(Physical AI を) やらないか 〜 ACT 学習 & 動作検証編
2026-04-02 | Author : 大前 遼

はじめに
ソリューションアーキテクトの大前です。
物理学ではエントロピー増大の法則という言葉があります。一般に物事は放っておくと乱雑な方に向かっていく。私の机も例に漏れません。ただし厳密に言えば、私の机のエントロピー増大は「放っておく」ことが原因ではなく、「私が片付けない」ことが原因です。誰かが代わりに片付けてくれたらいいのに。
そんな願いを叶えてくれるかもしれない技術が、Physical AI です。Physical AI とは物理世界を知覚し、理解し、操作するようなシステムを指しており、ここ数年で大きく進化を遂げています。さらに、3D プリンターで作成可能なオープンソースのロボットも次々と登場しており、個人でも手が届く範囲になりつつあります。
ただし、現状の技術で汎用的な「片付けロボット」を実現するのはまだ先の話です。本記事ではその第一歩として、代表的なオープンソースロボットアームである SO-101 (3D プリンターで作成可能な 6 自由度のロボットアーム) と Physical AI を利用して、特定の配置で消しゴムをカゴにしまうシステムを作る様子をご紹介します。
Amazon SageMaker AI を使って、ロボットポリシーである「ACT (Action Chunking with Transformers)」を学習し、ローカル Mac 上で推論を実行します。手元に高価な GPU マシンがなくても、SageMaker AI なら ml.g5.4xlarge (NVIDIA A10G) 1 台で約 $16 の学習コストで完了します。
ご注意
本記事で紹介する AWS サービスを起動する際には、料金がかかります。builders.flash メールメンバー特典の、クラウドレシピ向けクレジットコードプレゼントの入手をお勧めします。
builders.flash メールメンバー登録
builders.flash メールメンバー登録で、毎月の最新アップデート情報とともに、AWS を無料でお試しいただけるクレジットコードを受け取ることができます。
1. 模倣学習と ACT
模倣学習とは
ロボットに作業を覚えさせる方法の一つに模倣学習があります。人間がロボットを操作している間のカメラ映像や関節角度を記録し、「この状況ではこう動く」という対応関係をニューラルネットワークに学習させます。この「観測された状況から次の動作を決める関数」をポリシーと呼びます。
ACT(Action Chunking with Transformers)とは
ACT は Stanford 大学が 2023 年に発表した模倣学習の手法です(論文)。最大の特徴は「次の 1 動作」ではなく「次の数十動作をまとめて(chunk)」予測する点です。
人間の感覚で言えば、「指を 1mm 動かすたびに次を考える」のではなく、「コップを掴んで持ち上げるまでの一連の流れをイメージしてから動く」に近い方式です。これにより、手先の細かいブレが蓄積しにくくなり、一連の動きが安定します。また、パラメータ数が約 80 M と比較的軽量であり、非 GPU 搭載のマシンであっても推論が可能です。
ACT の詳しい特性と限界は、実験結果を踏まえて 「7. ACT の特性と限界の考察」で考察します。
2. テレオペレーションによるデータ収集
アームとカメラの設置
SO-101 はリーダーアームとフォロワーアームの 2 本構成です。人間がリーダーアームを操作するとフォロワーアームが追従し、その動きとカメラからの映像を同時に記録します。
今回のタスクは「消しゴムを拾ってカゴに入れる」というシンプルなものです。2 台のカメラ(手先カメラ + 俯瞰カメラ)で映像を撮影しながら、20 エピソード(各 15 秒、30 FPS)を収集しました。合計 8,767 フレーム、約 5 分のデモデータです。
俯瞰カメラとしては市販されている Web カメラを利用し、手先カメラとして innomaker U20CAM-1080P を利用しました。俯瞰カメラはミニ三脚の上にのせ、アームの根元から手先までとフィールド全体が映るように配置しました。手先カメラについて、今回は暫定的にクランプをマウントとしてテープで固定しましたが、3D プリンターで印刷可能な手先カメラ用パーツ も公開されており、再現性確保のためには印刷されることをお勧めします。
