AWS 기술 블로그
Category: Artificial Intelligence

A1Mobilsoft의 운영 문의 자동화 여정 (2): 세 에이전트 구현과 사람 vs AI 검증
본 블로그 시리즈는 A1Mobilsoft, Megazone, AWS 가 공동 작성 하였으며, 두 편으로 이루어져 있습니다. 각 편의 구성은 다음과 같습니다. 1편 (0~3장): 문제 정의와 3-에이전트 아키텍처 설계 2편 (4~7장, 현재 글): 세 에이전트 구현 우여곡절과 사람 vs AI 검증 2편: Bedrock AgentCore·Strands 기반 구현 디테일, 프롬프트 캐시, 그리고 14건 병렬 비교 결과 1편에서는 32개월간 846건이 쌓인 […]

A1Mobilsoft의 운영 문의 자동화 여정 (1): 문제 정의와 3-에이전트 아키텍처 설계
본 블로그 시리즈는 A1Mobilsoft, Megazone, AWS 가 공동 작성 하였으며, 두 편으로 이루어져 있습니다. 각 편의 구성은 다음과 같습니다. 1편 (0~3장, 현재 글): 문제 정의와 3-에이전트 아키텍처 설계 2편 (4~7장): 세 에이전트 구현 우여곡절과 사람 vs AI 검증 1편: 슬랙 #운영개발문의 채널의 고통에서 출발해, 왜 Knowledge·Code·DB 세 에이전트 구조로 갈랐는가 수 시간씩 늘어지던 운영 문의를 […]

AWS 환경에서 Physical AI 모델 구축하기 – (1) 데이터
Physical AI는 텍스트를 생성하던 AI가 물리 세계에서 직접 인식하고, 추론하고, 행동하는 단계로 넘어가는 흐름을 뜻합니다. 휴머노이드 로봇부터 자율주행까지 응용은 빠르게 늘고 있지만, 실제로 만들어 내려면 대규모 멀티모달 데이터, 막대한 학습 연산, 고정밀 시뮬레이션, 그리고 이 모든 것을 실제 동작으로 잇는 오케스트레이션까지 새로운 파이프라인이 필요합니다. 이 시리즈는 Physical AI를 뒷받침하는 핵심 기술과 그 과정의 챌린지를 먼저 […]

2주 만에 Strands SDK와 Amazon Bedrock AgentCore로 구현한 어스얼라이언스의 CS 환불 자동응답 에이전트 시스템
이번 블로그는 AWS DEVCRAFT 2026 (2026.3.26 ~ 4.9, AWS 코리아 오피스) 해커톤 프로그램에 참여하여 진행한 프로젝트를 기반으로 작성되었습니다. DEVCRAFT는 AWS SA와 고객사 개발팀이 함께 실제 비즈니스 과제를 2주간 집중 개발하는 프로그램입니다. 어스얼라이언스 (US Alliance)는 크리에이터 기반 금융 콘텐츠·커뮤니티 플랫폼 ‘어스플러스(US PLUS)’를 운영하는 기업입니다. 본 블로그에서는 어스얼라이언스가 Amazon Bedrock AgentCore 기반으로 약 2주 만에 구축한 CS […]

개인 생산성에서 멈춘 Claude Code, 조직의 생산성으로 – 영상 10개로 완성하는 Claude Code on Amazon Bedrock 학습 플랜
AI 코딩 도구, 이제 다들 하나쯤 쓰고 계실 겁니다. 문제는 그 다음입니다. 도구를 손에 쥐는 것과, 그 도구를 조직의 실제 생산성으로 잇는 것은 전혀 다른 이야기입니다. 대부분의 Claude Code 콘텐츠는 개인 데스크톱 생산성에서 멈춥니다. “이렇게 하니 빨라지더라”까지는 보여 줍니다. 하지만 코드·프롬프트가 어떻게 흐르는지, 토큰은 얼마나 쓰는지, 감사·통제는 누가 책임지는지 — 정작 조직이 던지는 질문의 자리는 […]

