- AWS Builder Center›
- builders.flash
生成 AI を活用したニュース 3 行要約を配信するシステムをマネージドに作成する ~ ニフティ株式会社による生成 AI 実装解説 ~
2024-05-01 | Author : 中村 伊吹 (ニフティ株式会社)
はじめに
この記事では定期的に配信されるニュース記事に対して、生成 AI による 3 行要約を Amazon Bedrock で作成し、それを Amazon CloudFront 経由で API として配信するシステムの構成についてご紹介します。
現在は Amazon Bedrock を利用することで、最新の生成 AI モデルが利用可能かつ、コストも利用に応じた金額だけになりました。生成 AI はプロンプトエンジニアリングを活用することで、様々なタスクに適用することができ、初期の PoC からプロダクションリリースにおいても効果的に活用できます。
本記事ではほとんどの部分をマネージドサービスで構成することで、運用コストを下げながら低コストで実現した機械学習システムの一例をお見せします。
builders.flash メールメンバー登録
ニフティニュースにおける記事の 3 行要約と課題
ニフティニュースは新聞、雑誌、週刊誌を始め、話題のネットニュースなどを集約して配信するニュースメディアです。 ニフティニュースでは 3 行要約と呼ばれる短い要約を、それぞれの記事に作成しています。
しかし、この要約は作成コストが高く、人力で作成するには労力も金銭的なコストもかかる作業です。したがってこれらを生成 AI によって自動作成するシステムを構築することにしました。
この要約機能リリース当初は、機械学習エンジニア (筆者) によってチューニングされたモデルを Amazon SageMaker 上にホストすることで要約を生成していましたが、データを更新したモデルを定期的に載せ直す必要性や、ホスティング環境のメンテナンスコスト、運用の手間の面からも、より効率的に運用する方法がないかと考えていました。
しかし Amazon Bedrock の登場により多くの部分をマネージドかつサーバーレスに構成することが可能になり、メンテナンスコストが大きく下がりました。本記事で紹介するのは、最終的にプロダクションに採用したアーキテクチャ構成です。
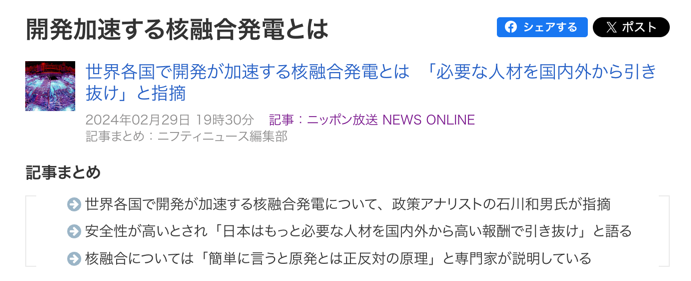
全体像
本記事では以下のような要件でシステムを構成します。
-
定期的にニュース記事が配信され、記事は DB に保存されていく
-
DB に保存された記事に対して、3 行で構成された要約 (3 行要約) を生成する
-
生成された要約は WebAPI で (別の環境で動作する) フロントエンドに配信される
これをそのまま構成するとこのような形になることが考えられます。
しかし、この構成では以下のような課題があります。
-
要約結果を保存するための新しい DB の設計および管理
-
配信するためのアプリケーションサーバーの開発・ホスティングが必要
-
WebAPI で配信するための何らかのアプリケーションが必要です
-
-
記事数が増えてきた場合における適切な Lambda 関数のスケジューリング
-
生成する記事数が増えてきた場合において、1 度の Lambda 関数実行では処理しきれない場合があり、タスクをキューイングなどの何らかの方法で管理する必要があります
-
この構成でも問題はありませんが、PoC 段階などの場合においてはさらに開発工数を削減し機能のリリースを優先させたいです。
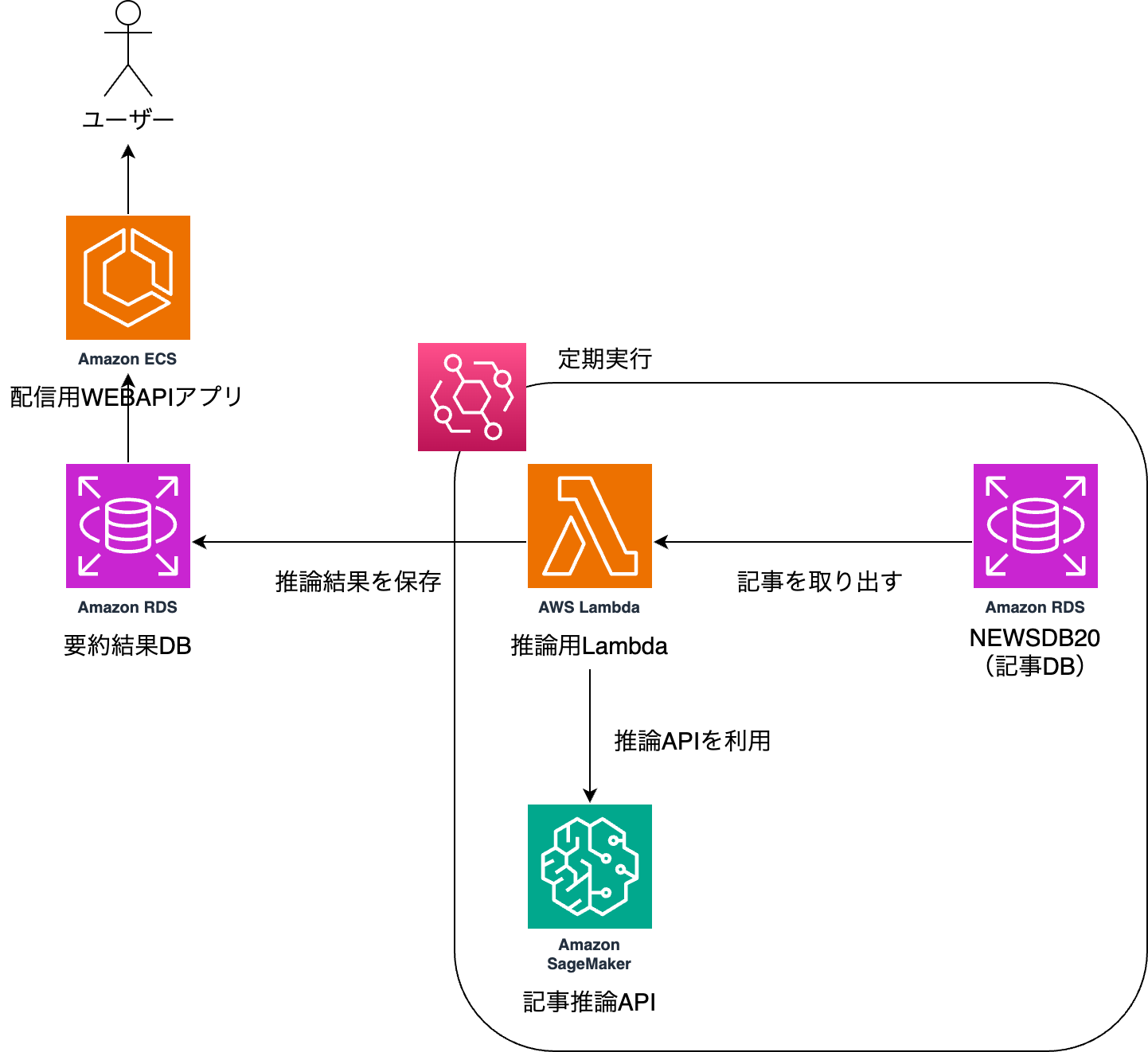
構成の課題
そこでこちらのようにアーキテクチャを構成します。
このポイントは以下の通りです。
-
Amazon S3 トリガーと AWS Lambda を利用することで、サーバーレスかつステートレスに構成します
-
1 記事ごとに Lambda 関数を発火させることで、複雑なキューイング処理を不要にします
-