データ収集コマンド
LeRobot ライブラリでは次のコマンドでテレオペレーションおよびデータ収集を実施できます。
lerobot-record \
--robot.type=so101_follower \
--robot.port=/dev/tty.<FOLLOWER_ARM_PORT> \
--robot.id=my_follower_arm \
--robot.cameras="{ front: {type: opencv, index_or_path: 0, width: 640, height: 480, fps: 30}, wrist: {type: opencv, index_or_path: 2, width: 640, height: 480, fps: 30}}" \
--teleop.type=so101_leader \
--teleop.port=/dev/tty.<LEADER_ARM_PORT> \
--teleop.id=my_leader_arm \
--display_data=true \
--dataset.repo_id=${HF_USER}/so101_basic_eraser_pick \
--dataset.num_episodes=20 \
--dataset.single_task="Pick up the eraser and put it in the basket"操作を録画
コマンドを実行すると Rerun のビジュアライザが起動し、カメラ映像と関節角度をリアルタイムに確認しながら操作を録画できます。1 エピソード完了するたびに自動的に次のエピソードへ進みます。
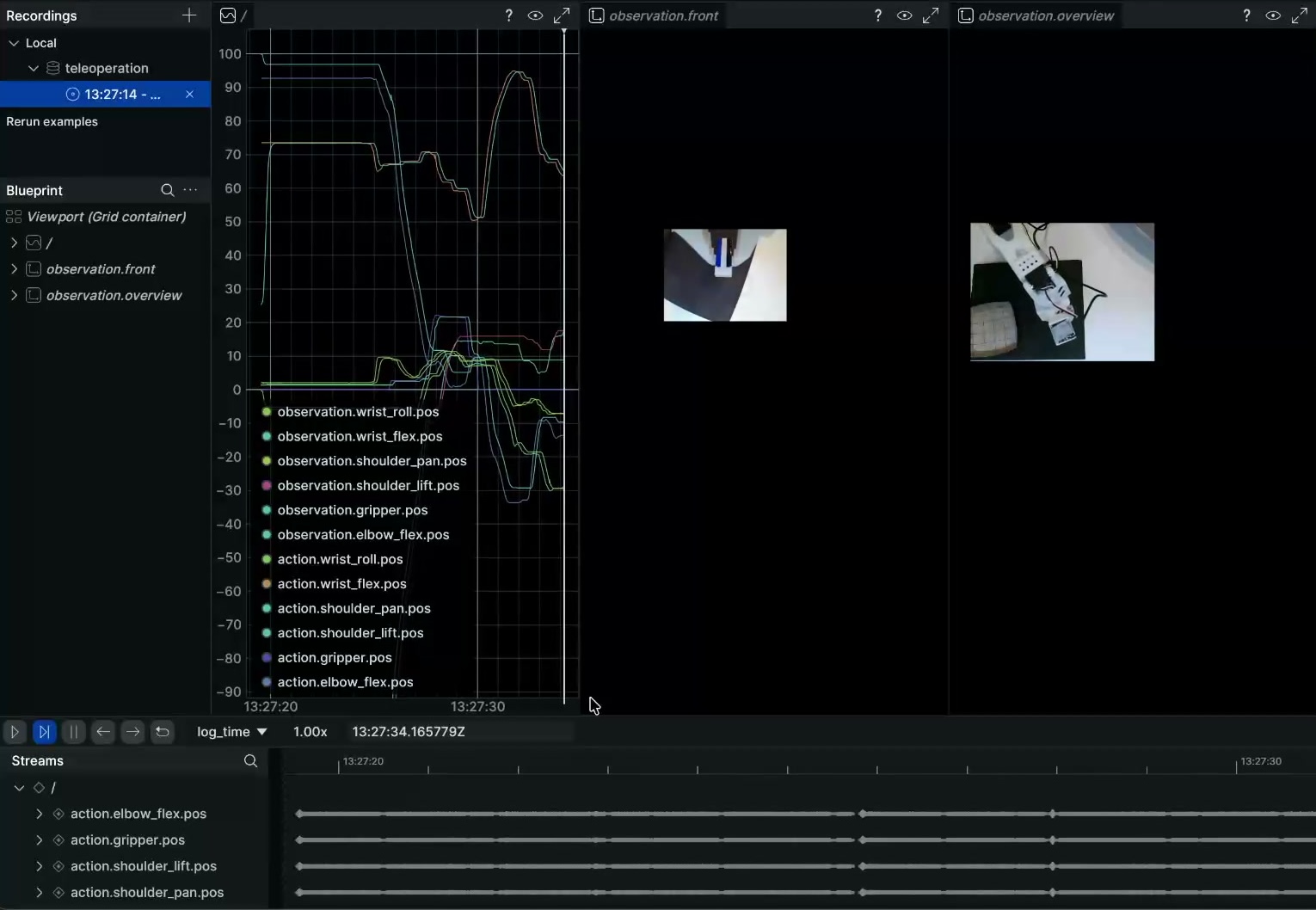
3. データセットを Amazon S3 にアップロード
収集したデータセットは LeRobotDataset v3.0 形式 (動画 + 関節角度の時系列 + メタデータ) でローカルに保存されています。SageMaker Training Job の入力チャネルとして利用するため、Amazon S3 にアップロードします。
aws s3 sync \
~/.cache/huggingface/lerobot/${HF_USER}/so101_basic_eraser_pick \
s3://sagemaker-us-west-2-xxxxxxxxxxxx/lerobot-data/${HF_USER}/so101_basic_eraser_pick20 エピソード × 2 カメラで約 100MB のデータです。アップロードは数十秒で完了しました。
4. SageMaker Training Job で ACT を学習
- インスタンス : ml.g5.4xlarge (NVIDIA A10G、VRAM 24 GB)
- ステップ数 : 100,000
- バッチサイズ : 8
- 学習率 : 1e-5
- chunk_size : 100
- Vision Backbone : ResNet18 (ImageNet 事前学習済み)
ジョブの投入
以下の Python スクリプト (sagemaker_train_act.py) をダウンロード・解凍して Training Job を投入します。エントリポイント (train_entry.py) を tar.gz にして S3 にアップロードし、 create_training_job API を呼び出します。
train_entry.py
エントリーポイント train_entry.py は SageMaker のコンテナ内で実行されるスクリプトです。LeRobot のインストール、学習の実行、MLflow へのメトリクス記録を行います。
# train_entry.py(抜粋)
policy_type = os.environ.get("SM_HP_POLICY_TYPE", "act")
cmd = [
sys.executable, "-m", "lerobot.scripts.lerobot_train",
f"--dataset.repo_id={dataset_repo_id}",
f"--dataset.root={input_dir}",
f"--policy.type={policy_type}",
f"--batch_size={batch_size}",
