AWS 기술 블로그
Category: Amazon SageMaker

AWS 환경에서 Physical AI 모델 구축하기 – (1) 데이터
Physical AI는 텍스트를 생성하던 AI가 물리 세계에서 직접 인식하고, 추론하고, 행동하는 단계로 넘어가는 흐름을 뜻합니다. 휴머노이드 로봇부터 자율주행까지 응용은 빠르게 늘고 있지만, 실제로 만들어 내려면 대규모 멀티모달 데이터, 막대한 학습 연산, 고정밀 시뮬레이션, 그리고 이 모든 것을 실제 동작으로 잇는 오케스트레이션까지 새로운 파이프라인이 필요합니다. 이 시리즈는 Physical AI를 뒷받침하는 핵심 기술과 그 과정의 챌린지를 먼저 […]
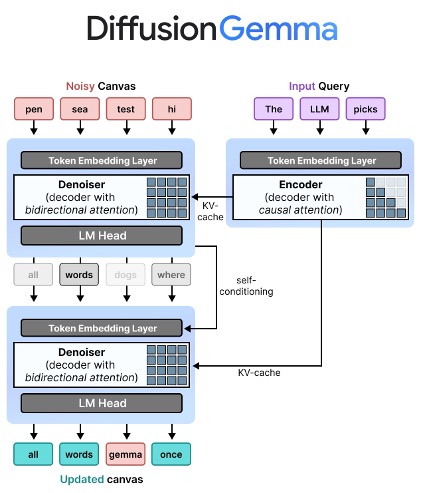
AWS 환경에서 프로덕션-레디 확산 언어 모델(DLM) 검증하기
확산 언어 모델(Diffusion Language Model, 이하 DLM)은 일반적인 자기회귀(Autoregressive, 이하 AR) 모델과 다른 방식으로 텍스트를 생성하는 언어 모델입니다. 최근 AR 모델과 동일한 사이즈의 DLM 모델들이 공개되고 있으며, 벤치마크 결과에서 AR보다 낮은 응답 지연(latency)을 보이며 주목을 받고 있습니다. 다만 AR과 완벽히 동일한 구조의 모델이 아니기 때문에 워크로드에서 모델을 변경하기 앞서 검증을 통해 기존 워크로드의 응답 품질에 […]

Sim-to-Real과 Real-to-Sim: 유능한 Physical AI를 가능하게 하는 핵심 엔진
이 글은 AWS Blog의 Sim-to-Real and Real-to-Sim: The Engine Behind Capable Physical AI by Dario Macagnano, Ignacio Sánchez, and Quinn Cheong 게시글을 번역한 글 입니다. 서론 Physical AI 시스템, 즉 현실 세계를 인지하고 추론하며 행동하는 로봇은 빠르게 발전하고 있습니다. Sim-to-Real 파이프라인은 이러한 발전의 핵심에 있습니다. 그러나 연구실 밖에서도 안정적으로 작동하는 모델을 만드는 것은 이 분야에서 […]

AWS 공간 데이터를 활용한 건물 검사 인텔리전스 구축
이글은 AWS Blog의 “Building Inspection Intelligence with AWS Spatial Data by Michael Prevost, Frantz Lohier, Graeme McHale, Jim Kennedy” 게시글을 번역한 글 입니다. AWS 기반 검사 워크플로를 위한 공간 데이터 관리 실용 가이드 서론 산업 전반에 걸쳐 검사 팀은 자산 상태를 정확하게 문서화하고, 규정 준수 요구사항을 충족하며, 데이터 수집 후 수개월 또는 수년이 지난 후에도 […]

AWS와 NVIDIA로 Physical AI 가속화: 시뮬레이션과 실제 학습을 통한 프로덕션 레디 애플리케이션 구축
이 글은 AWS Open Source Blog의 “Accelerating physical AI with AWS and NVIDIA: building production-ready applications with simulation and real-world learning by Srinivas Nidamarthi, Alex Mevec, Ali Shahrokni, Brian Kreitzer, and Raja GT” 게시글을 번역한 글 입니다. 디지털 지능을 넘어 Physical AI를 정의하다 Physical AI는 인공지능의 새로운 진화 방향으로, 순수한 컴퓨팅 시스템을 넘어 물리적 세계를 […]

