AWS Startup ブログ
AI 活用の前提はデータとコンテキスト ─ primeNumber が TROCCO・COMETA と Amazon Bedrock で築く AI Ready なデータ基盤

(左から)AWS 桑原 弘二、株式会社 primeNumber 取締役 CTO 鈴木 健太 氏、同 坂本 竜輝 氏、AWS 冨山 英佑
「あらゆるデータを、ビジネスの力に変える。」をビジョンに掲げ、クラウド ETL サービス「TROCCO」や AI データプラットフォーム「COMETA」を提供する株式会社 primeNumber。同社は「Generative Data Management(GDM)」というコンセプトを掲げ、データと AI を同時に活用する世界に向けたプロダクト開発を進めています。
その中核を担う COMETA と TROCCO では、生成 AI サービス Amazon Bedrock の上で、大規模言語モデル Anthropic Claude を活用しています。
前回のインタビュー記事では代表取締役 CEO の田邊雄樹氏に起業の原点や経営についてお話を伺いました。今回はアマゾン ウェブ サービス ジャパン合同会社 スタートアップ事業本部 シニアアカウントマネージャーの桑原 弘二とソリューションアーキテクトの冨山 英佑が、primeNumber 社 取締役 CTO の鈴木 健太 氏に、COMETA・TROCCO が Amazon Bedrock 上でどのように Claude を活用しているのかをお聞きしました。
※本記事の内容は取材時点(2026 年 6 月)の情報に基づきます。
データと AI は不可分。「集める」TROCCO と「意味を与える」COMETA
桑原:私たちは primeNumber さんと長くお付き合いさせていただいていますが、読者に向けて改めて、事業と TROCCO・COMETA がどういうプロダクトなのかをご説明いただけますか。

株式会社 primeNumber 取締役 CTO 鈴木 健太 氏
鈴木:私たちがやっているのは、AI とデータによってお客様のビジネス課題を解決していくことです。TROCCO と COMETA は、そこにおいて重要なプロダクトになっています。
AI はデータがそもそもないと意図通りに動かないんですよね。一番重要なのは、データの意味を整理して、それを AI に渡してあげること。そしてそもそも綺麗なデータの基盤を整えること。私たちは、一番下の「データレイヤー」と、その 1 つ上の「コンテキストレイヤー」、この 2 つを整備するプロダクトを提供しています。
冨山:その 2 つのレイヤーが、TROCCO と COMETA に対応しているのですね。
鈴木:はい。TROCCO は、点在しているデータを基盤に集約する ETL のプロダクトです。色々なところにデータが点在していると、AI にとっても人にとっても分かりにくい。それをデータ基盤に集約するのが TROCCO のメインの役割です。
ただ、データを集めるだけでは AI 活用には至らなくて。その 1 つ上のコンテキストレイヤーを、COMETA がデータカタログという形で担います。データ基盤上のテーブルやカラムが、それぞれどういう意味なのかを自然言語で定義していくプロダクトです。
冨山:一般的なデータカタログとは、何が違うのでしょうか。
鈴木:データカタログって、一般的にはテーブルやカラムの意味だけを定義するものなんです。でも、それだけだと AI が活用するうえでギャップがあると思っています。例えば、複数のテーブルにまたがって KPI を集計するといった業務は日常的にありますが、その「データの掛け合わせの意味」を定義する機能も持っているのが、私たちのプロダクトです。私たちはこれを「用語集」という機能で実現しています。
冨山:なるほど。お客様が AI でデータを活用したいと考えたとき、一番下のデータレイヤーを整えるのが TROCCO で、その上のコンテキストレイヤーを整えるのが COMETA、という整理ですね。データと AI は不可分で、そのデータを AI に読み込ませるまでの一連の流れを 2 つのプロダクトでカバーしている。