f"--steps={steps}",
]学習結果
ml.g5.4xlarge (A10G 24 GB) で 100,000 steps の学習が約 5 時間で完了しました。環境セットアップを含む billable time は約 7.5 時間で、オンデマンド料金で約 $16 です。学習が完了すればインスタンスは自動停止するため、無駄なコストが発生しません。
5. MLflow Apps で実験管理
学習曲線の推移
6. ローカル Mac で推論
学習済みチェックポイントを Mac にダウンロードし、ローカルで推論を実行します。SageMaker で学習し、ローカルで推論するというフローにより、GPU を持たない開発者でもロボティクス AI に取り組める構成になっています。
ACT は約 80M パラメータと軽量で、Mac の CPU/MPS でも 30FPS のリアルタイム推論が可能です。
ただし、SageMaker(CUDA 環境)で学習したモデルの config.json には "device": "cuda" と記録されています。Mac で推論する前に、この値を "mps" (Apple Silicon) または "cpu" に変更してください。
config.json の device を mps に変更
# config.json の device を mps に変更
sed -i '' 's/"device": "cuda"/"device": "mps"/' models/act_so101_eraser_pick/pretrained_model/config.json学習済みモデルでロボットを動かす
lerobot-evaluate \
--robot.type=so101_follower \
--robot.port=/dev/tty.<FOLLOWER_ARM_PORT> \
--robot.id=my_follower_arm \
--robot.cameras="{ front: {type: opencv, index_or_path: 0, width: 640, height: 480, fps: 30}, wrist: {type: opencv, index_or_path: 2, width: 640, height: 480, fps: 30}}" \
--policy.path=models/act_so101_eraser_pick/pretrained_model動作検証の結果
成功ケース
成功ケースでは、学習データと同じ配置(消しゴムの位置、カメラ角度)では、ピックアップからカゴへの投入まで一連の動作を安定して再現できました。同じかほぼ同様の条件であれば繰り返し成功します。

失敗ケース
一方、消しゴムを横向きに置いたり、位置を数 cm ずらすだけで、アームの軌道が大きくずれてタスクが失敗しました。同じ配置なら何度やっても成功するのに、少し変えるだけで崩れる。この差に ACT の本質が見えます。

7. ACT の特性と限界の考察
実験結果を振り返ると、ACT の特性が明確に見えてきました。
なぜ同一条件では成功するのか
ACT は ImageNet で事前学習済みの ResNet18 で画像を符号化し、CVAE (Conditional Variational Auto-Encoder) で連続する複数ステップの行動列 (action chunk) をまとめて生成します。20 エピソードという少数データでも、同一条件下では十分に模倣学習が成立しました。
これは ACT の強みです。固定された環境・固定されたタスクであれば、少ないデータ収集で高い再現性を実現できます。
なぜ環境変化に弱いのか
一方で、学習データの分布外に出ると途端に失敗します。原因は大きく 2 つ考えられます。
- 大規模な事前学習がない
ACT の Vision Backbone は ImageNet で事前学習された ResNet18 ですが、これは画像分類のための汎用特徴量であり、「消しゴムとは何か」「横向きの物体をどう掴むか」といったロボット操作に必要な知識は含まれていません。20 エピソード分の視覚パターンと動作の対応しか学習していないため、見たことのない配置に汎化できません。
- Action Chunking の連鎖崩壊
