AWS 기술 블로그
Zookeeper에 의존하지 않는 Kafka를 준비하기 : Amazon MSK에서 KRaft 모드 사용하기
들어가기
Amazon Managed Streaming for Apache Kafka(이하 Amazon MSK)는 AWS에서 제공하는 완전 관리형 Apache Kafka 서비스로 Apache Kafka에 대한 복잡한 설정, 관리, 운영을 AWS가 대신 처리해주어 개발자가 데이터 처리에만 집중 할 수 있도록 도움을 주는 AWS의 매니지드 서비스입니다.
많은 고객들은 Micro-service Architecture(MSA)을 채택하여 어플리케이션을 현대화하고 있으며 Apache Kafka는 MSA의 Event Driven Architecture(EDA)에서 메세징 허브 역할을 담당하면서 Apace Kafka에 대한 중요성은 계속 증가하고 있습니다. 또한 실시간 데이터 처리 및 Change Data Capture(CDC)에서도 Apache Kafka는 대중적으로 사용되고 있습니다.
이 블로그는 Amazon MSK을 사용하는 고객들을 위해 최신 Apache Kafka의 아키텍처인 KRaft 모드에 대한 설명하며 Amazon MSK는 KRaft 모드를 어떻게 지원하고 있는지 알아봅니다.
KRaft 모드의 등장 배경
기존 Kafka의 아키텍처 : Zookeeper 모드
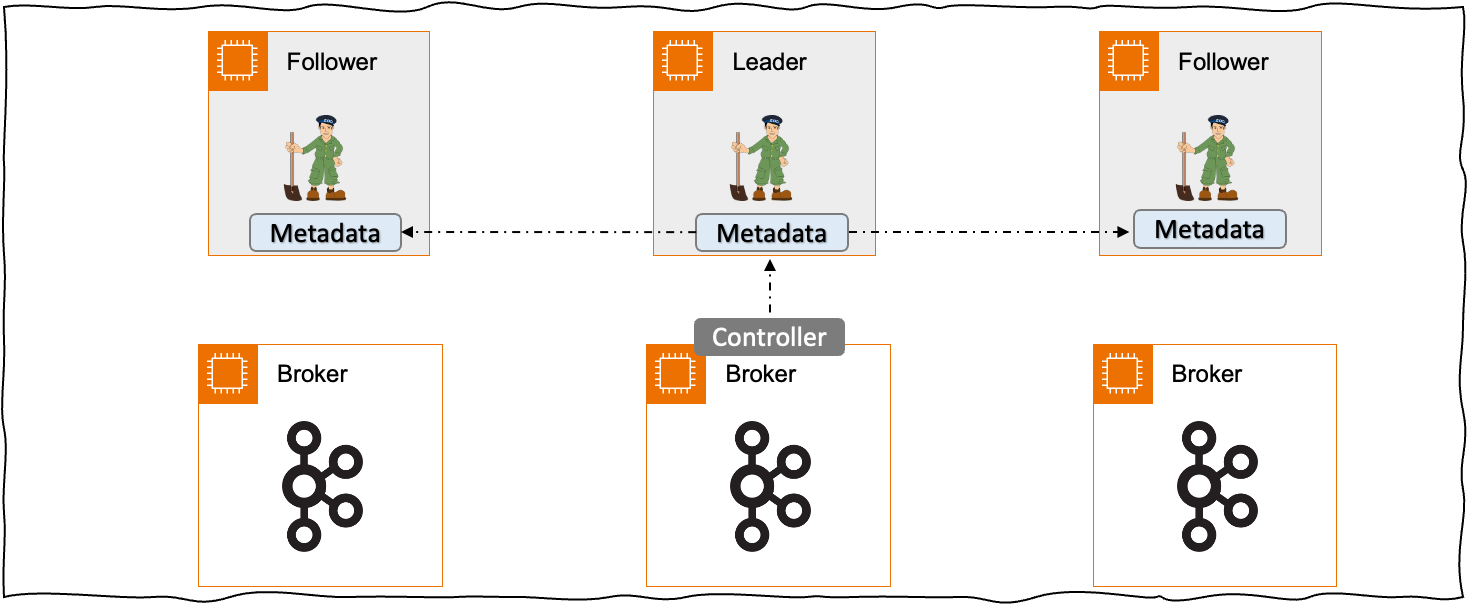 < 그림 1. 기존 Zookeeper 방식의 Apache Kafka >
< 그림 1. 기존 Zookeeper 방식의 Apache Kafka >
전통적인 Apache Kafka는 Apache Zookeeper를 사용하는 아키텍처로 Apache Zookeeper를 메타데이터 관리를 위해 사용합니다. 메타데이터는 Kafka 클러스터의 Topic의 구성 정보, 브로커의 목록, 파티션 리더 정보 등을 저장하고 있습니다. 브로커 중 하나는 Zookeeper와 통신하는 컨트롤러 역할을 하며 이 브로커는 Zookeeper을 통한 메타데이터들을 다른 브로커로 전달하는 역할을 하고 있습니다.
이러한 아키텍처는 클러스터의 고가용성 보장, 모든 브로커 노드의 일관성 보장, 브로커 장애 시 자동 복구와 같은 역할을 하지만 몇가지 한계가 있었습니다. Zookeeper의 메타데이터에 대한 업데이트는 단일 Controller 노드가 담당하게 됩니다. 이로인해 클러스터의 브로커의 수와 토픽 파티션의 수가 증가함에 따라 ZooKeeper의 읽기 및 쓰기 트래픽이 증가하게 되고 이는 클러스터 성능의 병목 현상으로 작용하게 됩니다. 또한 Broker의 단일 Controller는 장애시 많은 복구 비용과 시간이 필요합니다.