鈴木:そうです。ただ、それをすべてのお客様が自前でできるかというと、なかなか難しい。技術リテラシーのギャップもありますし、散らばっているものを整えて活用のゴールを決めていく作業は、難易度が高く、かつ泥臭い部分です。なので、プロダクトだけでは補えない部分を、プロフェッショナルサービスという形でも提供しています。
モデルを賢くするより、コンテキストを整える ── COMETA の AI 設計
冨山:では具体的に、COMETA の中で Amazon Bedrock 上の Claude がどのように使われているのかを伺います。全体像としては、どういうアーキテクチャになっているのでしょうか。
鈴木:COMETA のコアの機能は、チャットベースの AI です。これまでは、ユーザーがデータベースに対して自分で SQL を書いて、その結果をもとに分析していました。でも、技術リテラシーの問題でなかなか活用が進まないし、そもそもどこに何があるかを理解するにはカタログの情報が必要です。私たちは、ビジネスユーザーが直接データを活用できる世界を目指しています。
そのために必要なのが、カタログと、それを元にした AI エージェント。これが従来のデータ分析者の代替になります。ユーザーが AI エージェントに問い合わせると、エージェントがカタログを複数回・自律的に参照しながら、ユーザーの意図に該当する情報を探します。例えば「売上」と言われたら、売上に該当する情報を見に行く。どこを参照するかは Bedrock をもとに判断する「エージェンティックサーチ」の形です。そうしてテーブルやカラムを特定したら、それを元にもう一度 Bedrock に問い合わせて、最終的に SQL を生成・実行し、結果を返します。
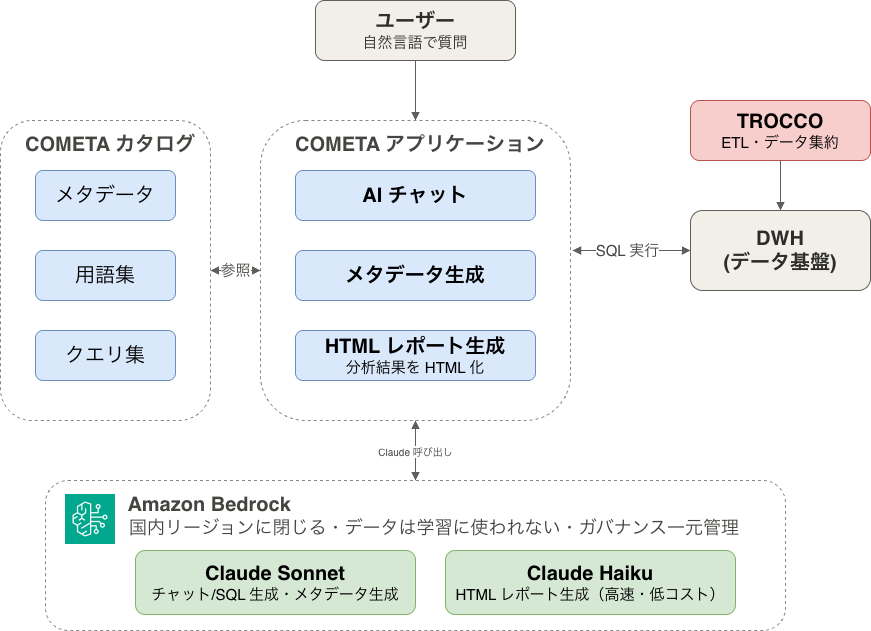
冨山:エージェントがカタログを探しに行く部分は、どのように動いているのですか。
鈴木:決められたプロセスではなく、ある程度自律的に探索させる形で実装しています。ユーザーの意図に対して、まず用語集などを調べて、返ってきたものをもとにもう一度検索する。エージェンティックに探索していくイメージです。フレームワークは AI SDK を使っていて、エージェント自体は状態を持たず、COMETA に関する情報はすべて COMETA の API 経由で取りに行く構成にしています。
冨山:この COMETA のカタログが、プレーンな LLM にコンテキストを与えている部分ですよね。ここが COMETA を COMETA たらしめている、一番大事なところだと感じます。作るうえでの難しさや工夫があれば教えてください。
鈴木:カタログの要素は、大きく 3 つあります。1 つはカラムごとのメタデータ。2 つ目が、さっきの用語集で、複数のテーブルにまたがるセマンティックな情報。例えば「利益」はこのカラムとこのカラムで計算する、といった定義です。そして 3 つ目が、最近リリースした「クエリ集」で、正解の SQL を集めたものです。
実は、最初カタログに含まれていたのはメタデータだけだったんです。でもメタデータだけだと、テーブル間にまたがるような情報が漏れてしまって、AI が正しい結果を返せなかった。そこを補うために用語集を作りました。さらに、ビジネスユーザーが分析したい内容は、実は過去に分析した内容の積み重ねだったりするんですね。それを一から AI に考えさせると、非決定的な部分があり、間違えた回答を行うリスクが高い。だから、過去の正解をクエリ集として用意することで、精度を上げる取り組みをしました。この半年くらいで積み上げてきた部分です。
ビジネスユーザーが使いますし、そもそもどういうデータがあるか分かっておらず、曖昧な質問をされることもあります。私たちはそれを前提にしようと考えました。人間同士でも、ビジネスユーザーが曖昧な要求をして、データの専門家がそこを擦り合わせていく、というのがメインの活動だったはずです。そこを AI に担わせています。なので、曖昧な質問が来たら、AI エージェントが体系的に聞き返すようにシステムプロンプトを組み込んでいます。claude.ai でよくあるように、選択肢を提示して回答してもらう形ですね。AI の非決定的な部分を受け入れつつ、勝手に判断して進めない。これは COMETA の特徴だと思います。
冨山:モデルの選定はいかがでしょう。SQL 生成のような部分は、賢いモデルを使った方がいいのか。例えば Claude Opus のような選択肢も検討されましたか。
鈴木:私たちのこのユースケースでは、Opus を使ったこともあるんですけど、あまり精度が変わらなかったんです。それよりも、コンテキストをちゃんと整備していく方が重要で。Opus ほどの性能が求められる処理というより、実際はコンテキストをちゃんと整理した方が精度向上に効く。これ以上モデルが賢くなっても、あまり変わらない気がしていて。どちらかというと、コンテキストのところをちゃんとやる方が大事だと思っています。
冨山:「モデルを賢くするより、コンテキストを整える」と。モデルは現在、どう使い分けているのですか。
鈴木:AI チャットや SQL 生成は Claude Sonnet がコアです。一方、分析結果を HTML レポートにする機能では、大量の出力が出るのでパフォーマンスが求められます。ここは取材時点では Claude Haiku を使っていて、体感ですが Sonnet と比べておおよそ 3 分の 1 くらいの時間で出せるようになりました。コストの面でも、採算を考えるとだいぶ違います。このように用途に応じて使い分けています。
それから、COMETA のもう 1 つの Bedrock 活用がメタデータ生成です。カラム名などから、それがどういう意味かを AI に自然言語で記述させる。ここでは、サンプルデータとスキーマ情報に加えて、TROCCO の設定情報も与えています。TROCCO はあるテーブルがどこからどう転送されてきたかという設定を持っているので、その情報も合わせてメタデータ生成に役立てています。さらに、用語集で事前に定義された社内の前提知識も使う。コンテキストを重ねていくイメージです。これは Sonnet を使っています。
冨山:TROCCO 側でも Bedrock を利用されているのですね。
鈴木:TROCCO には「カスタムコネクタ」という機能があります。TROCCO は 100 種類以上のコネクタをサポートしていますが、お客様が自社で使っている API など、対応しきれていないものもある。そういった API を通してデータを取り込みたい、というニーズに応えるのがカスタムコネクタです。ただ、これをユーザーに設定してもらうのは結構大変なんですね。そこで Bedrock を使っています。公開されている API 仕様書の URL を入れると、Bedrock がそのスペックを見に行って、コネクタの設定ドラフトを作ってくれる。これまで手でやらなければいけなかった部分が、AI でできるようになりました。ここは AI エージェントではなく、Bedrock の API を直接呼ぶ、もう少しシンプルな使い方です。モデルは Amazon Nova Pro ですね。
データを国内・自社環境に閉じたまま使える。だから Bedrock
桑原:数ある選択肢の中で、Claude を Amazon Bedrock 経由で使う理由を伺えますか。
鈴木:私たちが Bedrock を使っている一番の理由は、データが AWS の環境内・国内リージョンに閉じること、そしてデータが学習に使われないことです。お客様には「自分たちの重要なデータがどこに流れるのか」を気にされる方が多いんです。
冨山:導入時のセキュリティチェックで問われる、ということですか。
鈴木:はい。導入時のセキュリティチェックシートで「国内リージョンだけに閉じていること」を求められるケースが増えています。最近はセキュリティチェックシートに加えて、AI プロダクト向けのガバナンスチェックリストをいただくことも増えました。どこの会社もガバナンスを重要視する流れになってきていて、それが仕組みとして整備され始めているのかなと思います。
冨山:それは大手企業が中心なのでしょうか。