推論や生成は Amazon Bedrock によって行われるため、サーバーレスに実行されます
-
Amazon S3 と Amazon CloudFront を用いて JSON を配信することで、配信のためのアプリケーションを不要にします
-
ほとんどをサーバーレスで構成することで、メンテンナンスコストを下げ、運用の手間を無くします
-
固定でかかる費用もほぼ 0 にできるため、スモールスタートの場合においてもコスト最適で実現できます
-
特に Amazon Bedrock を用いて 3 行要約を生成する部分に関して、次の章で解説します。
Amazon Bedrock で 3 行記事要約を生成する
要約生成の手順
この Lambda 関数においては、以下の手順で要約を生成します。
-
S3 バケットからのイベントトリガーを受け取ります。イベントには、要約対象の記事データが格納されている S3 バケット名とオブジェクトキーが含まれており、どの記事データを読み出せばいいのかを渡されたイベントの内容から判別します。
-
イベントから取得したバケット名とオブジェクトキーを使用して、S3 バケットから記事データを読み込みます。記事データは JSON ファイルとして格納されており、記事のテキストが含まれています。
-
読み込んだ記事データから記事のテキストを取り出し、generate_summary 関数に渡します。この関数は、Amazon Bedrock を使用して記事の 3 行要約を生成します。
-
generate_summary 関数ではプロンプトを用いて、最終的に JSON ファイルを生成 AI に出力させます。生成 AI が生成する JSON は有効ではない場合があるため、3 回までリトライするように制御します。
-
-
generate_summary 関数から返された要約を受け取ります。要約は、summary_1、summary_2、summary_3 の 3 つのキーを持つ辞書として保持します。
-
生成された要約を、save_summary_to_s3 関数を使用して要約配信用の S3 バケットに保存します。要約は、記事 ID をファイル名に使用して JSON ファイルとして保存します。ここでは保存先の S3 バケットは、環境変数 SAVE_SUMMARY_S3_BUCKET で指定していることにしています。
以上の手順により、S3 バケットに格納された記事データから 3 行の要約を生成し、別の S3 バケットに保存する手順を自動的に行います。この AWS Lambda は、S3 イベントをトリガーとして使用しているので、新しい記事データが追加されるたびに自動的に要約が生成されます。
ニュース記事におけるプロンプトのテクニック
Claude に与えるプロンプトのテクニックとして、ニュース記事における 3 行要約では「記事の最初・中間・終わりがバランスよく含まれるようにしてください」という指示を与えることで、記事全体に言及しつつ分かりやすい要約を生成できます。この指示がない場合、記事の一部に偏った要約が生成され、読者がニュースの全体像を把握できなくなります。その結果、3 行要約の本来の目的である「素早くニュースを理解する」ことができず、要約の意味が薄れてしまいます。
また、ニュース記事要約においては「固有名詞や専門用語はそのままにして」というプロンプトは重要です。ニュース記事には固有名詞や専門用語が多く含まれていますが、特に英語表記の場合において Claude などの生成 AI は単語を翻訳して要約を生成してしまうために、要約が不自然になることがあります。「固有名詞や専門用語はそのままにして」と指示を明確に与えることで、生成された要約がより自然なものになります。
実装の初期段階においては実際に生成された要約を確認しながら、不自然な要約だと感じる点を見つけ、直接かつ具体的にプロンプトで指示を与えることで、生成 AI の出力を改善することができます。(コード内に記載しているプロンプトは簡略化されたものであり、実際のプロダクション環境のプロンプトとは異なります)