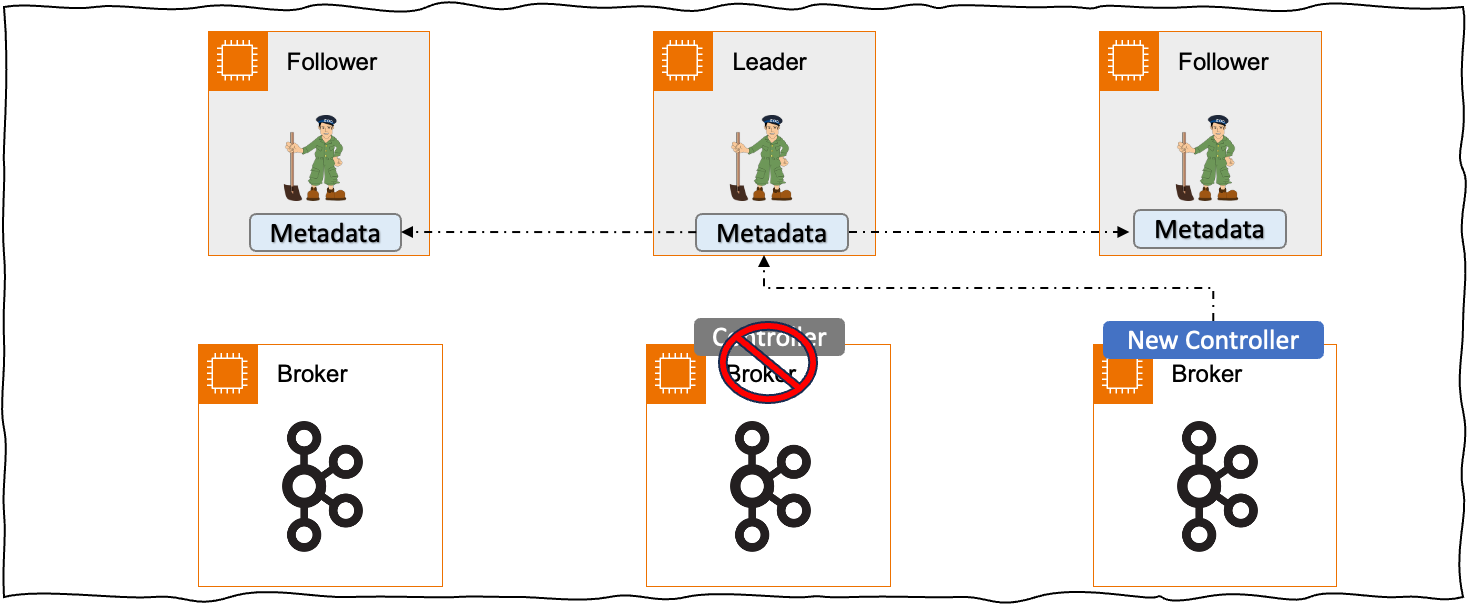 < 그림 2. Zookeeper 방식에서의 새로운 Controller 선출 >
< 그림 2. Zookeeper 방식에서의 새로운 Controller 선출 >
하나의 시나리오를 통해 1/Zookeeper 사용 그리고 2/Controller노드로 인한 인한 병목 현상을 설명해보고자 합니다. 만약 기존의 Controller가 Shutdown 하게 된다면 다른 브로커 중 하나가 Controller 역할을 담당하게 됩니다. 새롭게 선정 된 Controller 브로커는 Zookeeper로부터 메타 데이터를 가져오고 이 메타데이터를 브로커에 다시 전파하게 됩니다. 만약 브로커의 수, 파티션의 수가 많아 메타데이터의 사이즈가 클 경우에는 어떻게 될까요? ZooKeeper에서 메타데이터를 가져오는 데 많은 시간이 필요하게 되고 Controller는 여러 Kafka의 관리 기능을 수행하지 못하게 됩니다.
그 외에도 Zookeeper로 인한 의존성으로 인해 발생하는 대표적인 한계는 아래와 같습니다.
- 메타데이터 동기화 지연 : 메타데이터 동기화에 많은 홉이 발생합니다. Zookeeper → Controller → Broker로 여러 홉을 거치게 됩니다.
- 컨트롤러 복구 시 지연 발생 : 컨트롤러 장애시 새로운 컨트롤러 선출에 많은 시간이 소요되며 대량의 메타데이터 동기화가 필요합니다.
- 파티션 수 및 브로커 수의 한계 : 많은 메타데이터 발생 시 ZooKeeper에 성능 저하를 발생하여 파티션과 브로커 수의 한계가 발생합니다.
- 이중 시스템의 복잡성 : Kafka와 Zookeeper는 다른 서비스입니다. 각기 다른 운영 방안이 필요합니다. 또한 기존 Zookeeper의 문제 발생 시 Kafka의 장애로 이어지는 Zookeeper에 대한 의존성도 존재했습니다.
Apache Kafka는 Zookeeper의 의존성으로 인해 발생하는 한계를 극복하기 위해 KIP-500을 시작으로 메타데이터에 대한 관리를 Zookeeper가 아닌 Kafka 자체적으로 관리하는 방안이 등장하게 됩니다.
Kafka KRaft 모드 이해하기
먼저 KRaft 방식의 Apache Kafka의 구성 요소들에 대해 알아봅니다.
 < 그림 3. Apache Kafka의 KRaft 모드 구성 요소 >
< 그림 3. Apache Kafka의 KRaft 모드 구성 요소 >
- Leader Controller : Leader Controller는 Raft 합의 알고리즘에 따라서 리더로 선출되며
__cluster_metadata에 데이터를 기록하는 역할을 담당합니다. - Voter Controller :
__cluster_metadata토픽에 대한 사본을 저장하며 해당 토픽에 대한 In Sync Replica(ISR)로의 역할을 수행합니다. 새로운 리더 선출 시 투표할 수 있는 권한을 갖습니다, - Observer : Kafka의 브로커이며 Controller 리더 선출을 위한 투표권은 갖고 있지 않습니다.
__cluster_metadata을 저장하고 해당 내용을 메모리에 캐시 및 스냅샷을 저장합니다.
새롭게 등장한 Kafka KRaft 모드는 메타데이터에 대한 관리를 Zookeeper가 아닌 Kafka 클러스터가 자체적으로 관리합니다. 기존의 Zookeeper 방식에서 메타데이터에 대한 동기화 방식을 RPC 통신 방식으로 사용했으나, 새롭게 도입된 KRaft는 메타데이터의 변경 사항을 Kafka 클러스터의 내부 토픽인 __cluster_metadata에 저장하고 이벤트 기반으로 처리합니다.
Quorum 방식의 Controller는 메타데이터에 대한 변경사항을 추적하기 위한 __cluster_metadata 토픽을 관리하게 됩니다. 이 토픽은 순서보장을 위하여 하나의 파티션으로 구성되어 있으며 Kafka에 대한 모든 메타데이터 정보를 기록합니다. KRaft 방식의 Apache Kafka는 아래와 같은 순서로 메타데이터를 관리합니다.
 < 그림 4. Apache Kafka의 KRaft 모드 동작 방식 >
< 그림 4. Apache Kafka의 KRaft 모드 동작 방식 >
- Leader Controller는 ISR 변경과 같은 Metadata의 업데이트를 ‘__cluster_metadata’ 토픽에 기록합니다.
- ‘__cluster_metadata’에 저장된 메세지를 전체 클러스터로 복제하게 되며 Quorum 방식으로 복제합니다. 이 토픽에 저장된 데이터를 각 브로커의 log 파일로 저장합니다.
- 메타데이터의 정보는 각 Controller와 Broker의 캐시에 업데이트합니다.
- 캐시에 저장된 정보들을 주기적으로 각 Controller와 Broker에 스냅샷 방식으로 저장합니다.
메타데이터에 대한 정보는 각 Controller와 브로커의 메모리에 캐시 및 스냅샷 방식으로 디스크에 저장합니다. 이러한 과정으로 인하여 브로커 복구 시 메타데이터의 정보를 디스크의 스냅샷에서 바로 읽어 더 빠른 복구 시간을 제공합니다. 이는 기존 Zookeeper 방식보다 메타데이터에 대한 복제 과정을 단순화시켜 Controller 또는 Broker 재기동시 더 빠른 복구를 지원합니다.
메타데이터 토픽의 동기화 과정
메타데이터를 관리하는 내부 토픽인 __cluster_metadata는 다른 브로커로 복제 되지만 기존의 메세지를 처리하던 Topic 과는 다른 방식으로 복제됩니다. 기존의 메세지 토픽과 메타데이터 토픽의 처리 방식이 어떻게 다른지 알아보겠습니다.
기존 메세지 토픽 : Leader & Follower 복제 방식
Kafka의 메세지 토픽은 파티션과 복제본의 수로 구성됩니다. 아래와 같이 파티션의 수가 1개이고, 복제본의 수가 3개일 경우로 가정해보도록 하겠습니다. 여러 파티션 중 하나는 리더 파티션의 역할을 수행하게되며 토픽을 바라보는 여러 Producer와 Consumer는 리더 파티션을 기준으로 메세지를 쓰고 읽습니다. 모든 복제본 파티션에 메세지가 정확히 기록될 때 리더 파티션은 복제가 완료된 메세지까지 Commit을 하게 되고 이 지점까지 Consumer에 메세지를 노출하게 됩니다.
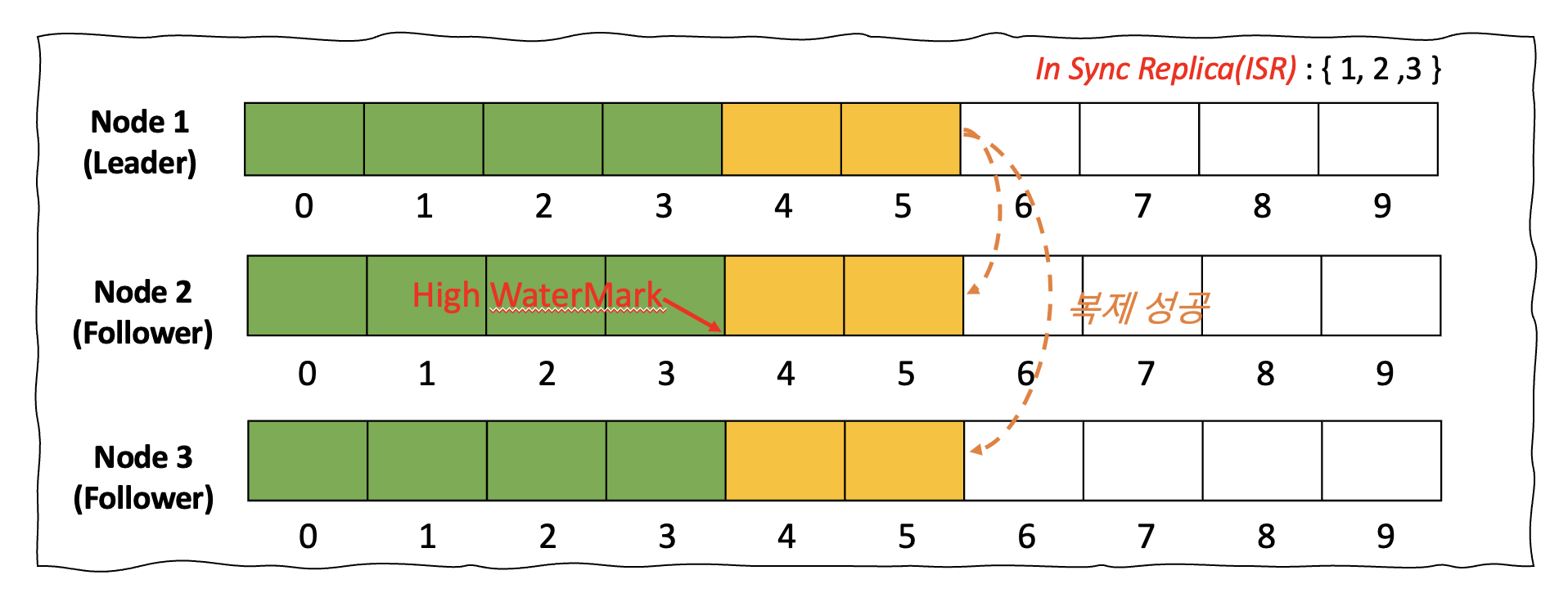 < 그림 5. 기존 메세지 토픽의 복제 방식 >
< 그림 5. 기존 메세지 토픽의 복제 방식 >
메타데이터 토픽 : 쿼럼(Quorum) 복제 방식
쿼럼 복제 방식은 분산 시스템에서 데이터의 가용성 및 일관성을 보장하기 위한 복제 방식입니다. 모든 노드에 작업이 완료되지 않아도, 특정 수 이상의 노드에서 데이터 읽기 및 쓰기 작업이 성공하면 해당 작업이 유효하다고 인정하는 방식입니다. 쓰기 요청이 들어오면, 쿼럼(과반수) 노드에 데이터 복제를 시도하며 과반 이상에 쓰기 작업이 완료되면 해당 작업은 성공으로 처리합니다. 예를 들어 총 3대의 쿼럼 노드가 있다고 가정 할 경우 2대에서 쓰기가 성공 할 경우 데이터 복제 성공이 완료된 것으로 간주하게 됩니다. 이러한 방식은 기존의 Leader & Follower 방식에 비해 더 빠른 복제 시간을 제공합니다.
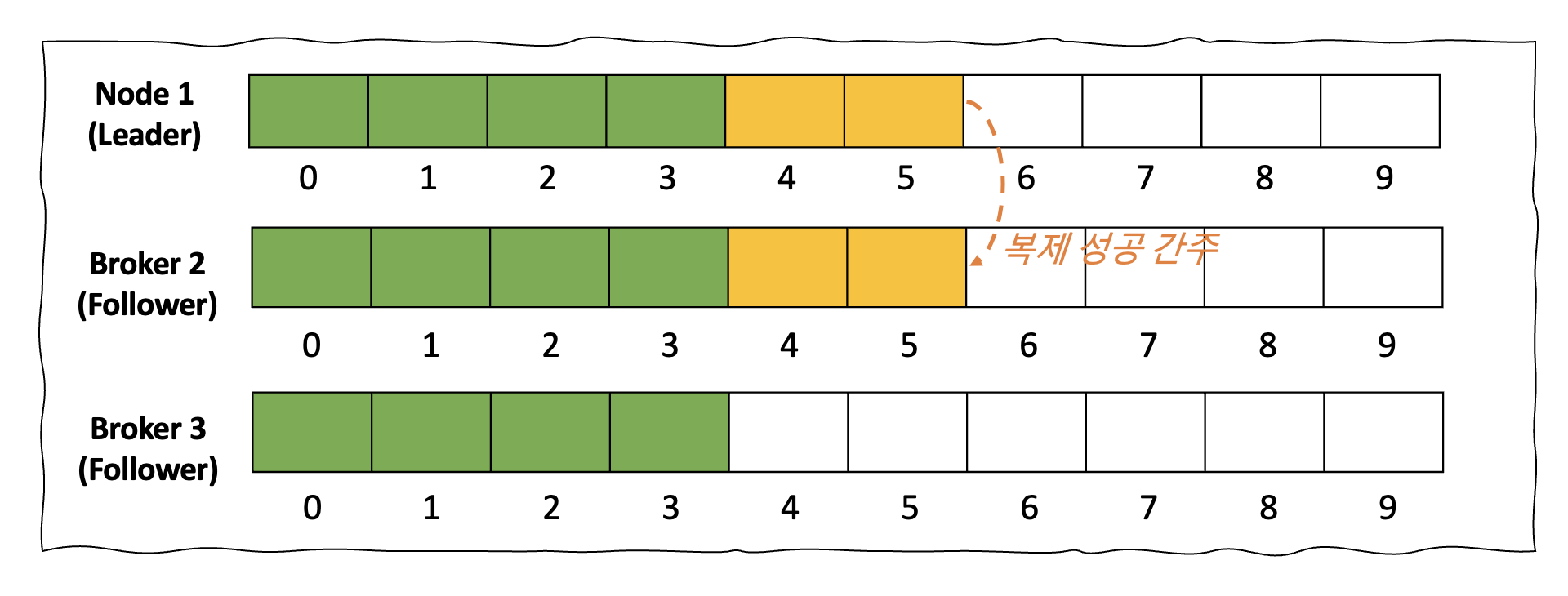 < 그림 6. 메타데이터 토픽의 복제 방식 >
< 그림 6. 메타데이터 토픽의 복제 방식 >
Leader Controller의 선출 작업 이해하기
기존의 Leader Controller가 셧다운되고 새로운 Controller가 선출되기 위한 과정에 대해 살펴보겠습니다. 기존의 리더 Controller가 셧다운 시 새로운 후보자는 새로운 Epoch 값과 후보자가 갖고 있는 최신 Offset 정보를 투표권자에 전달합니다. 아래의 상황을 예로 들어 보겠습니다. 기존 Leader Controller였던 1번 노드에 셧다운이 발생했습니다. 이때 2번 노드가 후보자가 되었고 이 후보자는 candidateEpoch는 2이라는 값과 자신이 갖고 있는 Offset 정보는 5를 유권자인 3번 노드에 전달합니다.
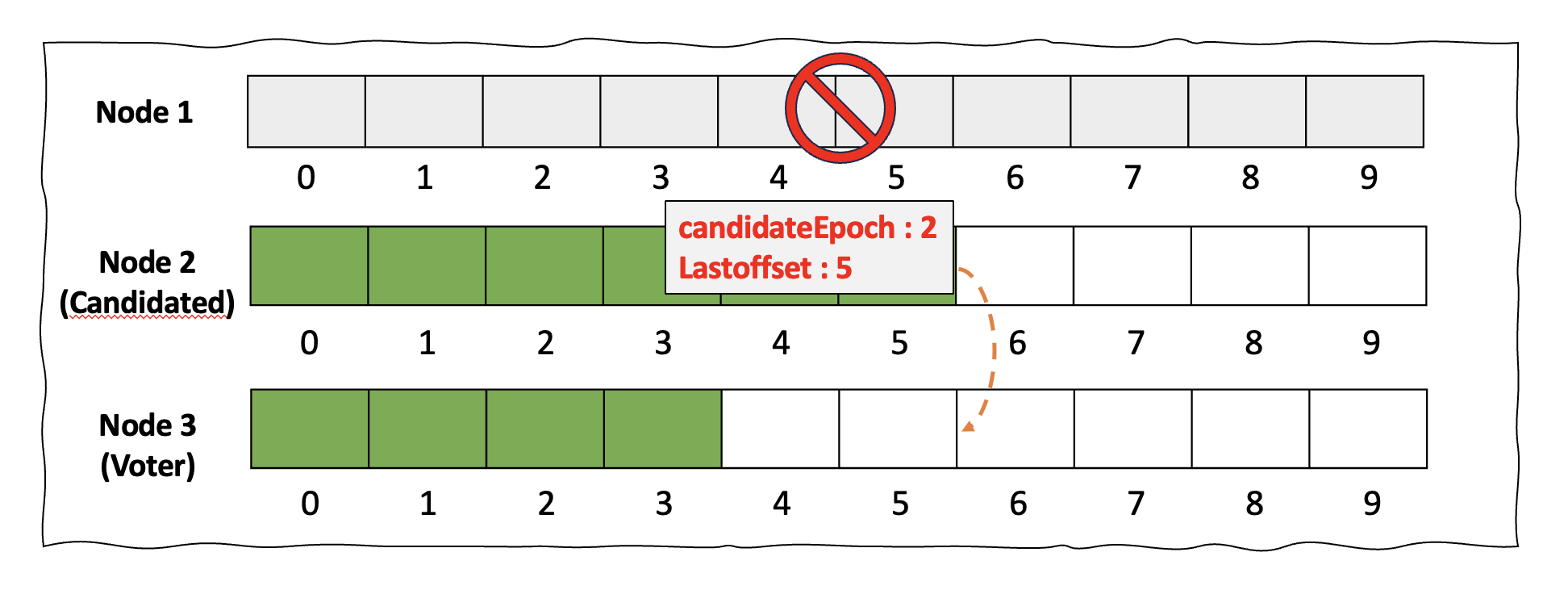 < 그림 7. 새로운 Controller 선출 과정 >
< 그림 7. 새로운 Controller 선출 과정 >
이제 유권자인 3번 노드는 후보자인 2번 노드가 전달한 정보를 기반으로 투표의 여부를 결정합니다.
- 후보자가 보낸 에포크 값이 유권자의 에포크 값보다 큰지?
- Why? – 더 높은 에포크 값은 더 최신의 리더 정보이므로 항상 최신성을 보장하기 위함입니다.
- 제공된 에포크에 처음으로 투표하는지?
- Why ? – 같은 에포크에서 여러 후보자에게 투표하는 것을 방지하기 위함입니다.
- 자신이 갖고 있는 Offset보다 긴지?
- Why? – 더 많은 메타데이터를 가진 후보자가 리더가 되어야 하기 때문입니다.
위 셋 질문에 모두 True일 경우 해당 후보자에 투표를 부여하고 새로운 리더 Controller을 선출하게 됩니다. 결국 이 기준들은 가장 적합한 후보자(최신 데이터를 가진 노드)가 리더가 되도록 하여 Kafka 클러스터의 안정성과 데이터 무결성을 보장하는 것이 목적입니다.
Amazon MSK에서의 KRaft 모드 지원
Amazon MSK에서의 KRaft 살펴보기
Amazon MSK에서는 Apache Kafka 3.7 버전부터 Kafka KRaft 모드를 지원하기 시작했으며, Amazon MSK 4.0 버전에서는 오직 KRaft 모드만을 지원합니다. ZooKeeper 노드와 마찬가지로 Amazon MSK에는 KRaft 컨트롤러가 추가 비용 없이 포함되어 있으며, 추가 설정이나 관리가 필요하지 않습니다. ZooKeeper 기반 클러스터에는 기본 30개의 브로커 할당량이 있지만, KRaft 모드의 경우, 한도 증가 요청 없이 최대 60개의 브로커를 추가하여 클러스터당 더 많은 파티션을 호스팅할 수 있습니다.
Amazon MSK 3.7 버전 이상에서 Kafka 클러스터를 KRaft 모드로 생성하면 KRaft에 대한 설정을 확인 할 수 있습니다. 아래는 kafka-metadata-quorum.sh 을 통해 메타데이터 정보를 조회한 결과입니다.
메타데이터 조회 결과에 대한 주요 내용입니다.
- LeaderId : KRaft 모드의 컨트롤러 중 리더인 사항입니다. 현재 10003 노드가 리더 컨트롤러입니다.
- LeaderEpoch : 리더가 변경 될 때 증가하는 에포크 값입니다. 현재 2회의 리더 선출 작업이 있었습니다.
- CurrentVoters : 컨트롤러 중 리더 선출을 위한 투표권이 있는 노드입니다. 현재 3개의 컨트롤러가 투표권을 갖고 있습니다.
- CurrentObservers : 관찰자로서 데이터 플레인의 브로커에 해당합니다. 현재 3개의 브로커로 구성되어 있습니다.
Amazon MSK의 KRaft Mode 지원에 대한 주요 사항
다음은 Amazon MSK에서 KRaft 모드를 사용하는데 있어서 유의해야하는 몇가지 사항입니다. 자세한 사항은 AWS의 공식 문서를 참조하세요.
- KRaft모드는 새로운 클러스터에만 사용 할 수 있습니다. 블로그를 작성하는 시점에서 기존의 Zookeeper 모드의 클러스터를 KRaft로의 In-place 전환은 현재 제공하고 있지 않으며 별도의 마이그레이션 전략이 필요합니다.
- Amazon MSK는 Kafka 3.7 버전부터 KRaft 모드를 지원하며 클러스터의 KRaft 모드 사용 시 버전에 대한 정보는
3.7.x.KRaft로 표기됩니다. 같은 버전의 Zookeeper을 사용 할 경우3.7.x로 표기됩니다. - 브로커당 파티션 수는 KRaft 및 ZooKeeper 기반 클러스터에서 동일합니다. 하지만 KRaft를 사용하면 최대 60개의 브로커를 지원(기존 30개 브로커)를 지원하므로 클러스터당 더 많은 파티션을 보유할 수 있습니다.
- KRaft 모드의 클러스터를 위한 별도의 CloudWatch 메트릭 정보는 제공하고 있지 않습니다. Controller에 대한 별도의 모니터링이 필요할 경우 오픈 소스기반(Prometheus)을 통해 일부 비컨트롤러에 대한 관련 지표를 수집 할 수 있습니다. Controller에 대한 DNS 정보는 Amazon MSK ListNodes API을 통해 확인 할 수 있습니다.
- Zookeeper 모드와 동일하게 KRaft Controller 노드에 대한 관리 작업을 위해 별도로 액세스 할 필요가 없습니다.
Amazon MSK의 KRaft 아키텍처
Amazon MSK를 3 곳의 AZ에 3개의 브로커로 생성 할 경우 아래와 같은 그림으로 KRaft 모드의 Amazon MSK 클러스터가 구성되게 됩니다. 고객의 VPC의 각 AZ 별로 Broker와 Controller에 매핑되는 ENI가 생성되며, Broker와 Controller는 AWS 서비스 영역에 배치됩니다. 두 엔드포인트는 아래의 상황에서 사용됩니다.
- Broker 엔드포인트 :
—bootstrap-server옵션을 사용하여 Amazon MSK의 관리적인 사항이나 Producer/Consumer 등의 데이터 처리를 위해 사용합니다. 대부분 Amazon MSK의 사용을 위해 사용하게 됩니다. - Controller 엔드포인트 : Controller 노드에 대한 모니터링이 필요할 경우 사용하며, 대부분 사용하지 않습니다.
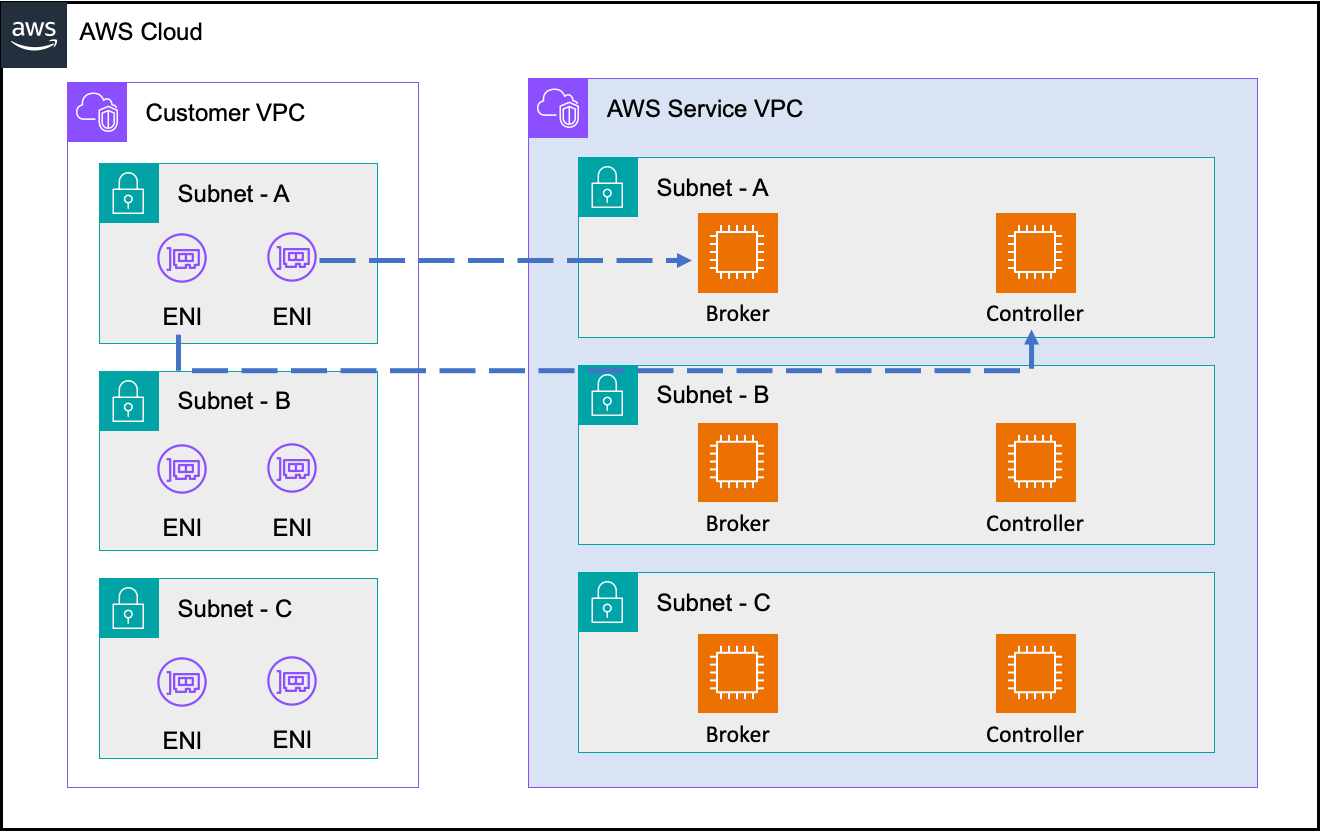
< 그림 8. Amazon MSK KRaft 모드 구성 >
KRaft 모드로의 마이그레이션
현재 블로그를 작성하는 시점에서는 Zookeeper 방식에서 KRaft 방식으로의 In-place 업그레이드는 제공하지 않습니다. 기존의 Zookeeper 방식의 Amazon MSK을 사용하고 있다면, KRaft 모드인 신규 클러스터를 생성하여 기존 MSK 클러스터의 데이터를 신규 클러스터로 마이그레이션 해야합니다. AWS에서는 Amazon MSK의 데이터 마이그레이션을 위해 아래 두 가지 방식을 지원하고 있습니다.
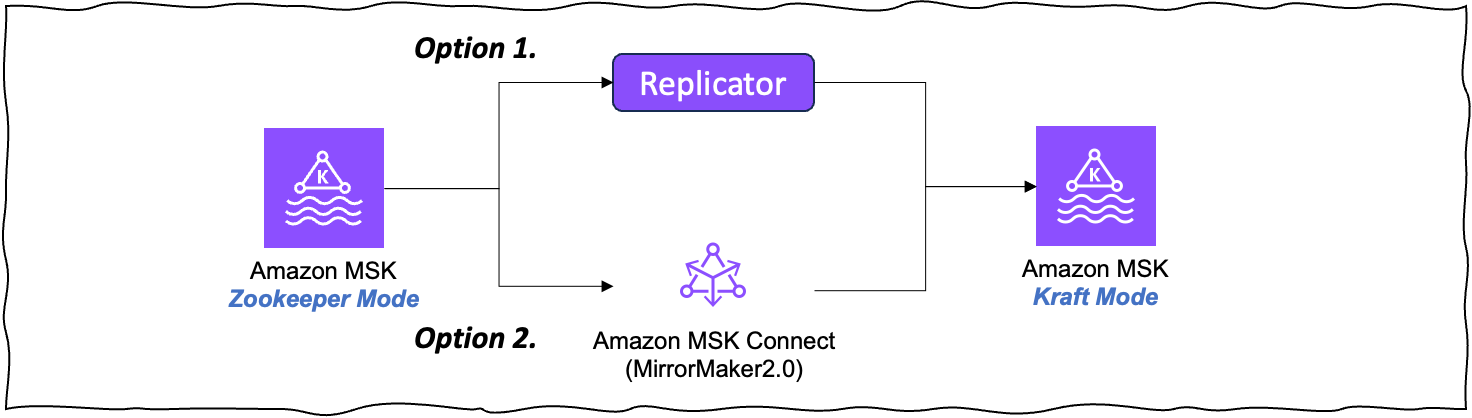
< 그림 9. Kraft 모드로의 마이그레이션 >
- Amazon MSK Replicator : Amazon MSK Replicator는 AWS에서 제공하는 완전 관리형 복제 서비스로, Kafka 클러스터 간 데이터를 실시간으로 복제할 수 있는 서비스입니다. Amazon MSK Replicator를 사용하여 기존 클러스터를 KRaft 모드인 신규 클러스터로 복제 할 수 있습니다.
- Amazon MSK Connect와 MirrorMaker 2.0 : Amazon MSK Connect는 Apache Kafka Connect의 완전 관리형 서비스입니다. 오픈소스인 MirrorMaker 2.0은 Amazon MSK Connect에 활용하여 기존 클러스터를 KRaft 모드인 신규 클러스터로 복제 할 수 있습니다.
관리 툴 및 어플리케이션의 변화
Amazon MSK를 KRaft모드로 마이그레이션 할 경우 ZooKeeper에 연결하여 MSK 클러스터와 상호 작용하던 관리 툴 및 어플리케이션의 변화도 살펴봐야합니다. Kafka는 1.0 버전 부터 관리 도구가 bootstrap.servers 가 입력 파라미터로 사용할 수 있는 기능을 도입했으며, 버전 2.5부터 ZooKeeper 연결 문자열을 사용하는 옵션을 더 이상 사용하지 않습니다. 이 변경은 Kafka와 ZooKeeper를 분리하고 메타데이터 관리를 위해 궁극적으로 KRaft 모드로 대체할 수 있는 기반을 마련하기 위한 과정이었습니다. 만약 기존의 관리 툴 또는 어플리케이션에서 ZooKeeper를 입력 파라미터로 지정하고 있을 경우 bootstrap.servers 구성 옵션을 사용하여 Kafka 브로커에 직접 연결해야 합니다.
Amazon MSK Controller 노드 모니터링하기
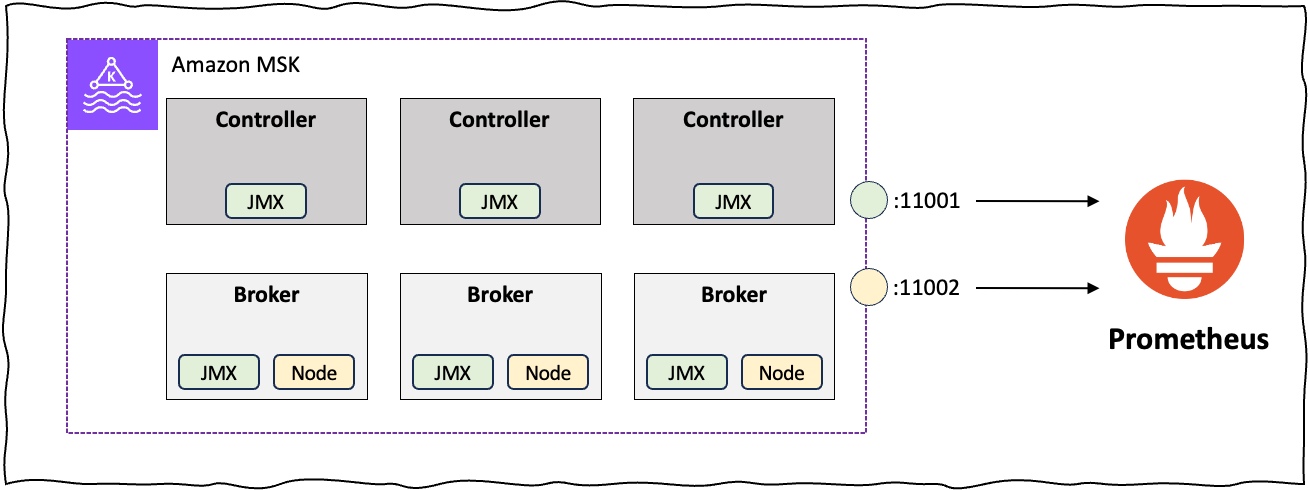
< 그림 10. Kraft 모드 모니터링 >
Amazon MSK의 Controller 노드는 CloudWatch 기반의 Metric 정보를 제공하고 있지 않으며, Prometheus와 같은 오픈소스 기반의 Metric 정보를 제공합니다. Kafka Controller 노드에 대한 주요 Metric 지표는 Kafka의 공식 문서에서 확인 할 수 있습니다. Amazon MSK에서 오픈소스 기반의 모니터링을 사용하기 위해서는 아래와 같이 Prometheus를 사용한 오픈 모니터링 옵션을 활성화해야 합니다. Prometheus을 통한 Amazon MSK 모니터링 기능은 별도의 비용은 발생하지 않지만, Cross-AZ로 인한 네트워크 비용이 발생 할 수 있으므로 이를 고려한 모니터링 파이프라인 구성이 필요합니다.
 < 그림 11. Prometheus을 활용한 오픈 모니터링 >
< 그림 11. Prometheus을 활용한 오픈 모니터링 >
아래는 Prometheus을 기반으로 Kraft 모드의 Amazon MSK에 대한 kafka_server_raft_metrics 상태를 조회한 결과입니다.
벤치마크 테스트로 알아보는 KRaft 모드와 Zookeeper 모드간의 성능 차이
KRaft모드로 Kafka을 사용 했을 때 메타데이터에 대한 정보를 내부 토픽으로 관리하며 무엇보다 메타데이터에 대한 정보를 Broker의 캐시에 저장함에따라 장애시 더 빠른 회복성을 보여줍니다. 벤치마크 테스트를 통해 Kraft모드가 Zookeeper모드 대비 얼마나 빠른 브로커 회복에 대한 성능을 보여주는지 테스트해봅니다.
테스트 환경
Kraft Mode와 Zookeeper 모드간 벤치마크 테스트를 위해 아래의 환경을 구성합니다.
- Apache Kafka 버전 : Kafka 3.9 버전
- Broker Size : kafka.m7g.xlarge
- 가용 영역 및 브로커 수 : 총 3개의 브로커
- Topic 수 : 500개(—partitions : 3 , —replication-factor : 2)
- 총 3000개의 파티션이 있으며, Broker 당 1,000개의 파티션
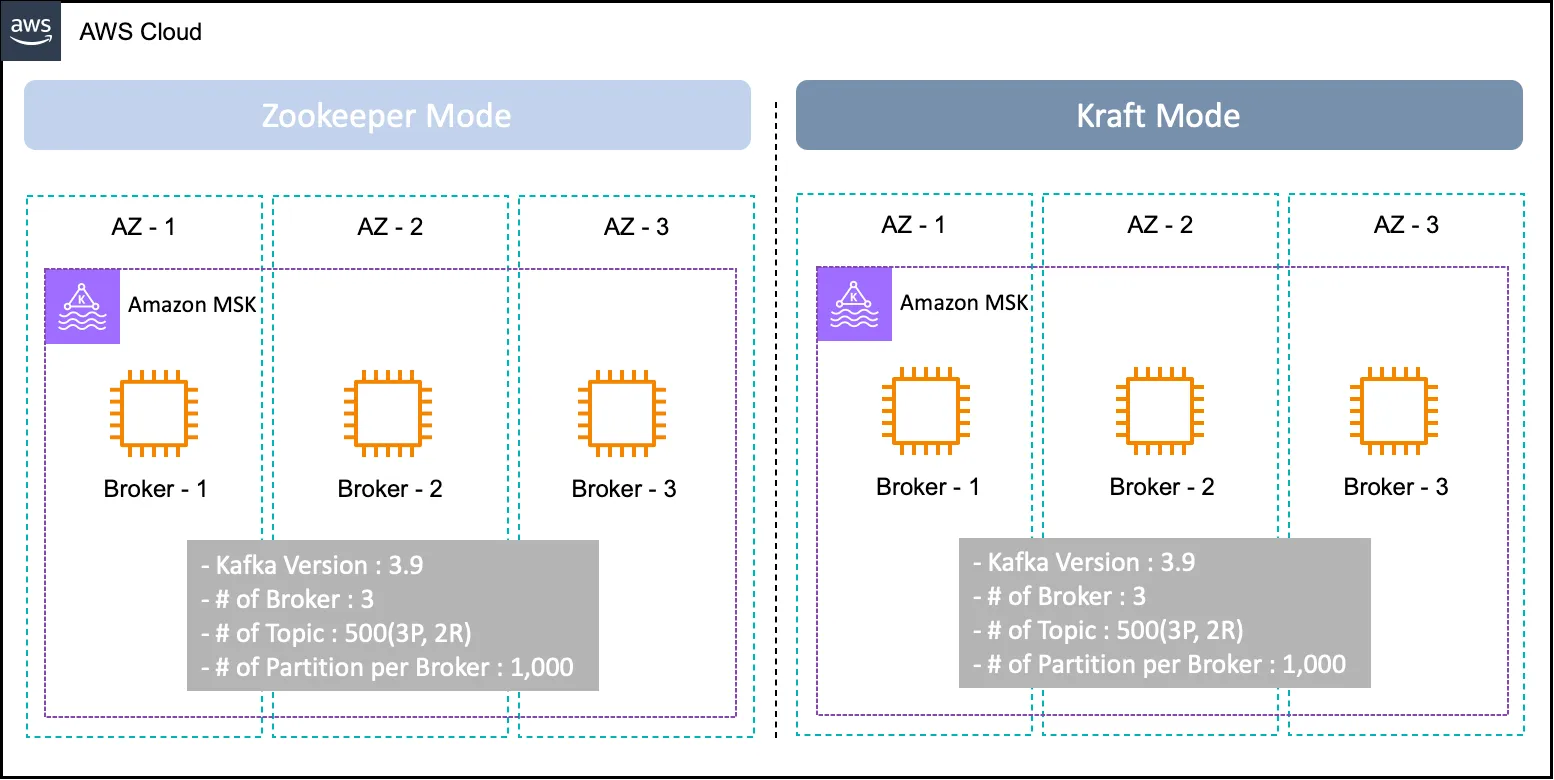
< 그림 12. 테스트 아키텍처 >
테스트 시나리오 및 결과
- 테스트 시나리오 : Kraft Mode의 클러스터와 Zookeeper Mode 클러스터에서 1번 브로커의 Reboot을 실행하고 Reboot이 완료되기까지의 시간을 측정.
- 테스트 결과 : 장애 상황을 가정하는 Broker Reboot 테스트에서는 Kraft Mode의 클러스터(2m 08s)가 Zookeeper 모드 클러스터(2m 59s) 대비 28% 빠른 속도를 보여주었습니다.
| API | Event | Zookeeper Mode | Kraft Mode |
| RebootBroker | Start Time | 09시 41분 59초 | 09시 41분 39초 |
| End Time | 09시 44분 58초 | 09시 43분 47초 | |
| Total duration | 2분 59초(179초) | 2분 8초(128초),28%빠름 | |
결론
지금까지 Amazon MSK에서 KRaft 모드를 사용하기 위해 기존의 Zookeeper 모드와 KRaft 모드의 차이점에 대해 알아보았습니다. Amazon MSK는 4.0 버전 부터 KRaft 모드를 단독으로 지원하며, 기존의 Zookeeper 모드의 클러스터 사용 시 Amazon MSK Replicator 또는 MirrorMaker2.0을 이용한 마이그레이션 전략이 필요합니다.
참고 자료
- https://kafka.apache.org/
- https://www.confluent.io/ko-kr/blog/what-is-KRaft-and-how-do-you-use-it/
- https://aws.amazon.com/ko/about-aws/whats-new/2024/05/amazon-msk-KRaft-mode-apache-kafka-clusters/
- https://www.confluent.io/blog/why-replace-zookeeper-with-kafka-raft-the-log-of-all-logs/?session_ref=direct