GraphRAG Toolkit으로 지식 그래프 쿼리하기
시리즈 안내 이 글은 3편으로 기획된 GraphRAG Toolkit 시리즈의 3번째 글입니다. 시리즈의 첫 번째 글인 Neptune GraphRAG Toolkit을 활용하여 정교한 비정형 데이터 검색하기에서는 비정형 데이터에서 벡터 임베딩이 포함된 그래프를 자동으로 구축하고, 구조적으로 관련된 정보를 검색하는 질의응답 전략 프레임워크를 소개했습니다. 두 번째 글인 GraphRAG Toolkit으로 지식 그래프 인덱싱하기에서는 해당 toolkit을 활용하여 지식 그래프를 단계별로 인덱싱하는 과정을 […]

에이전틱 AI와 Amazon Bedrock AgentCore를 활용한 전문가 팀 시뮬레이션
이 글은 AWS Spatial Computing Blog에 게시된 Simulating Expert Teams with Agentic AI and Amazon Bedrock AgentCore 를 한국어로 번역 및 편집하였습니다. 소개 여러 전문 분야에 걸친 기술적 질문에 답하는 것은 단순히 정답을 찾는 문제가 아닙니다. 가장 어려운 부분은 그 답을 제공할 수 있는 적절한 사람들을 조율하는 일인 경우가 많습니다. 만약 AI가 전문가 팀을 대체하는 […]
Amazon SageMaker HyperPod로 슈퍼브에이아이의 비전 파운데이션 모델 ‘ZERO’ 효율적으로 대규모 분산 학습하기
이 블로그는 슈퍼브에이아이의 차문수 (공동창업자, CTO), 장태웅 (머신러닝 엔지니어), 최상범(머신러닝 엔지니어) 님과 AWS 유용환 (GenAI Solutions Architect) 님이 작성해주신 블로그 입니다. 슈퍼브에이아이는 압도적인 비전 AI 노하우와 경험을 바탕으로 피지컬 AI로 확장 중인 비전 인텔리전스 기업입니다. 산업 현장에서 바로 적용 가능한 비전 파운데이션 모델 ‘ZERO(Zero-shot Object Detector)’를 어떻게 Amazon SageMaker HyperPod를 이용하여 효율적으로 학습시키고 개선했는지 소개하려 […]

NVIDIA와 함께 AWS에서 자율주행 3.0을 위한 End-to-End Physical AI 데이터 파이프라인 구축하기
본 블로그는 Olivier Sutter, Geoff Van Natter, Mikhail Yurasov, Amrith Prabhu, Steven DeVries, Wonsik Han이 작성한 Building an End-to-End Physical AI Data Pipeline for Autonomous Vehicle 3.0 on AWS with NVIDIA를 번역, 편집하였으며, 이해를 돕기 위해 Note를 추가했습니다. 도입 자율주행(AV) 개발은 아키텍처 관점에서 명확한 세대 전환이 진행 중입니다. AV 1.0: 인지(Perception), 예측(Prediction), 계획(Planning), 제어(Control)로 이어지는 […]

Amazon SageMaker HyperPod의 오토스케일링 알아보기
이 글은 Artificial Intelligence 블로그에 게시된 글 (Introducing auto scaling on Amazon SageMaker HyperPod)을 한국어로 번역 및 편집하였습니다. 2025년 8월에 Amazon SageMaker HyperPod가 Karpenter를 통한 관리형 노드 오토스케일링 지원하기 시작했습니다. 이를 통해 추론 및 학습 요구 사항에 맞춰 SageMaker HyperPod 클러스터를 효율적으로 확장할 수 있습니다. 실시간 추론 워크로드는 예측 불가능한 트래픽 패턴에 대응하고 서비스 수준 계약(SLA)을 유지하기 […]