要約を WebAPI として配信する
AI による要約結果を JSON として S3 に保存し、Amazon CloudFront を通して WebAPI として配信します。この構成には以下のような利点があります。
-
アプリケーションサーバー不要で API として配信可能
S3 に保存された JSON ファイルを Amazon CloudFront を通して直接 WebAPI として配信できるため、API を提供するためのアプリケーションサーバーを用意する必要がありません。これにより、インフラの構成がシンプルになり、運用コストを抑えることができます。
-
自動的なスケーリングとキャッシュ
Amazon CloudFront は CDN (Content Delivery Network) サービスであり、世界中に分散されたエッジロケーションを利用してコンテンツを配信します。アクセス数が増加しても、CloudFront が自動的にスケーリングを行うため、API の可用性を高く維持できます。またキャッシュを利用することで、同じリクエストに対してはキャッシュされた結果を返すことができるため、リクエストの処理時間を短縮できます。
-
セキュリティの強化
Amazon CloudFront を用いることで DDoS 攻撃の緩和やアクセス制御、AWS WAF との統合を行うことが可能です。現在のところ今回構築した API が攻撃を受けたことはありませんが、既知の脆弱性を悪用する攻撃や同一 IP 元からのアクセス攻撃などをブロックできるため、この点においても運用コストを下げることが可能です。
Amazon Route 53 で CloudFront にルーティングを行い、CloudFront のビヘイビアによるパス設定を行うことで、フロント側では通常の API と似たような形(例えば、[api サーバーの URL]/summary/[id].json) でアクセスすることが可能になります。
ニフティニュースでは既存のシステムにおいて Amazon CloudFront を採用しており、今回は静的なリソース配信のみで完結することから、アプリケーション開発が不要となるこのような構成を採用しました。開発工数を削減できた分、インフラ構築から検証および実際の機能リリースまで 1 ヶ月で完了するという、非常にスピード感のあるリリースができたと考えています。
要約を WebAPI として配信する
AI による要約結果を JSON として S3 に保存し、Amazon CloudFront を通して WebAPI として配信します。この構成には以下のような利点があります。
-
アプリケーションサーバー不要で API として配信可能
S3 に保存された JSON ファイルを Amazon CloudFront を通して直接 WebAPI として配信できるため、API を提供するためのアプリケーションサーバーを用意する必要がありません。これにより、インフラの構成がシンプルになり、運用コストを抑えることができます。
-
自動的なスケーリングとキャッシュ
Amazon CloudFront は CDN (Content Delivery Network) サービスであり、世界中に分散されたエッジロケーションを利用してコンテンツを配信します。アクセス数が増加しても、CloudFront が自動的にスケーリングを行うため、API の可用性を高く維持できます。またキャッシュを利用することで、同じリクエストに対してはキャッシュされた結果を返すことができるため、リクエストの処理時間を短縮できます。
-
セキュリティの強化
Amazon CloudFront を用いることで DDoS 攻撃の緩和やアクセス制御、AWS WAF との統合を行うことが可能です。現在のところ今回構築した API が攻撃を受けたことはありませんが、既知の脆弱性を悪用する攻撃や同一 IP 元からのアクセス攻撃などをブロックできるため、この点においても運用コストを下げることが可能です。