1시간 대화로 만드는 Amazon Connect Customer AI Agent [AICC Builder 시리즈 #1]
Amazon Connect Customer AI Agent가 무엇으로 이루어지는지 이해하고, 코드 한 줄 없이 전화받는 PoC까지 완성하기 이 블로그는 아래 데모 영상 속 AICC Builder를 활용해 Amazon Connect Customer AI Agent를 빠르게 만드는 방법을 가이드합니다. 아래 녹음과 같이 고객 응대를 하는 우리 회사만의 AI Agent를 빠르게 구성하는 방안을 안내합니다. Amazon Connect Customer AI Agent가 배송 조회 해주는 […]

Claude Apps Gateway on AWS 자세히 알아보기
들어가며 최근 많은 엔터프라이즈 기업들은 Amazon Bedrock을 기반한 Claude Code 및 Claude Desktop의 도입을 적용하고 있습니다. Amazon Bedrock을 통해 Claude 모델을 호출하면, 사용자의 데이터를 모델 학습에 재활용하지 않으며, Private Network 기반으로 사용자들의 Claude 사용 환경을 구성 할 수 있습니다. 또한 기존 AWS 계정·IAM 권한 체계를 통해 인증과 비용을 통합 관리할 수 있으며, Guardrails로 콘텐츠 필터링을 […]
AWS Transform for migrations, 이제 13개 언어에 대한 현지화 지원
이 글은 AWS Blog의 “AWS Transform for migrations now supports localization for 13 languages” by Jamie Vinciguerra and Jason Amaya 게시글을 번역한 글 입니다. 마이그레이션 프로젝트를 수행하는 조직이 항상 하나의 공통 언어로 운영되는 것은 아닙니다. 마이그레이션 팀은 여러 지역에 걸쳐 있으며, 워크로드에 가장 가까운 사람들이 종속성, 비즈니스 컨텍스트, 운영 리스크를 가장 잘 이해하고 있는 경우가 […]
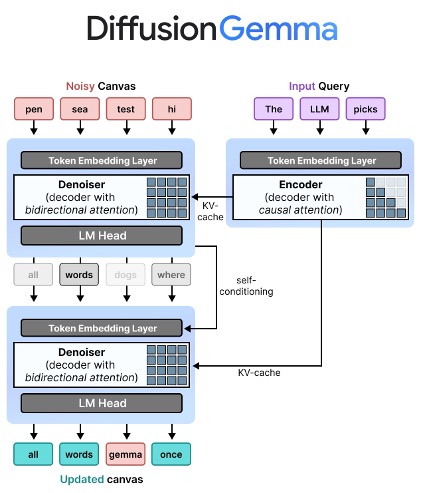
AWS 환경에서 프로덕션-레디 확산 언어 모델(DLM) 검증하기
확산 언어 모델(Diffusion Language Model, 이하 DLM)은 일반적인 자기회귀(Autoregressive, 이하 AR) 모델과 다른 방식으로 텍스트를 생성하는 언어 모델입니다. 최근 AR 모델과 동일한 사이즈의 DLM 모델들이 공개되고 있으며, 벤치마크 결과에서 AR보다 낮은 응답 지연(latency)을 보이며 주목을 받고 있습니다. 다만 AR과 완벽히 동일한 구조의 모델이 아니기 때문에 워크로드에서 모델을 변경하기 앞서 검증을 통해 기존 워크로드의 응답 품질에 […]

분산 학습을 위한 AWS 컴퓨트 선택 가이드 (1편: 모델 규모와 하드웨어 선택)
대규모 언어 모델(LLM) 학습을 준비하는 팀이 가장 먼저 부딪히는 질문은 결국 “어떤 GPU를 얼마나, 어떻게 확보할 것인가”로 귀결됩니다. 그러나 이 질문은 H100이냐 B200이냐를 고르는 단순한 하드웨어 선택으로 끝나지 않습니다. 하나의 노드로 충분한지, 아니면 여러 노드로 확장해야 하는지, On-Demand로 그때그때 띄울지, Capacity Block으로 미리 예약할지, 평범한 EC2 클러스터로 감당이 되는지, 아니면 Amazon EC2 울트라클러스터(UltraClusters)나 Amazon EC2 […]