です。これまでに Jupyter Notebook を使用したことがない場合は、上部の ヘルプメニュー の ユーザーインターフェイスツアー を参照して、簡単にウォークスルーしてください。
<例>

サンプルノートブックでは、NeptuneWorkbench を利用します。NeptuneWorkbench は、Neptuneとその機能を簡単に操作できるようにするカスタム Jupyter マジックコマンドのセットです。
起点ノードの検索
このセクションでは、特定の属性を持つ頂点またはエッジを検索するいくつかの基本的な Gremlin クエリを実行します。 ここでいう属性とは、ラベル、一意のID、またはプロパティを指します。 このノートブックのクエリは自由に変更して構いません。ぜひクエリを変更してどのように結果が変わるかを確認してください。
1.ノートブックの一覧に戻り 01-Gremlin-Queries-Select-Filter.ipynb をクリックします。
頂点とエッジをIDで検索
最も単純な Gremlin クエリから始めます。まず、一意のIDで頂点とエッジを検索します。 Neptune では各頂点とエッジは一意のIDを持ちます。 IDはランダム(UUIDなど)にすることもできますが、一意であれば意味のある文字列にすることもできます。
2.ハンズオンで提供されているデータでは Kevin Bacon のIDは nm0000102 です。次のセルを実行し、 Kevin の ID を使用して彼の頂点を見つけます。

3.エッジでも同様に一意のIDによる検索が可能です。たとえば、Kevin Bacon から Footloose までの関係を表すエッジは、tt0087277-actor-nm0000102 です。 次のセルを実行し、このエッジをクエリします。

プロパティ値の表示
これまでの手順では頂点またはエッジのIDを出力していましたが、それぞれに関連付けられたプロパティ値を出力することで、より有用なデータを取得できます。
4.次のセルを実行し、Kevin Bacon の頂点に関連付けられているすべてのプロパティを見てみましょう。

5.次のセルを実行し、映画 Footloose のプロパティを確認できます

ここまで使用した valueMap() で表示されるのはプロパティ値のみで、ID と ラベルは表示されません。
6.次のセルを実行し、ID とラベルの情報も含めた結果を出力できます。

上記の出力では全ての値が1行で出力されます。
7.次のセルを実行し、各プロパティを別々の行で表示します。

8.エッジは ID、ラベル、プロパティに加えて、入力頂点と出力頂点を持ちます。次のセルを実行し、エッジに隣接する頂点を確認します。

特定のプロパティによるフィルタリング
ここまで頂点およびエッジを ID によって検索してきましたが、検索したい頂点またはエッジの ID が分からない場合があります。このセクションでは、指定されたプロパティ値をもつ頂点およびエッジを検索します。
9.次のセルを実行し、Footloose を表す全ての頂点を検索します。ここではプロパティ値として title が Footloose の頂点をクエリします。

Neptune の各頂点およびエッジはラベルを持ちます。ラベルのカーディナリティは非常に低い傾向にあります。もし対象データにテレビドラマなど他のメディアが含まれており、その中から映画だけを対象に検索したい場合は、hasLabel() を使用します。
10.次のセルを実行し、映画 Footloose を表す全ての頂点を検索します。

実行結果として、1984年に公開された作品と、2011年に公開された作品の2つが出力されます。
条件の使用
ここまで使用した has() 以外にも、特定の検索条件に基づいて頂点とエッジを見つける方法があります。このセクションでは条件付き操作を実行します。
11.次のセルを実行し、2000年より前の Footloose のすべてのバージョンを検索します。

12.次のセルを実行し、2000年から2012年に撮影されたFootlooseのすべてのバージョンを検索します。

探索
前セクションでグラフ構造の基本を理解したので、ここでは探索に関するクエリを実行します。エンティティである頂点と同じ方法で”関係”を保存することは、グラフデータの重要な差別化要因です。この”関係”を表現するエッジを探索することで、高度に接続されたデータセットをクエリすることが可能です。
1.ノートブックの一覧に戻り 02-Gremlin-Queries-Find-Traversal- Steps.ipynb をクリックします。
まず、エッジを横切る単純な探索から始めます。ハンズオンで利用するデータセットでは、アーティストと映画が役割でラベル付けされたエッジを介して接続しています。特定のアーティストが取り組んだ作品を見つけるため、該当アーティストの頂点から検索したい役割を持つエッジを介して関連する映画を探索することができます。
2.次のセルを実行し、Christopher Nolan 監督の映画を見つけます。
この例ではまず 起点ノードとなる Christopher Nolan を見つけ、次に in('director') によって 起点ノードに向かう director のラベルをもつエッジを探索します。この時点で Christopher Nolan が監督した作品のリストができました。次に values() を使用して、各作品のタイトルを一覧表示します。

