AWS 기술 블로그
Strands Agents와 Amazon Bedrock AgentCore를 활용해 포스트잇 워크숍을 파워포인트로 정리하기
디자인 씽킹 워크숍, 브레인스토밍 세션, 이벤트스토밍 워크숍 등에서 포스트잇은 빠질 수 없는 도구입니다. 다양한 전문가와 기관이 포스트잇을 활용하여 참가자들의 아이디어를 빠르게 수집하고 시각화하면서 워크샵을 진행합니다. 하지만 워크샵이 끝나고 나면 진짜 일이 시작됩니다. 수백 개의 포스트잇을 일일이 읽고, 유사한 내용끼리 묶고, 이를 보고서나 프레젠테이션으로 정리하는 작업에 약 2~3일의 시간이 소요됩니다.

<AnyCompany의 SWOT 워크숍 예시>
본 포스팅에서는 포스트잇 워크샵 결과를 파워포인트로 정리하는 구체적인 비즈니스 문제를 정의하고, AI Agent를 활용해 이 작업 시간을 단축하는 방법을 소개합니다. 기술적으로는 Strands Agents를 활용한 빠른 에이전트 개발과 Amazon Bedrock AgentCore Runtime을 통한 프로덕션 배포 과정을 다룹니다.
아래와 같은 고민을 해보신 적이 있으시다면 본 포스팅을 참고해 보세요.
- “포스트잇 사진과 같은 비정형 데이터를 AI로 처리할 수 있을까?”
- “파워포인트 같은 실무 문서도 Agent가 자동으로 만들 수 있나?”
이 포스트에서는 Strands Agents와 Amazon Bedrock AgentCore를 활용해 위 질문들에 대한 실질적인 답을 제시합니다. 이 AI Agent는 포스트잇 워크샵 결과를 자동으로 정리하여 파워포인트 보고자료를 만들고 웹사이트에서 정보를 검색하여 보고자료 개선 방향을 제시합니다.
1. Strands Agents Framework 소개
Strands Agents는 AI Agent 개발을 위한 오픈소스 SDK입니다. AI Agent의 핵심은 모델 선택과 도구 정의를 두 축으로 하여 간단하게 AI Agent를 개발할 수 있습니다.
특징
Strands Agents는 1) 쉬운 사용성 2) 모델 독립성 3) 도구 활용성의 특징을 가집니다. 첫째, Strands Agents의 디폴트 속성을 활용한다면 단 세 줄의 코드로 에이전트를 정의하고 질의할 수 있는 만큼 빠르게 Agent를 만들고 활용해볼 수 있습니다. 둘째, Strands Agents는 다양한 모델을 사용할 수 있습니다. Amazon Bedrock, Google Gemini, OpenAI, Ollama 등 다양한 모델 제공자를 지원합니다. 셋째, Python 의 @tool 데코레이터를 활용해 일반 함수를 에이전트 도구로 정의할 수 있습니다.
from strands import Agent
#디폴트 세팅으로 에이전트 정의
agent = Agent()
#에이전트에 질의
agent("Tell me about agentic AI")Agent Loop
Strands Agents는 내부적으로 Agent Loop 형태로 구현되어 있어 input으로 들어온 유저의 요청을 LLM에 전달합니다. 그 뒤, 모델은 정보 수집이나 작업 수행을 위해 도구 사용 여부를 결정합니다. 만약 모델이 도구 사용을 요청하면 도구를 실행하고 그 결과를 모델에 다시 전달합니다. 이러한 과정을 반복하면서 추론을 이어가고 모델이 충분한 대답이 준비되었다고 판단하면 결과를 반환합니다.
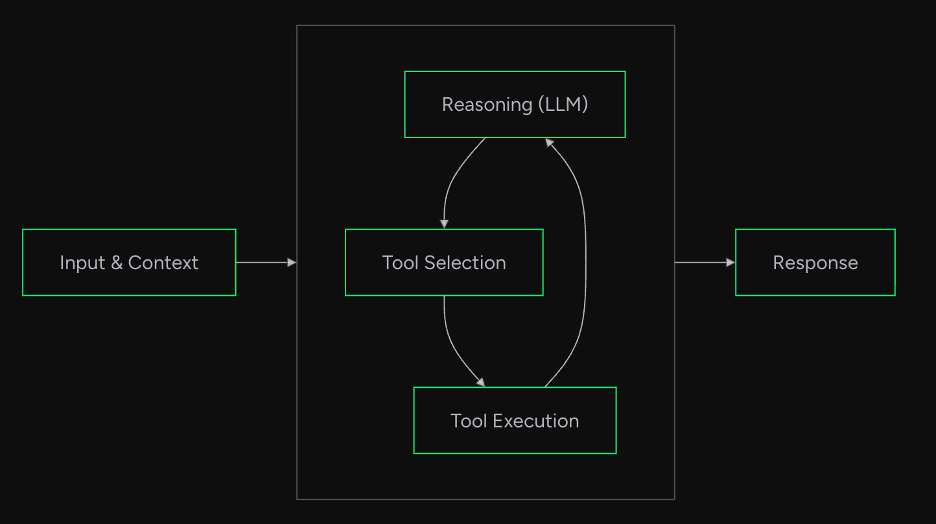
예를 들어, “서울의 인구를 1000으로 나눈 값은?”이라는 질문을 받으면, 첫 번째 루프에서 LLM이 검색 도구 사용을 결정하고 서울 인구를 검색해 결과를 받습니다. 두 번째 루프에서는 검색 결과를 바탕으로 계산기 도구 사용을 결정하고 나눗셈을 수행해 결과를 받습니다. 세 번째 루프에서는 계산 결과를 바탕으로 최종 응답을 생성합니다.
2. AI Agent 디자인
다음 단계는 과업을 어떻게 여러 에이전트로 나누고 통합할 것인지 설계해야 합니다. 복잡한 작업을 한 번에 처리하는 단일 에이전트보다, 각자의 전문 영역을 가진 여러 에이전트가 협력하는 구조가 더 효과적인 경우가 많습니다.
작업 분해와 에이전트 설계
에이전트 설계를 위한 첫 단계는 전체 작업을 어떻게 분할할 것인지 고민하는 것입니다. 포스트잇 사진에서 PPT를 만드는 과정을 단계별로 나누면, 크게 네 가지 작업으로 분리할 수 있습니다. 첫 번째는 이미지에서 포스트잇의 텍스트를 인식하는 작업입니다. 두 번째는 추출된 텍스트를 분석하고 유사한 내용끼리 그룹핑하는 작업입니다. 세 번째는 분석한 내용을 엑셀 보고서로 정리합니다. 마지막은 분석한 내용을 PowerPoint 프레젠테이션 자료로 요약하는 작업입니다.
따라서 이번 프로젝트에서는 4개의 전문화된 에이전트를 설계합니다. 이미지 인식 에이전트는 사진 속 포스트잇의 텍스트를 추출하는 역할을 담당합니다. 내용 분석 에이전트는 추출된 텍스트를 분석하고 유사한 의견을 그룹핑합니다. 엑셀 생성 에이전트는 분석한 내용을 엑셀 문서로 정리합니다. PowerPoint 생성 에이전트는 최종 프레젠테이션 파일을 만듭니다. 각 에이전트는 자신의 전문 영역에만 집중하므로, 각 단계의 품질을 높일 수 있습니다.
멀티 에이전트 아키텍처 선택
과업을 분할하여 전문 에이전트를 설계했다면 다음으로 다중 에이전트를 어떻게 통합할 것인지 결정해야 합니다. 멀티 에이전트 시스템에는 다양한 아키텍처 패턴이 있는데, 대표적으로 Agents-as-Tools, Workflow, Graph, Swarm 패턴이 있습니다. Agents-as-Tools 방식은 하나의 메인 에이전트(Supervisor 혹은 Orchestrator)가 다른 에이전트들을 도구처럼 호출하는 구조입니다. Workflow 방식은 업무의 순서를 사용자가 미리 정하고 각 에이전트가 순차적으로 작업을 수행합니다. Graph 방식은 에이전트 간의 관계를 그래프로 표현하고, 상황에 따라 동적으로 경로를 결정합니다. Swarm 방식은 여러 에이전트가 자율적으로 협력하며 문제를 해결합니다.
Strands Agents는 Graph 객체와 Swarm 객체를 지원하여 사용자가 빠르게 다중 에이전트를 정의할 수 있도록 돕습니다. Graph 객체는 사용자가 미리 결정한 조건에 따라 방향성을 가진 형태로 에이전트가 협업하는 형태입니다. Graph는 노드와 엣지로 구성되어 있으며 각각의 에이전트를 하나의 노드로 지정하고 각 조건에 따라 edge를 설정하여 다중 에이전트의 활동을 조절할 수 있습니다. Swarm은 여러 에이전트가 맥락과 메모리를 공유한 상태에서 토의를 통해 결과를 도출하는 형태입니다. Swarm은 여러 에이전트 간 작업 인계(handoff)를 조절할 수 있으며 다중 에이전트가 팀으로 논의하여 더 효과적으로 문제를 해결합니다.
여러 아키텍처 중 어느 하나가 절대적으로 우월한 것은 아닙니다. 과업의 성격에 따라 더 적합한 아키텍처가 있을 수 있으며, 사용자가 에이전트에게 기대하는 업무의 복잡성에 따라 더 적절한 구조를 선택할 수 있습니다.
우리의 경우를 살펴보면, 문제 상황의 특성이 명확합니다. 고객은 항상 PowerPoint Canvas가 필요합니다. 그리고 그 과정에서 이미지 인식과 내용 분석이 반드시 선행되어야 합니다. 즉, 모든 상황에서 동일한 순서로 작업이 진행됩니다. 이미지 인식 → 내용 분석→ 엑셀 보고서 생성 → PPT Canvas 생성이라는 고정된 흐름이 존재하는 것입니다. 따라서 우리는 이 문제를 Workflow 형태로 디자인하여 아래와 같은 아키텍처로 만들 수 있습니다.
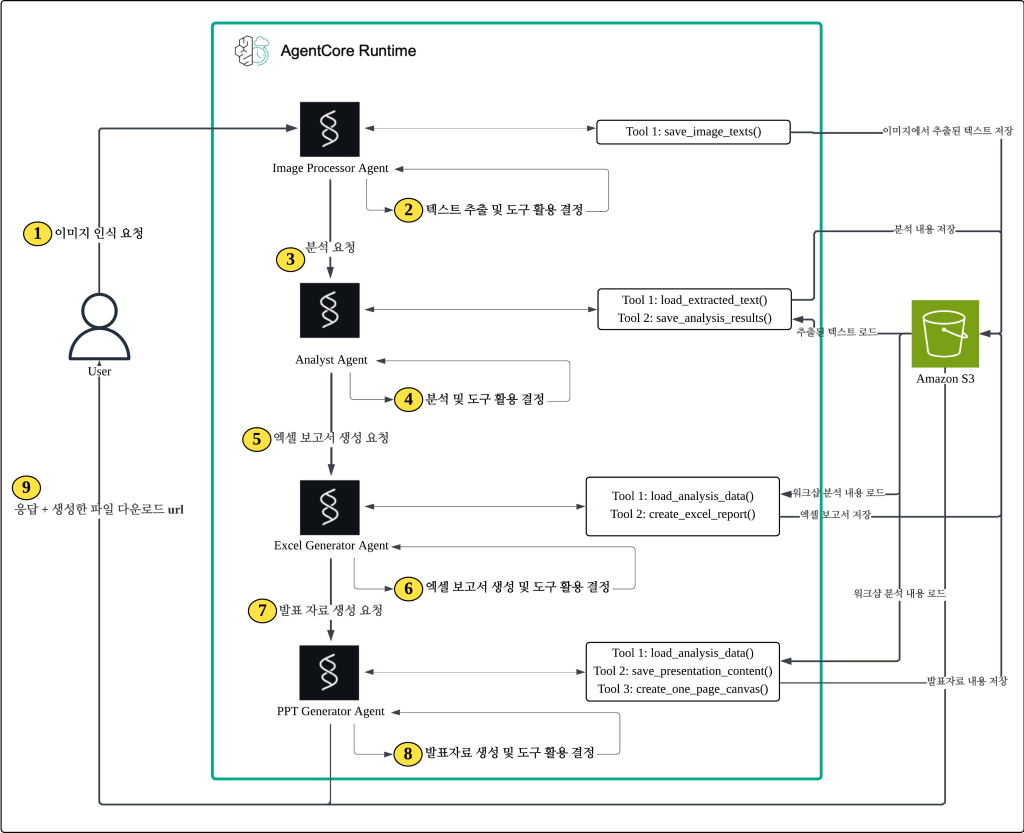
3. AI Agent 빌드하기
Strands Agents는 다양한 모델을 활용해 AI Agent를 만들 수 있습니다. Anthropic의 Claude Sonnet 4, Sonnet 4.5나 Haiku 4.5를 선택할 수도 있고 DeepSeek-R1모델이나 gpt-oss 모델 등 다양한 모델을 Bedrock에서 선택해서 사용해볼 수 있습니다. 이 외에도 Anthropic, GPT 등 자체 API를 활용하는 것도 가능하며 본 포스팅에서는 Claude Sonnet 4으로 에이전트의 모델을 선택해보겠습니다.
Image Processor Agent 빌드하기 (예시)
#strands_workshop_workflow_agent.py
from strands.models import BedrockModel
from botocore.config import Config
from strands import Agent
from workshop_agents_tools import save_image_texts
AVAILABLE_MODELS = {
"claude-4-opus": "us.anthropic.claude-opus-4-20250514-v1:0",
"claude-4-1-opus": "us.anthropic.claude-opus-4-1-20250805-v1:0",
"claude-4-sonnet" : "global.anthropic.claude-sonnet-4-20250514-v1:0",
"deepseek-r1": "us.deepseek.r1-v1:0",
"deepseek-v3": "deepseek.v3-v1:0",
"llama-4-maverick-17b": "us.meta.llama4-maverick-17b-instruct-v1:0",
"llama-4-scout-17b": "us.meta.llama4-scout-17b-instruct-v1:0",
"claude-4-5-sonnet": "global.anthropic.claude-sonnet-4-5-20250929-v1:0",
"claude-4-5-haiku":"global.anthropic.claude-haiku-4-5-20251001-v1:0",
"gpt-oss": "openai.gpt-oss-120b-1:0",
"qwen3-235b": "qwen.qwen3-235b-a22b-2507-v1:0",
"pixtral-124b": "us.mistral.pixtral-large-2502-v1:0",
}
def get_model(model_name: str = "claude-4-sonnet", max_tokens: int = 16384, streaming: bool = True, read_timeout: int = 1000) -> BedrockModel:
model_id = AVAILABLE_MODELS.get(model_name)
#max_token <= 65536
if not model_id:
raise ValueError(f"Unknown model: {model_name}. Available: {list(AVAILABLE_MODELS.keys())}")
return BedrockModel(
model_id=model_id,
max_tokens=max_tokens,
streaming=streaming,
boto_client_config=Config(read_timeout=read_timeout)
)
sonnet_model = get_model("claude-4-sonnet")
IMAGE_PROCESSOR_SYSTEM_PROMPT = """ 당신은 이미지에서 텍스트를 추출해서 저장하는 전문가입니다.
이미지는 주로 한국어로 작성되어 있으며 손글씨로 적혀있기 때문에 이미지에서 읽어낼 때 주의를 기울여야 합니다.
당신은 전문적인 기술로 손글씨를 잘 해석해서 저장해야 합니다.
**작업 순서**:
1. 제공된 모든 이미지를 주의 깊게 분석합니다.
2. 각 이미지에서 한글과 영어 텍스트를 모두 추출합니다.
3. save_image_texts() 도구를 사용하여 결과를 저장합니다.
save_image_texts(session_id=전달받은_실제_session_id , image_texts= [{"image_name": "이미지 파일 이름", "extracted_text": "추출한 텍스트"}, ...]) 도구를 사용하여 추출한 텍스트를 저장합니다.
**중요**: 사용자 메시지에 [SESSION_ID: xxx] 형태로 제공된 session_id를 그대로 사용하십시오.
절대로 임의의 session_id를 생성하지 마십시오.