ACT は chunk_size=100(30FPS で約 3.3 秒分)のアクションをまとめて予測します。ACT には temporal ensemble(複数チャンクの予測を混合する仕組み)による緩和機構はあるものの、対象物の位置認識が根本的にずれた場合はチャンク全体の軌道が連鎖的に崩壊します。
データ量だけで解決するか
今回は 20 エピソードと少量でしたが、仮にエピソード数を 100〜200 に増やしても、全て同じ配置で収集しては汎化性能は向上しません。重要なのはエピソード数ではなく、環境のバリエーション (物体位置、照明、背景などのランダム化) を含めてデータを収集することです。
ACT の元論文でも 50 エピソード程度でも環境に多様性があれば十分な性能が報告されています。例えば、消しゴムの向きを複数パターンで記録する、カメラの設置位置をずらしつつ記録する、照明条件を変える、などの工夫が必要そうです。
8. VLA モデルへの展望
ACT の限界を克服する候補が、VLA (Vision-Language-Action) モデルです。
VLA は大規模な画像・言語データで事前学習されているため、「物体とは何か」「どう掴むか」という世界知識を既に獲得しています。SmolVLA や π₀ などの事前学習済み VLA に少数のロボットデータでファインチューニングすることで、環境変化への汎化が期待できます。
ただし、VLA にも課題はあります。特定のロボットアーム (SO-101 など) での動作には依然としてファインチューニングが必要であり、推論レイテンシーも ACT より大きくなります。万能ではありませんが、「学習データと異なる状況にもある程度対応できる」という点で、ACT の限界を大きく押し広げる可能性があります。
今回構築したパイプラインは、そのまま VLA にも適用可能です。 train_entry.py の policy_type を変更し、インスタンスタイプをスケールアップするだけで切り替えられます。
インスタンスタイプの選択
|
目的
|
policy_type
|
インスタンスタイプ
|
|---|---|---|
|
ACT の学習
|
policy_type = "act" |
ml.g5.4xlarge (A10G) で十分 |
|
VLA のファインチューニング
|
policy_type = "smolvla" |
ml.g5.12xlarge にスケールアップ |
インスタンスタイプを変えるだけでスケールアップでき、使った分だけの課金で済むのは SageMaker AI の利点です。
次回の記事では、VLA のファインチューニングと実機での推論結果を紹介する予定です。ACT で見えた「環境変化への脆弱性」が、事前学習済み VLA でどこまで改善されるか。 実験結果をお楽しみに。
コスト試算
|
リソース
|
利用内容
|
コスト
|
|---|---|---|
|
SageMaker Training
|
ml.g5.4xlarge × 約 7.5 時間 (100K steps) |
約 $16 |
|
Amazon S3
|
データ + モデル保存 (~500MB × 1 ヶ月) |
約 $0.01 |
|
MLflow Apps
|
実験メタデータ (S3 ストレージのみ) |
約 $0.01 |
|
合計
|
|
約 $16 |
GPU マシン (RTX 4090 搭載 PC で 30〜50 万円) の購入と比べると、$16 でモデルの可能性を検証できるのは大きな利点です。学習完了後にインスタンスが自動停止するため、停め忘れによる課金も発生しません。
なお、ハードウェア費用 (SO-101 パーツ代約 3 万円 + カメラ約 5,000 円 + 3D プリント代) は別途必要です。
まとめ
本記事では、SageMaker AI を利用して ACT による模倣学習を実施しました。SageMaker AI を利用することで、GPU サーバーを持たなくてもロボット操作ポリシーの学習を始められます。モデルの切り替えもハイパーパラメータ 1 つ、スケールアップもインスタンスタイプの変更だけです。
Physical AI の実験サイクルを回す基盤として、参考にしていただければ幸いです。
筆者プロフィール
大前 遼 (おおまえ りょう)
アマゾン ウェブ サービス ジャパン合同会社
ソリューションアーキテクト。
製造業のお客様を中心に、クラウド活用の技術支援を行っています。最近は Physical AI / ロボティクスとクラウドの組み合わせに夢中です。