Amazon Route 53 で CloudFront にルーティングを行い、CloudFront のビヘイビアによるパス設定を行うことで、フロント側では通常の API と似たような形(例えば、[api サーバーの URL]/summary/[id].json) でアクセスすることが可能になります。
ニフティニュースでは既存のシステムにおいて Amazon CloudFront を採用しており、今回は静的なリソース配信のみで完結することから、アプリケーション開発が不要となるこのような構成を採用しました。開発工数を削減できた分、インフラ構築から検証および実際の機能リリースまで 1 ヶ月で完了するという、非常にスピード感のあるリリースができたと考えています。
フロントエンドから今回構築した API を使って 3 行要約を取得することで、最終的にこのように記事ページに表示しました。
生成 AI を活用したプロダクトにおける注意点
生成 AI を活用する場合には、生成 AI の利点と実現可能な範囲の理解が必要になります。
今回のような要約作成において、生成 AI は絶大な効果をもたらします。人の手による要約作成はどれだけ多くても 1 人 1 日 50 記事程度が限度であり、多く作成しようとするとそれだけ人手が必要になります。これが生成 AI を活用することによって、現在 1 日 2000 記事を超える記事に要約が付与されています。
しかし、生成 AI も万能ではなく、人間には違和感がある文章を出力したり、人間にはあまりない間違いをすることがあります。例えば今回のような記事要約の場合、記事内の時系列情報を混同する、対義語に変換されて出力されるといった現象が起きます。自分自身の経験として、ニュース記事の要約を作成する場合に、人間ではこのような間違いはほとんど起こりません。間違いを起こさない・人間が理解できる間違いだけをする、ということは AI にはまだ難しいため、ある程度の間違いは許容されるような用途に現在の生成 AI は向いています。ニフティニュースにおいては注釈をつけることで生成 AI の限界をユーザーに認識してもらいつつ、生成 AI を活用する道を現在も模索しています。
また、今回は生成 AI に JSON を出力してもらうことでプログラム内で扱いやすくしています。JSON を直接出力してもらうことで取り扱いがしやすくなる一方で、Claude 3 Haiku などのモデルでは有効な JSON が出力されやすい傾向にあることは確かですが、出力された JSON が有効かどうかを確認する作業は必要となる、というのが私の経験に基づく感想です。リトライ処理などを追加し、生成 AI が苦手とする作業を補うことによって、既存のアプリケーションへの適用を素早く行うことが可能になると思います。
まとめ
本記事ではマネージドかつサーバーレスに機械学習システムを構成し、生成 AI プロダクトをプロダクションにリリースする一例について紹介しました。Amazon Bedrock を利用することで、AI を活用したチャレンジングな取り組みを手軽かつスピード感を持って行うことが可能になったと感じています。
さらに Amazon S3 と Amazon CloudFront を効率的に活用することで、WebAPI での静的コンテンツ配信において追加のアプリケーションサーバ開発不要で素早くプロダクションへのリリースが可能になります。AWS を効率的に活用してこれからも最高の AI アプリケーションを作っていきたいと思います。
筆者プロフィール
中村 伊吹(なかむら いぶき)
ニフティ株式会社でニフティニュース開発リーダーを担当。
スクラム開発による「いきいきとしたチーム」の構築を目指している。その他、スペシャリスト制度であるN1!Machine Learning Product Engineerとして、プロダクトへの機械学習実装をミッションに活動する。
男女混成チアリーディング元日本代表という謎の経歴を持つ。

Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages