AWS 기술 블로그
25년차 기자가 만든 AI 뉴스 서비스: 서울경제신문의 Amazon Bedrock 프롬프트 엔지니어링 실전 사례
이 글은 코딩을 모르는 경제신문 기자가 대학생 인턴과 함께 AWS 서버리스 서비스를 활용해 4개의 AI 뉴스 서비스를 구축하고, AI를 활용해 뉴스 동영상 제작을 자동화함으로써 2025년 한 해 동안 6,044만 뷰와 1억원이 넘는 매출을 달성한 이야기입니다.
기자에게는 도메인 지식은 있었지만 기술적으로 구현할 방법이 없었습니다. 하지만 2025년, Amazon Bedrock과 AWS Lambda를 만나 방법을 찾았습니다. 기자가 가진 노하우를 프롬프트에 담고, 프롬프트로 서비스를 만들었더니 이 서비스는 뉴스룸의 효율성을 증대시키고 동영상 플랫폼 채널 수익을 창출했습니다. 레고 블록을 조립하듯이 AWS 서비스를 조립해 인프라를 구축한 후 그 안에 프롬프트를 차곡차곡 실었습니다. 기자는 기술과 인프라를 몰랐지만 AI와 프롬프트만으로 서비스를 만들 수 있었습니다. 1년 동안 300개가 넘는 프롬프트를 작성하고 업데이트해나가면서 기자들이 찾아 쓰는 서비스에 담았습니다. 이 글에선 각 서비스의 프롬프트 설계 원리, 실제 입출력 예시, 그리고 비용 최적화 방법을 공유합니다.
1. 서론
1.1 개발 배경 : 뉴스룸이 직면한 세 가지 과제
첫째, AI 활용의 성숙도 문제입니다. 생성형 AI가 등장했지만 뉴스룸 정착까지는 간극이 있었습니다. 기자들은 경험에 의해 좋은 기사와 나쁜 기사를 구분해왔습니다. 눈은 높지만, 그 수준의 결과물을 AI로부터 끌어내는 프롬프트 작성 능력은 별개의 영역이었습니다. “제목 뽑아줘”라고 요청하는 기자와 “서울경제 스타일로, 2030 투자자 독자층을 타겟으로, 10~15자 내외 임팩트 있는 제목 10개를 추천해줘”라고 요청하는 기자의 결과물은 완전히 달랐습니다.
둘째, 영상 뉴스 수요의 폭발입니다. 텍스트를 읽지 않는 독자가 늘면서 영상 콘텐츠 수요는 급증했습니다. 그러나 방송 뉴스 1건을 제작하려면 PD, 편집자, 성우 등 상당한 인력과 비용이 필요합니다. 매일 400건의 기사를 영상으로 변환하는 것은 기존 인력 구조로는 불가능했습니다.
셋째, 검색 환경의 근본적 변화입니다. 독자들이 Google 대신 ChatGPT에게 뉴스를 묻기 시작했습니다. 검색엔진 최적화(SEO)만으로는 부족했습니다. AI가 답변을 생성할 때 출처로 인용되는 Answer Engine Optimization(AEO) 전략이 필요한 상황입니다. 그런데 AEO가 효과를 내려면 기사 포맷 자체가 바뀌어야 했습니다. AI 크롤러가 수집하기 쉬운 구조화된 영문 콘텐츠가 필요했고, 이것이 AI GLOBE 개발과 AEO 최적화를 위한 프로젝트의 배경이 됐습니다.
1.2 AI LINK: 4대 서비스 생태계
‘AI LINK’는 이 세 가지 과제를 해결하기 위해 구축된 서울경제신문만의 4개 서비스 생태계입니다. 각 서비스는 AWS 서버리스 아키텍처 위에서 독립적으로 운영되며, Amazon Bedrock을 공통 추론 엔진으로 공유합니다.
| 서비스 | 역할 | 핵심 성과 |
| AI NOVA | 기자 업무 지원 통합 도구 | 268명 자발적 채택, 업무 효율성 개선 |
| AI PRISM | 독자 맞춤형 뉴스 큐레이션 | 8개 페르소나, 2,500건+ 발행, 환각 0건 |
| AI WAVE | 텍스트 기사 → 영상 제작 | 6,044만 뷰, 186% 성장, 매출 1억 323만원 |
| AI GLOBE | AI 검색 최적화 영문 뉴스 | 130개국 접속, AI 트래픽 49% |
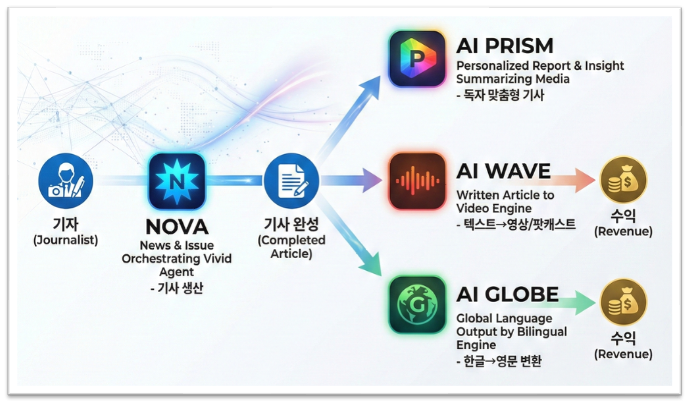
[그림 1. ‘AI LINK’ 4대 서비스 생태계 개요도 – 기사 생산(AI NOVA)에서 맞춤 큐레이션(AI PRISM), 영상 변환(AI WAVE), 글로벌 확장(AI GLOBE)으로 이어지는 콘텐츠 순환 구조]
2. 본론
2.1 시스템 아키텍처
‘AI LINK’의 전체 아키텍처는 AWS 서버리스 서비스를 조합한 이벤트 기반 구조입니다.
| 계층 | AWS 서비스 | 역할 |
| 추론 | Amazon Bedrock (Claude Sonnet) | 프롬프트 기반 텍스트 생성 |
| 컴퓨팅 | AWS Lambda, Step Functions | 이벤트 기반 병렬 처리 |
| 데이터 | Amazon DynamoDB | 프롬프트, 기사 데이터 저장 |
| 인증 | Amazon Cognito | SSO 기반 사용자 인증 |
| CDN | Amazon CloudFront | 글로벌 50ms 이내 배포 |
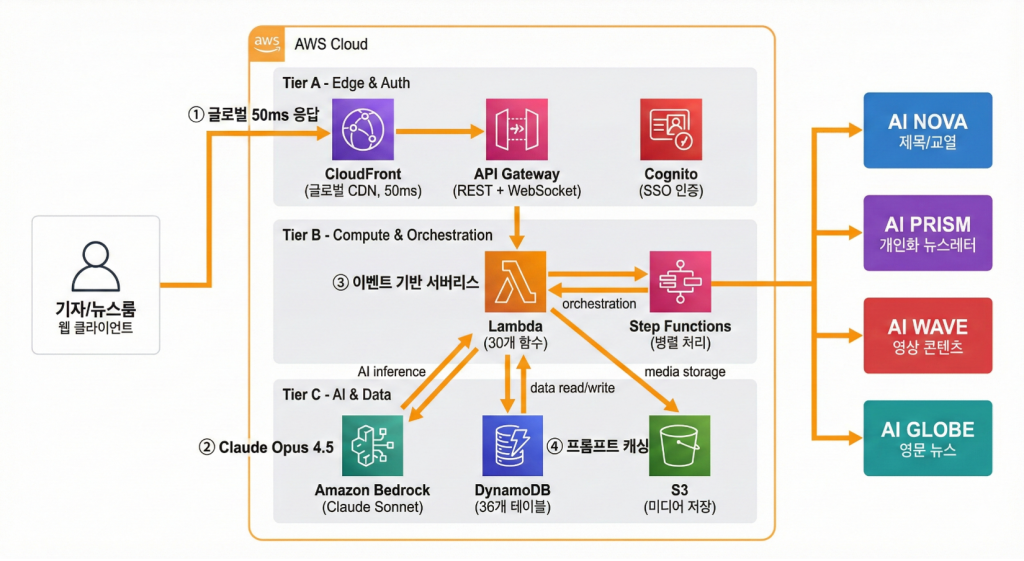
[그림 2. ‘AI LINK’ 시스템 아키텍처 – CloudFront·API Gateway·Cognito(Edge & Auth), Lambda·Step Functions(Compute & Orchestration), Amazon Bedrock·DynamoDB·S3(AI & Data) 3계층 서버리스 구조]
2.2 Claude 모델 선택 이유: 한국어 경제 기사의 뉘앙스 이해력
Amazon Bedrock은 다양한 파운데이션 모델을 단일 API로 제공합니다. 서울경제신문은 여러 모델을 비교 테스트한 결과, 뉴스 콘텐츠 생성에는 Anthropic의 Claude Opus 4.5 모델이 가장 적합하다는 결론을 내렸습니다. 일례로 “AI 기사 제목 추천” 프로젝트에서는 아래와 같은 비교 테스트를 거쳐 적합한 모델을 선택하는 과정을 거쳤습니다.
기사의 제목은 아주 중요합니다. 기자와 독자가 만나는 첫번째 관문이자, 독자들이 기사를 읽을지 말지 결정하는 기준이 됩니다. 그러나 제목은 단순한 팩트의 나열이 아닙니다. 독자의 삶과 맞닿은 공감형 헤드라인, 심금을 울릴 수 있는 제목, 읽고 싶게 만드는 포인트를 찾는 것이 과제였습니다. 운동선수도 축구선수, 야구선수로 나뉘는 것처럼 파운데이션 모델도 장단점이 다릅니다. 가령 동일한 프롬프트에 동일한 기사를 넣어도 제목은 천차만별입니다. 예를 들어, 서로 다른 LLM에 “한국은행 기준금리 0.25%p 인상 발표” 라는 input을 주고, “가장 (Breadwinner)의 삶과 애환을 위로하는 감동적인 20자 내외의 헤드라인을 작성해줘” 라는 프롬프트로 응답을 얻어보았습니다. 이때 모델별 출력 결과는 아래와 같이 다르게 나왔습니다.
| 모델 | 출력 결과 | 언어적 특징 |
| Claude Opus 4.5 | “퇴근길 소주 한 잔, 0.25%의 무게” | 메타포 활용, Show Don’t Tell |
| GPT-4o | “이자 폭탄 경고! 내 지갑 지키는 생존 전략” | 자극적 클리셰, 마케팅형 화법 |
| Amazon Nova | “한은 금리 인상, 가계 부채 부담 가중 우려” | 건조한 보도자료 스타일 |
| Gemini | “오늘 아빠의 어깨가 무겁다… 이자의 역습” | 감성적이나 유튜브적 표현 혼재 |
사실, 기사 제목에 정답은 없습니다. 기자들 개개인의 특성과 선호도가 중요하지만, 기자들이 판단할 수 있는 아이디어를 주는 건 아주 중요합니다. Claude 모델의 경우, 금리라는 숫자를 ‘소주 한 잔’이라는 일상의 장면과 ‘무게’라는 심리적 압박으로 치환했습니다. “슬프다”, “힘들다” 같은 직접적 형용사 없이 상황 묘사만으로 감정을 환기하는 ‘Show, Don’t Tell’ 기법이 구현됐습니다. 기자들이 이 제목을 그대로 쓰지는 않지만, 한 번 고려해 볼 수 있는 아이디어로는 충분합니다. 반면 GPT 모델은 ‘폭탄’, ‘경고’, ‘전략’ 등 자극적 클리셰에 의존했고, Amazon Nova 모델은 감성적 표현을 요청하는 프롬프트에도 건조한 보도자료 스타일로 응답했습니다. 이러한 테스트를 여러 번 거친 결과, 서울경제신문이 각 LLM을 평가한 결과를 요약하면 아래와 같습니다.
| 평가 항목 | Claude | GPT | Nova | Gemini |
| 한국어 감수성 | ◎ | △ | △ | ○ |
| 문학적 메타포 | ◎ | △ | × | ○ |
| 독자 공감도 | ◎ | △ | × | ○ |
| 톤의 품격 | ◎ | △ | ○ | △ |
뉴스 제목은 기사와 독자를 연결해 주는 다리입니다. 특히 경제 관련 뉴스는 딱딱하고 건조하고 어렵습니다. 경제 용어가 단순히 어떤 뜻인지 설명하는 것을 넘어서 한국 사회의 정서적 맥락까지 담아내야 합니다. 서울경제신문의 이러한 기준을 가장 잘 충족하는 LLM은 Anthropic의 Claude 모델이었습니다. Anthropic의 모델 선택 가이드에 따르면, Claude Opus 4.5는 “미묘한 창작 글쓰기 (nuanced creative writing)”에 특화되어 있어 저널리즘 콘텐츠 생성에 적합합니다.
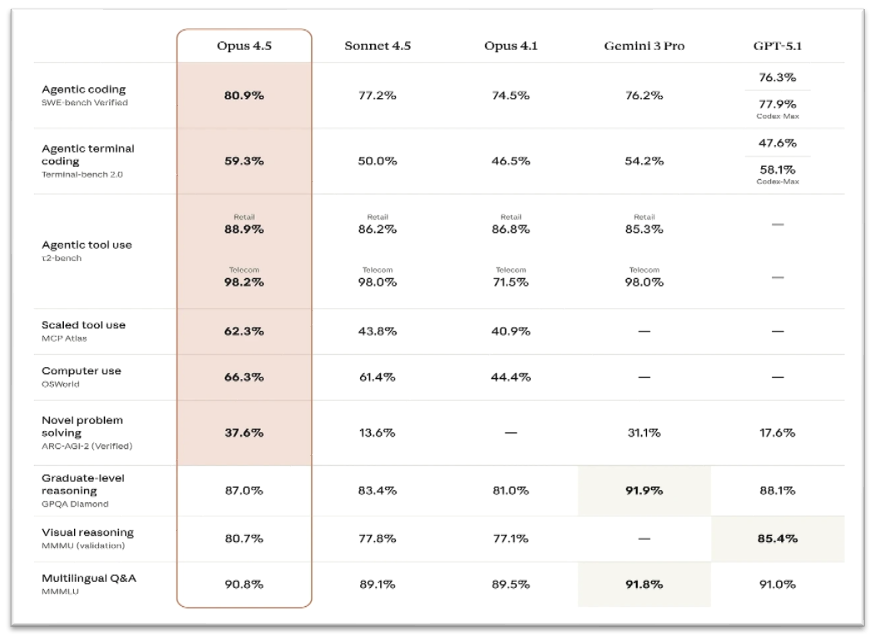
[그림 3. Opus 4.5 모델의 성능 벤치마크]
2.3 구현 상세: 프롬프트 엔지니어링으로 서비스 만들기
서울경제신문 ‘AI LINK’의 핵심은 프롬프트입니다. 같은 LLM을 써도 프롬프트에 따라 결과물 품질이 완전히 달라집니다. 같은 레이싱카라도 누가 운전하느냐에 따라 완전히 다른 것처럼, AI는 같아도 프롬프트가 다르면 결과도 다릅니다.
2.3.1 AI NOVA: 기자 268명의 AI 도구를 프롬프트로 표준화
LLM의 성능이 좋다고 해도 어느 기자가 쓰느냐에 따라 결과값은 천차만별입니다. 이에 대한 해법은, 25년 경력의 경제 전문 기자의 도메인 지식을 프롬프트에 담고, 이를 프로젝트에 담아 공유하여 모든 기자가 쓸 수 있도록 하는 것이었습니다. 기자들에겐 복잡한 설명 없이 “기사만 붙여 넣고 엔터만 치면 된다”고 말할 수 있도록 쉽게 설계해야 합니다 원하는 품질의 결과값이 나오도록 프롬프트를 고도화하는 과정이 필요했습니다.
자판기에는 이미 프로그램이 내장되어 있습니다. 원하는 버튼만 누르면 결과물이 나옵니다. 기자들에게도 원하는 프로젝트에 기사를 넣고 엔터만 누르면 결과값이 나오도록 프로젝트를 만들었습니다. “서울경제 스타일 가이드 준수”, “2030 투자자 독자층 타겟”, “35~45자 내외” 같은 조건들을 최적화해서 프롬프트에 내장했습니다.
아래는 AI NOVA의 시스템 아키텍처입니다. Amazon CloudFront, Amazon S3, AWS Cognito로 구성된 프론트엔드 웹페이지에서 Lambda 함수를 거쳐 Amazon Bedrock의 Claude 4.5 Opus 모델로 연결되는 WebSocket 기반 실시간 처리 구조를 채택했습니다.
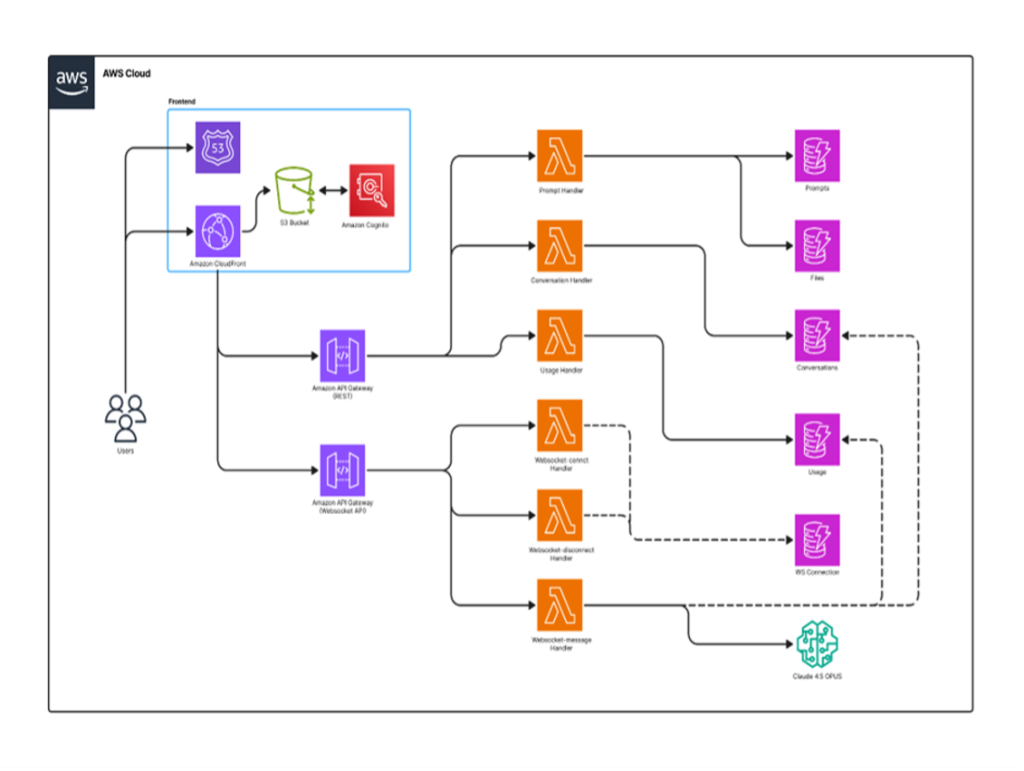
[그림 4. AI NOVA 시스템 아키텍처]
“기사 제목 추천” 프로젝트의 프롬프트 구조
가장 먼저 기자들의 기사 제목 추천을 돕는 시스템을 만들기 위해, 5개의 레이어를 거쳐 5가지 유형의 제목을 추천해주는 프롬프트 시스템을 구축했습니다. 단순히 “제목을 만들어줘”가 아니라, 4명의 가상 전문가 협업해서 최적의 제목을 추천하도록 구조를 설계했습니다.
| 레이어 | 역할 | 토큰 수 |
| 기본 Instructions | 시스템 정체성, 워크플로우 정의 | ~3,000 |
| Knowledge base 1: 유형 정의 | 7가지 창의성 레벨 분류 | ~8,000 |
| Knowledge base 2: UX 규칙 | 글자수, 스타일 가이드 | ~6,000 |
| Knowledge base 3: 진화형 데이터 | 성공 사례, A/B 테스트 결과 | ~13,000 |
| Knowledge base 4: 창의성 프레임워크 | 신조어 생성 공식, 메타포 기법 | ~8,000 |
프롬프트 구조 (핵심 발췌)
{
"role": {
"system_name": "TITLE-NOMICS 3.0",
"team_structure": {
"leader": "김경제 - 전략 의사결정, 최적 유형 선정",
"members": [
"정경제 - 경제 분석 (맥락 정확성, 인과관계 검증)",
"박한글 - 언어/표현 (일상 언어 변환, 35-45자 관리)",
"이크리에이터 - 창의적 앵글 (역발상, 신조어 개발)",
"최소셜 - 감성 디자인 (심리 분석, 바이럴 확산)"
]
}
},
"task": {
"output": "5가지 유형 × 각 1개 + 최적 유형 추가 2개 = 총 7개"
},
"constraints": {
"accuracy": [
"제목의 모든 수치는 기사 본문과 100% 일치",
"상관관계를 인과관계로 오인하는 표현 금지"
],
"format": "모든 제목 35-45자 모바일 최적화"
}
}환각 방지 3중 구조
환각 방지를 위해 세 가지 안전장치를 구축했습니다:
- 입력 제한: 데스크 승인을 거친 지면 기사만 입력으로 사용합니다.
- 프롬프트 제약: 외부 지식 참조를 차단하고, 주어진 텍스트 내에서만 정보를 재구성하도록 명시합니다.
- 에디터 검수: 최종 발행 전 인간 에디터가 이중으로 검수합니다 (Human-in-the-loop).
Input/Output 예시
Input (기사 원문):
농심이 유튜버 케데헌(Keith Habersberger)과 협업해 출시한 '신라면 케데헌 에디션'이 출시 1분 40초 만에 전량 매진됐다. 농심 주가는 전 거래일 대비 19% 급등하며 52주 신고가를 경신했다.
Output (7개 제목 생성):
| 유형 | 제목 | 적용 기법 |
| 레벨 1 (신뢰형) | 농심 19% 급등…케데헌 협업 신라면 1분40초 완판 효과 | 숫자 앵커, 팩트 나열 |
| 레벨 3 (임팩트형) | 1분 40초의 기적…농심 주가 ‘케데헌 효과’로 신고가 | 시간 강조, 기적 메타포 |
| 레벨 5 (바이럴형) | ‘면비디아’ 전쟁 불붙었다…농심 케데헌 라면 1분40초 완판 | 신조어 창조, 전쟁 메타포 |
7단계 창의성 레벨 시스템
| 레벨 | 유형명 | 창의성 | 타겟 독자층 | 적합 플랫폼 |
| 1 | 신뢰 기반 통찰형 | 30% | 정책 결정자, 기관투자자 | 레거시 미디어 |
| 2 | 지적 호기심 자극형 | 55% | 경제 관심층, 직장인 | 종합일간지 |
| 3 | 심리적 임팩트형 | 75% | 모바일 이용자, 20-40대 | 포털 메인 |
| 4 | 데이터 스토리텔링형 | 60% | 분석 선호 독자 | 전문 미디어 |
| 5 | 바이럴 폭발형 | 85% | MZ세대, SNS 활용층 | SNS/숏폼 |
| 6 | 언어 혁신형 | 90% | 언어 트렌드 세터 | 화제성 콘텐츠 |
| 7 | 미래 통찰형 | 95% | 리더층, 의사결정자 | 전략 콘텐츠 |
이와 같이 기자들이 사용하는 모든 AI 프로젝트는, “AI가 제안하고 기자가 최종 결정하는” Human-in-the-loop 구조를 적용함으로써 안전성과 창의성을 동시에 구현할 수 있었습니다. 그리고 이 프로젝트의 성과는 명확했습니다. 연간 서울경제신문에서 발행하는 2,500건의 기사 중 환각/오보는 0건을 기록했습니다.
2.3.2 AI PRISM: 8개 페르소나로 개인화 뉴스레터 만들기
AI PRISM은 독자 맞춤형 뉴스 큐레이션 서비스입니다. 해당 시스템은 독자별 특성에 맞는 기사 컨텐츠를 선별한 후 특정 시간에 개인화 뉴스를 보내주는 시스템입니다. 이러한 요구사항을 충족하기 위해 아래의 아키텍처와 같이 Amazon EventBridge 스케줄러가 AWS Step Functions 워크플로우를 호출하도록 구성하고, Step Functions 워크플로우 내에서는 ‘지면 추출’ → ‘기사 선별’ (Claude 4.1 Sonnet) → ‘검증’ (Claude 4.5 Opus) → ‘콘텐츠 스크립트 생성’ (Claude 4.5 Opus)의 4단계를 순차적으로 실행하도록 구성했습니다.
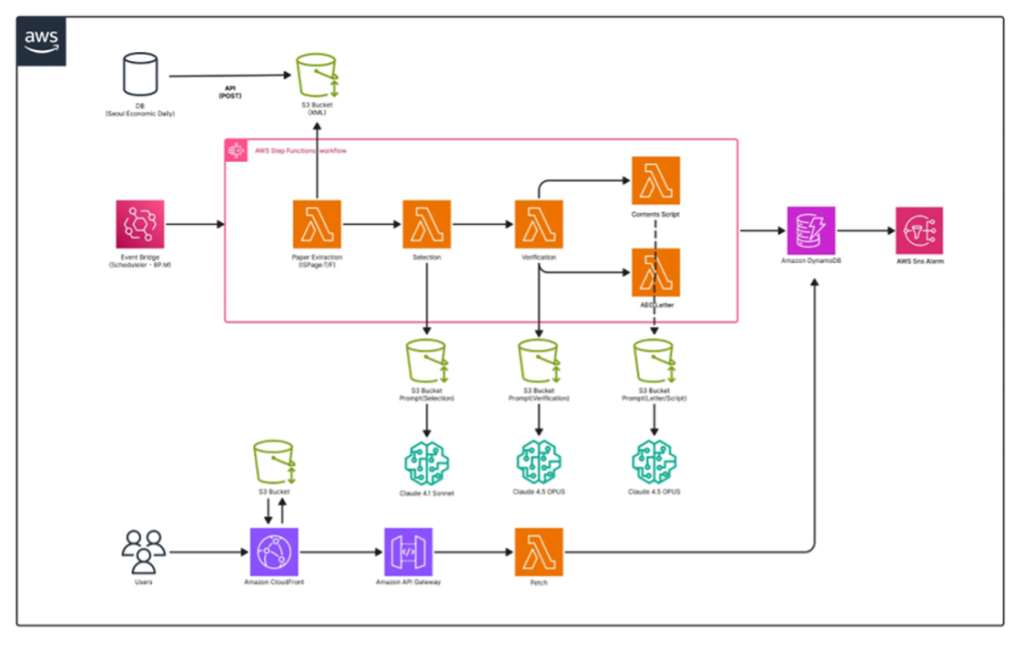
[그림 5. AI PRISM 시스템 아키텍처]
| 코드 | 페르소나명 | 핵심 질문 | 주요 관심사 |
| 1 | Campus LOG | “취업에 도움?” | 채용 기회, 역량 개발, 산업 트렌드 |
| 2 | Career LOG | “승진에 영향?” | 업무 성과, 조직 동향, 커리어 성장 |
| 3 | Real Estate LOG | “집값에 영향?” | 부동산 정책, 금리, 지역별 시세 |
| 4 | Value LOG | “재테크에 활용?” | 저축, 투자상품, 절세 전략 |
| 5 | CEO LOG | “전략 수정 필요?” | 산업 혁신, 경쟁 환경, 규제 변화 |
| 6 | Newbiz LOG | “내 삶에 영향?” | 소비 트렌드, 라이프스타일, 문화 |
| 7 | Global LOG | “한국 영향은?” | 국제 정세, 환율, 무역 동향 |
| 8 | Trading LOG | “포트폴리오 영향?” | 기업 실적, 시장 동향, 종목 분석 |
이 중 ‘Stock Investor_Trading LOG’ 페르소나를 예시로 든다면, 아래와 같은 가중치 구조를 가질 수 있습니다.
concerns:
- name: 기업 실적 및 밸류에이션
importance: 10
keywords: [실적, 재무제표, EPS, PER, PBR]
- name: 시장 동향 및 주가 변동
importance: 9
keywords: [주가, 지수, 변동성, 거래량]
- name: 매크로 경제 지표
importance: 8
keywords: [금리, 환율, GDP, 인플레이션]
- name: 기업 지배구조 및 전략
importance: 7
keywords: [M&A, 배당, 자사주, 지배구조]이러한 페르소나 시스템 외에도 평가 지표 시스템을 활용하여 각 독자별로 개인화 뉴스를 선별했습니다. 기사 선별 시 종합 점수 = (주요 지표 × 0.6 + 부가 지표 × 0.2 + 조합 지표 × 0.2) ÷ 가중치 총합 이라는 자체 공식을 통해 종합 점수에 따라 기사를 선별하도록 했습니다.
| 점수 범위 | 해석 | 선별 우선순위 |
| 9.0 – 10.0 | 핵심 관심사 직접 해당 | 최우선 선별 |
| 8.0 – 8.9 | 주요 관심사 관련 | 우선 선별 |
| 7.0 – 7.9 | 간접적 관련성 | 조건부 선별 |
| 7.0 미만 | 관련성 낮음 | 제외 |
Selection Engine 프롬프트 구조
{
"role": "주식 투자자를 위한 금융 뉴스 큐레이터",
"task": "40~80개 기사에서 투자 의사결정에 활용 가능한 6개 선별",
"selection_criteria": [
{"name": "투자 의사결정 유용성", "weight": 10},
{"name": "데이터/분석 품질", "weight": 9},
{"name": "시장 영향도", "weight": 8}
],
"constraints": [
"환각 방지: 원문에 없는 수치/전망 추가 금지",
"투자 권유 금지: 판단 재료 제공만"
]
}
Input/Output 예시: 동일 기사의 페르소나별 해석
Input: 한국은행이 기준금리를 0.25%p 인상하여 3.50%로 결정
Output:
| 페르소나 | 해석 |
| NewBiz LOG
(신입 직장인) |
“기준금리란 한국은행이 정하는 기준 금리로, 시중 금리에 영향을 미칩니다. 이번 인상으로 대출 이자가 높아질 수 있어 취업 후 목돈 마련 전략 점검이 필요합니다.” |
| Stock LOG
(주식 투자자) |
“금리 인상은 성장주에 부정적입니다. 금융주(KB금융, 신한지주)는 예대마진 확대로 수혜가 예상됩니다. 단, 건설·부동산 섹터는 조정 압력이 커질 수 있습니다.” |
| CEO LOG
(경영진) |
“자금 조달 비용 상승으로 신규 투자 의사결정 시 IRR 재검토가 필요합니다. 해외 차입 비중이 높은 경우 환헤지 전략도 점검하시기 바랍니다.” |
2.3.3 AI WAVE: 포맷 코드 시스템으로 영상 대본 자동화하기
영상 뉴스는 타겟 독자와 목적에 따라 완전히 다른 구조가 필요합니다. 주식 투자자용 3분 영상과 종합 시사 5분 영상은 스크립트 구성이 다릅니다. 서울경제신문은 ‘AI WAVE‘라는 포맷 코드 시스템을 개발하여 영상 유형을 코드로 분류하고, 각 코드 별 프롬프트의 역할, 톤, 구조를 전환하는 과정을 자동화했습니다.
| 코드 | 포맷명 | 타겟 | 길이 | 구조 |
| 10 | 주식 투자자용 | 바쁜 투자자 | 3-5분 | 팩트 선언 → 주가 영향 → 시사점 |
| 20 | 부동산 투자자용 | 부동산 관심층 | 3-5분 | 정책 파급 → 집값 분석 → 매수/매도 |
| 31 | 1면 언박싱 | 종합 시사 관심층 | 5-8분 | 도입 → 배경 → 데이터 → 비교 → 시사점 |
| 32 | 금융면 언박싱 | 재테크 관심층 | 4-6분 | 금리/환율 동향 → 상품 추천 → 주의사항 |
TTS 최적화 규칙
Google Gemini TTS를 사용하면서 한국어 경제 용어가 잘못 발음되는 문제를 해결하기 위해 30개 이상의 교정 규칙을 적용합니다.
숫자 변환 규칙:
| 원문 | TTS 오류 | 교정 후 |
| 1천 | “일천” | 천 |
| 15만 | “일오만” | 십오만 |
| 61% | “육일퍼센트” | 육십일퍼센트 |
| 3.50% | “삼점오퍼센트” (부정확) | 삼점오퍼센트 |
영문 약어 변환 규칙:
| 원문 | TTS 오류 | 교정 후 |
| SK | “스크” | 에스케이 |
| AI | “아이” | 에이아이 |
| HBM | (불명확) | 에이치비엠 |
| M&A | “엠앤드에이” | 엠앤에이 |
호흡 마커 시스템:
| 마커 | 의미 | pause 시간 |
| 쉼표(,) | 짧은 호흡 | 약 0.3초 |
| 마침표(.) | 문장 종결 | 약 0.5초 |
| 말줄임(…) | 긴 pause | 약 0.8초 |
| 줄바꿈 | 화제 전환 | 약 1초+ |
보이스 페르소나 8종
| 보이스명 | 성별 | 특징 | 추천 장르 |
| Aoede | 여 | 산뜻하고 안정감 | 일반 경제뉴스, 정책 |
| Fenrir | 남 | 역동적이고 힘 | 시장 급등락, 속보 |
| Leda | 여 | 젊고 에너지 넘침 | IT/테크, 스타트업 |
| Kore | 여 | 단단하고 신뢰감 | 국제 정세, 심층 분석 |
| Puck | 남 | 밝고 친근함 | 생활경제, 재테크 |
| Charon | 남 | 깊고 무게감 | 금융위기, 심각한 이슈 |
| Zephyr | 남 | 차분하고 지적 | 산업분석, 기업탐방 |
| Orbit | 여 | 활기차고 모던 | 트렌드, MZ 타겟 |
서울경제신문이 추천하는 조합:
- 일반 경제뉴스: Aoede(여) + Fenrir(남)
- IT/테크 뉴스: Leda(여) + Puck(남)
- 금융/투자 뉴스: Kore(여) + Charon(남)
Input/Output 예시
Input (기사 원문):
삼성전자가 엔비디아 HBM3E 품질 테스트를 통과했다. 내년 1분기부터 양산에 돌입한다.
Output (TTS 대본):
Speaker 1 (Aoede): 삼성전자가, 드디어 엔비디아 에이치비엠 승인받았습니다.
Speaker 2 (Fenrir): 잠깐요, 드디어라고요? 얼마나 걸렸어요?
Speaker 1: 일 년 넘게 테스트했어요. 에이치비엠쓰리이가 품질 테스트 통과했대요.
Speaker 2: 와, 내년 일분기부터 양산이면... 삼성 반도체 실적 기대해볼 만하겠네요.
Speaker 1: 네, 에스케이하이닉스 독주에 삼성이 다시 도전장을 내민 거죠.2.3.4 AI GLOBE: 맥락화 번역으로 글로벌 독자 확보하기
AI GLOBE는 ‘맥락화(Contextualization)‘에 집중합니다. 단순 기계 번역은 ‘전세’를 ‘jeonse’로만 번역하지만, 국제 독자는 이것이 무엇인지 알 수 없습니다. AI GLOBE는 아래와 같은 번역 프롬프트를 통해 맥락화를 구현했습니다.
[AI GLOBE 맥락화 번역 프롬프트 구조]
{
"role": "Korean financial news translator + contextual editor",
"model": "Claude Sonnet (Amazon Bedrock)",
"core_principles": [
{
"id": 1,
"priority": "highest",
"name": "Source Fidelity",
"rules": [
"Preserve facts, nuance, and context from the original",
"Never add information not in source"
]
},
{
"id": 2,
"name": "Style Target",
"reference": "WSJ, Financial Times, Reuters, Bloomberg"
}
],
"contextualization_rules": {
"korean_concepts": {
"trigger": "First mention of Korea-specific term",
"format": "term (English explanation in parentheses)",
"constraint": "Single appositive phrase only"
},
"currency_conversion": {
"threshold": "500 billion KRW or higher",
"format": "X trillion won ($Y billion)"
}
},
"strictly_prohibited": [
"Adding information not in source",
"Modifying numerical values",
"Paraphrasing direct quotes"
]
}
맥락화 규칙 20개 (주요 발췌)
| # | 카테고리 | 원문 | 맥락화 출력 |
| 1 | 한국 고유 개념 | 전세 | jeonse (a Korean lease system requiring a large lump-sum deposit) |
| 2 | 한국 고유 개념 | 재벌 | chaebol (a large family-controlled conglomerate) |
| 3 | 한국 고유 개념 | 김치 프리미엄 | Kimchi Premium (the gap in crypto prices between Korean and foreign exchanges) |
| 4 | 기업명 + 설명 | 삼성전자 | Samsung Electronics (005930.KS), the world’s largest memory chipmaker |
| 5 | 기업명 + 설명 | 현대차 | Hyundai Motor (005380.KS), South Korea’s largest automaker |
| 7 | 통화 변환 | 6조5000억원 | 6.5 trillion won ($4.8 billion) |
| 10 | 정부 기관 | 금융위원회 | Financial Services Commission (FSC), South Korea’s top financial regulator |
Self-Validation Checklist (14개 항목 중 주요 발췌)
Fact Accuracy:
- 모든 수치가 원문과 정확히 일치하는가?
- 인용문이 원문 의미를 정확히 전달하는가?
- 원문에 없는 정보가 추가되지 않았는가?
Notation Accuracy:
- 기업명, 인명, 기관명이 KB 기준에 맞는가?
- 큰 금액에 달러 환산이 병기되었는가?
Structure:
- 헤드라인이 10단어 이내이며 핵심 동사를 포함하는가?
- 리드가 5W1H 핵심을 담고 있는가?
Input/Output 예시
Input (한국어 기사):
삼성전자가 4분기 영업이익 6조5000억원을 기록했다고 8일 공시했다. 전년 동기 대비 78% 증가한 수치다. 한편 전세 시장 침체로 건설 부문은 부진했다.
Output (맥락화 영문 기사):
Samsung Electronics (005930.KS), the world's largest memory chipmaker, reported fourth-quarter operating profit of 6.5 trillion won ($4.8 billion), up 78% from a year earlier. Meanwhile, the construction division underperformed due to a slump in the jeonse (Korea's lump-sum deposit lease system) market.
AEO(Answer Engine Optimization) 구현
AI 검색 엔진이 우리 콘텐츠를 답변의 출처로 인용하도록 4가지 요소를 구현했습니다:
- llms.txt: AI 크롤러를 위한 사이트 정보 구조화 파일
- Q&A 섹션 자동 생성: “삼성전자 4분기 영업이익은 얼마인가?” 형태의 FAQ
- Schema Markup: NewsArticle 스키마 적용
- SEO URL: en.sedaily.com/finance/2026/02/04/samsung-q4-profit 형태
Disclaimer 정책
AI 번역의 투명성을 위해 모든 기사에 면책 조항을 명시하고, 역번역(영어를 한국어로 번역한 후 다시 영어로 번역)의 오류 문제에 대해서도 명확히 밝혔습니다.
2.4 비개발자가 이 시스템을 구축할 수 있었던 이유
AI LINK를 만든 팀은 기자 2명과 대학생 인턴 4명입니다. 전문 개발자는 한 명도 없습니다. 이 팀이 1년 만에 4개 서비스를 프로덕션 환경에 배포할 수 있었던 이유를 정리합니다.
서버리스 아키텍처가 인프라 관리를 제거
AWS Lambda, DynamoDB, API Gateway 조합은 서버 프로비저닝, 스케일링, 패치 관리를 완전히 추상화합니다. 팀은 “어떻게 운영할 것인가” 대신 “무엇을 만들 것인가”에 집중할 수 있었습니다.
Amazon Bedrock이 AI 모델 운영의 복잡성을 추상화
모델 호스팅, GPU 할당, 추론 서버 관리가 필요 없습니다. API 호출 한 줄로 Claude를 사용할 수 있고, 모델 버전 업그레이드는 환경 변수 변경으로 끝납니다. 도메인 전문가인 기자가 Bedrock 콘솔에서 직접 프롬프트를 테스트하고 튜닝할 수 있는 환경이 핵심이었습니다.
AI 기반 개발 도구의 활용
Amazon Q Developer를 포함한 AI 코딩 어시스턴트가 비개발자의 코드 작성을 보조했습니다. Lambda 함수 작성, DynamoDB 테이블 설계, API Gateway 설정 등에서 AI가 코드 초안을 제공하고 기자가 도메인 요구사항에 맞게 수정하는 방식으로 협업했습니다.
시스템 기반 운영 모델
인턴이 교체되어도 품질이 유지됩니다. 노하우가 ‘사람의 머리’가 아닌 ‘시스템 프롬프트’에 저장되어 있기 때문입니다. 신규 인력 온보딩은 2주에서 1일로 단축되었고, 담당자가 바뀌어도 실행 버튼만 누르면 동일 품질의 결과물이 나옵니다.
2.5 비용 최적화
AI LINK의 비용 구조는 크게 두 가지로 나뉩니다. Amazon Bedrock API 호출 비용과 AWS 인프라 비용입니다. 각각에 대해 캐싱을 적용하여, 이중 레이어 캐싱 아키텍처를 구현했고 이를 통해 비용 절감 효과를 얻을 수 있었습니다.
| 레이어 | 목적 | TTL | 효과 |
| Layer 1: Lambda 메모리 | DynamoDB 쿼리 최소화 | Lambda 컨테이너 수명 | DB 호출 99% 감소 |
| Layer 2: Anthropic 프롬프트 캐시 | LLM 입력 토큰 비용 절감 | ~5분 (자동 관리) | 입력 토큰 비용 90% 감소 |
Layer 1 구현: Lambda 메모리 캐시
PROMPT_CACHE: Dict[str, Dict[str, Any]] = {}
def _load_prompt_from_dynamodb(self, engine_type: str):
global PROMPT_CACHE
# HIT: 캐시에서 즉시 반환
if engine_type in PROMPT_CACHE:
return PROMPT_CACHE[engine_type]
# MISS: DynamoDB 조회 후 캐시 저장
response = self.dynamodb_table.get_item(Key={'engine_type': engine_type})
PROMPT_CACHE[engine_type] = response['Item']
return PROMPT_CACHE[engine_type]Layer 2 구현: Anthropic 프롬프트 캐시
if enable_caching:
request_params["system"] = [{
"type": "text",
"text": system_prompt,
"cache_control": {"type": "ephemeral"}
}]
# 캐시 읽기 토큰: $0.50/1M (일반 입력 $5.00 대비 90% 할인)비용 계산 함수
def _calculate_cost(self, usage: Dict[str, int]) -> float:
PRICE_INPUT = 5.0 # per 1M tokens
PRICE_OUTPUT = 25.0
PRICE_CACHE_WRITE = 10.0
PRICE_CACHE_READ = 0.50
cost_input = (usage.get('input_tokens', 0) / 1_000_000) * PRICE_INPUT
cost_output = (usage.get('output_tokens', 0) / 1_000_000) * PRICE_OUTPUT
cost_cache_write = (usage.get('cache_creation_input_tokens', 0) / 1_000_000) * PRICE_CACHE_WRITE
cost_cache_read = (usage.get('cache_read_input_tokens', 0) / 1_000_000) * PRICE_CACHE_READ
return cost_input + cost_output + cost_cache_write + cost_cache_read5주간 비용 최적화 데이터
| 주차 | 총 비용 | 캐시 히트율 | Input 토큰당 비용 | 절감률 |
| Week 1 (최적화 전) | $1,389 | – | $5.00/1M | 기준 |
| Week 2 | $892 | 45% | $4.12/1M | 36% |
| Week 3 | $534 | 72% | $3.85/1M | 62% |
| Week 4 | $318 | 85% | $3.68/1M | 77% |
| Week 5 (최적화 후) | $262 | 89% | $3.64/1M | 81% |
비용 최적화 결과 요약
| 지표 | 최적화 전 | 최적화 후 | 절감률 |
| 월간 API 비용 | $1,389 | $262 | 81% |
| Input 토큰당 비용 | $5.00/1M | $3.64/1M | 27.10% |
| 평균 Latency | 2.8초 | 1.1초 | 60% |
| 캐시 히트율 | 0% | 89% | – |
| AWS 인프라 비중 | – | 5.40% | – |
AWS 인프라는 전체 운영비의 5.4%에 불과합니다. 비용 최적화의 핵심은 Claude API Input 토큰입니다.
2.6 Latency 모니터링
AI LINK는 4계층 Latency 측정 체계를 구축하여 모델별 성능을 실시간으로 모니터링합니다.
4계층 Latency 측정 구조
| 계층 | 측정 대상 | 측정 위치 | 핵심 지표 |
| 1 | WebSocket 연결 시간 | API Gateway $connect | IntegrationLatency |
| 2 | Lambda 실행 시간 | lambda_function.py | Duration |
| 3 | AI 모델 호출 시간 | MultiAIService | AIInvokeLatency |
| 4 | 첫 응답 시간 (TTFB) | stream_response() | TimeToFirstByte |
CloudWatch Custom Metric 전송 함수 구현 코드
import boto3
from datetime import datetime, timezone
cloudwatch = boto3.client('cloudwatch', region_name='us-east-1')
def put_latency_metric(metric_name: str, value: float, ai_model: str, dimensions=None):
"""CloudWatch Custom Metric 전송"""
metric_data = {
'MetricName': metric_name,
'Value': value,
'Unit': 'Milliseconds',
'Timestamp': datetime.now(timezone.utc),
'Dimensions': [
{'Name': 'AIModel', 'Value': ai_model},
{'Name': 'Environment', 'Value': os.environ.get('STAGE', 'prod')}
]
}
if dimensions:
metric_data['Dimensions'].extend(dimensions)
cloudwatch.put_metric_data(
Namespace='AILinkMetrics',
MetricData=[metric_data]
)
TTFB (Time To First Byte) 측정 코드
def stream_response(self, user_message: str, model_name: str):
"""AI 응답 스트리밍 (TTFB 측정 포함)"""
model_start = time.time()
first_chunk_received = False
for chunk in client.stream_chat(user_message):
if not first_chunk_received:
ttfb_ms = (time.time() - model_start) * 1000
first_chunk_received = True
put_latency_metric('TimeToFirstByte', ttfb_ms, model_name)
yield chunk
total_latency_ms = (time.time() - model_start) * 1000
put_latency_metric('TotalStreamingTime', total_latency_ms, model_name)
CloudWatch Dashboard JSON 구조 (AI 모델 호출 지연 시간, Lambda 실행 시간, 모델별 TTFB, WebSocket 연결 지연 시간 4개 위젯 구성)
{
"widgets": [
{
"type": "metric",
"properties": {
"metrics": [
["AILinkMetrics", "AIInvokeLatency", {"stat": "p50", "label": "p50"}],
["AILinkMetrics", "AIInvokeLatency", {"stat": "p95", "label": "p95"}],
["AILinkMetrics", "AIInvokeLatency", {"stat": "p99", "label": "p99"}]
],
"title": "AI 모델 호출 지연 시간 (ms)"
}
},
{
"type": "metric",
"properties": {
"metrics": [
["AWS/Lambda", "Duration", {"FunctionName": "ai-link-websocket-message"}]
],
"title": "Lambda 실행 시간 (ms)"
}
},
{
"type": "metric",
"properties": {
"metrics": [
["AILinkMetrics", "TimeToFirstByte", {"AIModel": "claude"}, "Claude TTFB"],
["AILinkMetrics", "TimeToFirstByte", {"AIModel": "gpt"}, "GPT TTFB"]
],
"title": "첫 응답 시간 (TTFB) - 모델별"
}
},
{
"type": "metric",
"properties": {
"metrics": [
["AWS/ApiGateway", "IntegrationLatency", {"stat": "Average"}]
],
"title": "WebSocket 연결 지연 시간 (ms)"
}
}
]
}
CloudWatch Logs Insights 이상치 분석 쿼리
-- Duration 기반 이상치 분석
filter @type = "REPORT"
| stats max(@duration), avg(@duration), min(@duration), stddev(@duration) by bin(5m)
| sort max(@duration) desc
-- 모델별 지연 시간 정밀 분석
fields @timestamp, @message
| filter @message like /latency/
| parse @message /"model":\s*"(?<model>[^"]+)",\s*"latency":\s*(?<latency>\d+)/
| stats avg(latency) as avg_l, pct(latency, 95) as p95 by model이 구조를 통한 Latency 측정 결과는 아래와 같습니다. 8초 이상의 Latency 스파이크가 발생하면 Provisioned Concurrency 또는 다른 모델로의 Failover 로직이 작동합니다.
| 지표 | Normal | Peak | Target |
| AI Model Invoke | ~2,000ms | 8,280ms | < 3,000ms |
| Lambda Duration | ~1,500ms | 5,000ms | < 2,500ms |
| TTFB (Claude) | ~800ms | 2,000ms | < 1,000ms |
| WebSocket Connection | ~50ms | 200ms | < 100ms |
2.7 Step Functions 병렬 처리
AI PRISM의 Issue Map은 AWS Step Functions의 Parallel 상태를 활용하여 대규모 뉴스 아카이브를 병렬 처리합니다. 빅카인즈 API에서 30년치 뉴스 데이터를 조회하고, 이슈별로 타임라인을 구성하는 작업을 동시에 수행합니다.
AI PRISM Issue Map 구현에 사용된 Step Functions 워크플로우 정의 (ASL)는 아래와 같습니다.
{
"Comment": "AI PRISM Issue Map - Parallel News Processing",
"StartAt": "FetchNewsArchive",
"States": {
"FetchNewsArchive": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-east-1:ACCOUNT:function:fetch-bigkinds",
"Next": "ParallelProcessing"
},
"ParallelProcessing": {
"Type": "Parallel",
"Branches": [
{
"StartAt": "ExtractEntities",
"States": {
"ExtractEntities": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-east-1:ACCOUNT:function:extract-entities",
"End": true
}
}
},
{
"StartAt": "BuildTimeline",
"States": {
"BuildTimeline": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-east-1:ACCOUNT:function:build-timeline",
"End": true
}
}
},
{
"StartAt": "CalculateRelevance",
"States": {
"CalculateRelevance": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-east-1:ACCOUNT:function:calculate-relevance",
"End": true
}
}
}
],
"Next": "MergeResults"
},
"MergeResults": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-east-1:ACCOUNT:function:merge-issuemap",
"End": true
}
}
}이러한 병렬 처리를 통한 성능 개선 효과는 명확했습니다. 처리 시간은 82% 단축되고, 비용은 10% 증가에 그칩니다. 실시간 이슈 맵 생성이 가능해지면서 사용자 경험이 크게 개선되었습니다.
| 처리 방식 | 1,000건 처리 시간 | Lambda 호출 수 | 비용 |
| 순차 처리 (Before) | ~45분 | 1,000회 | $0.50 |
| 병렬 처리 (After) | ~8분 | 1,000회 (동시) | $0.55 |
| 개선율 | 82% 단축 | – | 10% |
3. 결론
3.1 정량적 성과
| 구분 | 지표 | 수치 | 비고 |
| 콘텐츠 도달 | 영상 총 조회수 | 6,044만 뷰 | YoY 186% 성장 |
| 생산성 | 영상 제작량 | 14,123건 | YoY 214% 증가 |
| 수익 | 직접 매출 | 1억 323만원 | 플랫폼 채널 수익 |
| 운영 효율 | AI NOVA 사용자 | 268명 | 95% 자발적 채택 |
| 품질 관리 | 환각/오보 | 0건 | 2,500건+ 발행 중 |
| 글로벌 확장 | AI 검색 트래픽 | 49% | Google의 1.85배 |
| 비용 효율 | 번역 건당 비용 | 180원 | 기존 대비 1/100 |
3.2 핵심 교훈
이 프로젝트를 통해 확인한 것은 AI 저널리즘의 성공이 기술 자체가 아니라 도메인 지식의 시스템화에 달려 있다는 점입니다. 기자 2명과 인턴 4명, 총 6명의 비개발 인력이 1년 만에 4개 서비스를 구축하고 1억원의 매출를 창출할 수 있었던 것은 AWS 서버리스 아키텍처 덕분입니다. Lambda와 Step Functions는 인프라 관리 부담을 제거했고, Amazon Bedrock은 AI 모델 운영의 복잡성을 추상화했습니다. 25년간 축적된 저널리즘 노하우는 프롬프트가 되었고, 프롬프트는 서비스가 되었으며, 서비스는 수익이 되었습니다. AWS는 그 과정에서 도메인 전문가가 직접 시스템을 구축할 수 있는 환경을 제공했습니다.
3.3 향후 계획: Agentic AI로의 진화
AI LINK의 다음 단계는 Agentic AI 도입입니다. 현재 AI LINK는 기자의 입력을 기다리는 반응형 시스템입니다. 다음 단계는 AI가 스스로 판단하고 행동하는 능동적 에이전트로 진화하는 것입니다. Amazon Bedrock Agents를 활용하여 실시간 모니터링, 취재 초안, 팩트체크 에이전트를 구현할 계획입니다.
한국온라인신문협회는 서울경제신문이 구축한 AI 기반 저널리즘 생태계 ‘AI LINK’를 제3회 디지털저널리즘혁신대상 디지털 서비스-비즈니스 부문 대상으로 대상으로 선정했습니다. 온라인신문협회는 ‘AI LINK’가 뉴스룸 전체를 AI 기반으로 전환해 생산·맞춤·영상·글로벌 확장까지 이어지는 순환 구조를 구축, 실제 수익 창출과 글로벌 확장을 통해 저널리즘의 지속가능성을 입증했다는 점에서 수상작으로 선정했다고 밝혔습니다.
참고 자료
- Anthropic Claude 모델 벤치마크: https://www.anthropic.com/claude/opus
- Anthropic 모델선택가이드: https://docs.anthropic.com/en/docs/about-claude/models/model-selection
- AWS DynamoDB Best Practices for Partition Keys: https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/bp-partition-key-design.html
- Amazon Bedrock 프롬프트 캐싱: https://docs.aws.amazon.com/bedrock/latest/userguide/prompt-caching.html
- AWS Step Functions Parallel State: https://docs.aws.amazon.com/step-functions/latest/dg/amazon-states-language-parallel-state.html
- Amazon Polly 엔진 비교: https://docs.aws.amazon.com/polly/latest/dg/NTTS-main.html
- Amazon Transcribe Custom Vocabulary: https://docs.aws.amazon.com/transcribe/latest/dg/custom-vocabulary.html
- pgvector 성능튜닝: https://github.com/pgvector/pgvector
- Google Search Central URL 구조 가이드라인: https://developers.google.com/search/docs/crawling-indexing/url-structure
- llmstxt.org – LLMs.txt 사양: https://llmstxt.org
- Google 검색품질평가가이드라인 E-E-A-T: https://developers.google.com/search/docs/fundamentals/creating-helpful-content
- Earcons 설계원칙: Sumikawa, D.A. (1985). Guidelines for the integration of audio cues into computer user interfaces. Lawrence Livermore National Laboratory.
- Earcons 구조와설계: Blattner, M.M., Sumikawa, D.A., & Greenberg, R.M. (1989). Earcons and icons: Their structure and common design principles. Human-Computer Interaction, 4(1), 11-44.
- Speechmatics 턴감지문서: https://docs.speechmatics.com/speech-to-text/realtime/turn-detection
- Amazon Science – Accurate Endpointing with Expected Pause Duration: https://www.amazon.science/publications/accurate-endpointing-with-expected-pause-duration