Amazon Redshift Integration for Apache Spark
Amazon Redshift との間でデータを読み書きする Apache Spark アプリケーションを構築
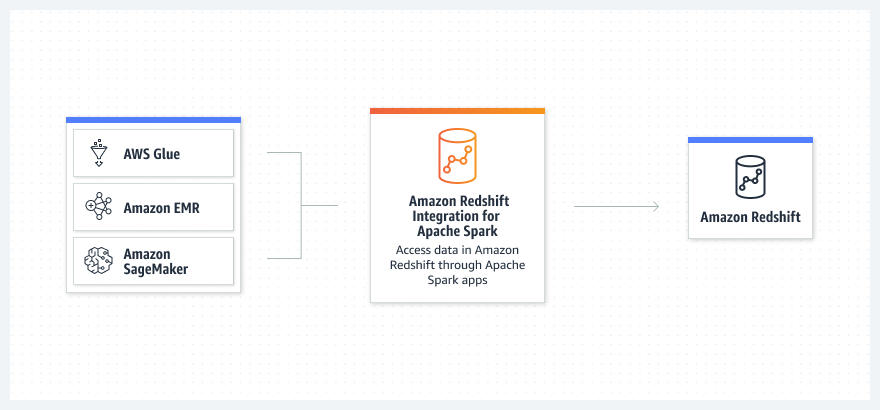
Amazon Redshift Integration for Apache Spark を選ぶ理由
Amazon Redshift Integration for Apache Spark は、Amazon EMR、AWS Glue、Amazon SageMaker などの AWS 分析サービスから Amazon Redshift データにアクセスする Apache Spark アプリケーションを簡素化および高速化します。Amazon EMR、AWS Glue、SageMaker を使用すると、パフォーマンスやトランザクションの一貫性を損なうことなく、Amazon Redshift データウェアハウスとの間で読み書きする Apache Spark アプリケーションを迅速に構築できます。Amazon Redshift Integration for Apache Spark は、セキュリティを強化するために AWS Identity and Access Management (IAM) ベースの認証情報も使用します。Amazon Redshift Integration for Apache Spark では、認定されていないバージョンのサードパーティーコネクタを手動で設定またはメンテナンスする必要はありません。Amazon Redshift のデータを使用して、Apache Spark ジョブを数秒で開始できます。この新しい統合は、Amazon Redshift データを使用して Apache Spark アプリケーションのパフォーマンスを改善します。

Amazon Redshift の利点
-
データウェアハウスとの間でデータを読み書きすることにより、Amazon EMR、AWS Glue、または SageMaker で実行される豊富な分析および機械学習 (ML) アプリケーションで使用できるデータソースの幅を広げます。
-
認定されていないコネクタと JDBC ドライバーを設定するための、多くの場合は手動である面倒なプロセスを合理化し、分析と ML タスクの準備時間を短縮します。
-
関連するデータのみが Amazon Redshift データウェアハウスから移動されるように、並べ替え、集計、制限、結合、スカラー関数などのいくつかのプッシュダウン機能を使用できます。
ユースケース
-
Apache Spark ベースの AWS 分析サービスを使用して、Java、Scala、および Python で Apache Spark アプリケーションを作成します。
-
Amazon EMR、AWS Glue、SageMaker、AWS Analytics および ML サービスを使用して、Amazon Redshift との間でデータを読み書きします。
-
Amazon EMR または AWS Glue を使用して、Apache Spark ジョブまたはノートブックからデータフレームコードを取得し、Amazon Redshift に接続します。
-
強化されたセキュリティ (IAM ベースの認証情報) と運用上のプッシュダウン、および高パフォーマンスのための Parquet ファイル形式により、プロセスを合理化できます。インストールやテストは不要です。
お客様
Huron Consulting、Data Architect Manager、Corey Johnson 氏
Huron は、健全な戦略を作成し、運用を最適化し、デジタルトランスフォーメーションを加速し、企業とその従業員が将来を自分のものにできるようにすることで、可能性を現実のものとするためにクライアントと協力するグローバルプロフェッショナルサービス企業です。
「当社では、エンジニアが Python と Scala を使用して Apache Spark でデータパイプラインとアプリケーションを構築できるようにしています。当社は、運用を簡素化し、より迅速かつ効率的にクライアントにサービスを提供できるようにする、カスタマイズされたソリューションを求めていました。そして当社は、新しい Amazon Redshift Integration for Apache Spark でそのようなソリューションを得ることができました」
GE Aerospace、Sr Principal Data Architect、Alcuin Weidus 氏
GE Aerospace は、商用および軍用航空機用のジェットエンジン、コンポーネント、およびシステムのグローバルプロバイダーです。同社は第一次世界大戦以来、ジェットエンジンの設計、開発、製造を行ってきました。
「GE Aerospace は AWS の分析と Amazon Redshift を使用して、重要なビジネス上の意思決定を促進する重要なビジネスインサイトを実現しています。Amazon S3 からの自動コピーのサポートにより、よりシンプルなデータパイプラインを構築して、Amazon S3 から Amazon Redshift にデータを移動できます。これにより、データ製品チームがデータにアクセスし、エンドユーザーにインサイトを提供する能力が向上します。データを通じて価値を付加することに多くの時間を費やし、統合に費やす時間を減らすことができています」
Goldman Sachs、Chief Data Officer、Neema Raphael 氏
Goldman Sachs Group, Inc. は、企業、金融機関、政府、個人を含む大規模かつ多様な顧客ベースに対して、投資銀行、証券、投資管理、消費者銀行にまたがる幅広い金融サービスを提供する世界有数の金融機関です。
「当社は、Goldman Sachs のすべてのユーザーのために、データに対するセルフサービスアクセスを提供することに重点的に取り組んでいます。当社は、オープンソースのデータ管理およびガバナンスプラットフォームである Legend を通じて、金融サービス業界全体で協力しながら、ユーザーがデータ中心のアプリケーションを開発し、データ駆動型のインサイトを引き出すことができるようにしています。 Amazon Redshift と Apache Spark の統合により、当社のデータプラットフォームチームは、最小限の手動ステップで Amazon Redshift データにアクセスできるようになります。ゼロコード ETL が可能になり、エンジニアが完全かつタイムリーな情報を収集して、ワークフローの完成に集中できる状況をより容易に実現できます。ユーザーが Amazon Redshift の最新データに簡単にアクセスできるようになったため、アプリケーションのパフォーマンスの改善とセキュリティの強化について期待を寄せています」
Amazon Redshift の使用を開始する
今日お探しの情報は見つかりましたか?
ページコンテンツの品質向上のため、皆さまのご意見をお寄せください