"""
image_processor = Agent(
model= sonnet_model,
tools=[
save_image_texts
],
system_prompt=IMAGE_PROCESSOR_SYSTEM_PROMPT,
name="image_processor"
)Tool 정의하기
AI Agent를 만들 때 의도한 대로 동작하도록 하려면 도구(Tools)를 정의할 필요가 있습니다. Strands Agents에서 도구는 @tool 데코레이터를 활용하여 정의할 수 있습니다. 이 때, 도구의 주석을 잘 작성하는 것이 중요합니다. 해당 도구의 역할과 목적을 명시하고 Argument값과 Return 예시를 적어주면 에이전트가 이를 읽고 도구가 필요로 하는 Argument를 제시하고 적절한 시기에 사용합니다.
image_processer 에이전트는 이미지에서 추출한 텍스트를 S3에 저장해야 합니다. 이렇게 저장한 내용을 관리하려면 저장 경로와 파일 이름을 Agent에게 자율적으로 맡기기보다 사용자가 직접 관리하는 것이 오류를 줄일 수 있고 Agent 작업에 대한 가시성을 높일 수 있습니다.
#workshop_agents_tools.py
@tool
def save_image_texts(session_id: str, image_texts: list) -> str:
"""
이미지별 추출된 텍스트를 저장
Args:
session_id: 세션 ID
image_texts: [{'image_name': 'file1.jpg', 'extracted_text': 'file1에서 추출된 텍스트'}, {'image_name': 'file2.jpg', 'extracted_text': 'file2에서 추출된 텍스트'}]
Return Example:
{'session_id': 'xxxx', 'saved_path': 's3://bucket/{S3_PREFIX_OUTPUT}/image_processing/xxxx_image_texts_20240401_153000.json'}
"""
try:
extraction_results = {
"session_id": session_id,
"extraction_timestamp": datetime.now().isoformat(),
"image_texts": image_texts
}
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
output_key = f"{S3_PREFIX_OUTPUT}/image_processing/{session_id}_image_texts_{timestamp}.json"
s3_client.put_object(
Bucket=BUCKET_NAME,
Key=output_key,
Body=json.dumps(extraction_results, ensure_ascii=False, indent=2).encode('utf-8'),
ContentType='application/json'
)
return {
"session_id": session_id,
"saved_path": f"s3://{BUCKET_NAME}/{output_key}"
}
except Exception as e:
return f"저장 실패: {str(e)}"ppt_generator 에이전트는 분석한 내용을 바탕으로 프리젠테이션 자료를 만들어야 합니다. 도구를 정의하지 않고 powerpoint를 생성하기는 어려우므로 우리는 적절한 도구를 만들어 에이전트가 이를 활용해 발표 자료를 만들도록 가이드해야 합니다. python-pptx 라이브러리를 활용하여 파워포인트 생성 도구를 다음과 같이 정의할 수 있습니다.
#workshop_agents_tools.py
from pptx import Presentation
from pptx.util import Inches, Pt, Mm, Cm
from pptx.enum.text import PP_ALIGN
from pptx.dml.color import RGBColor
@tool
def create_one_page_canvas(session_id: str):
"""
CBO Canvas PowerPoint 프레젠테이션 생성하는 도구
workflow agent가 사용함
Note:
- presentation content를 정리하여 저장된 데이터를 사용하여 PPT 생성
- data_path가 없으면 session_id로 최신 presentation_content 파일 자동 검색
- 고정된 anchors.json 템플릿과 데이터를 결합하여 완성된 Canvas PPT 생성
Example response:
{
'status': 'success',
'content': [{
'json': {
'session_id': '25751a07',
'Canvas_output_path': 's3://bucket/{S3_PREFIX_OUTPUT}/Canvas/25751a07_Canvas_20240401_153000.pptx'
}
}]
}
Args:
session_id: Session identifier
data_path: S3 path to presentation content JSON file (optional, auto-detected if None)
Returns:
Dictionary containing status and Canvas output path
"""
try:
anchors_path = f"{S3_PREFIX_TEMPLATES}/anchors.json"
presentation_content_prefix = f"{S3_PREFIX_OUTPUT}/presentation_content/{session_id}_presentation_content"
response = s3_client.list_objects_v2(Bucket=BUCKET_NAME, Prefix=presentation_content_prefix)
if 'Contents' in response:
latest_file = max(response['Contents'], key=lambda x: x['LastModified'])
data_path = latest_file['Key']
else:
return "❌ 발표 자료 콘텐츠를 찾을 수 없습니다. save_presentation_content 도구를 먼저 사용하세요."
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
output_path = f"{S3_PREFIX_OUTPUT}/Canvas/{session_id}_Canvas_{timestamp}.pptx"
result_path = build_from_template(anchors_path, data_path, output_path)
result = {"session_id": session_id, "Canvas_output_path" : result_path}
return {
"status": "success",
"content": [ {
"json": result,
} ]
}
except Exception as e:
return f"❌ One Page Canvas 생성 실패: {str(e)}"
def build_from_template(anchors_path: str, data_path: str, out_pptx: str):
"""템플릿을 사용하여 PPT 생성"""
# S3에서 파일 다운로드
local_anchors = download_from_s3(anchors_path)
local_data = download_from_s3(data_path)
if local_anchors is None or local_data is None:
raise ValueError("Failed to download required files from S3")
anchors = json.load(open(local_anchors, "r", encoding="utf-8"))
data = json.load(open(local_data, "r", encoding="utf-8"))
# PowerPoint 템플릿 로드
template_path = anchors.get("background")
if template_path and template_path.endswith('.pptx'):
# S3에서 템플릿 다운로드
local_template = download_from_s3(template_path)
prs = load_template_presentation(local_template)
# 첫 번째 슬라이드 사용 (또는 새로 추가)
if len(prs.slides) > 0:
slide = prs.slides[0]
else:
slide = prs.slides.add_slide(prs.slide_layouts[0])
else:
# 템플릿이 없으면 빈 프레젠테이션 생성
prs = Presentation()
slide = prs.slides.add_slide(prs.slide_layouts[6]) # blank
# 필드 채우기
layouts = anchors.get("layouts", {})
for key, spec in layouts.items():
if spec is None:
continue
val = data.get(key, "")
if spec.get("type") == "image":
if isinstance(val, dict) and val.get("path"):
add_image(slide, spec, val["path"])
else:
add_textbox(slide, spec, val)
# 임시 파일에 저장 후 S3에 업로드
temp_pptx = tempfile.NamedTemporaryFile(suffix='.pptx', delete=False)
prs.save(temp_pptx.name)
# S3에 업로드
s3_result = upload_to_s3(temp_pptx.name, out_pptx)
# 임시 파일 정리
os.unlink(local_anchors)
os.unlink(local_data)
if 'local_template' in locals():
os.unlink(local_template)
os.unlink(temp_pptx.name)
return s3_result
def add_textbox(slide, spec: Dict[str, Any], value: Any):
"""슬라이드에 텍스트박스 추가"""
# cm 단위로 직접 사용
left = Cm(spec["left_cm"])
top = Cm(spec["top_cm"])
width = Cm(spec["width_cm"])
height = Cm(spec["height_cm"])
shape = slide.shapes.add_textbox(left, top, width, height)
tf = shape.text_frame
tf.clear()
# 텍스트박스 크기 고정 설정
tf.word_wrap = True
tf.auto_size = None
# 폰트 설정
font_spec = spec.get("font", {})
size_pt = font_spec.get("size_pt", 12)
bold = font_spec.get("bold", False)
font_name = font_spec.get("name", "Arial")
font_color = font_spec.get("color", "#000000")
line_spacing = font_spec.get("line_spacing", 1.0)
align = {
"left": PP_ALIGN.LEFT,
"center": PP_ALIGN.CENTER,
"right": PP_ALIGN.RIGHT
}.get(font_spec.get("align", "left"), PP_ALIGN.LEFT)
# 색상 변환 함수
def hex_to_rgb(hex_color):
hex_color = hex_color.lstrip('#')
return tuple(int(hex_color[i:i+2], 16) for i in (0, 2, 4))
def _apply(p):
p.font.size = Pt(size_pt)
p.font.bold = bold
p.font.name = font_name
rgb = hex_to_rgb(font_color)
p.font.color.rgb = RGBColor(rgb[0], rgb[1], rgb[2])
p.alignment = align
p.line_spacing = line_spacing
if isinstance(value, list) and spec.get("bullet"):
for i, item in enumerate(value):
p = tf.paragraphs[0] if i == 0 else tf.add_paragraph()
p.text = str(item)
p.level = 0
_apply(p)
p.font.bold = False if i > 0 and bold else p.font.bold
else:
p = tf.paragraphs[0]
p.text = str(value)
_apply(p)S3를 활용한 가장 큰 장점은 데이터의 영속성과 추적 가능성입니다. 에이전트 간 통신에서 발생할 수 있는 데이터 손실을 방지할 뿐만 아니라, 각 처리 단계의 결과물을 개별적으로 확인하고 디버깅할 수 있습니다.
Workflow Multi-Agent 함수 정의하기
마지막으로 멀티에이전트 워크플로우를 구성하는 process_workflow() 함수를 정의합니다. 이 함수는 아키텍처 다이어그램에 따라 네 개의 에이전트를 순차적으로 실행하며, 각 에이전트의 출력이 다음 에이전트의 입력으로 전달됩니다.
Image Processor Agent는 이미지와 텍스트를 함께 처리해야 하므로, Strands의 content block 형식을 사용합니다. Content block 형식에 대한 자세한 내용은 Strands 멀티모달 문서를 참고하세요.
아래 코드는 다음과 같은 디렉토리 구조를 가정합니다:
#strands_workshop_workflow_agent.py
def load_local_images(folder_path: str) -> list:
"""로컬 폴더에서 이미지를 찾아서 ContentBlock으로 변환"""
content_blocks = []
extensions = {'.png': 'png', '.jpg': 'jpeg', '.jpeg': 'jpeg'}
if not os.path.exists(folder_path):
return content_blocks
for file in os.listdir(folder_path):
file_path = os.path.join(folder_path, file)
file_ext = next((ext for ext in extensions if file.lower().endswith(ext)), None)
if file_ext:
try:
with open(file_path, 'rb') as f:
content_blocks.append({
"image": {
"format": extensions[file_ext],
"source": {"bytes": f.read()}
}
})
except Exception:
continue
return content_blocks
def process_workflow(session_id: str, images_folder: str = "workshop_image_files"):
session_info = f"[SESSION_ID: {session_id}]"
content_blocks = load_local_images(images_folder)
if not content_blocks:
return "이미지 파일을 찾을 수 없습니다."
content_blocks.insert(0, {"text": f"{session_info}\n주어진 이미지 파일에 대해서 텍스트를 추출해 주세요:"})
image_response = image_processor(content_blocks)
analysis = analyst(f"{session_info}\n다음의 정보를 참고해서 분석하여 내용 그룹화, 5 Steps 카테고리 분류를 진행해 주세요: {image_response}")
excel_gen = excel_generator(f"{session_info}\n분석 결과를 엑셀 파일로 정리해 주세요: {analysis}")
canvas = ppt_generator(f"{session_info}\n분석 결과를 활용해서 프리젠테이션 자료 Canvas를 만들어주세요: {analysis}")
return canvas
def main():
parser = argparse.ArgumentParser()
parser.add_argument('--session-id', default=f"demo_{datetime.now().strftime('%Y%m%d_%H%M%S')}")
parser.add_argument('--images-folder', default='workshop_image_files')
args = parser.parse_args()
result = process_workflow(args.session_id, args.images_folder)
print(result)
if __name__ == "__main__":
main()S3 버킷과 환경변수 설정하기
포스트잇 워크샵 에이전트를 로컬에서 실행하기 위해서는 AWS S3 버킷과 환경변수 설정이 필요합니다. 먼저 AWS 콘솔에 접속하여 S3 서비스로 이동한 후, 새로운 버킷을 생성합니다. 버킷 이름은 YOUR_BUCKET_NAME 같은 형태로 지정하고, 리전은 us-west-2를 선택합니다. 버킷 생성 시 기본 설정을 그대로 사용하면 되며, 퍼블릭 액세스는 차단된 상태로 진행합니다. 아래는 버킷 내 구조 예시로 anchors.json 은 발표 자료 생성을 위한 기본 양식을 담고 있으며 Workshop_Canvas_Template.pptx는 발표자료 배경화면이 되는 템플릿 파일입니다.
다음으로 프로젝트 루트 디렉토리에 .env 파일을 생성하여 AWS 자격 증명과 버킷 정보를 설정합니다. AWS 콘솔의 IAM 서비스에서 액세스 키를 생성하거나 기존 키를 사용하여 AWS_ACCESS_KEY_ID와 AWS_SECRET_ACCESS_KEY를 입력하며 이 때 IAM 권한은 Bedrock의 관련 권한과 S3 권한을 포함하고 있어야 합니다. 다음으로, 앞서 생성한 버킷 이름을 BUCKET_NAME에 지정합니다. AWS_REGION은 버킷을 생성한 리전과 동일하게 설정하고, S3_PREFIX_OUTPUT은 에이전트가 생성하는 파일들이 저장될 S3 내부 경로를 지정하는 것으로 Outputs/post-it-workshop 같은 형태로 작성하면 됩니다. 이렇게 설정하면 에이전트 코드에서 load_dotenv()를 통해 환경변수를 자동으로 로드하고, boto3 클라이언트가 S3에 접근하여 워크샵 결과물들을 체계적으로 저장할 수 있게 됩니다.
Workflow Multi-Agent 함수 정의하기 섹션에서 작성한 코드를 실행하면 S3에 발표 자료가 생긴 것을 확인할 수 있습니다.


4. Bedrock AgentCore Runtime으로 AI Agent 배포하기
Amazon Bedrock AgentCore Runtime은 로컬에서 개발한 AI 에이전트를 프로덕션 환경에서 실행할 수 있게 해주는 관리형 서비스입니다. 개발자가 작성한 에이전트 코드를 클라우드에서 안정적으로 운영할 수 있도록 합니다. 핵심 역할은 복잡한 인프라 관리 없이도 에이전트를 확장 가능하고 안전한 환경에서 실행하는 것입니다.
Bedrock AgentCore Runtime의 역할과 장점
AgentCore Runtime의 가장 큰 장점은 프레임워크 독립성입니다. Strands Agents, LangGraph, CrewAI 등 어떤 에이전트 프레임워크를 사용하든, 동일한 배포 프로세스를 따를 수 있습니다.
배포 프로세스는 AgentCore Starter Toolkit을 통해 진행할 수 있습니다. 이 도구는 도메인 특화 Infrastructure-as-Code (IaC) 솔루션처럼 작동하며, 복잡한 AWS 인프라 설정을 자동화하여 개발자가 에이전트 로직에 집중할 수 있게 합니다. 도커 컨테이너 빌드, ECR 저장소 관리, IAM 역할 구성, CloudWatch 로깅 설정 등 수많은 인프라 작업이 몇 가지 명령어로 처리됩니다. 결과적으로 개발팀은 인프라 관리에 시간을 쓰는 대신 에이전트의 핵심 기능과 사용자 경험 개선에 집중할 수 있습니다.
아래 코드는 Bedrock AgentCore Runtime으로 Agent를 배포하는 예시 코드입니다. 이를 보면, BedrockAgentCoreApp()을 선언하고 @app.entrypoint 를 통해 해당 에이전트 파일의 시작 지점을 명시할 수 있습니다.
# BedrockAgentCoreApp: AgentCore Runtime과의 통합을 처리하는 핵심 래퍼 클래스
from bedrock_agentcore.runtime import BedrockAgentCoreApp
from strands import Agent
agent = Agent()
app = BedrockAgentCoreApp()
# 엔트리포인트 데코레이터 추가
@app.entrypoint
def invoke(payload):
"""Process user input and return a response"""
user_message = payload.get("prompt", "Hello")
response = agent(user_message)
return str(response)
if __name__ == "__main__":
app.run()workshop agent를 AgentCore Runtime으로 감싸기 위해서는 기존 strands_workshop_workflow_agent.py 의 main() 함수를 지우고 아래의 invoke() 함수를 추가하면 됩니다.
#workshop_workflow_agent.py
@app.entrypoint
def invoke(payload, **kwargs):
"""Process user input and return a response"""
user_input = payload.get("prompt")
session_id = payload.get("session_id")
result = process_workflow(user_input, session_id=session_id)
print(result.metrics.get_summary())
response = {
'response': result.__str__(),
'metrics': result.metrics.get_summary()
}
return json.dumps(response, ensure_ascii=False)
if __name__ == "__main__":
app.run()이렇게 파일을 작성했다면 requirements.txt 파일을 다음과 같이 작성합니다.
마지막으로 작성한 에이전트를 AWS 환경에 배포하기 위한 스크립트를 작성합니다. deploy_workflow.py는 Bedrock AgentCore Runtime을 사용하여 에이전트를 컨테이너화하고 배포하는 과정을 자동화합니다. configure() 메소드에서 엔트리포인트 파일과 실행 역할을 지정합니다. 해당 포스팅에서 agent 코드는 workshop_workflow_agent.py에 작성했으므로 entrypoint를 workshop_workflow_agent.py로 설정합니다. launch() 메소드에서 S3 버킷 정보 등의 환경 변수를 전달합니다. 배포가 완료될 때까지 상태를 주기적으로 확인하며, ‘READY’ 상태가 되면 에이전트를 사용할 수 있습니다.
#deploy_workflow.py
from bedrock_agentcore_starter_toolkit import Runtime
from boto3.session import Session
import time
boto_session = Session()
region = "us-west-2"
agentcore_runtime = Runtime()
agent_name = "workshop_workflow_agent"
response = agentcore_runtime.configure(
entrypoint="workshop_workflow_agent.py",
auto_create_execution_role=True,
auto_create_ecr=True,
requirements_file="requirements.txt",
region=region,
agent_name=agent_name
)
launch_result = agentcore_runtime.launch(
env_vars={
"BUCKET_NAME": "YOUR_BUCKET_NAME",
"S3_PREFIX_USER_UPLOAD": "Files_user_uploaded",
"S3_PREFIX_OUTPUT": "Outputs/post-it-workshop",
"S3_PREFIX_TEMPLATES": "Templates"
}
)
status_response = agentcore_runtime.status()
status = status_response.endpoint['status']
end_status = ['READY', 'CREATE_FAILED', 'DELETE_FAILED', 'UPDATE_FAILED']
while status not in end_status:
time.sleep(10)
status_response = agentcore_runtime.status()
status = status_response.endpoint['status']
print(status)
배포 스크립트를 실행하면 에이전트가 컨테이너 이미지로 빌드되어 Amazon ECR에 저장되고, AgentCore Runtime 환경에서 실행 가능한 상태가 됩니다. auto_create_execution_role=True로 설정했으므로 execution role이 자동으로 생성됩니다. 이 때, 자동으로 생성되는 role은 S3 접근 권한이 없는데 우리의 Workshop Agent는 S3에 파일 작성을 하고 읽어야 하므로 해당 권한을 수동으로 추가해야 합니다. 이 role의 이름은 매번 다른데 배포시 생성되는 role의 이름을 확인할 수 있습니다.

이렇게 S3에 들어가서 아래의 Edit 버튼을 눌러서 정책을 추가합니다. 
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::YOUR_BUCKET_NAME",
"arn:aws:s3:::YOUR_BUCKET_NAME/*"
]
}
]
}
이제 외부 애플리케이션에서 이 엔드포인트를 호출하여 포스트잇 워크샵 자동화 기능을 사용할 수 있습니다. 에이전트를 호출하는 방식을 알아보기 위해서는 콘솔에서 AgentCore Runtime을 검색해서 들어갑니다.

Runtime resources에 생성한 Agent가 보입니다. 이 workshop_workflow_agent를 클릭한 뒤, View invocation code를 클릭합니다.
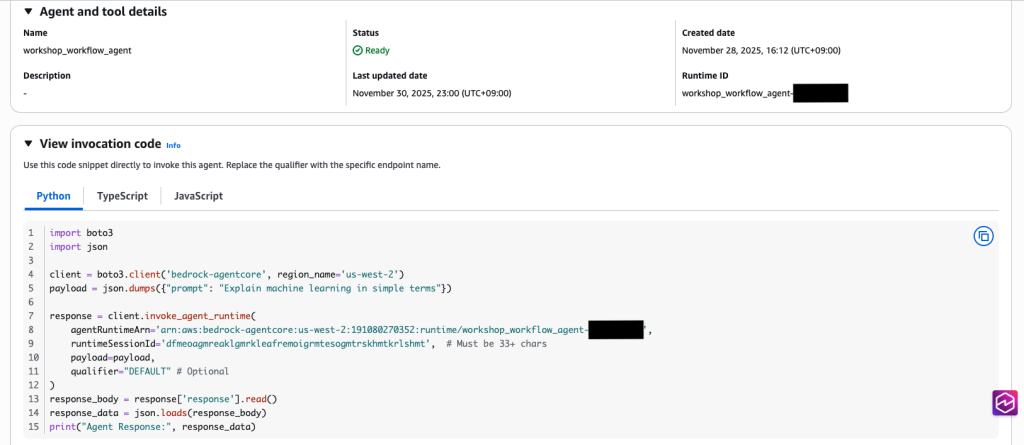
invoke_agent_runtime()을 백엔드 코드에서 호출하면 AgentCore Runtime을 호출할 수 있습니다. 이 때, runtimeSessionId는 세션구별자로 활용되고 33자 이상이어야 합니다.
5. Amazon Transcribe와 Rekognition을 활용한 맥락 보강하기
언어 모델에 맥락 정보를 추가 제공하여 모델이 더 관련성있는 답변을 생성하도록 하는 기법을 맥락 보강(Context Augmentation)이라고 합니다.
AI Agent가 이미지 인식을 진행할 때, 아무런 정보 없이 이미지에서 텍스트를 추출하는 것과, 해당 워크샵의 주제와 논의 내용에 대해 알고 나서 텍스트를 추출하는 것은 정확도에서 큰 차이를 만듭니다.
지금까지 진행한 이미지 인식 에이전트는 모델의 멀티모달 기능을 활용해 진행했습니다. 모델의 손글씨 인식률은 일반적인 OCR보다는 우세하지만 여전히 비즈니스 활용하기에는 어렵습니다. 특히 한국어의 경우, 영어에 비해 모델들의 손글씨 인식률이 낮기 때문에 이러한 어려움이 가중되고 있습니다. 이번 섹션에서는 동일한 모델을 활용하면서도 이미지 인식률을 제고하는 방법에 대해 소개하겠습니다.