鈴木:大手じゃなくても求められるケースが多いです。どこの会社も AI に対してのセキュリティ意識が高まっているのを感じます。「我々の環境内・データベース内に通している」「国内リージョンである」「データが学習に使われない」、この 3 点が、私たちが Bedrock を使っている理由になっています。
冨山:同じ Bedrock という基盤の上で統一的にモデルを使えるのは、運用面でもメリットがありそうですね。
鈴木:私たちとしては楽ですね。色々な API を叩き始めると、コスト管理も「ちゃんと国内に閉じているか」の確認も分断されてしまう。Bedrock が 1 つのレイヤーでラッピングしてくれることで、そこを私たちが考えなくて済む。これはすごいメリットだと思っています。
コンテキストを「自律的に育てる」プロダクトへ
冨山:最後に、今後のプロダクトの展望を伺えますか。
鈴木:会社としては GDM の実現に向けて、AI に必要なデータ基盤と、その上のコンテキストレイヤーをいかに自律的に育てていけるか、というところを目指しています。
例えば、COMETA の AI チャットで各ユーザーが分析した内容って、本来は組織のナレッジ・コンテキストになっていくべきだと思うんです。今はアドホックに集計して終わりで、組織に積み上がっていかない。そこを組織のコンテキストに昇格させていく。具体的には、BI のような領域を COMETA に取り込んでいく構想もあります。GDM の実現に向けて、自律的にデータ基盤とコンテキストレイヤーを整備していく。それをプロダクトとコンサルティングの両輪で実現していく、というのが大きな方向性です。

冨山:お客様が手元で使っているエージェントから、COMETA のコンテキストを呼び出したいというニーズもありそうですね。
鈴木:あります。ちょうど取材の前週に、COMETA の用語集やメタデータを外部から直接呼べる Public API を公開しました。例えば Claude Code のようなツールから、COMETA のコンテキストを使いたい、というニーズがあるんです。どの AI を使うかに依存しない使い方ができる。
冨山:社内でも COMETA は活用されているんですか。
鈴木:社内のビジネスユーザーも COMETA を利用していて、今ちょうど「どれだけ業務時間が短くなったか」を社内アンケートで集計しているところです。暫定ですが、一人あたり 2、3 日分くらいは短縮できていそうだ、という手応えがあります。全体で考えると、かなりの業務改善に繋がり、より高付加な仕事に時間を使えるようになってきています。
一人で AI を使う場合は、自分で必要なコンテキストを貯めていけます。でも、それを組織全体でどう共有するかが課題になる。だからこそ、コンテキストは一か所に集約してあげたいんです。
桑原:AWS に対して、今後期待することはありますか。
鈴木:私たちは今、AI チャットという領域に向き合っていますが、今後はプロダクトとしてサポートする AI のユースケースが増えていくと思っています。そこで、柔軟なモデル選択と、ガバナンスが一括で管理されている状態が両立していること。ここは引き続き期待しているところです。Bedrock や Claude の性能が上がれば上がるほど、お客様に返せるものが増えていく。そういったところは、ぜひ AWS さんと一緒にやらせていただきたいです。
冨山:COMETA が管理するメタデータ・用語集・クエリ集は、まさにビジネスデータのコンテキストとして一番大事なところだと感じます。この情報をどう蓄積していくかが、これからの課題であり続けるのだと思います。ぜひ私たちも一緒に、その世界の実現を後押しさせてください。
桑原:本日は貴重なお話をありがとうございました。引き続き、御社のプロダクトづくりを全力でサポートさせていただきます。
著者情報
冨山 英佑(Eisuke Tomiyama)
アマゾン ウェブ サービス ジャパン合同会社 スタートアップ事業本部 ソリューションアーキテクト。
桑原 弘二(Koji Kuwabara)
アマゾン ウェブ サービス ジャパン合同会社 スタートアップ事業本部 シニアアカウントマネージャー。