AWS 기술 블로그
AWS R-Assistant: Amazon Bedrock 기반 자연어 인터페이스의 클라우드 리소스와 비용 관리를 위한 챗봇
본 블로그에서는 Amazon Bedrock을 기반으로 한 AWS R-Assistant 챗봇을 소개합니다. 이 솔루션은 리소스 모니터링, 비용 관리, 최적화 및 AI 기반 AWS 전문가 채팅 기능을 통합하여 클라우드 환경을 효율적으로 관리할 수 있도록 지원합니다.
클라우드 환경에서 리소스와 비용을 효율적으로 관리하는 것은 개인 사용자와 기업 모두에게 중요하면서도 복잡한 과제입니다. 특히 AWS Management Console에 반복적으로 접속해야 하는 불편함과 복잡한 인터페이스는 사용자 경험을 저해하는 주요 요인으로 작용합니다. 이러한 문제를 해결하기 위해 개발된 AWS R-Assistant 챗봇은 대시보드와 자연어 인터페이스를 통해 혁신적인 사용자 경험을 제공합니다. 먼저 개인 사용자와 기업 관점에서 클라우드 관리의 어려움을 분석하고, 이 솔루션이 어떻게 이러한 문제를 해결하는지 살펴보겠습니다. 또한 챗봇의 각 탭에서 지원하는 구체적인 기능들이 실제 사용 환경에서 어떤 장점을 제공하는지 자세히 다루겠습니다. 나아가 AI Agent, RAG 등 최신 기술과의 통합을 통해 이 솔루션이 어떻게 더욱 강력한 클라우드 관리 도구로 발전할 수 있는지도 탐구해보겠습니다.
마지막으로 챗봇 구축을 위한 코드 분석을 통해 이 솔루션의 기술적 세부사항을 깊이 있게 다루며, AWS 기반 클라우드 관리가 어떻게 더 직관적이고 효율적으로 변화할 수 있는지 종합적으로 살펴보겠습니다.
클라우드 모니터링과 자원 관리의 중요성 및 어려움
AWS를 사용하는 모든 사용자에게 클라우드 모니터링과 자원 관리는 비용 효율성, 성능 최적화, 그리고 운영 안정성을 보장하는 핵심 요소입니다. 그러나 사용자의 규모와 목적에 따라 그 중요성과 어려움은 크게 달라집니다. 개인 사용자와 기업 내 계정 관리 조직의 관점에서 이를 나누어 살펴보겠습니다.
개인 사용자가 직면하는 현실
개인 사용자들, 즉 프리랜서 개발자나 스타트업 창업자, 학생들은 보통 제한된 예산과 기술 리소스 내에서 AWS를 활용합니다. 이들에게 클라우드 모니터링과 자원 관리가 중요한 이유는 명확합니다.
먼저 비용 통제가 가장 큰 관심사입니다. 개인 사용자는 종종 소규모 프로젝트나 학습 목적으로 AWS를 사용하는데, 예상치 못한 비용 발생은 큰 부담이 될 수 있습니다. 무료 티어를 초과하거나 사용하지 않는 EC2 인스턴스를 방치하는 것만으로도 예산에 상당한 타격을 받을 수 있습니다.
또한 소규모 환경에서는 단일 리소스의 비효율적 사용이 전체 성능과 비용에 큰 영향을 미칩니다. 과도하게 프로비저닝된 인스턴스 하나가 전체 프로젝트의 경제성을 해칠 수 있습니다. 여기에 더해 AWS의 방대한 서비스와 설정 옵션은 초보자에게 복잡하게 느껴지며, CloudWatch 같은 모니터링 도구를 이해하고 활용하는 데 상당한 시간이 필요합니다.
하지만 개인 사용자들은 여러 현실적인 어려움에 직면합니다. 개인은 종종 여러 역할을 동시에 수행하기 때문에 리소스 모니터링과 비용 분석에 충분한 시간을 할애하기 어렵습니다. AWS Management Console에서 CloudWatch나 Cost Explorer를 탐색하며 필요한 정보를 찾는 과정은 번거롭고 비효율적입니다. 특정 S3 버킷의 비용을 확인하려면 여러 메뉴를 거쳐야 하며, 이 과정에서 중요한 정보를 놓칠 수 있습니다.
더 큰 문제는 전문성 부족입니다. 고급 모니터링 설정이나 최적화 전략을 구현할 전문 지식이 부족한 경우가 많습니다. 사용자 지정 알람을 설정하거나 적절한 인스턴스 유형을 선택하는 것조차 어려운 과제가 됩니다.
기업 조직이 마주하는 복잡성
기업 내 계정 관리 조직의 상황은 개인 사용자와는 완전히 다른 차원의 복잡성을 가집니다. 클라우드 운영 팀이나 재무 팀은 수백 또는 수천 개의 리소스를 관리하며, 조직 전체의 비용과 성능을 최적화하는 책임을 집니다.
대규모 비용 관리가 가장 중요한 과제입니다. 기업은 여러 부서와 프로젝트에 걸쳐 막대한 클라우드 지출을 발생시키며, 이를 통제하지 않으면 예산 초과로 이어질 수 있습니다. 개발 팀이 테스트 환경에서 불필요한 고성능 인스턴스를 방치하는 것만으로도 월별 비용이 급등할 수 있습니다.
규제 준수와 거버넌스도 중요한 요소입니다. 많은 기업은 내부 정책 및 GDPR, HIPAA 같은 외부 규제에 따라 리소스 사용과 비용을 엄격히 관리해야 합니다. 모니터링은 감사 기록과 보고서를 제공하여 이를 지원하는 필수 요소입니다. 동시에 비즈니스 크리티컬 애플리케이션의 다운타임을 방지하기 위한 지속적인 모니터링과 리소스 사용 패턴 분석을 통한 적절한 확장 전략 수립이 요구됩니다.
그러나 기업이 직면하는 어려움은 개인 사용자와는 다른 종류의 복잡성을 가집니다. 수많은 계정, 리전, 서비스를 관리하는 것은 매우 복잡합니다. 특정 리소스가 어떤 프로젝트에 속하는지, 비용이 어느 부서에 할당되어야 하는지 추적하는 데 많은 노력이 필요합니다.
조직 간 협업 문제도 심각합니다. 개발, 운영, 재무 팀 간의 소통 부족으로 인해 리소스 사용과 비용 최적화에 대한 책임 소재가 불분명해질 수 있습니다. 여기에 더해 대규모 환경에서는 모니터링 데이터의 양이 방대하여, 이를 분석하고 실행 가능한 인사이트로 변환하는 데 상당한 리소스가 필요합니다.
모든 사용자가 공통으로 겪는 Console 접속의 불편함
개인 사용자와 기업 모두에게 공통적인 문제는 Management Console에 반복적으로 접속해야 하는 불편함입니다. 콘솔은 강력한 도구이지만 여러 제약사항으로 인해 비효율적일 수 있습니다.
시간 소모가 가장 큰 문제입니다. 특정 리소스나 비용 데이터를 찾기 위해 여러 메뉴와 필터를 거쳐야 하며, 특히 여러 리전을 다룰 때 이 과정이 반복됩니다. 콘솔은 기술적 지식이 있는 사용자에게 최적화되어 있어, 비전문가에게는 직관적이지 않습니다. Cost Explorer에서 특정 서비스의 비용 추세를 분석하려면 적절한 필터와 차트를 설정하는 데 익숙해야 합니다.
실시간성 부족도 또 다른 문제입니다. 콘솔에서 데이터를 수동으로 새로 고침해야 하며, 자동화된 알림이나 대시보드가 없으면 중요한 변화를 놓칠 수 있습니다. 특정 리전의 모든 RDS 인스턴스 상태를 확인하려면 각 리전별로 콘솔을 이동하며 데이터를 수집해야 하며, 이 과정에서 실수가 발생할 가능성이 높습니다.
이러한 문제들을 해결하기 위해 AWS R-Assistant 챗봇을 설계하여 자연어 인터페이스와 통합 대시보드를 제공합니다. 이 솔루션은 콘솔 탐색의 번거로움을 줄이고, 개인 사용자와 기업 모두에게 실시간 인사이트와 실행 가능한 추천을 제공하는 것을 목표로 합니다.
AWS R-Assistant
앞서 언급한 클라우드 관리의 여러 단점들을 보완하며 빠르고 간편하게 클라우드의 자원과 비용을 관리할 수 있다면 어떨까요? 더 나아가 AI 기반의 최적화 방안 제시와 전문가 채팅 기능을 활용하여 자연어 기반으로 관리할 수 있다면 클라우드 관리는 완전히 새로운 차원의 경험이 될 것입니다. 이러한 아이디어에서 시작한 AWS R-Assistant를 소개드리도록 하겠습니다.
