- 料金›
- クラウド構成と料金試算例 TOP
データレイクにあるデータを使った分析環境を構築したい
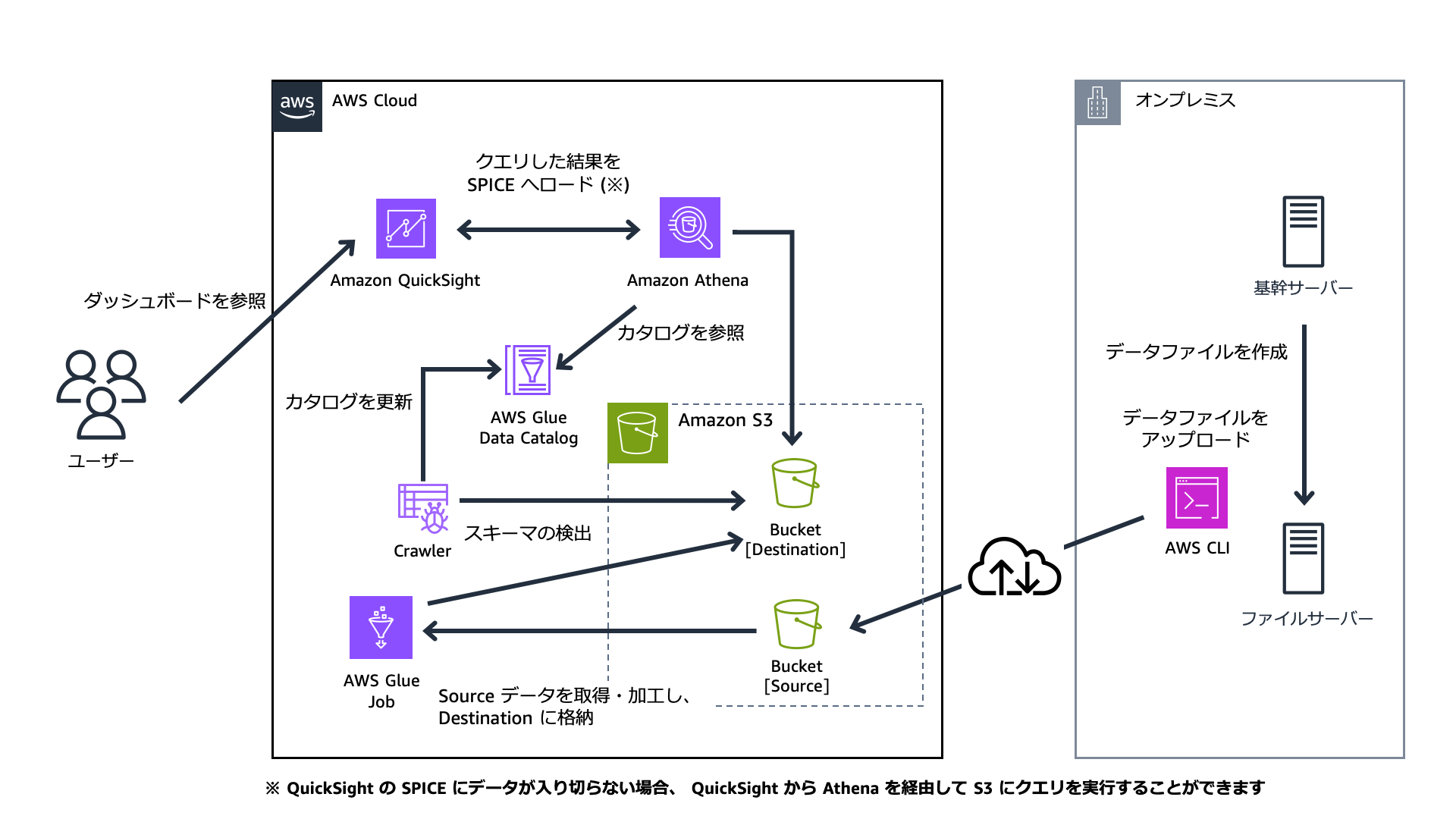
オンプレミスにある EC システムなどに保存されている各種データ (売上・販売データ、顧客からの商品レビュー) を、データレイクのストレージとして活用する Amazon S3 に転送・蓄積し、データレイクに蓄積したデータを活用して、売上推移の可視化や販売チャネルの分析、各商品に対するレビュー分析を実現する構成例とその概算料金をご紹介します
構成概要
この構成例のクラウドレベル:
応用編
入門編:該当するユースケースの知識が全くない方が対象
基礎編:該当するユースケースの入門知識がある方が対象
応用編:該当するユースケースにある程度精通している方が対象
この構成例で解決できる課題・困りごと:
-
クラウドにデータを移行し、管理や分析を効率化したい
-
データを迅速に分析し、可視化することで意思決定を加速させたい
-
データの一元管理とセキュリティを強化し、コンプライアンスを確保したい
この構成例の概算料金:
266.92 ドル (月額)
この構成例のメリット:
-
マネージドの ETLや BI サービスの利用により、運用コストを軽減できます
-
データ分析に標準 SQL が使用できるインフラストラクチャで、分析プロセスの一貫性と効率性が向上します
-
BI サービスのライセンスコストが課題である場合、アクセス頻度に応じた従量課金によってコスト効率を高めます
-
データレイクに対して、直接 SQL を使ってアドホックに分析できます
月額合計料金:266.92 (USD)
この構成例で使用したサービスと概算料金内訳
|
サービス
|
項目
|
数量
|
単価
|
料金 (USD)
|
||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
Amazon S3
|
|
|
|
|
||||||||||||||||
|
AWS Glue
|
|
|
|
|
||||||||||||||||
|
Amazon Athena
|
スキャンされたデータ |
10 GB/日 * 30 日 = 300 GB |
5.00 USD/TB |
1.5 |
||||||||||||||||
|
Amazon QuickSight
|
|
|
|
|
-
東京リージョンでの利用を想定しています。
-
1 ヶ月を 30 日として計算しています。
-
オンプレの各種システムから、毎日 200 ファイル、各々 50 MB のデータファイル が生成されます。
-
データファイルは、 AWS CLI を使って S3 バケット [Source] へアップロードします。
-
実行される Glue Job により、S3 バケット [Source] にアップロードされた 200 ファイル50MB を、 100 ファイル 100 MBに変換し、 S3 バケット [Destination] へ格納します。
-
Glue Job が終了したら、Crawler を実行しテーブルやパーティションなどのメタデータを、AWS Glue Data Catalog に更新します。
-
Athena クエリエンジンが Glue Data Catalog にあるメタデータを参照して、 S3 バケット [Destination] にあるデータの検索、読み取り、および処理を行います。
-
Glue Data Catalog には、 Glue テーブルやデータベースなどのオブジェクトが 200 万個/月作成され、オブジェクトへは 200 万アクセス/月あるものとします。
-
Athena からクエリを実行するたびに、 S3 バケット [Destination] 内の 10 GB 分のファイルを読み取って処理を行います
-
QuickSight はエンタープライズ・エディションを利用します。
-
Athena クエリのデータ処理結果を QuickSight の SPICE に日次で増分更新します。
-
3 名が作成者ユーザー 、 30 名がリーダーユーザーとして、 QuickSight を利用します。
-
SPICE は作成者ごとに、20 GB を消費します。
※ 2024 年 09 月 16 日時点での試算です