Neptune のエッジには方向性があります。in()、 out()、both() を使用して、特定の方向でエッジを探索できます。in() は起点ノードに向かうエッジ、 out() は起点ノードから出るエッジを探索し、 both() はエッジの方向は問いません。可能な限り、これらの手順ではエッジラベルを指定することをお勧めします。
3.次のセルを実行し、IDが person378 の人がフォローしているアーティストの人数を数えます。count() は言葉の意味通り、マップされている入力を受け取りそれらの数を出力します。

in() と out() を連鎖させて、より複雑な探索が可能です。
4.次のセルを実行し、IDが person378 の人物を見つけて、同じアーティストをフォローしているユニークな人物(自分自身を含む)の数を数えます。dedup() はマップされている重複を削除し、重複がなくなった状態のリストを返します。
この例ではまず起点ノードとなる ID が person378 の人を見つけ、この人がフォローしているアーティスト一覧を取得します。そしてこのアーティストをフォローしている人の一覧を取得します。ここで、同一人物がアーティスト一覧上の複数のアーティストをフォローしている可能性があります。このため、dedup()が必要です。

次の演習では、as() を使用して後続のステップで参照できるようにステップにラベルをつけます。併せて、後続のステップで参照する際に利用する select() も紹介します。
5.次のセルを実行し、Halle Berry と共演したすべてのアーティストと、彼らが一緒に出演した映画を出力します。
この例ではまず起点ノードとなる Halle Berry の頂点を見つけ、出演映画を探索します。ここまでのステップに movie というラベルをつけます。さらにこの映画に出演するアーティストを探索し、ここまでのステップに costars というラベルをつけています。そして、後続のステップでこれらを参照しています。
select() の後の by() により、title に関連付けられている映画と name に関連付けられている共演者の頂点だけを返しています。出力結果は頂点 ID だけではなく、by() によって指定されている映画のタイトルと出演者名が含まれます。

このクエリでは出力結果に Halle Berry 自身が含まれています。
6.次のセルを実行し、Halle Berry を含まない彼女の共演者のみを取得します。
起点ノードとなる Halle Berry の頂点を検索し、このステップ に halle とラベルをつけて、costars が halle と等しくない場合という条件を追加しています。

続いてもう少し複雑なことを試してみましょう。
Facebook、Twitter、LinkedIn などが、「つながりたいと思うかもしれない」人々のリストをどのように提供するのか疑問に思ったことはありませんか?このタイプの探索は、Friends of Friends(FoF)探索とも呼ばれます。
ここでは、特定のアーティストの共演者の共演者を調べることで、FoF を再現できます。
このタイプのクエリでは、aggregate() を活用する必要があります。 aggregate() は、探索の途中で一時的なコレクションを作成し参照できるようにします。
7.次のセルを実行し、まだ Rebel Wilson と共演していないが、共通の共演者の数が最も多いアーティストを見つけます。
Rebel Wilson の共演者リストを costars として一時的なコレクションを作成します。この共演者の共演者を探索し、既に共演している costars を除外することで、「まだ Rebel Wilson と共演していない」という条件を満たします。

他のデータベースクエリ言語と同様に、Gremlin はグループ化と順序付けを行う手段を提供します。ここでは groupCount().by('name') によってアーティスト名毎に共通の共演者数を数えています。 また、order().by() を使用して結果の順序付けを実行しています。
Insert & Update
このセクションでは、データの挿入、データの更新、一括操作のクエリについて説明します。高い同時実行性とスループットを提供するために、データを Neptune にロードする際のいくつかのベストプラクティスもあります。
先述したように、Neptune では頂点とエッジを作成する時に独自の文字列を ID として指定できます。非常に同時性の高い書き込みシナリオにおいて、常に独自の文字列 ID を使用することが重要です。
また、可能な限り予測可能な ID (つまり、特定の頂点またはエッジをクエリする時にユーザが予測できる ID )を使用するようにしてください。明示的に ID を指定しない場合 Neptune は文字列ベースの UUID を作成しますが、この値をユーザが予測するのは困難です。
1.ノートブックの一覧に戻り 03-Gremlin-Queries-Inserting-Updating-Data.ipynb をクリックします。
頂点の作成
自身の ID を person0 とし、自分自身を表す新しい頂点を作成します。
2.次のセルを実行し、事前に ID が person0 の頂点が存在しないことを確認します。Neptune の頂点およびエッジには一意の ID が必要なため、同じ ID で頂点を作成しようとするとエラーが発生します。

3.次のセルを実行し、自分自身を表す新しい頂点を作成します。自分自身を表す新しい頂点を作成します。Lorem および Ipsom と指定されている部分は、ご自身あるいは任意の名前に置き換えてください。

Neptune に ID を割り当てさせる
このセクションでは、Neptune が ID を割り当てる例を試してみます。
4.次のセルを実行し、Sherlock Holmes を表す新しい頂点を作成します。誕生年は 1899 年です。

実行結果として UUID 形式の ID が返されます。これはいくつかの点で不便です。データセットに一意の識別子が含まれている場合は、UUID ではなくその一意の識別子を使用することを選択します。 これにより、データセットとアプリケーションコードの両方がはるかに読みやすくなります。
プロパティ値とカーディナリティの上書き
実は前のセクションには間違いがありました。シャーロックホームズは、1899年ではなく1854年に生まれたと言われています。したがって、彼の誕生日を修正する必要があります。 また彼は1893年に亡くなったので、それも追加してみましょう。
その前に、Neptune がプロパティ値を格納する方法を理解する必要があります。 デフォルトでは、Neptune はすべてのプロパティ値をセットとして保存します。 Apache TinkerPop フレームワークは、これをセットカーディナリティと呼びます。ここで既にセットさせているプロパティである birthyear を指定して、property('birthyear',1707) コマンドを実行しても、以前の値は上書きされません。 セットの一部として新しい 1707 値が追加されます。 代わりに、プロパティ値を単一のカーディナリティとして保存することを選択できます。
5.次のセルを実行し、カーディナリティを変更せずにプロパティを更新する例を確認します。

6.次のセルを実行し、更新結果を確認します。

実行結果として、複数の誕生年が返されます。
7.次のセルを実行し、各プロパティに単一の値のみを格納するように強制します。

8.次のセルを実行し、更新結果を確認します。

実行結果を確認すると、誕生年と死亡年の両方が単一の値になっています。
エッジの作成
ここまでの手順で複数の頂点を作成したので、その頂点間にエッジを作成してみましょう。
9.次のセルを実行し、Sherlock Holmes とあなたを表す頂点の間に follows というエッジを追加します。

実行結果として、新たに作成されたエッジの ID が返されます。
10.次のセルを実行し、あなたを表す頂点から出ていくエッジの先を探索します。

実行結果として、Sherlock Holmes に関連するすべてのプロパティが表示されます。
条件付き書き込み
場合によっては、upsert のような機能が必要になることがあります。新しい頂点(またはエッジ)が存在しない場合にのみ新規に作成し、 すでに存在する場合は追加しません。Gremlinでは、fold()-coalesce()-unfold() イディオムを使用してこれを実現します。 このアプローチの詳細な説明については、頂点が存在しない場合にのみ頂点を追加するためのcoalesceの使用を参照してください。
coalesce() パターンを使用すると、ID、ラベル、プロパティを指定して、要素がすでに存在するかどうかを判別できます。ただし、Neptune ではラベルやプロパティに対して一意制約がありません。
同時に2つのライタープロセス(クライアント、スレッドなど)が、同じ要素を対象に処理を試みる可能性があります。この場合、両方のライターが要素が存在しないと判断し、ラベルとプロパティは同じで、ID が異なる2つの要素が作成される可能性があります。
この状況を回避するために重要なのは、Neptune では 重複した ID を持てないという点です。つまり、2つの頂点が同じ ID を持つ、あるいは2つのエッジが同じ ID を持つことはできません(ただし、頂点とエッジは同じ ID を持つことができます)。
coalesce() を使用する場合は、プロパティやラベルの述語ではなく、常にID で要素を識別してください。新しい要素に予測可能な独自の ID を使用することで、複数のライターが同じ要素を同時に作成しようとした場合に、1人のライターだけが勝つことが保証されます。
11.次のセルを実行し、既に存在する ID が person0 の頂点を追加しようとします。

実行結果として返されるエラーを確認すると、該当の ID をもつ頂点が既に存在することがわかります。
12.次のセルを実行し、fold()-coalesce()-unfold() パターンを試します。これにより、頂点が既に存在するかどうかが確認されます。 存在する場合は既存の頂点 ID を返し、 そうでない場合は頂点を作成してその ID を返します。

person0 は既に頂点が作成されていた為、まだ作成していない person1 で同様の手順を試します。
13.次のセルを実行し、ID が person1 の頂点が存在しないことを確認します。

14.次のセルを実行し、fold()-coalesce()-unfold() パターンを使用して頂点を追加します。

一括書き込み操作
最後に、複数の頂点あるいはエッジの追加を単一のクエリとして繋げる方法を紹介します。これにより、各 Gremlin クエリがトランザクションと見なされます。多数の小さなトランザクションをコミットする代わりに、単一のトランザクションで複数の頂点とエッジ(およびプロパティ)を作成することでスループットを向上させることができます。
15.次のセルを実行し、5つの頂点と5つのエッジを持つ小さなサンプルグラフを作成します。

16.次のセルを実行し、作成された頂点とエッジを確認します。

まとめ
このブログでは、グラフデータベースに馴染みのない方に向けて、グラフデータベースでどんなことができるのか具体的なクエリをご紹介しました。
ここでは Gremlin を例に基本的な探索や更新について解説しましたが、ハンズオンで提供されるサンプルノートブックには、より複雑な探索、実行計画の確認、自身でクエリを埋めるエクササイズ形式など応用的な内容も含まれています。また、openCypher 及び SPARQL のバージョンもありますので、ぜひご自身の興味に合わせて色々なクエリをお試しください。
Neptune を利用してアプリケーションを開発するには、Neptune のユーザガイドを参照してください。