Amazon Transcribe 활용하기
Amazon Transcribe는 아마존의 Speech-To-Text(STT) 서비스입니다. 워크샵을 진행하면서 이뤄진 질문과 토의 내용을 Transcribe를 통해 기록하고 이를 에이전트에 맥락으로 주입하면 image process의 이미지 인식률을 유의미하게 향상시킬 수 있습니다. AWS Free Tier를 활용한다면 12개월동안 60분/월 무료로 서비스를 활용할 수 있으므로 부담없이 활용할 수 대안이 됩니다.
AWS 콘솔에 접속하여 Real-time transcription을 사용하면 아무런 코드 설치없이 곧바로 활용해볼 수 있습니다.
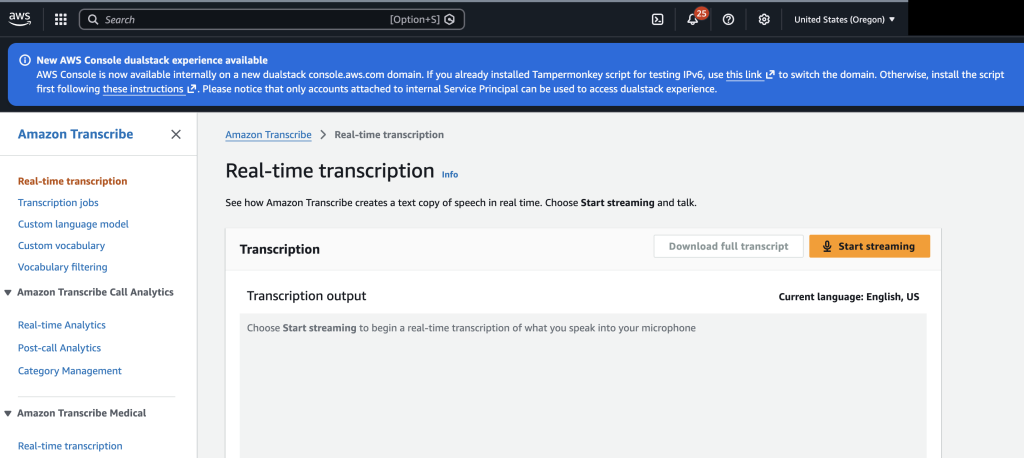
자사 서비스에 통합하고 싶다면 AWS SDK를 활용해 실시간 전사를 진행할 수 있습니다.
Amazon Rekognition 활용하기
Amazon Rekognition은 머신러닝 기반의 시각 정보 처리 시스템입니다. Rekognition을 활용하면 이미지에 담겨있는 여러 개의 포스트잇을 bounding-box를 활용해 영역 인식을 진행할 수 있고, 이를 바탕으로 LLM이 보다 제한된 영역에 대해서 텍스트 추출을 진행할 수 있습니다.
해당 접근 방법을 단계 별로 설명하면 다음과 같습니다. 1) Amazon Rekognition의 detect label을 활용하여 포스트잇을 인식합니다. 2) 인식된 객체의 영역을 bounding box를 기준으로 판별하고 이미지를 자릅니다. 3) 작게 자른 이미지를 Agent에 전달하여 텍스트 추출을 진행합니다.
예시 코드는 다음과 같습니다.
이 방식은 3가지의 장점이 있습니다. 첫째, 모델의 attention이 분산되지 않고 응답 결과가 간단하여 사람의 수정이 덜 필요합니다. 전체 이미지의 여러 영역을 동시에 해석하지 않고 하나의 포스트잇에만 집중하면 배경 노이즈로 인한 혼란 없이 해당 영역의 손글씨만 인식할 수 있습니다. 둘째, 전체 고해상도 이미지를 모델에 전송하는 대신 작은 크롭 이미지만 전송하기 때문에 멀티모달 모델의 토큰 사용량을 줄일 수 있습니다. 셋째, 자른 이미지와 추출한 텍스트를 병렬 배치하여 사용자가 수정하기 유용하도록 만들 수 있습니다.

<Rekognition 영역 인식 후 이미지 분할하여 텍스트 추출 예시>
결론
본 포스팅에서는 Strands Agents와 Bedrock AgentCore를 활용하여 포스트잇 워크샵 데이터를 자동으로 처리하고 발표 자료를 만드는 AI Agent 아키텍처를 구현했습니다.
Strands Agents는 사용자 스스로 필요한 도구를 정의하여 에이전트가 이미지 처리, 데이터 분석, 발표 자료 생성 등에 특화된 전문 에이전트를 구축할 수 있습니다. Bedrock AgentCore는 독립된 인프라 환경을 제공하여 세션 간 완전한 격리를 보장하며, 서버리스 아키텍처로 AI Agent 개발 및 배포 과정에서 인프라 관리 부담을 줄입니다. 이에 더하여, 이번 데모에서는 맥락 보강(context augmentation)을 통해 이미지 인식률을 향상시키는 방안에 대해 소개했습니다. 여기에 Human-in-the-Loop 패턴을 도입하면 사용자 피드백을 반영하여 결과물의 정확도를 높일 수 있습니다.
이러한 기술 조합으로 워크샵 후 수작업 문서화 소요 시간을 약 56% 감소한 PoC 사례가 있었습니다. 이러한 Agentic Workflow를 적용해 효율적인 워크숍 분석과 발표 자료 생성을 시작해 보십시오. 감사합니다.