본 솔루션은 AWS 리소스 모니터링을 위한 챗봇으로, Streamlit, Boto3, Pandas, Plotly, 그리고 Amazon Bedrock의 Claude 3.5 Sonnet을 사용하여 구축되었습니다. 이 챗봇은 AWS 리소스 조회, 비용 분석, 메트릭 시각화, 최적화 추천을 자연어 인터페이스를 통해 제공합니다. 코드베이스는 리소스 수집, 비용 분석, AI 통합, 사용자 인터페이스와 같은 특정 기능을 처리하는 여러 구성 요소로 구조화되어 있습니다.
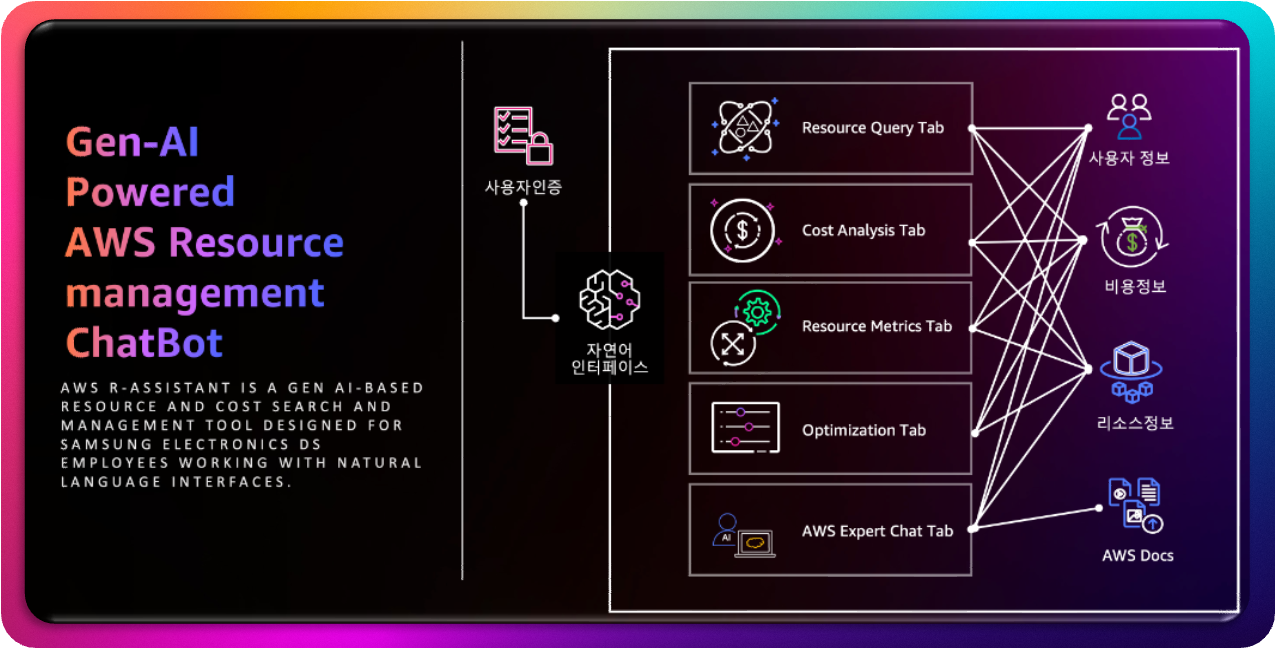
그림 1. AWS R-Assistant Overview
AWS R-Assistant 챗봇이 제공하는 핵심 장점
AWS R-Assistant 챗봇은 Streamlit 기반의 웹 애플리케이션으로, AWS 리소스와 비용 데이터를 한눈에 볼 수 있는 대시보드와 자연어 쿼리 기능을 제공합니다. 이 솔루션의 가장 큰 장점은 통합된 뷰를 제공한다는 것입니다. 리소스 상태, 비용 분석, 성능 메트릭, 최적화 추천을 단일 인터페이스에서 확인할 수 있어, AWS Management Console의 여러 탭과 메뉴를 오가는 번거로움을 완전히 없앱니다.
실시간 데이터 시각화도 중요한 특징입니다. Plotly를 활용한 대시보드는 서비스별 비용 분포를 파이 차트로, 리전별 비용을 바 차트로, 일별 비용 추세를 라인 차트로 직관적으로 보여줍니다. 사용자는 데이터를 새로 고침 없이 즉시 확인할 수 있어 실시간 의사결정이 가능합니다.
자연어 인터페이스는 이 솔루션의 가장 사용자 친화적이며 핵심적인 부분입니다. “us-west-2 리전의 모든 EC2 인스턴스 보기”와 같은 자연어 쿼리로 복잡한 필터 설정 없이 원하는 정보를 빠르게 조회할 수 있습니다. 이는 특히 비전문가나 바쁜 개인 사용자에게 매우 유용한 기능입니다.
AI 기반 인사이트는 Amazon Bedrock의 Claude 3.5 Sonnet을 통해 비용 데이터와 리소스 사용 패턴을 분석하여 주요 비용 요인, 이상 패턴, 최적화 기회를 상세히 설명합니다. 이는 기업의 계정 관리 팀이 전략적 결정을 내리는 데 큰 도움이 됩니다.
최적화 추천 기능은 낮은 CPU 사용률을 가진 EC2 인스턴스나 중지된 리소스를 식별하여 다운사이징 또는 종료를 제안하며, 잠재적 절감액을 추정합니다. 이는 개인 사용자가 예산을 절약하고, 기업이 대규모 비용을 최적화하는 데 실질적인 도움을 제공합니다.
무엇보다 이 챗봇의 가장 큰 가치는 시간 절약입니다. 콘솔에서 수동으로 데이터를 탐색하는 대신, 챗봇의 대시보드는 필요한 정보를 자동으로 수집하고 표시하여 시간과 노력을 크게 절약합니다. 맞춤형 필터링 기능을 통해 서비스 유형이나 리전별로 데이터를 필터링할 수 있어, 사용자는 관심 있는 정보만 빠르게 확인할 수 있습니다.
탭별 기능과 고유한 장점
이 챗봇은 다섯 개의 주요 탭으로 구성되어 있으며, 각 탭은 특정 기능을 제공하며 고유한 장점을 가지고 있습니다.
Resource Query 탭은 자연어 쿼리를 통해 AWS 리소스를 조회하고 상세 정보를 확인할 수 있는 기능을 제공합니다. 복잡한 콘솔 탐색 없이 “실행 중인 EC2 인스턴스 보기”와 같은 간단한 문장으로 원하는 데이터를 즉시 조회할 수 있습니다. 특히 개인 사용자가 특정 리소스의 상태나 태그를 빠르게 확인할 때 유용하며, 기업에서는 대규모 리소스 목록을 필터링하여 효율적으로 관리할 수 있습니다.
Cost Analysis 탭은 서비스별, 리전별, 일별 비용 데이터를 시각화하고 AI 기반 비용 인사이트를 제공합니다. 비용 분포와 추세를 한눈에 파악할 수 있는 차트를 통해 개인 사용자는 예산 초과를 방지하고, 기업은 주요 비용 요인을 식별하여 예산 할당을 최적화할 수 있습니다. AI 인사이트는 갑작스러운 비용 증가와 같은 비정상 패턴을 감지하여 사전 대응을 가능하게 합니다.
Resource Metrics 탭은 EC2, RDS, Lambda 등의 리소스 성능 메트릭을 표시하는 기능을 담당합니다. CPU 사용률, 메모리, 네트워크 등의 지표를 실시간으로 모니터링하여 성능 병목 현상을 빠르게 식별할 수 있습니다. 개인 사용자는 소규모 환경에서 리소스 활용도를 확인하여 비용을 절감할 수 있고, 기업은 크리티컬 애플리케이션의 안정성을 유지하는 데 유용하게 활용할 수 있습니다.
Optimization 탭은 리소스 사용 패턴을 분석하여 다운사이징, 종료 등의 최적화 추천을 제공하며, AI로 강화된 상세 전략을 제시합니다. 잠재적 절감액을 추정하여 개인 사용자는 불필요한 지출을 줄이고, 기업은 대규모 비용 절감을 실현할 수 있습니다. AI 전략은 구체적인 실행 계획과 주의점을 포함하여 추천의 실행 가능성을 높입니다.
AWS Expert Chat 탭은 AWS 관련 질문에 대해 AI 전문가가 컨텍스트 기반의 상세 답변을 제공하는 기능입니다. 개인 사용자는 “EC2 인스턴스 유형 선택 방법”과 같은 복잡한 AWS 개념을 쉽게 이해할 수 있고, 기업은 아키텍처 리뷰나 보안 강화와 같은 고급 주제에 대한 전문가 수준의 조언을 받을 수 있습니다. 채팅 기록 기능은 이전 대화를 참고하여 지속적인 학습과 문제 해결을 지원합니다.
이러한 각 탭별 장점 덕분에 AWS R-Assistant는 개인 사용자와 기업 모두에게 AWS 환경을 더 효율적이고 직관적으로 관리할 수 있는 강력한 도구를 제공합니다. 복잡한 클라우드 관리를 간단하고 직관적인 경험으로 변화시키는 것이 이 솔루션의 궁극적인 목표입니다.
심플하지만 강력한 아키텍처
놀랍게도 AWS R-Assistant의 아키텍처는 매우 간단하며 빠르고 간단하게 구축할 수 있습니다. 복잡해 보이는 기능들을 제공하지만, 실제 구성은 몇 가지 핵심 AWS 서비스들의 효율적인 연동으로 이루어져 있습니다.
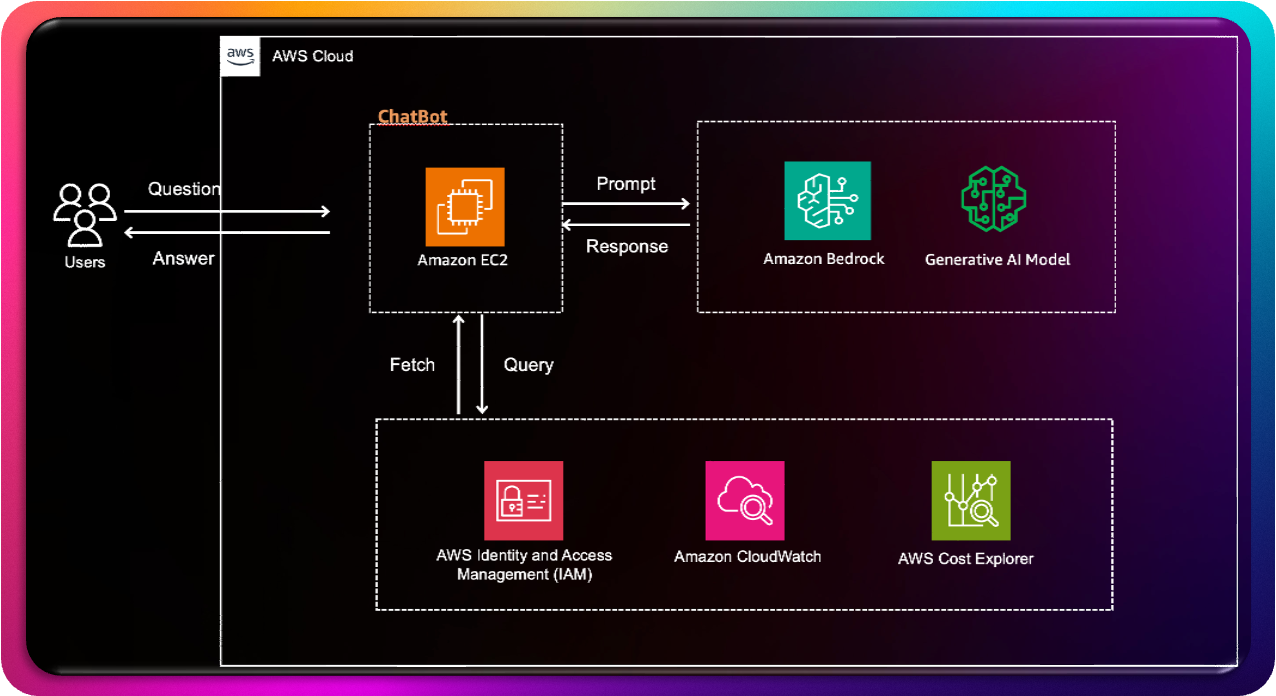
그림 2. Architecture
핵심 구성 서비스들의 역할
이 챗봇의 핵심은 Amazon EC2에서 실행되는 애플리케이션입니다. EC2 인스턴스는 챗봇 애플리케이션이 실행되는 서버 역할을 담당하며, 사용자의 질문을 받아 처리하고 필요한 경우 AI 모델에 프롬프트를 전달하는 중앙 허브 역할을 합니다.
Amazon Bedrock은 AWS의 생성형 AI 서비스로, EC2에서 받은 프롬프트를 기반으로 AI 모델을 호출하여 응답을 생성하는 핵심 엔진입니다. 실제로 답변을 생성하는 것은 Bedrock 내의 Claude 3.5 Sonnet 모델이 담당합니다. 이 모델은 사용자의 자연어 질문을 이해하고, 컨텍스트에 맞는 전문적인 답변을 생성합니다.
보안과 접근 제어는 AWS Identity and Access Management (IAM)이 담당합니다. IAM은 리소스 접근 제어 및 인증과 인가 관리를 통해 챗봇이 필요한 AWS 리소스에 안전하게 접근할 수 있도록 보장합니다.
시스템의 안정성과 성능 관리는 Amazon CloudWatch가 담당합니다. CloudWatch는 시스템 모니터링 및 로그 관리를 통해 챗봇의 상태를 실시간으로 추적하고, 문제가 발생할 경우 빠른 대응을 가능하게 합니다.
마지막으로 AWS Cost Explorer는 비용 분석 및 관리 도구로, 챗봇이 제공하는 비용 분석 기능의 데이터 소스 역할을 합니다.

그림 3. AWS R-Assistant의 기능 요약
데이터 흐름의 워크플로우
이 시스템의 데이터 흐름은 매우 직관적입니다. 사용자가 챗봇에 질문을 보내면, Amazon EC2 인스턴스가 이 질문을 받아 처리합니다. EC2는 받은 질문을 적절한 프롬프트로 가공하여 Amazon Bedrock에 전달합니다.
Bedrock은 내부의 생성형 AI 모델인 Claude 3.5 Sonnet을 통해 답변을 생성하고, 이 응답을 다시 EC2로 반환합니다. EC2는 받은 응답을 사용자가 이해하기 쉬운 형태로 가공하여 최종 답변을 사용자에게 전달합니다.
이 모든 과정에서 EC2는 IAM을 통해 필요한 권한을 확인하고, CloudWatch로 로그 및 모니터링 데이터를 전송하며, Cost Explorer와 연동하여 비용 관련 정보를 관리합니다. 이러한 백그라운드 프로세스들이 사용자에게는 보이지 않지만, 시스템의 안정성과 보안을 보장하는 중요한 역할을 담당합니다.
단순함 속의 파워
이처럼 간단하지만 파워풀한 AWS 서비스들의 연동을 통하여 자연어로 편리하게 클라우드 리소스를 관리할 수 있습니다. 복잡한 아키텍처 없이도 몇 가지 핵심 서비스만으로 강력한 AI 기반 클라우드 관리 솔루션을 구축할 수 있다는 것이 AWS 클라우드의 진정한 가치입니다. 이러한 단순함은 개발과 유지보수를 용이하게 하며, 확장성과 안정성을 동시에 보장합니다.
AWS 서비스 연동 및 챗봇 구축하기
이제 AWS R-Assistant 구축을 위한 코드를 부분별로 상세히 살펴보겠습니다. 이 코드는 AWS 서비스와 상호작용하여 리소스, 비용, 메트릭 데이터를 수집하는 AWSResourceCollector 클래스를 중심으로 구성됩니다. 주요 구성 요소와 기능을 코드 설명과 함께 자세히 살펴보겠습니다.
클래스 초기화 및 설정
AWSResourceCollector 클래스의 초기화는 전체 시스템의 기반을 마련하는 중요한 단계입니다. 이 과정에서 boto3를 사용하여 CloudWatch, EC2, RDS, Lambda, S3, Cost Explorer 등 다양한 AWS 서비스에 대한 클라이언트를 초기화합니다.
핵심적인 코드 라인들을 살펴보면, self.cloudwatch = boto3.client(‘cloudwatch’)를 통해 CPU 사용률과 같은 성능 메트릭을 가져오기 위한 CloudWatch 클라이언트를 생성합니다. 이는 리소스 모니터링의 핵심 구성 요소로, 실시간 성능 데이터를 수집하는 역할을 담당합니다.
비용 관리를 위해서는 self.ce = boto3.client(‘ce’)를 통해 Cost Explorer 클라이언트를 초기화합니다. 이 클라이언트는 AWS 계정의 비용 데이터를 조회하고 분석하는 데 필수적인 도구입니다.
특히 주목할 점은 self.service_mapping의 구현입니다. 이는 내부 서비스 이름을 AWS Cost Explorer의 서비스 이름에 매핑하여 정확한 비용 필터링을 보장하는 중요한 역할을 합니다. 서비스 이름의 불일치로 인한 데이터 누락을 방지하고, 정확한 비용 분석을 가능하게 합니다.
리전 관리도 중요한 부분입니다. self.regions 설정을 통해 모든 사용 가능한 AWS 리전을 동적으로 가져오려 시도하며, 오류 발생 시 기본 리전 목록으로 대체하여 애플리케이션의 안정성을 유지합니다. 이러한 방식은 새로운 리전이 추가되거나 접근 권한이 변경될 때도 시스템이 안정적으로 작동할 수 있도록 보장합니다.
이러한 초기화 과정은 단순해 보이지만, 실제로는 다양한 AWS 서비스 간의 복잡한 상호작용을 관리하고, 오류 상황에 대비한 안정성 메커니즘을 구축하는 핵심적인 단계입니다. 각 클라이언트의 적절한 초기화와 설정은 이후 모든 기능의 정상적인 작동을 보장하는 기반이 됩니다.
class AWSResourceCollector:
def __init__(self):
print("Initializing AWSResourceCollector")
self.cloudwatch = boto3.client('cloudwatch')
self.ec2 = boto3.client('ec2')
self.rds = boto3.client('rds')
self.lambda_client = boto3.client('lambda')
self.s3 = boto3.client('s3')
self.ce = boto3.client('ce')
self.service_mapping = {
'EC2': 'Amazon Elastic Compute Cloud - Compute',
'RDS': 'Amazon Relational Database Service',
'Lambda': 'AWS Lambda',
'S3': 'Amazon Simple Storage Service'
}
# 모든 리전 목록 가져오기
try:
self.regions = [region['RegionName'] for region in self.ec2.describe_regions()['Regions']]
except Exception as e:
print(f"Error getting regions: {str(e)}")
self.regions = ['us-east-1', 'us-west-2', 'ap-northeast-2'] # 기본 리전
print("AWSResourceCollector initialized")CloudWatch 메트릭 수집
CloudWatch 메트릭 수집은 AWS R-Assistant의 핵심 기능 중 하나로, 특정 리소스의 성능 메트릭을 지난 1시간 동안 수집합니다. 이 기간은 period 매개변수를 통해 사용자가 원하는 대로 지정할 수 있어 유연한 모니터링이 가능합니다.
메트릭 수집 과정에서 가장 중요한 부분은 지역별 CloudWatch 클라이언트 생성입니다. cloudwatch = boto3.client(‘cloudwatch’, region_name=region)를 통해 리소스가 위치한 지역에 맞는 클라이언트를 생성하여 관련 메트릭을 정확하게 가져옵니다. 이는 AWS의 지역별 리소스 격리 특성을 고려한 필수적인 구현입니다.
메트릭 수집의 핵심은 metric_configs 설정에 있습니다. 이 설정은 서비스별로 수집할 메트릭을 정의하는 역할을 담당합니다. 예를 들어, EC2 인스턴스의 경우 CPUUtilization 메트릭을 통해 CPU 사용률을 모니터링하고, RDS 인스턴스의 경우 DatabaseConnections 메트릭을 통해 데이터베이스 연결 상태를 추적합니다. 이러한 서비스별 메트릭 정의는 각 리소스 타입에 가장 적합한 모니터링 지표를 제공합니다.
실제 메트릭 데이터 수집은 response = cloudwatch.get_metric_statistics(…) 호출을 통해 이루어집니다. 이 함수는 지정된 시간 범위에 대한 평균 메트릭 값을 가져오며, response[‘Datapoints’][-1]를 통해 최신 데이터 포인트만 사용하도록 구현되어 있습니다. 이러한 방식은 실시간에 가까운 모니터링을 제공하면서도 데이터 처리 부하를 최소화합니다.
시스템의 안정성을 위해 포괄적인 오류 처리가 구현되어 있습니다. 메트릭 수집 중 오류가 발생할 경우 함수는 비어 있는 딕셔너리를 반환하도록 하여 애플리케이션 전체의 안정성을 유지합니다. 이는 특정 리소스의 메트릭 수집이 실패하더라도 다른 기능들이 정상적으로 작동할 수 있도록 보장하는 중요한 안전장치입니다.
def get_cloudwatch_metrics(self, resource_id, service_type, region, period=3600):
"""CloudWatch 메트릭 데이터 수집"""
try:
cloudwatch = boto3.client('cloudwatch', region_name=region)
metrics_data = {}
end_time = datetime.utcnow()
start_time = end_time - timedelta(hours=1)
metric_configs = {
'EC2': {
'namespace': 'AWS/EC2',
'dimension_name': 'InstanceId',
'metrics': [
('CPUUtilization', 'Percent'),
('NetworkIn', 'Bytes'),
('NetworkOut', 'Bytes'),
('DiskReadBytes', 'Bytes'),
('DiskWriteBytes', 'Bytes')
]
},
'RDS': {
'namespace': 'AWS/RDS',
'dimension_name': 'DBInstanceIdentifier',
'metrics': [
('CPUUtilization', 'Percent'),
('FreeableMemory', 'Bytes'),
('DatabaseConnections', 'Count'),
('ReadIOPS', 'Count/Second'),
('WriteIOPS', 'Count/Second')
]
},
'Lambda': {
'namespace': 'AWS/Lambda',
'dimension_name': 'FunctionName',
'metrics': [
('Invocations', 'Count'),
('Duration', 'Milliseconds'),
('Errors', 'Count'),
('Throttles', 'Count')
]
}
}
if service_type in metric_configs:
config = metric_configs[service_type]
dimension = [{'Name': config['dimension_name'], 'Value': resource_id}]
for metric_name, unit in config['metrics']:
try:
response = cloudwatch.get_metric_statistics(
Namespace=config['namespace'],
MetricName=metric_name,
Dimensions=dimension,
StartTime=start_time,
EndTime=end_time,
Period=period,
Statistics=['Average']
)
if response['Datapoints']:
metrics_data[metric_name] = {
'value': round(response['Datapoints'][-1]['Average'], 2),
'unit': unit
}
except Exception as e:
print(f"Error getting metric {metric_name}: {str(e)}")
return metrics_data
except Exception as e:
print(f"Error getting CloudWatch metrics: {str(e)}")
return {}리소스 비용 조회
리소스 비용 조회 기능은 AWS Cost Explorer를 활용하여 지난 30일 동안 특정 리소스의 비용을 조회하는 없어서는 안 될 기능입니다. 이 기능은 사용자가 비용 최적화 결정을 내릴 수 있도록 정확하고 상세한 비용 정보를 제공합니다. 비용 조회의 시작점은 적절한 시간 범위 설정입니다. TimePeriod={‘Start’: …, ‘End’: …}을 통해 비용 데이터를 위한 30일 기간을 지정합니다. 이 기간은 필요에 따라 사용자가 원하는 대로 지정할 수 있어 유연한 비용 분석이 가능합니다. 30일이라는 기본 기간은 충분한 데이터를 제공하면서도 최신 비용 트렌드를 파악하기에 적합한 균형점을 제공합니다. 정확한 비용 할당을 위해서는 세밀한 필터링이 필수입니다. Filter={‘And’: […]}를 통해 지역 및 서비스 유형별로 비용을 필터링하여 정확한 비용 할당을 보장합니다. 이러한 필터링은 다양한 리전과 서비스에 분산된 리소스들의 비용을 정확히 추적하고, 각 리소스의 실제 비용 기여도를 정확히 파악할 수 있도록 합니다. AWS Cost Explorer의 복잡한 응답 구조를 처리하는 것도 중요한 부분입니다. Cost Explorer는 다양한 형태의 데이터를 반환할 수 있으며, 때로는 예상치 못한 응답 구조나 빈 데이터를 반환할 수 있습니다. 이러한 상황에 대비하여 포괄적인 오류 처리가 구현되어 있습니다. 시스템 안정성을 위해 오류 발생 시 또는 데이터가 없는 경우 0.0을 반환하도록 구현되어 있습니다. 이는 애플리케이션 충돌을 방지하고, 비용 데이터가 없는 리소스에 대해서도 일관된 사용자 경험을 제공합니다. 이러한 방식은 특히 새로 생성된 리소스나 아직 비용이 발생하지 않은 리소스에 대해 유용합니다.
def get_resource_cost(self, resource_id, service_type, region):
"""리소스별 비용 조회"""
try:
end_date = datetime.now()
start_date = end_date - timedelta(days=30)
response = self.ce.get_cost_and_usage(
TimePeriod={
'Start': start_date.strftime('%Y-%m-%d'),
'End': end_date.strftime('%Y-%m-%d')
},
Granularity='MONTHLY',
Metrics=['UnblendedCost'],
Filter={
'And': [
{'Dimensions': {'Key': 'REGION', 'Values': [region]}},
{'Dimensions': {'Key': 'SERVICE', 'Values': [self.service_mapping[service_type]]}}
]
}
)
if response['ResultsByTime']:
return float(response['ResultsByTime'][0]['Total']['UnblendedCost']['Amount'])
return 0.0
except Exception as e:
print(f"Error getting resource cost: {str(e)}")
return 0.0리소스 데이터 수집 (예: EC2)
리소스 데이터 수집 기능은 AWS R-Assistant의 핵심 중 하나로, 모든 리전의 EC2 인스턴스에 대한 상세 정보를 메트릭과 비용을 포함하여 종합적으로 수집합니다. 이 과정은 단순한 데이터 조회를 넘어서 실용적인 인사이트를 제공할 수 있는 풍부한 정보를 구성하는 복잡한 과정입니다. 데이터 수집의 시작점은 ec2_client.describe_instances() 호출입니다. 이 함수는 특정 리전의 모든 EC2 인스턴스 데이터를 가져오는 기본적인 역할을 담당합니다. 하지만 AWS의 응답 구조는 복잡하게 중첩되어 있어, 실제 인스턴스 정보에 접근하기 위해서는 중첩 루프를 통해 예약과 인스턴스를 개별적으로 처리해야 합니다. 단순한 기본 정보 수집을 넘어서, 각 인스턴스의 데이터를 성능 메트릭과 비용 정보로 보강하는 과정이 핵심입니다. metrics = self.get_cloudwatch_metrics(…)를 통해 실시간 성능 데이터를 수집하고, cost = self.get_resource_cost(…)를 통해 비용 정보를 통합합니다. 이러한 데이터 보강 과정은 단순한 리소스 목록을 실제 운영에 유용한 종합적인 정보로 변환시킵니다. 수집된 데이터는 pandas.DataFrame 형태로 반환됩니다. 이는 Streamlit 앱에서 데이터를 쉽게 조작하고 표시할 수 있도록 하는 중요한 설계 결정입니다. DataFrame 형태의 데이터는 필터링, 정렬, 그룹화 등 다양한 데이터 처리 작업을 효율적으로 수행할 수 있게 해줍니다. 시스템의 안정성을 위해 다층적인 오류 처리가 구현되어 있습니다. 인스턴스 수준, 리전 수준, 전체 수준에서 강력한 오류 처리를 통해 부분적 실패가 전체 프로세스를 중단시키지 않도록 보장합니다. 이는 특히 대규모 환경에서 일부 리소스에 접근 권한이 없거나 일시적인 네트워크 문제가 발생할 때 전체 시스템이 계속 작동할 수 있도록 하는 중요한 안전장치입니다. 이러한 패턴은 EC2에만 국한되지 않습니다. RDS, Lambda, S3에 대한 유사한 메서드들도 동일한 패턴을 따릅니다. 즉, 리전별 데이터 수집, 메트릭 보강, 비용 통합이라는 일관된 접근 방식을 통해 각 AWS 서비스의 특성을 고려하면서도 통일된 데이터 구조를 제공합니다. 이러한 일관성은 코드의 유지보수성을 높이고, 새로운 서비스 추가 시에도 동일한 패턴을 적용할 수 있도록 합니다.
def collect_ec2_data(self):
"""EC2 인스턴스 데이터 수집"""
print("Collecting EC2 data...")
try:
ec2_data = []
for region in self.regions:
try:
ec2_client = boto3.client('ec2', region_name=region)
response = ec2_client.describe_instances()
for reservation in response['Reservations']:
for instance in reservation['Instances']:
try:
metrics = self.get_cloudwatch_metrics(
instance['InstanceId'],
'EC2',
region
)
cost = self.get_resource_cost(
instance['InstanceId'],
'EC2',
region
)
instance_data = {
'resource_id': instance['InstanceId'],
'service_type': 'EC2',
'region': region,
'status': instance['State']['Name'],
'creation_date': instance['LaunchTime'].strftime('%Y-%m-%d %H:%M:%S'),
'last_modified': datetime.now().strftime('%Y-%m-%d %H:%M:%S'),
'tags': json.dumps({tag['Key']: tag['Value'] for tag in instance.get('Tags', [])}),
'cost': cost,
'details': {
'instance_type': instance['InstanceType'],
'private_ip': instance.get('PrivateIpAddress', ''),
'public_ip': instance.get('PublicIpAddress', ''),
'vpc_id': instance.get('VpcId', ''),
'subnet_id': instance.get('SubnetId', ''),
'metrics': metrics
}
}
ec2_data.append(instance_data)
except Exception as e:
print(f"Error processing EC2 instance {instance['InstanceId']}: {str(e)}")
continue
except Exception as e:
print(f"Error processing region {region}: {str(e)}")
continue
return pd.DataFrame(ec2_data)
except Exception as e:
print(f"Error collecting EC2 data: {str(e)}")
return pd.DataFrame()비용 분석 및 예측
비용 분석 및 예측 기능은 서비스별, 리전별, 일별로 비용 데이터를 집계하여 포괄적인 분석을 제공합니다. 이 기능은 단순한 비용 조회를 넘어서 실질적인 비용 최적화 인사이트를 제공하는 핵심 도구입니다. 비용 분석의 핵심은 적절한 데이터 그룹화에 있습니다. GroupBy=[{‘Type’: ‘DIMENSION’, ‘Key’: ‘SERVICE’}]를 통해 명확한 분류를 위해 비용 데이터를 서비스별로 그룹화합니다. 이러한 그룹화는 전체 비용 구조를 이해하고 주요 비용 발생 원인을 식별하는 데 필수적입니다. 사용자는 어떤 서비스가 가장 많은 비용을 발생시키는지, 어떤 리전에서 예상보다 높은 비용이 발생하는지 한눈에 파악할 수 있습니다. 데이터 시각화의 편의성을 위해 시스템은 DataFrame의 딕셔너리를 반환합니다. 이는 다양한 차원에서 비용을 쉽게 시각화할 수 있도록 하는 중요한 설계 결정입니다. 서비스별 분석, 리전별 분석, 일별 추세 분석 등 각각의 관점에서 비용을 조회하고 시각화할 수 있어, 사용자는 자신의 요구사항에 맞는 분석 방식을 선택할 수 있습니다. 비용 예측 기능은 단순한 과거 데이터 조회를 넘어서는 진보된 기능입니다. predict_costs 메서드는 과거 데이터를 기반으로 미래 비용을 예측하기 위해 간단한 선형 회귀 접근 방식을 사용합니다. 이 방법은 현재 프로토타입 단계에서는 충분한 예측 정확도를 제공하지만, 향후 더 정교한 모델로 향상될 수 있는 확장 가능한 기반을 제공합니다. 선형 회귀 모델의 선택은 구현의 단순성과 해석의 용이성을 고려한 결정입니다. 비용 데이터의 경우 일반적으로 시간에 따른 선형적 증가나 감소 패턴을 보이는 경우가 많아, 초기 단계에서는 충분히 유용한 예측을 제공할 수 있습니다. 하지만 계절성이나 복잡한 사용 패턴을 고려한 더 정교한 모델링이 필요한 경우, 이 기반 위에 ARIMA나 시계열 분석과 같은 고급 기법을 적용할 수 있습니다. 이러한 비용 분석 및 예측 기능은 개인 사용자에게는 예산 계획과 비용 최적화에 도움을 주고, 기업 사용자에게는 전략적 의사결정을 위한 데이터 기반 인사이트를 제공합니다. 특히 미래 비용 예측은 예산 수립과 리소스 계획에 매우 유용한 정보를 제공합니다.
def get_cost_analysis(self):
"""비용 분석 데이터 수집"""
print("Getting cost analysis...")
try:
end_date = datetime.now()
start_date = end_date - timedelta(days=30)
# 서비스별 비용
service_response = self.ce.get_cost_and_usage(
TimePeriod={
'Start': start_date.strftime('%Y-%m-%d'),
'End': end_date.strftime('%Y-%m-%d')
},
Granularity='MONTHLY',
Metrics=['UnblendedCost'],
GroupBy=[{'Type': 'DIMENSION', 'Key': 'SERVICE'}]
)
service_costs = pd.DataFrame([
{
'SERVICE': group['Keys'][0],
'cost': float(group['Metrics']['UnblendedCost']['Amount'])
}
for group in service_response['ResultsByTime'][0]['Groups']
])
# 리전별 및 일별 비용에 대한 유사한 코드
# ...
return {
'service_costs': service_costs,
'region_costs': region_costs,
'daily_costs': daily_costs_df
}
except Exception as e:
print(f"Error in cost analysis: {str(e)}")
return None최적화 추천
최적화 추천 기능은 AWS R-Assistant의 가장 실용적인 기능 중 하나로, 리소스 사용 패턴을 분석하여 실행 가능한 비용 절감 추천을 제공합니다. 이 기능은 단순한 모니터링을 넘어서 실질적인 비용 절감 기회를 발견하고 구체적인 실행 방안을 제시하는 핵심 도구입니다. 최적화 추천의 핵심 알고리즘은 CPU 사용률 분석에 기반합니다. 시스템은 낮은 CPU 사용률을 보이는 인스턴스를 식별하여 다운사이징을 제안합니다. 구체적으로 cpu_util < 20인 인스턴스를 대상으로 하며, 이러한 인스턴스들은 현재 할당된 컴퓨팅 리소스를 충분히 활용하지 못하고 있다는 것을 의미합니다. 시스템은 이러한 경우 현재 비용의 50%를 잠재적 절감액으로 추정합니다. 이러한 추정은 일반적으로 한 단계 낮은 인스턴스 유형으로 다운사이징할 때 약 50%의 비용 절감이 가능하다는 AWS의 인스턴스 가격 체계를 반영한 것입니다. 예를 들어, m5.large 인스턴스를 m5.medium으로 변경하면 대략 50%의 비용 절감이 가능합니다. 더 적극적인 최적화 기회로는 중지된 인스턴스의 식별이 있습니다. 시스템은 중지된 상태의 인스턴스를 찾아내어 완전한 종료를 통해 절감을 극대화할 것을 제안합니다. 중지된 인스턴스는 컴퓨팅 비용은 발생하지 않지만 스토리지 비용은 계속 발생하므로, 더 이상 필요하지 않은 인스턴스는 완전히 종료하는 것이 비용 최적화에 유리합니다. 실용성을 고려하여 모든 추천 결과는 DataFrame 형태로 반환됩니다. 이는 UI에 쉽게 통합할 수 있도록 하여 사용자가 추천 내용을 직관적으로 확인하고 실행할 수 있도록 합니다. DataFrame에는 리소스 정보, 현재 사용률, 추천 액션, 예상 절감액 등의 정보가 구조화되어 포함되어 있어 사용자가 정보에 기반한 결정을 내릴 수 있도록 지원합니다. 이러한 최적화 추천은 개인 사용자에게는 월별 AWS 비용을 크게 줄일 수 있는 실질적인 방법을 제공하고, 기업 사용자에게는 대규모 비용 절감 기회를 체계적으로 식별할 수 있는 도구를 제공합니다. 특히 지속적인 모니터링과 추천을 통해 클라우드 비용 최적화를 자동화할 수 있는 기반을 마련합니다.
def get_optimization_recommendations(self):
"""리소스 최적화 추천"""
print("Getting optimization recommendations...")
try:
recommendations = []
# EC2 인스턴스 분석
ec2_data = self.collect_ec2_data()
if not ec2_data.empty:
for _, instance in ec2_data.iterrows():
metrics = instance['details'].get('metrics', {})
# CPU 사용률 기반 추천
if 'CPUUtilization' in metrics:
cpu_util = metrics['CPUUtilization']['value']
if cpu_util < 20:
recommendations.append({
'resource_id': instance['resource_id'],
'service_type': 'EC2',
'recommendation_type': 'Downsizing',
'reason': f'Low CPU utilization ({cpu_util}%)',
'potential_savings': instance['cost'] * 0.5,
'action': 'Consider using a smaller instance type'
})
# 중지된 인스턴스 확인
if instance['status'] == 'stopped':
recommendations.append({
'resource_id': instance['resource_id'],
'service_type': 'EC2',
'recommendation_type': 'Termination',
'reason': 'Instance is stopped',
'potential_savings': instance['cost'],
'action': 'Consider terminating if not needed'
})
# RDS 인스턴스 분석
rds_data = self.collect_rds_data()
if not rds_data.empty:
for _, instance in rds_data.iterrows():
metrics = instance['details'].get('metrics', {})
# 연결 수 기반 추천
if 'DatabaseConnections' in metrics:
connections = metrics['DatabaseConnections']['value']
if connections < 5:
recommendations.append({
'resource_id': instance['resource_id'],
'service_type': 'RDS',
'recommendation_type': 'Downsizing',
'reason': f'Low number of connections ({connections})',
'potential_savings': instance['cost'] * 0.4,
'action': 'Consider using a smaller instance class'
})
print(f"Recommendations generated: {recommendations}")
return pd.DataFrame(recommendations)
except Exception as e:
print(f"Error generating recommendations: {str(e)}")
return pd.DataFrame()Bedrock 활용하기
이 코드의 가장 중요한 부분은 자연어 처리 및 AI 기반 인사이트를 위한 Amazon Bedrock 활용입니다. BedrockService 클래스는 모델 호출 및 다양한 AI 작업을 처리하는 핵심 구성 요소입니다. Amazon Bedrock은 자연어 인터페이스를 통한 사용자 친화적인 경험을 제공하는 이 챗봇의 심장과 같은 가장 중요한 요소로 볼 수 있습니다.
초기화 및 모델 호출
Bedrock 서비스의 초기화는 안정적이고 일관된 AI 응답을 보장하기 위한 세심한 설정으로 시작됩니다. Bedrock 클라이언트를 설정하고 텍스트 생성을 위해 Claude 3 Sonnet 모델을 호출하는 메서드를 제공하는 것이 핵심 목적입니다. 특히 주목할 점은 self.model_id = ‘anthropic.claude-3-sonnet-20240229-v1:0’를 통해 Claude 모델의 특정 버전을 지정한다는 것입니다. 이는 일관된 응답 품질을 보장하고, 모델 업데이트로 인한 예상치 못한 동작 변화를 방지하는 중요한 설계적 부분입니다. AI 응답의 품질을 조절하는 핵심 매개변수는 temperature설정입니다. 이 값은 응답의 창의성과 정확성 간의 균형을 맞추는 중요한 역할을 담당합니다. 0.1이라는 값은 사실적인 정보 제공에 중점을 둔 설정이지만 충분한 유연성을 허용하면서도 사실적인 정보 제공을 보장하는 최적의 균형점으로 필요에 따라 혹은 사용 사례에 맞게 낮추거나 높이며 조정할 수 있습니다. 시스템 안정성을 위해 포괄적인 오류 처리가 구현되어 있습니다. Bedrock 호출이 실패하더라도 애플리케이션 전체의 안정성을 유지할 수 있도록 보장하여, AI 서비스의 일시적인 문제가 전체 시스템에 영향을 미치지 않도록 합니다.
class BedrockService:
def __init__(self):
self.bedrock_runtime = boto3.client(
service_name='bedrock-runtime',
region_name='us-west-2'
)
self.model_id = 'anthropic.claude-3-sonnet-20240229-v1:0'
def invoke_model(self, prompt, max_tokens=1000, temperature=0.1):
try:
body = {
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": max_tokens,
"messages": [
{
"role": "user",
"content": prompt
}
],
"temperature": temperature
}
response = self.bedrock_runtime.invoke_model(
modelId=self.model_id,
body=json.dumps(body)
)
response_body = json.loads(response['body'].read())
return response_body['content'][0]['text']
except Exception as e:
print(f"Error invoking Bedrock model: {str(e)}")
return None자연어 쿼리 처리
자연어 쿼리 처리는 이 시스템의 가장 인상적인 기능 중 하나입니다. 사용자의 자연어 쿼리를 리소스 조회를 위한 구조화된 필터 파라미터로 변환하는 복잡한 과정을 담당합니다.
핵심은 정확한 프롬프트 설계에 있습니다. 프롬프트는 모델이 JSON 객체를 반환하도록 명시적으로 지시하여 구조화된 출력을 보장합니다. 이는 자연어의 자유로운 형태를 시스템이 처리할 수 있는 구조화된 데이터로 변환하는 중요한 다리 역할을 합니다.
JSON 파싱과 오류 처리는 이 과정의 안정성을 보장하는 핵심 요소입니다. 관련 데이터를 정확히 추출하며, 파싱 실패 시에는 기본값으로 대체하여 사용자 경험의 연속성을 유지합니다. 이러한 방식은 AI 응답의 불확실성을 실용적인 시스템에서 관리하는 효과적인 방법을 보여줍니다.
def process_natural_language_query(self, query):
try:
prompt = f"""
Convert this natural language query to AWS resource filter parameters.
Query: {query}
Return only a JSON object with these exact fields:
{{
"service_type": "EC2" or "RDS" or "Lambda" or "S3",
"region": "region name if specified, otherwise null",
"status": "status if specified, otherwise null"
}}
"""
response = self.invoke_model(prompt, max_tokens=500, temperature=0)
if response:
try:
# JSON 문자열에서 실제 JSON 객체 부분만 추출
json_str = response.strip()
if '{' in json_str and '}' in json_str:
json_str = json_str[json_str.find('{'):json_str.rfind('}')+1]
return json.loads(json_str)
except json.JSONDecodeError as e:
print(f"Error parsing JSON response: {str(e)}")
return {
"service_type": None,
"region": None,
"status": None
}
return None
except Exception as e:
print(f"Error in process_natural_language_query: {str(e)}")
return None비용 인사이트 및 추천 강화
Bedrock의 자연어 기능을 활용한 비용 인사이트 제공은 단순한 데이터 표시를 넘어서는 지능적인 분석을 가능하게 합니다. 이 기능은 비용 데이터를 분석하고 상세한 인사이트를 제공하여 사용자의 의사결정을 지원합니다.
데이터 처리 과정에서 DataFrame을 딕셔너리로 변환하는 것은 프롬프트에서 JSON 직렬화를 쉽게 처리하기 위한 실용적인 접근입니다. 이를 통해 복잡한 비용 데이터를 AI 모델이 이해할 수 있는 형태로 효율적으로 변환합니다.
비용 분석의 특성에 맞춰 temperature=0.1로 설정하여 더 사실적이고 분석적인 응답을 보장합니다. 이는 비용 분석이라는 중요한 비즈니스 의사결정 영역에서 정확성과 신뢰성을 우선시하는 신중한 선택입니다.
구조화된 프롬프트 설계는 모델이 비용 분석의 특정 측면을 체계적으로 다루도록 보장합니다. 이를 통해 일관되고 포괄적인 분석 결과를 제공할 수 있습니다.
enhance_recommendations와 chat_with_aws_expert 같은 추가 메서드들도 동일한 Bedrock 기반 접근 방식을 활용합니다. 각각 상세한 최적화 전략 제공과 전문가 수준의 Q&A 기능을 담당하여, 전체 시스템이 단순한 모니터링 도구를 넘어서 지능적인 클라우드 관리 어시스턴트로 기능할 수 있도록 합니다.
def generate_cost_insights(self, cost_data):
try:
cost_data_dict = {
'service_costs': cost_data['service_costs'].to_dict(orient='records'),
'region_costs': cost_data['region_costs'].to_dict(orient='records'),
'daily_costs': cost_data['daily_costs'].to_dict(orient='records') if 'daily_costs' in cost_data else []
}
prompt = f"""
다음 AWS 비용 데이터를 분석하여 상세한 인사이트를 제공해주세요:
{json.dumps(cost_data_dict)}
다음 항목들에 대해 분석해주세요:
1. 주요 비용 발생 요인
2. 비정상적인 패턴이나 급격한 비용 증가
3. 비용 최적화가 가능한 영역
4. 전반적인 비용 추세와 향후 예측
분석 결과를 다음과 같은 형식으로 제공해주세요:
### 주요 비용 발생 요인
- [구체적인 분석 내용]
### 이상 패턴 분석
- [비정상적인 비용 패턴 설명]
### 최적화 기회
- [구체적인 최적화 방안]
### 비용 추세
- [추세 분석 및 예측]
"""
return self.invoke_model(prompt, max_tokens=1500, temperature=0.1)
except Exception as e:
print(f"Error generating cost insights: {str(e)}")
return "현재 비용 분석을 생성할 수 없습니다."Streamlit 활용하여 Chatbot App UI 만들기
이 코드는 Streamlit 웹 애플리케이션을 구축하여 모든 백엔드 기능을 대화형 UI로 통합하는 사용자 인터페이스 계층을 담당합니다. 복잡한 AWS 관리 기능들을 직관적이고 사용하기 쉬운 웹 인터페이스로 제공하는 것이 핵심 목표입니다.
성능 최적화를 위한 초기화 및 캐싱
성능 향상과 API 호출 최적화를 위해 AWS 리소스 데이터를 5분 동안 캐싱하는 시스템이 구현되어 있습니다. 이는 사용자 경험을 개선하면서도 AWS API 사용량을 효율적으로 관리하는 중요한 기능입니다.
핵심 설정인 ttl=300은 5분 캐시 만료를 설정하여 데이터의 신선도와 성능 간의 적절한 균형을 맞춥니다. 이 시간은 AWS 리소스의 변경 빈도와 사용자의 실시간 정보 요구사항을 고려하여 신중하게 선택된 값입니다. 너무 짧으면 성능 이점이 줄어들고, 너무 길면 오래된 정보를 제공할 위험이 있기 때문입니다.
비용 분석, 예측, 추천 기능에도 동일한 캐싱 메커니즘이 적용되어 있습니다. 이러한 일관된 캐싱 전략은 전체 애플리케이션의 응답 속도를 크게 향상시키고, 특히 대규모 AWS 환경에서 데이터 수집에 소요되는 시간을 현저히 줄여줍니다.
@st.cache_data(ttl=300)
def fetch_aws_resources():
debug_print("Fetching AWS resources...")
collector = AWSResourceCollector()
resources = collector.collect_all_resources()
return resources체계적인 UI 구조 및 탭
사용자 인터페이스의 핵심은 다양한 기능을 위한 다중 탭 인터페이스 구조입니다. 이는 복잡한 AWS 관리 기능들을 논리적으로 분류하고, 사용자가 원하는 기능에 빠르게 접근할 수 있도록 돕는 중요한 설계 결정입니다.
5개의 주요 탭이 정의되어 있으며, 각 탭은 AWS 관리의 특정 측면에 초점을 맞춰 사용자 친화적인 경험을 보장합니다. 이러한 분리는 기능별 전문화를 통해 각 영역에서 최적화된 사용자 경험을 제공하면서도, 전체적으로는 통합된 관리 환경을 유지합니다.
st.title("AWS Resource Monitor")
tab1, tab2, tab3, tab4, tab5 = st.tabs([
"Resource Query",
"Cost Analysis",
"Resource Metrics",
"Optimization",
"AWS Expert Chat"
])자연어 기반 리소스 쿼리 탭
리소스 쿼리 탭은 사용자가 Bedrock을 통해 처리되는 자연어로 리소스를 조회할 수 있는 챗봇의 가장 중요한 기능을 제공합니다. 이는 기존의 복잡한 필터링 인터페이스를 대체하는 직관적인 접근 방식입니다.
st.text_area를 통해 자연어 쿼리를 위한 사용자 입력을 캡처합니다. 이는 사용자가 “us-west-2 리전의 실행 중인 EC2 인스턴스 보기”와 같은 자연스러운 문장으로 복잡한 조회를 수행할 수 있도록 합니다.
실제 쿼리 처리는 db.execute_query(user_input)를 통해 이루어지며, 이 과정에서 Bedrock을 사용하여 쿼리를 해석하고 리소스를 필터링합니다. 자연어를 구조화된 필터 조건으로 변환하는 이 과정은 사용자 경험을 크게 향상시키는 기능입니다.
with tab1:
user_input = st.text_area(
"Enter your question about AWS resources:",
value=st.session_state.get('user_input', ''),
height=100,
placeholder="Example: Show me all EC2 instances in us-west-2"
)
if st.button("Query Resources", type="primary"):
if user_input:
debug_print(f"Processing query: {user_input}")
try:
db = DatabaseConnection()
results = db.execute_query(user_input)
if results is not None and not results.empty:
st.subheader("Query Results:")
# 결과 표시 및 상세 정보 보기통합 비용 분석 및 기타 탭
비용 분석 탭은 Plotly 차트를 활용하여 비용 데이터를 시각화하는 전문적인 기능을 제공합니다. 서비스별, 리전별, 시간별 비용 분포를 다양한 차트 형태로 표현하여 사용자가 비용 구조를 한눈에 파악할 수 있도록 돕습니다.
리소스 메트릭 탭은 실시간 성능 메트릭을 표시하여 시스템 모니터링 기능을 담당합니다. CPU 사용률, 메모리 사용량, 네트워크 트래픽 등의 핵심 지표들을 실시간으로 추적하고 시각화하여 운영 상황을 즉시 파악할 수 있게 합니다.
최적화 탭은 AI로 강화된 추천을 보여주어 실질적인 비용 절감 기회를 제공합니다. 단순한 데이터 표시를 넘어서 구체적인 실행 방안과 예상 절감액을 포함한 실행 가능한 추천을 제시합니다.
마지막으로 AWS 전문가 채팅 탭은 컨텍스트 인식 응답으로 Q&A를 지원하는 전문가 수준의 상담 기능을 제공합니다. 사용자의 AWS 환경과 이전 대화 내용을 고려하여 맞춤형 답변을 제공하며, 복잡한 AWS 개념이나 문제 해결 방법에 대한 전문적인 조언을 받을 수 있습니다.
향후 확장 가능한 기능과 최신 AI 기술 통합의 가능성
현재의 AWS R-Assistant는 기본적인 모니터링, 비용 분석, 최적화 추천 기능을 제공하며, 비교적 간단한 아키텍처로 구축되었습니다. 그러나 이 솔루션은 다양한 방향으로 확장 가능하며, 최신 AI 기술과 트렌드를 통합함으로써 더욱 강력한 도구로 발전할 수 있습니다.
확장 가능한 기능
현재 시스템은 EC2, RDS, Lambda, S3에 초점을 맞추고 있지만, EKS(Elastic Kubernetes Service), ECS(Elastic Container Service), DynamoDB, CloudFront 등 더 많은 AWS 서비스를 지원하도록 확장할 수 있습니다. 이러한 서비스 확장을 통해 사용자는 더 다양한 리소스를 통합적으로 관리할 수 있게 됩니다.
사용자 맞춤 알림 시스템의 도입도 중요한 확장 방향입니다. 리소스 상태나 비용 이상에 대한 사용자 지정 알림을 설정할 수 있는 기능을 추가하면, 개인 사용자는 예산 초과를 방지하고 기업은 중요한 문제를 즉시 감지할 수 있습니다. CPU 사용률이 80%를 초과하거나 일일 비용이 20% 증가하는 경우와 같은 특정 조건에 따른 자동 알림은 사전 예방적 관리를 가능하게 합니다.
멀티 계정 및 조직 지원은 기업 환경에서 특히 중요한 확장 기능입니다. AWS Organizations와 통합하여 여러 계정의 리소스와 비용을 단일 대시보드에서 관리할 수 있도록 확장하면, 기업의 계정 관리 팀이 전체 조직의 클라우드 사용을 중앙에서 모니터링하고 최적화할 수 있습니다.
자동화된 최적화 작업은 현재의 추천 시스템을 한 단계 발전시킨 기능입니다. 최적화 추천을 단순히 제안하는 것을 넘어, 사용자의 승인 후 자동으로 중지된 EC2 인스턴스 종료나 RDS 인스턴스 다운사이징 같은 작업을 실행할 수 있습니다. 이를 통해 수동 작업을 줄이고 효율성을 극대화할 수 있습니다.
비용 예측 모델의 고도화도 중요한 발전 방향입니다. 현재의 간단한 선형 회귀 기반 예측 대신, ARIMA나 Prophet 같은 머신러닝 모델을 활용하여 더 정확한 비용 예측을 제공할 수 있습니다. 이는 기업이 장기적인 예산 계획을 수립하는 데 큰 도움이 됩니다.
최신 AI 기술 통합의 무한한 가능성
AI Agent 통합은 현재 시스템을 한 차원 높은 수준으로 끌어올릴 수 있는 핵심 기술입니다. 현재의 챗봇은 사용자의 입력에 반응하는 방식으로 작동하지만, 자율적으로 작업을 수행하는 AI Agent를 통합하면 더 능동적인 역할을 할 수 있습니다. Agent는 비용 이상을 감지하고 자동으로 관련 리소스를 분석한 후 최적화 작업을 제안하거나 실행할 수 있어, 특히 기업 환경에서 대규모 리소스 관리의 부담을 크게 줄여줍니다.
RAG(Retrieval-Augmented Generation) 기술의 활용은 답변의 품질과 정확성을 대폭 향상시킬 수 있습니다. AWS 공식 문서, Well-Architected Framework, 최신 블로그 게시물 등 방대한 외부 지식 기반에서 정보를 검색하고, 이를 기반으로 더 정확하고 최신의 답변을 제공할 수 있습니다. “최신 AWS 보안 모범 사례는 무엇인가?”와 같은 질문에 대해 최신 AWS 문서를 참조하여 답변을 생성할 수 있어 AWS Expert Chat 탭의 품질을 크게 향상시킬 것입니다.
멀티모달 AI의 도입은 사용자 인터페이스를 더욱 다양화할 수 있습니다. 현재는 텍스트 기반 인터페이스에 초점을 맞추고 있지만, Amazon Transcribe를 활용한 음성 입력이나 리소스 아키텍처 다이어그램 분석과 같은 이미지 분석을 지원할 수 있습니다. 사용자는 음성으로 쿼리를 입력하거나, 다이어그램을 업로드하여 관련 리소스 정보를 조회할 수 있게 됩니다.
자연어 이해 기술의 고도화는 사용자 경험을 한층 향상시킬 수 있습니다. BERT 기반 모델 같은 최신 NLU 기술을 활용하여 사용자의 의도를 더 정확히 파악하고, “us-west-2의 EC2 중 CPU 사용률이 20% 미만인 인스턴스를 찾아서 2월 비용을 분석해줘”와 같은 복잡한 다단계 쿼리를 처리할 수 있습니다.
강화 학습의 적용은 시스템의 지속적인 개선을 가능하게 합니다. 사용자의 피드백을 기반으로 챗봇이 스스로 학습하고 응답 품질을 개선할 수 있어, 사용자가 특정 추천을 거부하면 그 이유를 학습하여 더 적합한 추천을 제공할 수 있습니다.
생성형 AI 기반 코드 생성 기능은 실용적인 가치를 크게 높일 수 있습니다. AWS 리소스 관리에 필요한 Terraform 스크립트나 AWS CLI 명령어를 자동 생성하고 사용자에게 제공함으로써, 개인 사용자가 복잡한 설정을 쉽게 구현하도록 돕고, 기업은 대규모 배포를 자동화하는 데 활용할 수 있습니다.
이러한 확장 기능과 AI 기술 통합은 AWS R-Assistant를 단순한 모니터링 도구에서 지능형 클라우드 관리 플랫폼으로 발전시킬 수 있습니다. Agent와 RAG를 통해 더 자율적이고 지식 기반의 응답을 제공하며, 멀티모달 및 NLU 고도화로 사용자 경험을 크게 개선할 수 있습니다. 또한 강화 학습과 생성형 AI는 지속적인 개선과 자동화를 가능하게 하여, 개인 사용자와 기업 모두에게 더 큰 가치를 제공할 것입니다.
결론
AWS R-Assistant 챗봇은 Amazon Bedrock의 강력한 AI 기능과 AWS의 다양한 서비스를 통합하여 클라우드 모니터링과 자원 관리의 복잡성을 해결하는 사용자 친화적 솔루션입니다. 이 솔루션은 개인 사용자가 비용 초과를 방지하고 리소스를 효율적으로 관리할 수 있도록 지원하며, 기업의 계정 관리 조직에게는 대규모 환경에서 비용과 성능을 최적화하는 데 필요한 실질적인 인사이트를 제공합니다.
이 챗봇의 핵심 가치는 AWS Management Console 탐색의 번거로움을 완전히 없애고, 자연어 인터페이스와 실시간 시각화를 통해 직관적이고 효율적인 사용자 경험을 제공한다는 점입니다. 각 탭이 제공하는 고유한 기능들은 리소스 조회부터 비용 분석, 최적화 추천, 전문가 상담에 이르기까지 포괄적인 클라우드 관리 환경을 구성합니다.
더 나아가 이 솔루션은 AI Agent, RAG, 멀티모달 AI와 같은 최신 기술을 통합함으로써 더욱 지능적이고 자율적인 클라우드 관리 플랫폼으로 발전할 무한한 가능성을 가지고 있습니다. 단순한 모니터링 도구를 넘어서 사용자의 의도를 이해하고 선제적으로 대응하는 지능형 어시스턴트로 진화할 수 있는 기반을 제공합니다.
Amazon Bedrock 기반으로 구축된 이 솔루션을 통해 클라우드 환경을 더 효과적으로 관리하고 비용을 절감해 보세요. AWS R-Assistant를 활용하여 AWS와 함께 더 나은 클라우드 경험을 만들어 나갈 수 있습니다. 복잡한 클라우드 관리가 더 이상 부담스럽지 않은, 간편하고 지능적인 새로운 시대가 시작됩니다.
Github Repository for Sample Code
AWS_Resource_Monitoring_Chatbot. aws-ai-ml-workshop-kr/genai/aws-gen-ai-kr/20_applications/15_AWS_Resou…
Demo 영상 link
참고 자료 (References)
1. AWS Cost Optimization Guide: AWS 공식 문서에서 제공하는 비용 최적화 가이드라인. AWS Cost Optimization
2. Amazon Bedrock Documentation: Bedrock을 활용한 AI 모델 통합에 대한 공식 문서. Amazon Bedrock Documentation
3. Boto3 Documentation: AWS 서비스와 상호작용하기 위한 Python SDK인 Boto3의 공식 문서. Boto3 Documentation
4. Streamlit Documentation: 대화형 웹 애플리케이션 구축을 위한 Streamlit 프레임워크 문서. Streamlit Documentation
5. Cloud Cost Optimization Strategies: Gartner의 클라우드 비용 최적화 전략 가이드라인. Gartner Cloud Cost Optimization
6. AWS Well-Architected Framework: 비용 최적화를 포함한 클라우드 아키텍처 설계 원칙. AWS Well-Architected Framework